基于分布式流处理的自适应数据分发策略
2018-08-15闾程豪荆一楠何震瀛王晓阳1
闾程豪 荆一楠 何震瀛 王晓阳1,
1(复旦大学软件学院 上海 201203)2(复旦大学计算机科学技术学院 上海 201203)3(上海市数据科学重点实验室(复旦大学) 上海 200433)
0 引 言
在分布式数据流处理中,一个典型的场景就是采用一个固定的数据分发方法将数据(根据其键值)发送到多个工作节点中。例如,新浪、Twitter等媒体门户对当下新闻中的热点词汇进行实时统计[1],实现基于频数统计的在线数据挖掘技术[2],或是基于分布式数据流进行基于“group by”的实时查询等。
在上述场景中,数据分发方法都是以最小化整体处理的延迟时间或者最大化整体处理的吞吐量为目标的。为了实现这个目标,负载均衡和键值分离这两个因素往往被考虑到。一方面,工作节点之间的负载越均衡,并行处理的效率就越高,整体处理的性能表现就越好。另一方面,为了使负载尽可能地均衡,一些分发方法将含有相同键值的数据分发到不同的节点上(例如round-robin数据分发方法)从而产生了键值分离。键值分离往往需要额外的归并处理,因而产生额外开销。
现有工作基于类似上述两方面的考虑,针对不同特征的数据集提出了各种静态数据分发方法[6-9]以优化处理的整体性能。当这些数据分发方法应用于某些特定数据集时,处理延迟时间或吞吐量得以最优化。在处理分布特征不同的数据集或者数据特征不断变化的数据集时,这些静态分发方法显得力不从心。例如,我们对一周内Wikimedia所有网站的访问记录进行分析,发现每小时被访问网页的数量(标记为K)与每小时内最受欢迎网页被访问的次数占总次数的比例(标记为p1)都会随着时间发生较大变化,如图1所示。这些值的大小对不同数据分发方法的性能表现有很大影响。此时,任何一种只对某种数据特征进行优化的分发方法都无法使得查询处理的延迟时间一直保持最小。
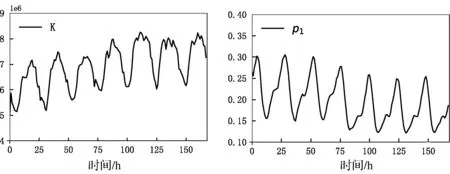
图1 Wikmedia数据集上数据特征随着时间的变化
面对上述挑战,本文策略为:(1) 在基于mini-batch的分布式流处理模型中,提出了一种自适应数据分发策略APS,以应对数据特征不断变化的流数据处理任务。(2) 为数据分发方法提供了一种叫做整体分发评估HPM的估计,HPM综合考虑了每个mini-batch中的负载均衡和键值分离情况,并为APS的调整提供依据。(3) 采用处理的延迟时间作为整体性能的评判标准,并通过在Spark Streaming[5]上的大量实验证明了 APS的优越性与HPM的准确性。
1 相关工作
现有工作中的数据分发方法主要基于最大负载和键值分离两方面的考虑。文献[6-7]提出MPC模型,通过综合分析一个目标查询所需数据交换的轮数和每轮数据交换中的最大负载这两个因素找到最佳的数据分发方法。Nasir等[8-9]和Katsipoulakis等[10]通过权衡数据分发的不平衡程度与键值分离产生的额外处理和存储开销来确定最优的数据分发方法。本节我们将着重介绍并比较当下最流行和最先进的5种分发方法。
1.1 现有分发方法
(1) Hash分发方法 Hash分发方法(HASH)使用一个哈希函数为每个键值映射一个特定的“编号”,并将数据发送到“编号”对应的工作节点。“编号”与工作节点一一对应且相同键值总是对应相同的“编号”。因此HASH不会产生键值分离,但其负载均衡受数据集倾斜程度的影响较大。
(2) Round-robin分发方法 Round-robin分发方法(RR)不考虑数据的键值,将数据逐条轮流发送至每一个工作节点。RR会产生大量的键值分离,但每个节点上的负载几乎相同。
(3) Power of Two Choices分发方法 Power of Two Choices分发方法(PoTC)[12]在数据分发过程中,令每个负责数据分发的载入节点各自记录已发送过的键值与其对应送往的“编号”。各个载入节点互相独立,并分别实时更新并记录送往每个“编号”对应节点的负载条数。对含有新键值的数据,PoTC使用两个独立的哈希函数产生两个“编号”,将数据发送到当前负载较小的“编号”对应的节点中,并记录该“编号”与键值的对应关系;对含有旧键值的数据,PoTC通过该键值对应的“编号”对其进行分发。Katsipoulakis等[10]指出,当载入节点只有一个时,PoTC不仅能避免键值分离,还能改善负载均衡。然而,现实的分布式应用中,数据的分发往往由多个独立的载入节点共同完成,因此同一个键值在不同载入节点中对应的“编号”不一定相同,键值分离随之产生。
(4) Partial Key Grouping分发方法 Partial Key Grouping分发方法[8](PK)在数据分发过程中,令每个载入节点实时更新记录送往不同“编号”对应节点的负载条数。对每条刚到达的数据,PK使用两个独立的哈希函数产生两个“编号”,将数据发送到当前负载较小的“编号”对应的节点中。Nasir等[8]指出,当数据倾斜程度与工作节点数量满足一定条件时,PK获得较好的负载均衡且只产生少量键值分离。然而当数据倾斜过大,PK的负载均衡较差。此外,PK缺乏一定的拓展性。
(5) D-Choices分发方法与W-Choices分发方法 D-Choices分发方法(DC)和W-Choices分发方法(WC)是PK的两种更高级的拓展[9](APK)。分发过程中,每个载入节点与PK类似,各自记录发往下游工作节点的负载情况。同时,APK根据键值出现的概率将所有键值分为heavy hitter与light key两类。对含有light key的数据,APK使用两个独立的哈希函数产生两个“编号”,将数据发送到当前负载较小的“编号”对应的节点中;对含有heavy hitter的数据,APK为其提供更多“编号”的选择(DC使用d个独立哈希函数产生d个编号,WC则提供所有的编号),并将数据发送到当前负载最小的“编号”对应的节点中。根据Nasir等[9]的分析,DC和WC均能获得最佳的负载均衡且表现接近,同时会产生一定的键值分离。当heavy hitter个数为0时,APK退化成了PK;当每个键值都是heavy hitter时(例如只有1个键值的情况),APK退化成了RR。为了讨论方便,本文选用WC来代表APK。
1.2 现有分发方法的比较
1) HASH不会产生键值分离,且负载均衡程度由数据分别的特征决定。当数据分布较均匀时,一个理想的HASH方法可以获得最佳的处理表现。
2) 在常见的含有多个载入节点的应用中,PoTC与PK都为所有的键值提供了两个选择,键值分离程度类似。而PK在分发过程中为更多数据提供了两个选择,因此PK比PoTC有更好的负载均衡和整体表现。
3) APK通过给heavy hitter更多的分发选择,不仅提升了PK的可拓展性,更是以有限的键值分离增加为代价,解决了数据倾斜程度过大时的负载均衡问题。
4) APK和RR都能获得最佳的负载均衡,并分别对heavy hitter和所有键值进行全局的分发。因此APK的键值分离程度更少,整体表现性能更佳。
5) APK归纳或更优于RR、PoTC和PK。但由于APK会产生键值分离,因此只有当数据分布不均匀时,APK会更优于HASH获得最佳表现。
综上所述,HASH和APK有机会在不同的数据特征中获得最佳性能表现。因此,本文选用HASH和APK作为参考和比较。
2 问题归纳
2.1 基于mini-batch的流数据分发模型
基于mini-batch的分布式流处理系统是当下最流行的分布式流处理系统之一。以Spark Streaming[5]和Java Flume[11]为例,它们被广泛应用于实时或准实时的分布式流处理应用中,具有良好的错误恢复能力。
基于上述系统的数据分发模型如图2所示。模型根据系统时间将数据流划分为一系列微小批次(mini-batch),并对mini-batch进行串行处理。图2将第t个批次中的一次数据分发抽象成了一个有向无环图。图中结点“L”代表接收和分发数据的载入节点,结点“M”代表接收并处理数据的map工作节点,每条有向线段代表数据的分发方向。一次分发完成后,系统对各个map工作节点的工作状态进行同步,并根据处理任务的需要决定下一步的操作(继续分发、数据归并或结果输出等)。当一个mini-batch处理结束后,系统对所有节点的工作状态进行同步。在当前批次的数据处理完成且下一个批次的数据也收集完成之后,系统开始对下一个批次的数据进行处理。
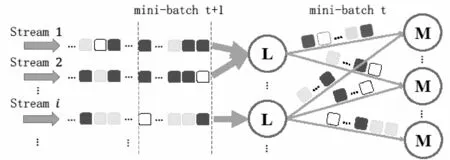
图2 基于mini-batch的流数据分发模型
2.2 整体分发评估(HPM)
为了衡量数据分发方法的性能表现,本文提供了一种叫作整体分发评估(HPM)的估计。
首先给出单个mini-batch中最大负载和键值分散度的定义来量化分发方法在单个mini-batch中的负载均衡程度和键值分离程度。接着,结合最大负载与键值分散度,本文给出分发方法在单个mini-batch中的整体分发评估。
定义1对于第t个mini-batch的数据分发,收到最多数据的工作节点所接收的数据条数为mini-batcht上的最大负载,记作L(t)。
定义2对于第t个mini-batch的数据分发,分发后每个工作节点含有键值数量的和减去被分发数据的键值数量为mini-batcht上的键值分散度,记作D(t)。
定义3对于第t个mini-batch的数据分发,其最大负载和键值分散度的线性组合为mini-batcht上的整体分发评估,记作HPM(t):
HPM(t)=L(t)+λ·D(t)
(1)
式中:λ为组合系数,用于衡量键值分离程度占整体处理开销的影响比例。例如,进行“union”操作时,键值分离并不会影响结果的输出,因此λ=0;进行“group by”操作时,由于键值分离,工作节点含有的部分结果需要进一步聚合归并,产生额外的开销,因此λ>0,且λ与单条数据在聚合归并时的处理时间以及单条数据在map工作节点中的处理时间密切相关。此外,对分离的键值进行聚合归并处理的节点越少时,对部分结果聚合归并的操作就慢,λ就越大。
为了帮助理解,图3以在mini-batcht中的数据分发为例,解释了上述概念。图3中不同颜色的方片代表含有不同键值的数据,根据定义,mini-batcht的最大负载L(t)=8,键值分散度D(t)=2。当进行“union”操作时,λ=0,HPM(t)为8;当进行组合系数λ=1的“group by”操作时,HPM(t)=8+1×2=10。
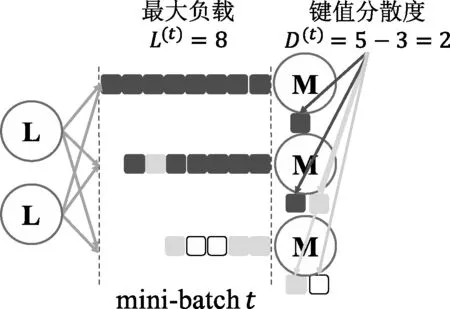
图3 在mini-batch t上的数据分发
根据基于mini-batch的流处理模型的特点,本文给出了数据分发方法整体分发评估的定义。
定义4在基于mini-batch的流处理分发模型中,各个mini-batch上整体分发评估的累加即为一个数据分发方法的全局整体分发评估,记作HPM:
(2)
2.3 优化目标
综合上述定义,单个mini-batch中的整体分发评估值越小,分发方法在该mini-batch中的表现越好。因此,全局整体分发评估的值越小,就意味着一个数据分发方法能提供给处理任务更好的整体性能表现。
因此,本文的优化目标为找到一种数据分发方法,使其在对数据分布特征不断变化的数据流的分发中,获得最小的全局整体分发评估HPM,从而使分布式流处理任务获得最小的延迟时间。
3 自适应数据分发策略(APS)
3.1 APS介绍与实现
基于上述优化目标,本文提出了一种叫做自适应数据分发策略(APS)的数据分发方法。APS采用了一系列被广泛使用的静态数据分发方法作为候选,根据对每个mini-batch数据分布特征的预测及各个候选方法在该mini-batch上整体分发评估的估计,调整在每个mini-batch上的数据分发方法。对每个mini-batch的处理中,APS按以下4个步骤进行:
1) 在开始某个mini-batcht的处理时,每个载入节点分别获得对mini-batcht数据分布特征的预测。
2) 每个载入节点分别遍历所有的候选分发方法,根据mini-batcht的预测数据特征,选取HPM(t)估计值最小的数据分发方法。
3) 每个载入节点根据所选的数据分发方法,将当前mini-batcht内的数据分发到map工作节点进行处理。
4) 若出现键值分离,map工作节点根据处理任务的需要,决定对数据的下一步的操作(例如聚合归并)。
在步骤2)中,每个载入节点分别获得相同的数据分布特征的预测并且采用相同的HPM估计方法,因此会调整至同一种数据分发方法。
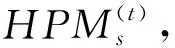
本文通过上一个mini-batch的数据特征分布情况来预测当前mini-batch的数据特征。由于文献[13-14]中许多数据流特征估计方法的存在,本文并未对数据特征的预测方法展开深入讨论。
3.2 HPM的估计
在APS的调整中,数据分发方法在一个mini-batch上对HPM的估计非常关键。根据第1节中对现有分发方法的介绍和比较,本文选用HASH和APK组成APS的候选分发方法集合。本节将分别介绍这两种分发方法在mini-batch上对HPM的估计。
假设系统共有m个接收并处理来自载入节点数据的map工作节点。mini-batcht含有M条待分发的数据和K个不同的键值,其中出现次数最多的键值出现的概率为p1, heavy hitter的个数为h。
3.2.1 HASH在mini-batch上对HPM的估计
HASH不会产生键值分离,因此D(t)=0。至于最大负载的估计,HASH满足带权重单选择的“balls-into-bins”模型[7]。其中,每个出现频率不同的键值对应模型中的不同重量的“ball”,m个map工作节点则分别对应模型中m个“bin”。根据模型,mini-batcht中HASH的最大负载L(t)满足:
(3)
式中:g(δ)=(1+δ)·ln(1+δ)-δ。
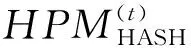
(4)
(5)
3.2.2 APK在mini-batch上对HPM的估计
APK可以保证L(t)最优,即负载完全平均:
APK给了每个heavy hitter最多m个选择,每个light key最多2个选择。因此,一次分发后,每个heavy hitter最多可以提供(m-1)个额外的键值,每个light key最多可以提供1个额外的键值。所以mini-batch t中APK的键值分散度D(t)满足:
D(t)≤(m-1)·h+1·(K-h)=K+(m-2)·h
(6)
APK在mini-batcht中对HPM的估计满足:
(7)
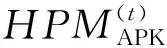
4 实 验
4.1 实验设置
实验在含有10台机器的集群中进行。每台机器分别有2个12核2.1 GHz Intel Xeon处理器,64 GB内存,运行64位Ubuntu Server 14.04操作系统。集群上运行Apache Spark 2.0.0与Apache Kafka 0.10.1.0。通过实验,我们将验证APS的优越性与HPM的准确性。
(1) 基于mini-batch的分布式流处理系统 实验选用Spark系统[4]中的Spark Streaming模块作为基于mini-batch的分布式流处理系统。Spark系统按照standalone的方式部署在10台机器上,其中,1台为master、9台为worker。每个worker维护一个含有24个核的executor。因此,本实验最多可以同时使用216个工作节点。当键值分离现象出现时,根据任务的需要,系统决定是否将含有分离键值的数据聚合归并到reduce节点中进行下一步操作。实验选用3个载入节点、15个map工作节点和1个reduce节点。
(2) 模拟数据源 实验中,我们搭建了一个含有3台机器的Kafka集群[3],并使用1个topic中的3个partition来部署数据集以模拟3个数据流。每个partition独立地存储数据,且被设置为从offset的最小值开始读取,并与3个载入节点一一对应。因此,相同数据源在使用不同分发方法时,分发数据的内容和顺序可以保持一致。
(3) 真实数据集 真实数据集WIKI是来自Wikimedia的开源数据。内容是自 2016年1月1日至2016年1月7日的每个小时内对所有Wikimedia网站的访问记录。我们将原数据集做一定的解析之后,得到含有168个小时级时间戳的4 490 000 000条记录。每条记录包括时间戳与其访问的网址信息,并将网址信息视作键值。其数据分布的特征变化如图1所示。实验中,我们对数据做了3%的均匀抽样以模拟更快的数据特征的变化。
(4) 模拟数据集 模拟数据集ZF1、ZF2均服从ZipF分布。分别通过改变ZipF分布函数中的键值数量K和特征指数函数z,我们生成了数据集ZF1和ZF2。图4展示了各个模拟数据集上数据分布的特征变化。固定ZF1中K=3 000,ZF2中z=0.8,通过控制系统读入数据流的速度,分别保证系统在处理ZF1和ZF2时,每个mini-batch上的特征分布能呈现图中变化。

图4 模拟数据集的数据特征偏移

4.2 在真实数据集上的性能表现
实验1将WIKI数据流基于mini-batch进行键值聚合(类似对键值做词频统计),并分别记录前60个mini-batch中系统分别使用HASH、APK和APS进行数据分发时的性能表现。每个mini-batch长度为40 s,并含有732 000条输入数据。为了更加清晰地展现数据分发方法对整体性能表现的影响,实验设置map工作节点上每条数据处理时间为0.1 ms,reduce节点上每条数据处理时间为0.3 ms,以模拟较为复杂的聚合任务。根据处理任务的类型(任务处理在各个节点上的延迟时间),组合系数λ设为3。
图5展示了不同分发方法在每个mini-batch中的处理延迟时间变化。APS通过自适应地调整选择每个mini-batch中的分发方法,将处理延迟时间尽可能地保持在最佳水平。与HASH和APK相比,APS分别最多能将处理延迟时间降低26.66%和26.67%。同时,注意到,由于本文对数据分布的预测存在误差,APS在对第50个和第59个mini-batch上的调整存在一定的延迟。
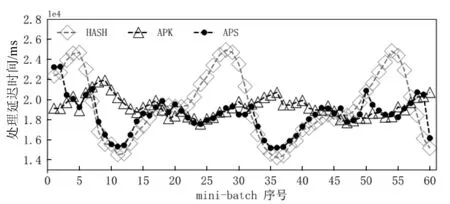
图5 不同分发方法在每个mini-batch上的处理延迟时间
图6展示了不同分发方法在每个mini-batch中的整体分发评估变化。每个mini-batch中整体分发评估的变化与图5非常相似,因此每个mini-batch上的延迟处理时间与整体分发评估具有很强的相关性。本文对HPM估计方法的准确性得以验证。
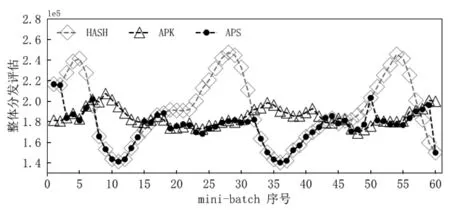
图6 不同分发方法在每个mini-batch上的整体分发评估
4.3 在模拟数据集上的性能分析
4.3.1 不同数据特征偏移对APS性能提升影响
实验2分别将ZF1和ZF2数据流基于mini-batch进行键值聚合,并选用每个mini-batch上的整体分发评估值作为性能指标。通过计算使用APS获得的HPM较使用HASH或APK获得的HPM所降低的百分比,我们得到APS较HASH和APK的处理性能提升比率。实验中,每个mini-batch长度为10 s,含有45 000条数据(被3个载入节点平均接收),数据特征变化如图7所示。此外,实验通过设置map工作节点和reduce节点上每条数据的处理时间,将组合系数λ设为1。
图7展示了APS在ZF1和ZF2中相比HASH和APK获得的性能提升比率。其中,“vs HASH avg”、“vs HASH max”和“vs APK avg”、“vs APK max”分别代表实验过程中APS较HASH性能提升比率的平均值、最大值以及较APK性能提升比率的平均值、最大值。
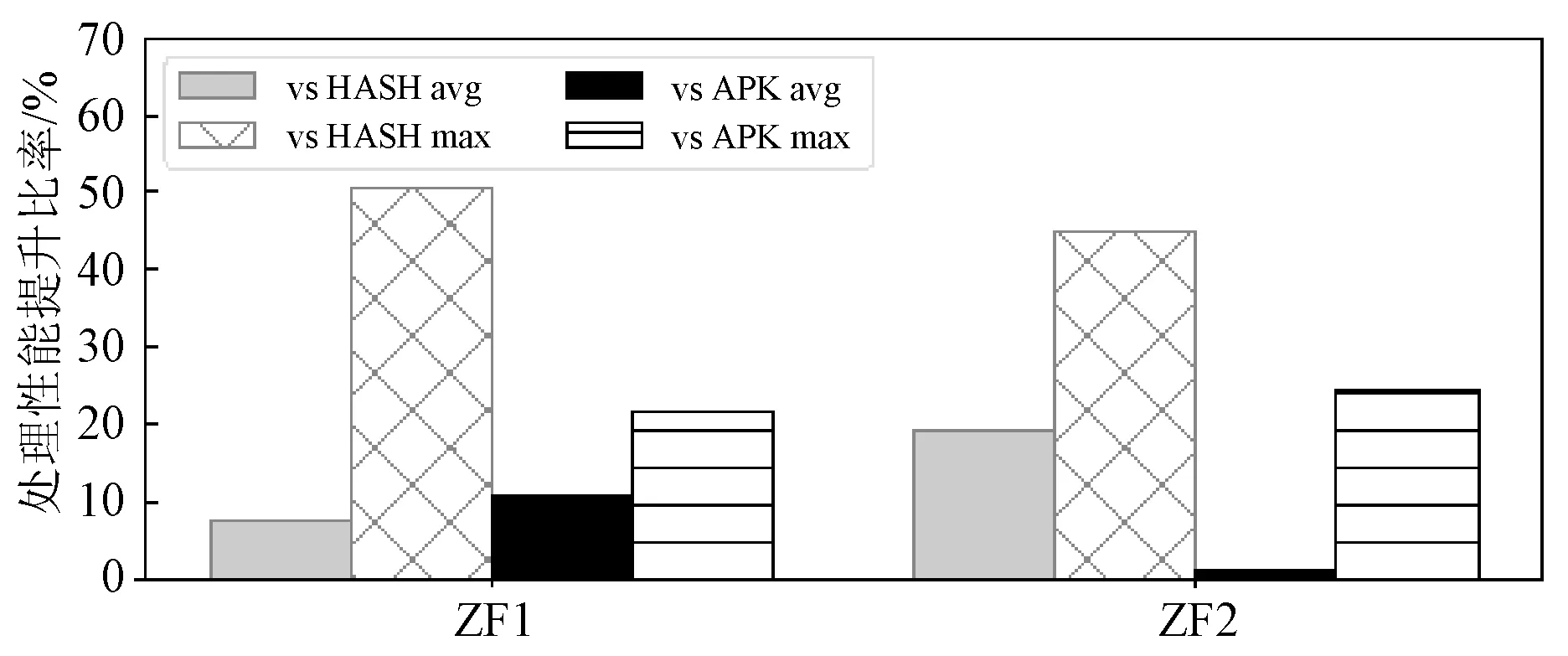
图7 在ZF1和ZF2上使用APS获得的性能提升
实验表明,在对拥有不同数据特征偏移的流数据集进行分布式处理时,相比于候选集中的静态数据分发方法,APS能让整体处理性能获得巨大的提升。
4.3.2 不同任务类型对APS性能提升的影响
实验3使用不同的组合系数λ来表示不同的任务类型,并使用不同的λ值对ZF1数据集进行类似实验2的多次模拟。同时,实验仍然选用每个mini-batch上的整体分发评估值作为性能指标,计算APS较HASH和APK的处理性能提升比率。实验假设,处理任务中键值分离产生的性能开销与λ的值成正比。
图8展示了APS在不同组合系数λ中的表现结果。λ的值越大,APS较HASH的提升比率越低,较APK的提升比率越高;λ的值越小,APS较HASH的提升比率越高,较APK的提升比率越低。
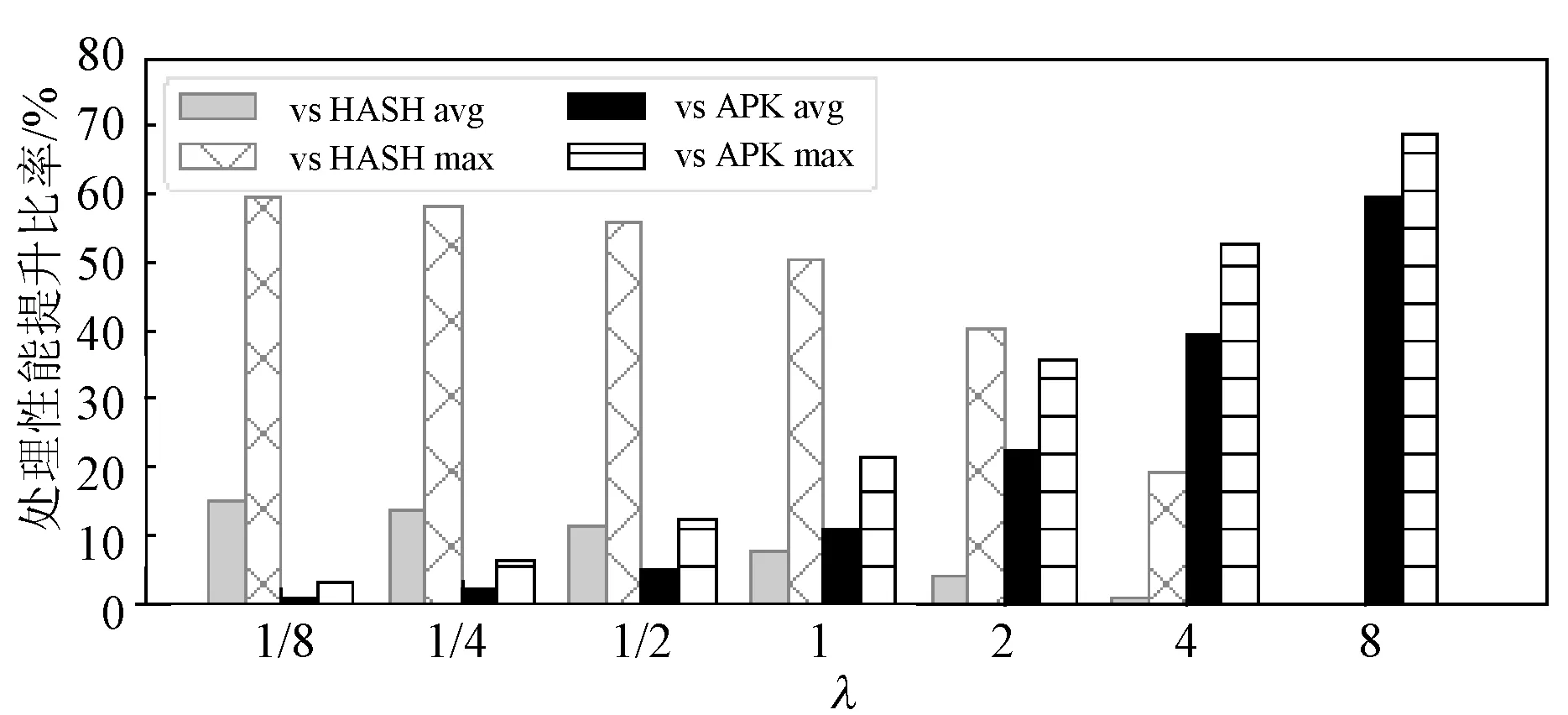
图8 在不同任务类型中使用APS获得的性能提升
实验表明,当处理任务中键值分离的开销很高时,APS相比产生键值分离的APK有巨大的性能提升,故倾向于调整为HASH。当处理任务中键值分离的开销很低时,APS相比负载偏移较多的HASH有巨大的性能提升,故倾向于调整为负载更加均衡的APK。
5 结 语
本文提出了一种叫做自适应数据分发策略(APS)的分发方法,为基于mini-batch的分布式流处理任务提供更好的性能表现。同时,本文还为数据分发方法的表现性能提供了一种叫作整体分发评估的估计方法。
通过真实数据集上的实验分析,本文验证了APS相比现有被广泛使用的静态分发方法的优越性和整体分发评估的准确性。通过模拟数据集上的实验分析,本文进一步分析了APS在不同实验设定下的表现能力。
