融合气象参数及污染物浓度的空气质量预测方法
2018-08-15万永权徐方勤燕彩蓉苏厚勤
万永权 徐方勤 燕彩蓉 苏厚勤
1(上海建桥学院计算机科学与技术系 上海 201306)2(东华大学计算机科学与技术学院 上海 201620)
0 引 言
空气污染一直影响着自然环境和人类健康,而且从长远来看,它还会加剧对地球的危害。作为一种可靠而有效的污染控制措施,空气质量预测已成为近年来一个重要研究领域[1-4]。
传统方法多采用数值预测模型和回归统计模型。前者主要依赖于污染物浓度数据本身,后者则主要通过分析大量影响污染物浓度的因子,建立这些影响因子与污染物浓度之间的线性或非线性关系,预测的准确度主要依赖于数学模型本身[1]。人工神经网络是使用最广泛的空气质量预测模型,通常采用污染物浓度作为主要输入,然后输出第二天或下一个时间段的平均空气质量指数AQI(air quality index)[2]。BP神经网络虽然应用广泛,但存在收敛速度慢和易陷入极小值的缺陷,相关研究将混沌变量加入遗传算法来进一步提高遗传算法的全局搜索能力和收敛速度,将混沌遗传算法优化后得到的最优解作为BP神经网络的初始权重和阈值[3]。为了更准确地描述和预测某区域的空气质量,可以采用多个站点来收集数据,并且通过多个污染物来综合评估空气质量,预测其AQI值[4]。随着物联网的发展,基于大数据的空气质量指数预测方法成为研究热点,即通过大量历史数据,分析空气质量变化规律,然后结合实时采集的数据,建立预测模型[5]。为了进一步提高预测准确度,一些混合模型或算法被提出,如将BP网络和小波分解模型相结合[6],将差分进化算法DE、集成经验模态分解的改进算法CEEMD和极限学习机ELM相结合[7],采用模糊综合评估模型[8]。虽然这些混合模型相比单一模型具有更高的精度,但由于污染物浓度受多种因素影响,使用单一污染物浓度数据源作为输入进行预测的效果也会受到限制,而且数据的时序性在预测时也是一个非常重要的关系[9-10]。本项目组研究发现气象参数对污染物浓度的变化有较大的影响,而且不同污染物受不同气象参数的影响程度也不同[11]。
考虑到空气污染物受到各方面的影响,而且变化快,所以本文主要研究短期的(每小时)污染物浓度预测,在建模时利用序列预测、相关性分析和神经网络模型,采用气象参数和各项污染物浓度数据作为输入,以此提高预测准确度,在模型训练时采用更大的数据集进行模型参数学习。
1 气象参数与污染物浓度相关性分析
气象参数通过给定时间内大气状态采样来获得。主要气象参数包括温度、湿度、风向、风速、气压、太阳辐射、降水等,本文主要分析前5个。为了分析他们之间的关系,采集2015年-2016年上海市每天发布的5个气象参数。给定随机变量x和y,它们之间的相关系数定义为:
(1)
式中:Cov(x,y)表示x与y的协方差,V(x)为x的方差,V(y)为y的方差,ρ表示x和y的相关程度。
ρ取值范围为[-1,1],ρ≤0表示两者无关,ρ>0表示两者相关,当ρ>0.3时,可以认为两个参数之间存在强相关。表1列出了5个气象参数之间的相关系数。

表1 各气象参数之间的相关关系
根据计算产生的气象参数之间的相关系数,可以在构建神经网络时选择合适的输入,不仅可以减少模型训练的参数,而且也避免了不必要的参数对预测结果产生的负面影响。
空气质量预测主要通过空气污染扩散模型测量或计算大气污染物浓度。中国大陆的AQI是根据6个大气污染物浓度来计算,即二氧化硫(SO2)、二氧化氮(NO2)、一氧化碳(CO)、臭氧(O3)、空气动力学当量直径小于等于2.5微米的颗粒物(PM2.5)、空气动力学当量直径小于等于10微米的颗粒物(PM10),通过在每个城市的环境监测站对它们进行测量。如空气质量指数为0~50时,表示空气质量级别为I级,空气质量状况属于优,此时不存在空气污染问题,对公众的健康没有任何危害。
根据2015年-2016年上海市某站点监测的每天24小时的污染物状况和同期气象参数数据,采用SPSS工具提供的“分析-回归-自动线性建模”,绘制了气象参数对污染物浓度的影响,如图1所示。由此图可知,风速对NO2、PM2.5和PM10的影响最大,湿度对O3和SO2的影响最大,CO主要受温度和风速的影响。然而,空气压力对SO2、NO2、PM2.5和PM10的影响最小,风向对CO和O3的影响最小。风向对CO和O3的影响最小。
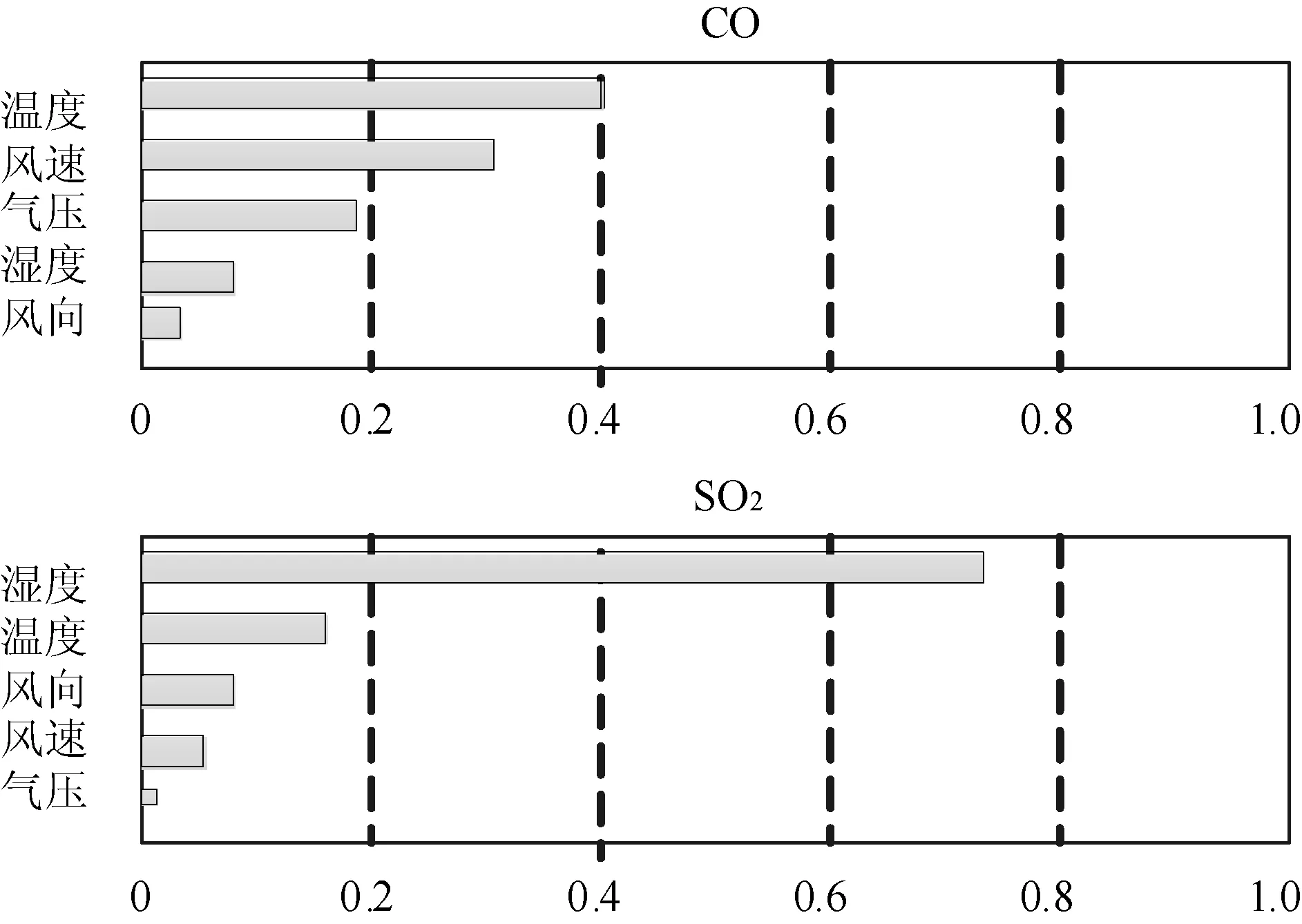

图1 气象参数对污染物浓度的影响程度
2 空气质量预测方法
根据气象参数和污染物浓度之间的数据分析,提出空气质量预测系统框架,如图2所示。该框架由3部分组成。第1部分是数据生成,包括两类数据,污染物浓度数据和气象参数数据,它们都需要进行预处理,如归一化处理、空值填充和异常值检测。第2部分为模型构建与训练,预测模型是本方法的重点,使用历史数据集来训练模型,数据集被分成3份:训练集、验证集和测试集。第3部分为模型服务,验证后的模型及其参数将被保存,并提供在线预测功能。
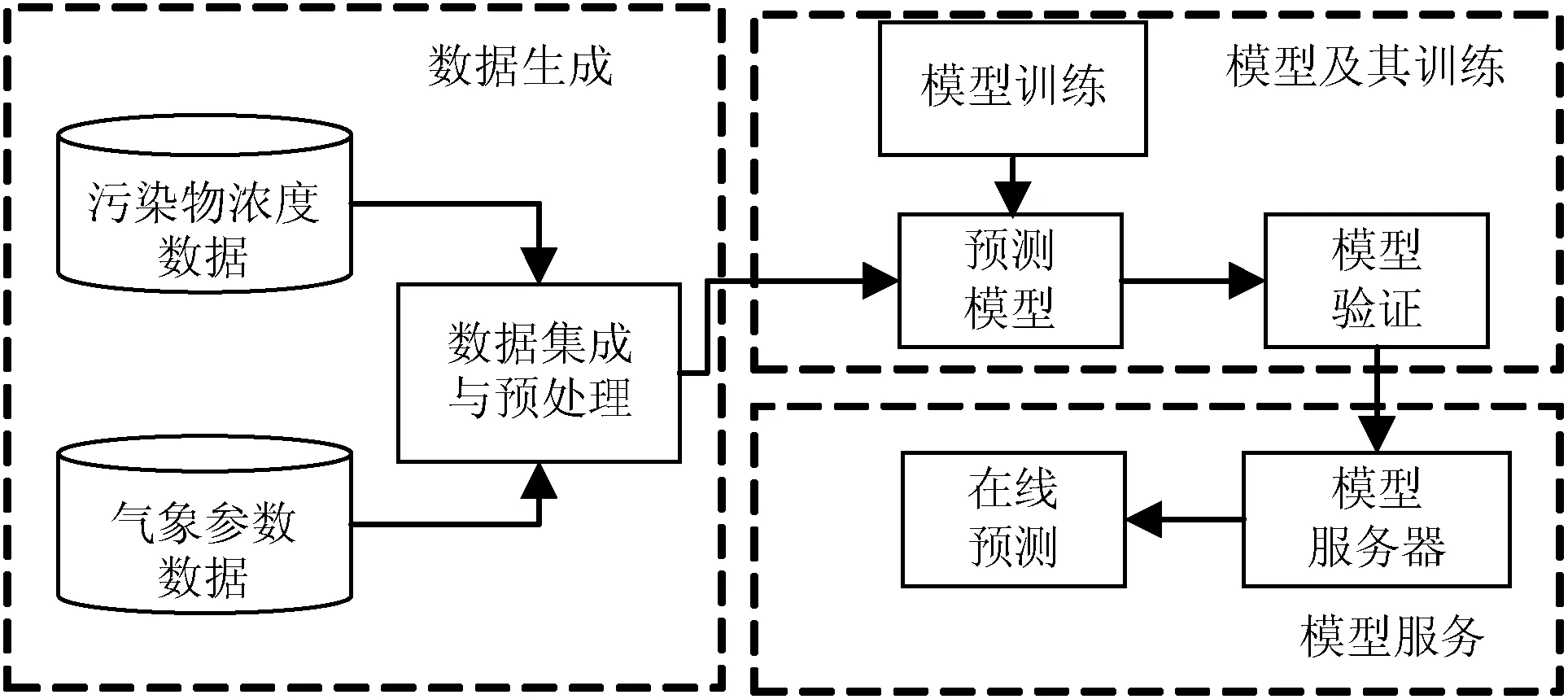
图2 空气质量预测框架
在此框架下,具体的预测步骤描述如下:
1) 收集数据。5个气象参数数据从上海市气象局官网采集,每天一次;污染物浓度数据从监测站点获得,每小时都能获取最新的6个污染物浓度数据。所以每条气象参数记录的更新频率为一天,每条污染物浓度记录的更新频率为一小时。
2) 数据预处理。首先是归一化处理,若数据x被归一化的结果为Norm(x),xmin表示该数据出现的最小值,xmax表示该数据出现的最大值,计算方法如下:
(2)
当出现数据空值的情况时,对于污染物浓度数据,因为相差只有1个小时,所以直接采用上一个历史数据进行填充;对于气象数据,每天的变化比较大,所以采用最近一周的平均值来进行填充。
当出现数据值异常时,如温度超过50度,这时将与数据出现空值时采用相同的策略进行填充。
3) 数据相关性分析。分析5个气象参数内部以及与污染物浓度之间的关系,发现参数之间的强相关性和弱相关性。
4) 第一阶段神经网络模型。采用气象参数作为输入。对于隐藏层中的每个节点,输出可以表示为:
a(l+1)=f(W(l)a(l)+b(l))
(3)
式中:l代表层数,f是激活函数,选用relu。参数a(l)、b(l)和W(l)分别表示上一层输出的激励、偏置项和模型第l层的权重参数。模型采用relu激活函数的原因在于:它不会出现像sigmoid函数和tanh函数一样的梯度消失现象。此外,由于它是线性的,只需要一个阈值就可以得到激活值,不需要复杂的运算,所以使用relu得到的随机梯度下降算法的收敛速度会比sigmoid和tanh快。
5) 第二阶段神经网络模型。输入包括:4)的输出结果、根据3)选择的重要气象参数,以及需要预测的污染物浓度的历史序列。也就是说,不同的污染物浓度预测,其模型结构相同,但是输入不同,而且需要学习的权重也不同。输出为该污染物在下一个小时内的浓度预测值。
6) AQI计算。根据各污染物浓度预测值,采用相关公式,计算新的AQI值。
本方法通过预测污染物浓度来预测AQI值,而不是直接通过模型来预测AQI值。
3 预测模型
根据预测框架,预测模型也分为两个神经网络模型单独进行,而且不同的污染物浓度的预测也是独立进行,最终的输出结果是污染物浓度预测值。为了方便表述,本文提出的预测方法称为two-phase neural network (2-NN),采用的相关模型称为2-NN模型,见图3。
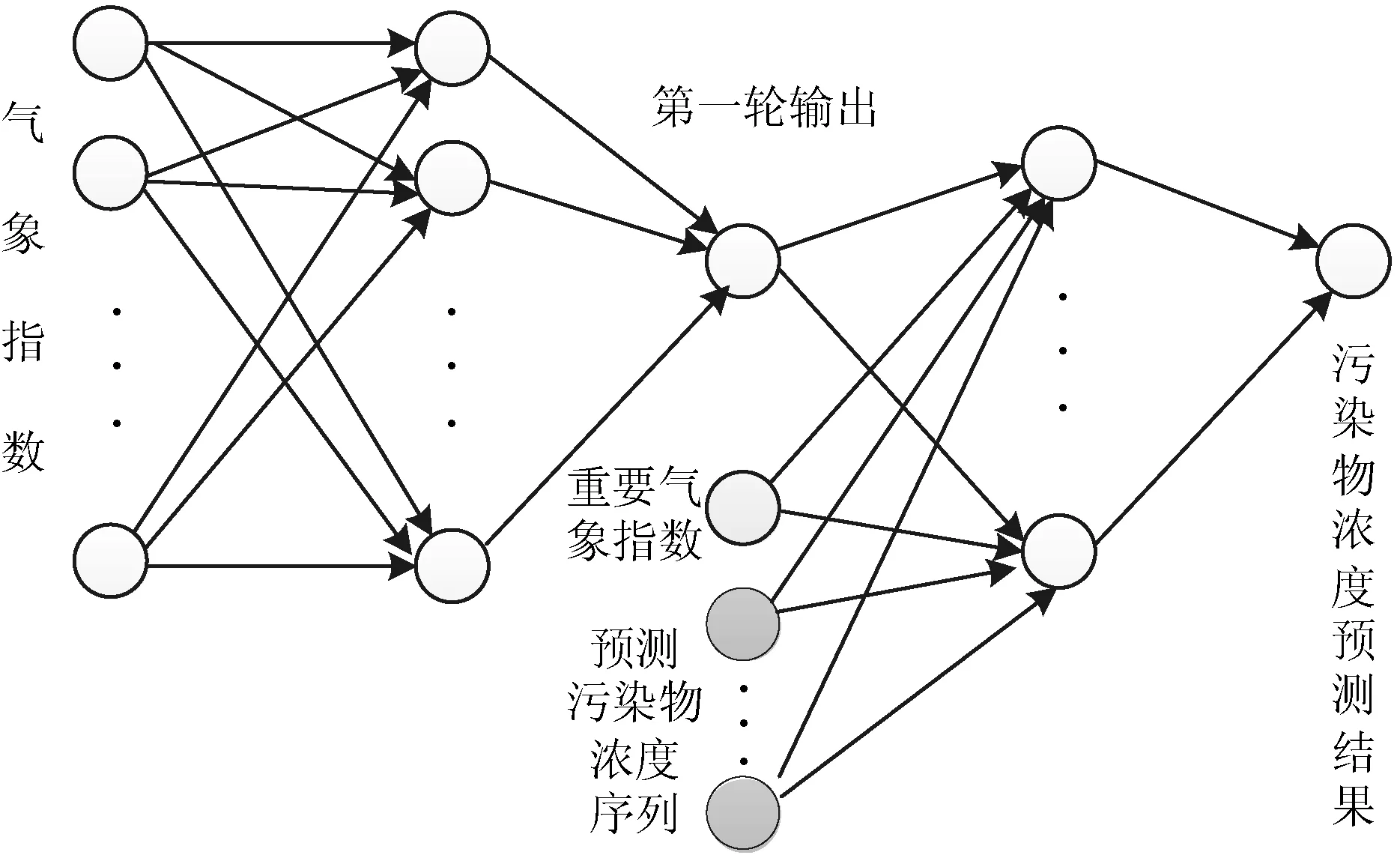
图3 预测模型结构
模型训练过程中,当数据学习过于彻底时,会产生噪声特征,将影响后期的预测效果,即模型对训练数据表现良好,但对未知的数据表现则不佳,出现了过拟合现象。
导致过拟合原因包括:1) 数据不纯,需要重新清理数据;2) 训练数据量太少,或训练数据占的比例太小,也可能出现过拟合。解决方法可以有:对数据进行预处理;增加训练的数据量;采用L2正则化方法;采用Dropout方法。Dropout方法在ImageNet方法中提出,而后在神经网络中也被广泛使用。本文在训练模型时综合采用以上几种解决方法来避免模型训练的过拟合现象。
4 实验结果
4.1 实验准备
实验使用两个数据集,分别为上海市某环境监测站采集的每小时空气污染物浓度数据和上海市气象中心发布的每日气象参数数据。所有数据将通过归一化、空值填充和异常值检测等方法进行预处理,使得数据尽可能完整,总记录数约为17 500条。
数据以6∶2∶2划分为训练集、验证集和测试集。采用均方根误差RMSE和均方误差MSE作为预测准确度评估,两者定义如下:
(4)
(5)

通过与本领域相关的几个经典方法进行比较来评估本文的方法。经典方法包括:1) 支持向量机(SVM),这是一种基于隐式反馈数据集的个性化排序方法,它使用标准的矩阵分解进行潜在预测,实验采用3种模型,分别为SVR、NuSVR和LinearSVR;2) 神经网络,每个稀疏和高维的分类特征首先被转换成低维和密集的实值向量,这些低维密集嵌入向量与连续特征级联,然后被送到前向通道中神经网络的隐藏层,实验采用3种模型来优化,分别为sgd、lbfgs和adam;3) K最近邻(KNN),这是具有交叉特征列的线性模型,利用加权平均值实现KNN回归算法,实验分别采用K=2、5、10来进行测试;4) 本文方法2-NN。
所有实验在一台具有28核的Linux服务器中通过Python语言编程完成计算。该服务器配置为Inter®Xeon®E5-2407 CPU @ 2.40 GHz处理器,64 GB内存。为了进行公平的比较,对所有方法使用相同的数据。
4.2 结果与评价
表2所示为不同方法对6个污染物浓度的预测准确度比较,表中数据为实际测试数据的再乘以1/100。从表中可以看出,本文方法相比其他方法具有更高的准确度。
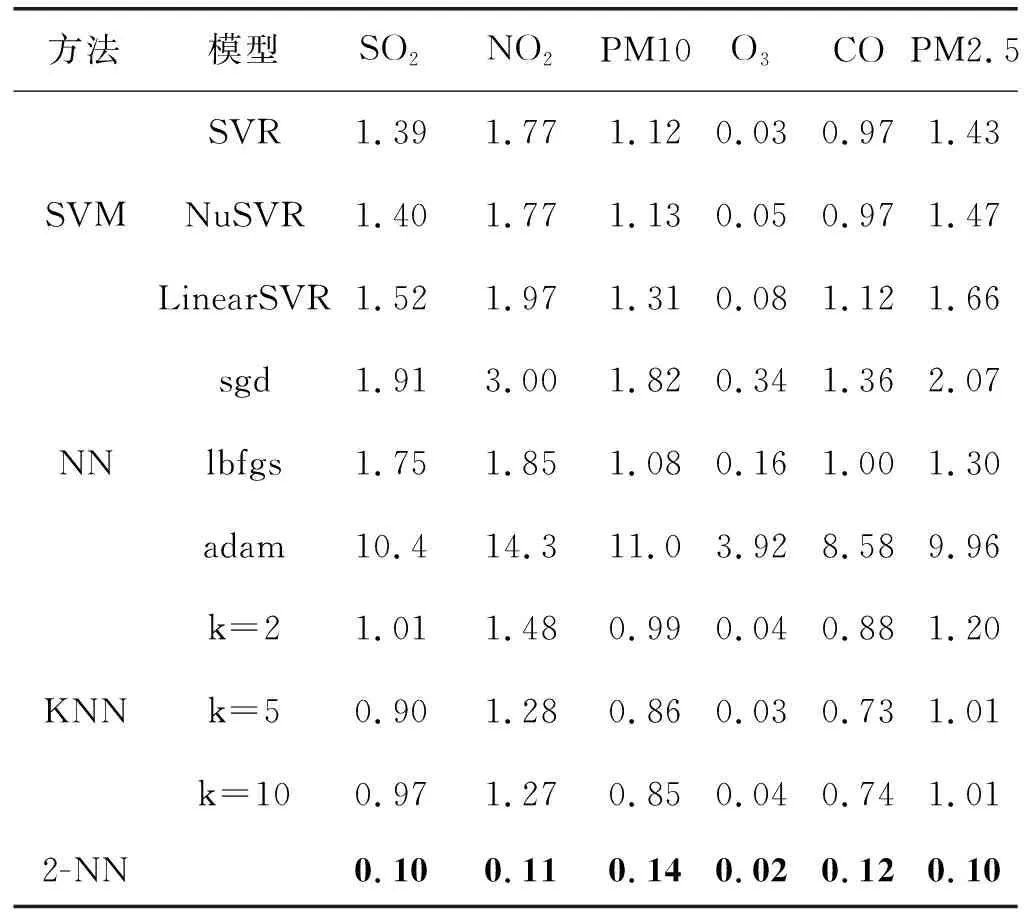
表2 不同方法对6个污染物浓度的预测准确度比较
图4所示为采用不同序列长度的污染物浓度数值对预测结果的影响。可以看出,不同污染物浓度对历史序列的依赖性不同。根据分析,本文主要采用最近2个时间点的序列数据作为参考。
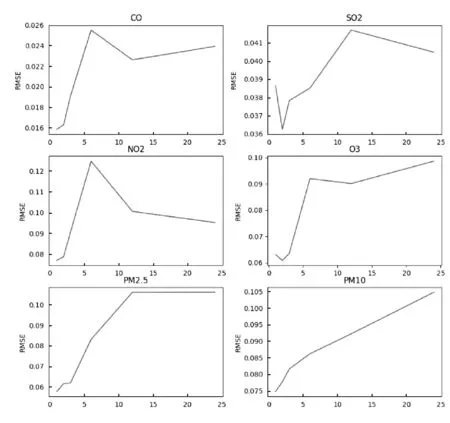
图4 不同序列长度下6个污染度浓度的RMSE比较
污染物浓度预测最终是为了预测空气质量。为了更好地说明本文方法的优势,采用三种方法分别对AQI进行预测,分别为:1) 长短期记忆网络(LSTM),一种递归神经网络模型,具有独特的结构,适合处理预测更长的时间间隔;2) BP神经网络BPNN;3) 本文方法2-NN。
AQI是政府机构用来向公众传达目前空气污染程度的数字。随着AQI值的增大,越来越多的人群可能健康遭受影响。AQI的计算公式为:
(6)
式中:C表示污染物浓度(记录或预测),Clow和Chigh表示污染物浓度的最低和最高值,Ilow和Ihigh是污染物指数的最低和最高值。Clow、Chigh、Ilow和Ihigh都是常数,由环境空气质量指数(AQI)技术规定(试行)(HJ 633-2012)。
图5所示为不同方法在预测AQI时的准确度比较。从中可以看到本文方法比其他两个方法的预测效果更好。

图5 不同方法的AQI预测准确度比较
5 结 语
本文提出了一种空气质量预测方法。该方法综合考虑气象参数以及污染物浓度之间的相关关系,对历史大数据进行分析,采用两级神经网络模型,根据预测的每小时空气污染物浓度来计算空气质量指数。通过与其他经典方法的对比实验表明,本文方法能够更准确地预测每小时空气污染物浓度和AQI值。
影响污染物浓度的因素特别多,除了气象参数,还有季节因素、交通状况等等,为了获得更准确地空气质量指数预测值,下一步还需要研究更多的数据,从而发现更准确的规律。
