基于Python的并行编程技术在批量气象规范报表入库处理中的应用
2018-08-13郭学兵
郭学兵
基于Python的并行编程技术在批量气象规范报表入库处理中的应用
郭学兵
(中国科学院地理科学与资源研究所生态系统网络观测与模拟重点实验室,北京 100101)
为满足中国生态系统研究网络(英文全称Chinese Ecosystem Research Network,简称CERN)对大批量气象规范报表(Excel格式)进行高效快速转换并载入数据库的需求,作者在对当前流行的并行编程方法和技术进行对比研究的基础上,提出了利用Python的多进程编程技术实现报表处理的方案,建立了CERN气象规范报表的抽象数据转换模型,并编写了多进程并行处理程序,实现了将大批量气象报表的快速转换载入Oracle数据库的功能。同时,作者对多进程编程的不同参数设置情景下的转换效率进行了测试、比较和分析。实验结果显示,利用Python并行编程技术可以充分利用计算机硬件的潜力和性能,从而大大提高处理效率,且方法简便、事半功倍。作者最后进一步建议通过利用Parallel Python软件包,可更充分利用计算机多核性能,更大程度提高处理效率。更加满足CERN日益增长的数据快速处理需求。同时本文为类似数据处理需求提供了可借鉴的参考方案。
中国生态系统研究网络;CERN;python;并行编程;多进程;气象;报表;转换入库
0 引言
中国生态系统研究网络(英文全称Chinese Ecosystem Research Network,简称CERN)始建于1988年。目前,CERN包含覆盖全国主要类型区(农田、森林、草原、荒漠、湿地、湖泊、海湾生态系统等)共计44个野外生态站,另有水分、土壤、大气等5个学科分中心和1个综合中心。CERN与美国长期生态研究网络(US LTER Network)和英国环境变化网络(ECN)并列成为世界最为重要的国家级生态系统网络,是中国生态学领域的重要观测、研究、示范基地[1]。
CERN以野外生态站为基础单元开展各类生态系统中水分、土壤、生物、大气环境要素的长期观测,产生的数据由相关各方(产生者—生态站,质量控制者—学科分中心,数据集成者—综合中心)按照统一规定的数据监测规范及信息规范,对数据进行相应处理并实现生态站-分中心-综合中心逐级质量控制和数据报送。综合中心是所有生态站、各类环境要素数据的最终集成单位,因此综合中心必须通过开发软件系统,实现这些数据的快速处理、入库及网上发布共享等整套业务的长期稳定运行,以便为我国生态与环境保护、资源合理利用和国家可持续发展及应对全球变化等提供长期、系统的科学数据和决策依据[1]。
CERN传统气象数据报表转换入库处理程序采用微软Windows环境下OFFICE COM对象(Component Object Model)的面向对象编程方法,在Microsoft Visual Foxpro6.0编程环境下实现对Excel文件的读写(显式或隐式运行Excel 应用,操作工作薄、工作表对象,实现数据存取操作等),实现从Excel数据到VFP数据库表(.dbf文件)的数据移动[2]。然后再将.dbf文件数据表升迁到Oracle数据库。
这种传统的数据处理方法需要不断地进行I/O处理,因此造成处理时间过长[3],不能充分利用计算机性能,导致数据处理效率低下(CERN单一指标的数据处理大约耗费半小时)。
随着CERN野外生态站个数、监测指标个数不断增加等情况出现,数据采集正朝着海量化方向发展,这对数据处理和质量控制的效率提出了更高挑战;同时,计算机硬件技术也日新月异地发展,处理器性能不断提高,且多核处理器已成为当前处理器技术的发展方向,这些硬件变化的同时引领软件研发发生了基础性变化。基于多核的并行处理是充分发挥多核CPU强大运算能力的有效途径,并行计算模式正成为当前及未来程序开发的发展趋势,具有十分广阔的应用价值[4]。
传统程序基本上是为顺序处理器书写的,大部分程序在多处理器上不能直接获得加速,不再适应新形势下的数据处理需求。解决这一问题的途径之一是使用多处理器并行处理技术把顺序程序转换为并行程序[5],才能充分利用目前多核计算机等提供的计算资源等。
本文主要针对CERN生态站大批量的由自动气象观测站采集的固定格式Excel数据报表,进行快速转换并入库的并行处理技术方法进行分析、研究、实践验证。作者首先对当前流行的并行编程方法和技术进行了对比研究,提出了基于Python多进程编程技术实现报表转换入库的构。然后建立了CERN气象规范报表的抽象数据转换模型,利用Python2.7编写了多进程并行程序,实现了气象规范报表的快速转换及载入Oracle数据库功能,并对多进程编程的不同参数设置情景下的转换效率进行了比较和分析。结果表明基于Python的并行处理技术极大提升了应用程序的运行效率,充分发挥了计算机硬件性能。
1 多线程并行程序设计方法概述
根据对并行处理技术的综述性文献内容进行归纳总结,多线程并行程序设计方法目前主要包括以下几种[6]:
(1)显示线程编程
并行编程可以调用系统函数启动多线程,例如:Pthreads、Java线程类、微软Widows线程API。
(2)利用并行编程模型的编译器指导的编程
◊ OpenMP:OpenMP是一种面向共享内存的多处理器多线程并行编程模型,为在共享存储的多处理机上编写并行程序而设计的应用编程接口,运行在单机多核并行计算环境下。由一个小型的编译器命令集组成,包括一套编译制导语句和一个用来支持它的函数库。OpenMP 的编程模型以线程为基础,通过编译指导语句来显示地指导共享内存的多线程并行化,为编程人员提供了并行化的完整控制。通过与标准Fortran,C和C ++结合进行编程[5]
◊ Intel TBB:Intel Thread Building Block编译器
(3)利用并行应用库编程
◊ Intel IPPMKL,ScalaPACK、PARDISO
◊ MPI:MPI(Message Passing Interface)是基于消息传递的并行编程模型。消息传递指的是并行执行的各个进程具有自己独立的堆栈和代码段,作为互不相关的多个程序独立执行,进程之间的通信通过显式地调用通信函数来完成[7]。它用于非共享内存(即分布式共享内存)的集群计算环境,是用于计算机集群的编程技术。
(4)并行程序语言编程
目前有150种以上并行编程语言,其中Python是著名的一种并行程序开发语言,有进程池概念,不用自己创建进程。
(5)MapReduce
MapReduce是一种基于Google云计算平台的分布式编程模型,其云计算基础架构包括3个相互独立又紧密结合的系统(分布式文件系统GFS、并行编程模型和任务调度模型MapReduce、处理结构化以及半结构化数据的大规模分布式数据库Bigtable)。Apache Hadoop是一种由Java语言编写的运行在Linux 操作系统之上的开源云计算平台,由HDFS(Hadoop Distribute File System)和Hadoop MapReduce 两个核心部件组成,二者分别是GFS 和Google MapReduce的开源实现,Hadoop目前已经成为大数据领域事实上的标准[8]。
综上所述,目前并行程序设计方法非常多样化,而且仍处于不断发展之中,并无固定不变的定式。并行程序设计方法支持不同的开发环境,开发复杂度及开发成本相异,适宜处理不同规模及特征的数据与处理方法,可分别满足不同的并行处理流程、应用场景需求。
本文重点讨论应用Python面向对象的动态的高级程序设计语言,基于其并行程序编程方法以及强大科学计算功能而开发并行处理程序,实现CERN批量气象规范报表的快速转换入库的方法和技术。
2 Python并行编程
Python是一种模块化设计的,具有简洁和高可读性语法的高级编程语言,且支持多种方式的并行编程。基于Python语言的并行编程技术发展至今,形成了5种模式,分别是:异步编程模式、分布式并行模式、GPU并行模式、基于多线程的并行模式和基于多进程的并行模式。其中,异步编程模式适用于因复杂任务中的子任务争夺运算资源,而需要在程序运行期间协调CPU使用权的情况;分布式并行模式应用于集群运算;GPU并行模式则应用于图4形及科学运算。这两种模式均不适合CERN的气象数据报表转换处理的应用需求[9]。而“多线程”和“多进程”是可用于CERN气象规范报表转换处理并行化运行的主要实现方式。
Python由于全局锁GIL(Global Interpreter Lock)的存在,Python中的多线程其实并不是真正的多线程,Python的多线程不是并行执行(物理上同时发生)而是并发执行(轮换执行,逻辑上同时发生),还不能利用多核CPU[10]。如果想要充分使用多核CPU的资源,Python3.4中的 Parallel Python包可支持多CPU并行计算。
在Python2.7中使用多进程,它通过采用子进程的技术避开GIL,使用multiprocessing进行多进程编程提高程序效率。Python提供了非常好用的多进程包multiprocessing,可轻松完成从单进程到并发执行的转换,只需要编程人员定义一个函数,Python会完成其他所有事情。Multiprocessing支持子进程、通信和共享数据、支持执行不同方式的同步,提供了Process、Queue、Pipe、Lock等组件来支持对程序并行化的控制。
3 CERN气象规范报表数据处理流程及并行化方法分析
3.1 数据转换抽象模型
(1)待处理报表源文件(from_Sheet)
待处理的CERN气象规范报表每年包含待528个待处理文件(每年44个生态站,12个月/生态站),每个excel文件中包含共计26个指标的sheet,分别存储气温(T)、气压(P)、海平面气压(P0)、降水(R)、相对湿度(RH)、地表温度(Tg0)、1小时风速(W60)、10分钟极大风速(W10M)、2分钟平均风速(W2)、10分钟平均风速(W10A)等指标的每月仪器自动记录的各日逐时数据、逐日数据(日最高、日平均、日最低等)、逐月数据(月最高、月平均、月最低等)等子指标[11]。
Excel文件命名方式:3位台站代码+4位年份+2位月份。例如AKA201401.xls表示阿克苏站2014年1月的观测数据文件。
(2)转换目标表(to_Table)
每个指标的sheet数据将被转换分解为三个有待载入Oracle数据库表的子指标,例如气温(T)sheet最终将被转换为3个子指标:小时尺度气温(T1)、日尺度气温(T2)、月尺度气温(T3),它们分别是二维关系数据表的格式,其数据项的说明字典如下:
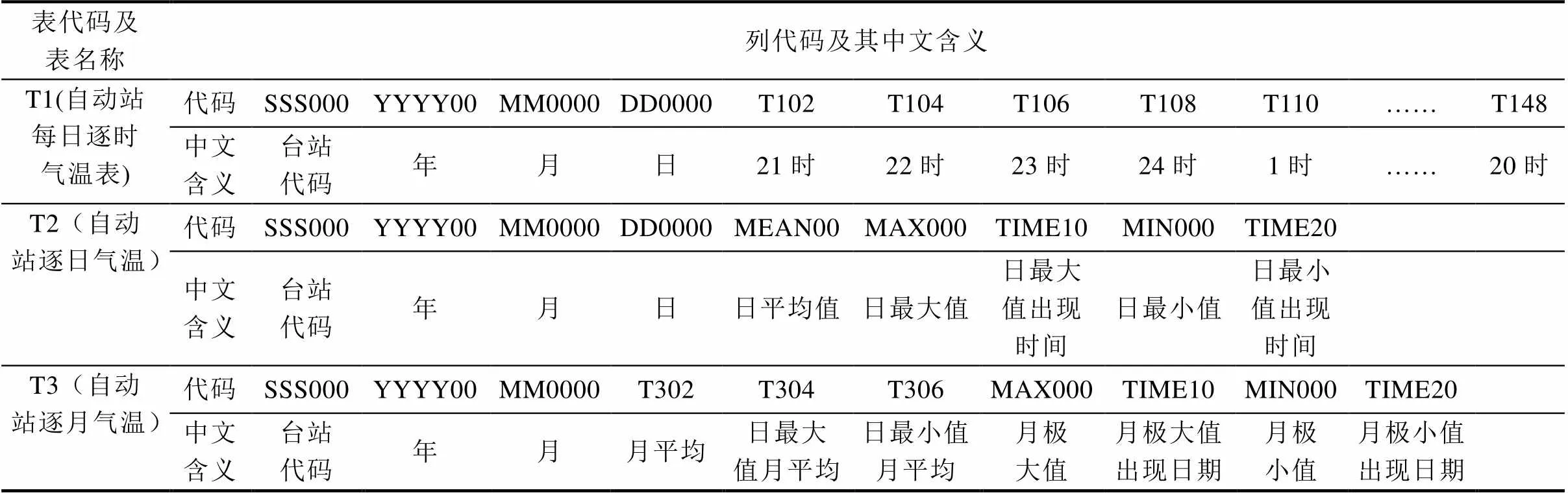
表代码及表名称列代码及其中文含义 T1(自动站每日逐时气温表)代码SSS000YYYY00MM0000DD0000T102T104T106T108T110……T148 中文含义台站代码年月日21时22时23时24时1时……20时 T2(自动站逐日气温)代码SSS000YYYY00MM0000DD0000MEAN00MAX000TIME10MIN000TIME20 中文含义台站代码年月日日平均值日最大值日最大值出现时间日最小值日最小值出现时间 T3(自动站逐月气温)代码SSS000YYYY00MM0000T302T304T306MAX000TIME10MIN000TIME20 中文含义台站代码年月月平均日最大值月平均日最小值月平均月极大值月极大值出现日期月极小值月极小值出现日期
(3)数据转换抽象模型
数据转换抽象模型主要定义了源sheet、转换目标表、以及各目标表源数据存储区段序列。数据存储区段序列由1~n个区段组成(区段是excel中一片连续的区域),每个区段由区段顺序编号、起始列、终止列、起始行号、终止行号定义。终止行号为“dpm”意味着终止行需要依据不同年份每月所含日数不同计算而定。下表是气温(T)指标的数据转换抽象模型示例。其他指标定义与此类似。
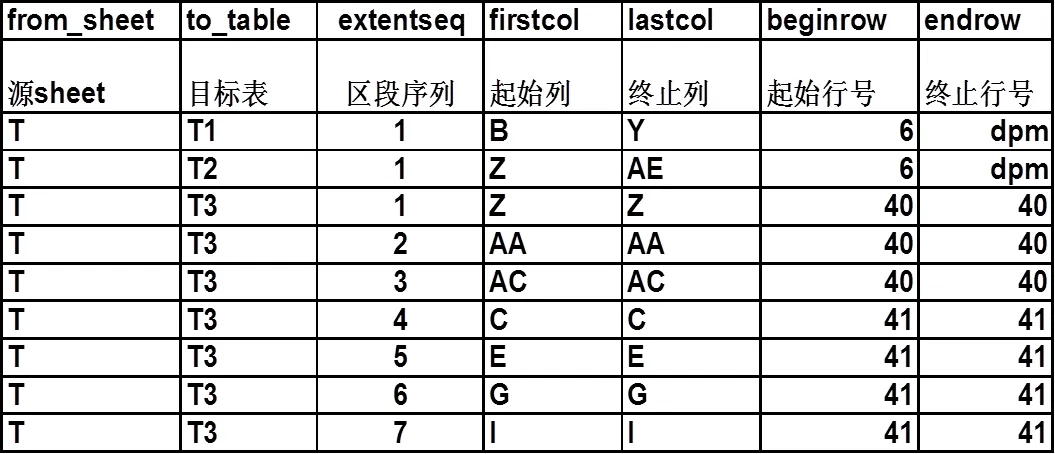
图2 数据转换抽象模型示例(气温T为例)
3.2 数据转换入库方法和流程
(1)数据转换过程
循环处理各生态站(第一层循环)、各年份(第二层循环)、各指标(第三层循环)。
在各个指标的循环中将当前生态站、当前年的1-12月excel数据进行逐月顺序处理,分别写入小时值、日值、月值的合并后数据文件(例如T1.csv、T2.csv、T3.csv),并生成相应的控制文件(例如T1.ctl、T2. ctl、T3. ctl)。写入过程中进行质量控制,将“-”、“//”等符号去掉替换成空。
(2)数据入库过程
将每年的所有生态站的报表源数据528个读入内存数组→进行转换(添加生态站代码、年、月、日等信息)→然后合并后产生子指标目标表文件.csv。方法是:生成各个子指标目标表格的sqlldr命令控制文件和数据文件[12]。
采用Sqlldr命令将合并后数据文件装入Oracle数据库,最终共生成78张目标表格:
例如气温日值表T2的控制文件T2.ctl(里面引用气温日值数据文件T2.csv)示例如下:
OPTIONS(SKIP=1,ROWS=16061)
LOAD DATA
INFILE "T2.csv"
insert into table T2
Fields terminated by ","
Optionally enclosed by '"'
trailing nullcols
(SSS000,YYYY00,MM0000,DD0000,MEAN00,MAX000,TIME10,MIN000,TIME20)
3.3 处理流程并行化分析及其关键技术
(1)数据转换过程的并行化方法分析
通过整个转换过程的流程分析,为了减少并行进程之间的通信开销、减少文件I/O次数及读写共享冲突,决定对指标分门别类进行并行化。因为CERN报表源按照其不同存储格式可分为4类,分别编写每类报表的转换程序代码,这些代码分别作为函数传递给多进程并行处理程序,从而使得程序并行处理实现快速转换。4类程序包括:
● run_other程序处理气温、湿度、气压、降水、土壤温度……等一类报表;
● run_W60_W10M程序处理1小时风、10分钟极大风等一类报表;
● run_W2_W10A程序处理2分钟平均风、10分钟平均风等一类报表;
● run_Radi_D5程序处理辐射小时类数据一类报表。
以此类推,可扩展处理所有类别报表。
(2)数据转换函数代码编写
以run_other函数为例,其输入参数为:报表源sheet名、生态站代码、年份共三个参数。程序需要导入Pandas数据包(import pandas as pd)、Numpy数组包(import numpy as np)。Numpy(Numerical Python)数组包提供了python对多维数组对象的支持,但它缺少数据处理分析所需的许多快速工具,Pandas(Python Data Analysis Library)基于NumPy开发,Pandas提供了大量快速便捷地处理大型数据集(比如Excel文件读写)所需的函数和方法,使得Python成为强大而高效的数据分析处理环境[13]。Numpy和Pandas二者结合起来可以非常方便地实现报表源数据到目标数据文件的快速转换。
代码主体主要顺序逐月处理12个月的数据报表源Excel文件,按照抽象数据模型将Excel文件的数据读入内存数组,并利用Numpy数组包进行内存数组的各种操作(插入行、列),然后将处理好的内存数组写到与数据字典结构一致的.csv数据文件及相应的控制文件.ctl。run_other函数主要用于温度、湿度、气压、降水、土壤温度等具有同样格式的sheet的处理。
(3)并行化关键技术
实现“多进程”编程首先要导入multiprocessing站点包,建立进程池pool,并将待并行运行的代码以函数形式传递给进程,实现动态映射任务,从而实现并行。其核心代码如下:
import multiprocessing as mp #-----导入多进程支持模块
from multiprocessing import Pool #-----导入多进程支持模块下的进程池
通过建立多进程mp的进程池pool,可以提供指定数量的进程供用户调用,当有新的请求提交到pool中时,如果池还没有满,就会创建一个新的进程用来执行该请求;如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来执行它。
下面例子展示了对前3类报表进行并行化处理的代码片断。
def apply_async(): #-------非阻塞并行
#-----处理所有年份的数据,本次仅处理1年的数据
YEAR=[2014]
#-----所有生态站代码,共44个生态站待处理SITE=["AKA","ASA","SJM","HLA","FKD","NMD","SYA","LCA","YCA","SPD","FQA","CWA","CSA","YGA","TYA","YTA","QYA","CBF","BJF","GGF","GGS","HTF","DHF","HSF","BNF","NMG","HBG","JZB","THL","DHL","DYB","SYB","CLD","MXF","ALF","LSA","LZD","ESD","HJA","SNF","DTM","BJU","QYF","PYL"]
#-----申请非阻塞式并行的进程池,最大进程数processes可设为1、2、4、8、16等。以处理8个指标为例。维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去
pool = mp.Pool(processes=4)
pool.apply_async(run_W60_W10M, ("W60",YEAR,SITE,), )
pool.apply_async (run_W60_W10M, ("W10M", YEAR,SITE,),)
pool.apply_async(run_W2_W10A, ("W2",YEAR, SITE,), )
pool.apply_async(run_W2_W10A, ("W10A", YEAR, SITE,), )
pool.apply_async(run_other, ("P",YEAR,SITE,), )
pool.apply_async(run_other, ("P0",YEAR,SITE,), )
pool.apply_async(run_other, ("R",YEAR,SITE,), )
pool.apply_async(run_other, ("Tg0",YEAR, SITE,), )
#-----关闭进程池。调用join之前,先调用close函数,执行完close后不会有新的进程加入到pool
pool.close()
pool.join() #-----主进程阻塞,等待子进程的退出,join方法要在close或terminate之后使用。
#-----启动主程序,申请并行执行
if __name__ == "__main__":
apply_async()
4 并行编程运行效果分析
试验环境:4核Intel® Xeon® CPU E3-1225 v5,内存16 GB,主频3.30 GHz。Python版本2.7,处理44个生态站2014年的8个指标数据。
采用上述非阻塞式并行的进程池进行并行转换处理。最大进程数processes分别设为1、2、4、8、16、32、64个进程,对比测试并行运行时间长度,以此比较并行化执行效率,如图5所示。

图3 并行编程不同运行效果比对
结果显示:
(1)传统串行运行与并行一个进程的执行时间相差无几,甚至并行一个进程比串行执行耗费时间更长,原因是并行一个进程时,计算机为多进程处理建立进程池开销反而超过了串行进程;
(2)并行处理显著加快了处理效率,并行4个进程的处理效率基本上是传统串行的执行效率的4倍。
(3)并行4个进程时(实际上逻辑进程已达8个,达到操作系统并行进程最大数),此时转换处理时间可达最少。随后即使增加最大并行进程数,也不会减短程序耗费时间,说明已达到计算机处理的极限;
(4)并行2个进程时,此时CPU占比60%左 右,程序处理时间大约下降到并行一个进程的处理时间的一半;
(5)并行4个进程时(实际上逻辑进程已达8个,达到操作系统并行最大数),此时CPU占比已近100%,达到计算机CPU的极限;
(6)串行或并行进程数小于等于4个时,内存占比几乎不变,这是因为内存占比主要受单一指标转换处理时的内存使用率(单一指标数据量大小)影响,和进程数相关关系很小;反倒是并行进程数大于16个时,内存占比增加,主要受进程数增多导致的进程池本身内存开销增大的影响。
5 结语
试验结果表明,利用新型编程语言Python的并行编程环境和python科学计算优势,可大幅提高气象数据报表转换程序的运行效率,充分利用性能不断提升的计算机硬件设备的潜力。本文使用的Python2.7未安装Parallel Python包,故采用非阻塞式并行编程方法,此方案可充分利用单核CPU的计算能力,发挥多进程优势,实现CERN气象数据报表的高效处理。数据格式转换操作是典型的数据密集型计算任务,进程间仅有少量指令通信,通信代价微乎其微,而各子进程又单独处理计算任务,在没有读写瓶颈制约的条件下,理论上并行转换引擎可以达到子进程数量正相关的加速比[14]。
未来如果使用Python3.4以上版本,可使用Parallel Python并行编程方法,就可将转换程序运行于SMP[15](即“对称多处理Symmetrical Multi- Processing”技术,单机多核)或集群环境上,方可充分利用多核CPU,更加依托多进程优势实现CERN气象数据报表的更高效处理。
[1] 杨萍, 于秀波, 庄绪亮, 牛栋. 中国科学院中国生态系统研究网络(CERN)的现状及未来发展思路[J]. 中国科学院院刊, 2008, 23(6): 555-561.
[2] 李晓京等. C++/CLR数据库与Excel并行数据转换技术研究[J]. 计算机技术与发展. 2013, 23(7): 155-162.
[3] 王志斌. 天气雷达资料实时并行处理方法[J]. 计算机工程. 2009. 35(23): 255-257.
[4] 韩李涛, 刘海龙, 孔巧丽, 阳凡林. 基于多核计算环境的地貌晕渲并行算法[J]. 计算机应用. 2017, 37(7): 1911- 1915, 1920.
[5] 蔡佳佳, 李名世, 郑锋. 多核微机基于OpenMP的并行计算[J]. 计算机技术与发展. 2007. 17(10): 87-91.
[6] 王晗. 基于多核环境下的多线程并行程序设计方法研究[D]. 郑州: 中原工学院, 2014.
[7] 王磊. 并行计算技术综述[J]. 信息技术. 2012. 10: 112-115.
[8] 应毅, 刘亚军. MapReduce并行计算技术发展综述[J]. 计算机系统应用. 2014. 23(4): 1-6, 11.
[9] 杨霄翼. 基于Python的”地理处理”并行方案[J]. 地理信息世界. 2017. 24(6): 117-121.
[10] 熊玮. 多核并行计算技术在电力系统短路计算中的应用. 电力系统自动化. 2011. 35(8): 49-52.
[11] 中国生态系统研究网络. 生态系统大气环境观测规范[专著]。P125-129.
[12] 沈佩娟, 汤荷美. 1995. 数据库管理及应用开发, 清华大学出版社, 206-221.
[13] 张若愚. Python科学计算(第2版)[M]. 北京: 清华大学出版社, 2016, 33-341.
[14] 张帅. 栅格地理数据并行格式转换引擎[J]. 国防科技大学学报. 2015. 37(5): 9-14.
[15] 百度百科. SMP对称多处理结构. https://baike.baidu.com/ item/SMP对称多处理结构/7213852.
An Application of Python-Based Parallel Programming in Batch Meteorological Excel Sheets’ Processing and Loading into Database
GUO Xue-bing
(Key Laboratory of Ecosystem Network Observation and Modeling, Institute of Geographic Sciences and Natural Resources Research, CAS, Beijing 100101)
In order to meet CERN’s (CERN is acronyms of Chinese Ecosystem Research Network) requirements of transforming batch meteorological Excel sheets quickly and loading into database in a high performance and efficiency, The author s tudy and compare several different parallel programming technologies at present, and Python-based parallel programming method is chosen as an approach to transform batch meteorological Excel sheets and load into Oracle database. Firstly the author build an abstract data model to describe data transform structure, then edit code using python-based multiprocessing parallel programming, at last the author analyze different transforming performance under condition of setting various parameters for multiprocessing parallel programming.The study result shows that python-based multiprocessing parallel programming method can fully utilize the computer ‘s hardware potential benchmark so as to promote the transform performance. Moreover, the method is quite simple and high efficient. The author suggest that Parallel Python package should be installed and imported, multi-core computers’ performance then could be utilized thoroughly to promote CERN’s data transforming performance much better in the future. This paper also provides a reference solution for other similar data transform requirement.
Chinese ecosystem research network; CERN; Python; Parallel programming; Multiprocessing; Meteorological sheet; Transform and load into database.
TP31
A
10.3969/j.issn.1003-6970.2018.07.005
中国科学院战略性先导科技专项(A类)(XDA19020301)资助
郭学兵(1967-),女,副教授,主要研究方向:生态信息学。
本文著录格式:郭学兵. 基于Python的并行编程技术在批量气象规范报表入库处理中的应用[J]. 软件,2018,39(7):24-29
