基于U统计量和集成学习的基因互作检测方法
2018-08-06郭颖婕刘晓燕吴辰熙郭茂祖
郭颖婕 刘晓燕 吴辰熙 郭茂祖,3 李 傲
1(哈尔滨工业大学计算机科学与技术学院 哈尔滨 150001)2(Rutgers大学数学系 美国新泽西洲皮斯卡特维 08854)3 (建筑大数据智能处理方法研究北京市重点实验室(北京建筑大学) 北京 100044) (yjguo0625@gmail.com)
复杂疾病如癌症、糖尿病等,因其发病率高、治愈率低的问题,长期危害人类健康.对此类疾病遗传变异致病机理的研究是生命科学界的重大课题.全基因组关联研究(Genome-Wide Association Studies,GWAS)作为一种发现遗传变异——单核苷酸多态性位点(single nucleotide polymorphism, SNP)的新兴研究模式,自2005年《Science》杂志发表首例关于GWAS的研究成果——老年性黄斑变性以来,GWAS的研究已经超过1 800项,并发表了关于237种不同疾病研究成果,共计24 000余个SNP被证实与这些疾病显著相关[1].但对于大多数复杂遗传相关疾病而言,这些成果仅仅阐释了遗传因素很小的一部分.例如,已发现的与老年性黄斑变性、高胆固醇、阿兹海默症疾病相关的致病风险基因,分别只占相应遗传致病因素的50%,25%及23%.这一现象被称为“失踪遗传(the missing heritability)”,是目前GWAS研究的热点.该现象的发生是由于复杂疾病由多对微效基因与环境因素共同作用所致,即基因之间存在复杂的相互作用关系.而传统的GWAS主要基于单位点模型,独立检测单个SNP与给定表型之间的关系,从而导致一些存在基因互作的性状相关基因无法被单独检测出来.因此,识别与分析基因相互作用,成为解决“失踪遗传”的可行方案之一.尽管利用基因相互作用不能完全解决“失踪遗传”,但此类研究依然可以通过辅助构建新的基因通路为复杂性状的遗传与调控机理提供生物学解释.
基因相互作用又称为“上位效应”(epistasis).此概念最早由Bateson在1909年提出[2],后由Fisher进一步给出定义[3]:上位效应是指2个位点之间相互作用形式,使用2个位点建模产生的性状值与单独使用每个位点得到的性状值的和之间产生的差值来衡量上位效应的强度.后续研究中,对上位效应的定义变得更为宽泛,不同的方法对于相互作用也有不同的定义.初期的上位效应研究主要着眼于2个SNP位点间的相互作用关系.在精神分裂症、阿兹海默症、乳腺癌等复杂疾病中均有关于2个SNP之间交互作用的报道.因此产生了许多以2个SNP、或者3个SNP乃至多个SNP为研究单位的上位效应检测方法.统计类的检测方法通过设计一些表征相互作用强度的统计量,检测显著的相互作用关系,例如基于优势比(odds ratio,OR)的统计量、基于连锁不平衡(linkage disequilibrium, LD)的统计量以及基于熵的统计量等.另一类方法则采用计算机方法的思想,例如采用降维技术的多因子降维方法[4]、基于树模型的TEAM(tree-based epistasis associa-tion mapping)方法[5]、通过优化存储策略加速计算的BOOST(Boolean operation-based screening and testing)方法[6],以及BEAM(Bayesian epistasis asso-ciation mapping),pRF等.这些基于位点的检测方法面临最大的挑战是维数灾难.由于必须考虑所有的SNP或SNP组,成对或者高阶的相互作用关系检测次数随互作关系阶数呈指数级增长,随之而来的对统计显著性的校正会导致统计效力的弱化.因此,本文研究以基因为单位,将一个基因中的所有SNP看作一个组来检测基因之间的相互作用.
基于基因的相互作用研究有以下3个明显的优势:
1) 基于基因的方法可以大大减少所需的检测次数,例如,对于20 000个基因,成对检测基因之间相互作用是可行的;而对于300万SNP,成对检测显然不现实.
2) 2组基因之间可能存在多对SNP的相互作用,组内的SNP之间也可能存在连锁不平衡关系,这些同时存在的作用关系会隐性地呈现在以基因为单位的模型中,更利于相互作用的检测.
3) 基于基因的方法可以更好地利用已有的生物学背景知识,缩小研究范围.例如可以检测那些蛋白质互作网络(protein-protein interaction, PPI)中已经呈现互作关系的蛋白质编码基因之间的关系,或者某个通路内基因之间的相互作用关系.
目前,在以基因为单位的相互作用研究中,Peng等人[7]在疾病组与对照组中分别对2个基因进行典型相关性分析(canonical correlation analysis, CCA),并设计统计量CCU(canonical correlation-based U statistic)来度量2个基因在疾病与对照组中相关性指标的差异程度,用于表征相互作用的强度.该方法的局限性在于CCA只能度量2个基因之间的线性关系.Yuan等人[8]和Larson等人[9]针对Peng等人的方法存在的问题,将CCU扩展到KCCU(kernel canonical correlation-based U statistic),在做典型相关性分析之前,将核函数作用在疾病和对照组中2个基因的数据上,从而增强模型对非线性关系的解释能力.Li等人[10]提出了一种基于熵的非参数假设检验方法GBIGM(gene based informa-tion gain method).通过分析2个基因共同作用时与考虑只有单个基因时熵的变化(即信息增益),并利用随机置换类标签的方式获得相互作用的显著性p值.Emily[11]开发了AGGrEGATOr(a gene-based gene-gene interaction)方法,该方法首先计算两基因间所有SNP对的Wald统计值,并将一组Wald统计值结合成为一个显著性p值用于度量2个基因之间是否存在相互作用.此前,Ma等人[12]成功地将这一策略用于数量型性状的基因互作检测中.
本文的主要贡献有4个方面:
1) 提出了一种基于U统计量与集成学习结合的假设检验方法GBUtrees(gene-based gene-gene interaction detection based on U statistics and tree-based ensemble learners),将基因相互作用问题转化为检验2组SNP与疾病性状的对数优势比(log odds ratio, LOR)之间是否满足加性模型关系;
2) 利用以树为基分类器的集成学习方法作为底层学习方法,充分发挥该类方法对非线性关系的建模能力,有效学习2组基因之间可能存在的相互作用关系;
3) 通过多次采样子样例集使得预测模型的结果满足U统计值框架,利用其满足渐进正态分布的性质设计表征基因相互作用强度的统计量;
4) 利用8种不同相互作用模式疾病模型生成的模拟数据集与真实人类类风湿关节炎数据的实验结果表明,我们提出的GBUtrees方法可以有效挖掘基因-基因之间不同形式的相互作用关系.
1 基于U统计量的度量集成学习不确定性方法
1.1 基因互作检测问题描述
本文以基因作为基本研究单位.假设基因G1和G2分别包含p和q个SNP,每个SNP位点只有高频等位基因(major allele)与低频等位基因(minor allele)两种碱基形式,分别记为A和a,则对于人类二倍体而言,每个SNP位点存在3种可能的基因型AA,Aa,aa.数据中使用0,1,2分别对应上述3种基因型.则基因G1可表示为
G1=(s1,s2,…,sp),
(1)
其中si∈{0,1,2},i=1,2,…,p.
同理,包含q个SNP的基因G2可表示为
G2=(s1,s2,…,sq),
(2)
其中si∈{0,1,2},i=1,2,…,q.
本文方法主要针对疾病-对照数据,因此我们的目标值y∈{0,1},其中1表示疾病组,0表示对照组.如果对于G1,G2与y的LOR之间存在以下的关系:

(3)
其中F1,F2可以是任意形式的函数.我们则称G1,G2与y之间满足加性关系,即G1,G2之间没有相互作用关系.换言之,当基因G1中变量发生改变时,并不会改变基因G2对性状的影响.因此,想要判断2个基因之间是否有相互作用关系,可以通过建立如下假设检验来衡量观测数据是否可以被建模成为加性模型:
H0:
∃F1,F2,F(G1,G2)=
F1(G1)+F2(G2),∀(G1,G2)∈XTEST,
(4)
H1:
∀F1,F2,F(G1,G2)≠
F1(G1)+F2(G2),∃(G1,G2)∈XTEST,
(5)
其中,XTEST表示测试集.
使用监督学习中的集成学习方法对目标值进行建模,同时获得集成学习方法中的统计指标,来完成上述假设检验.Mentch等人[13]在2016年提出了基于U统计理论度量随机森林方法中的不确定性,并于2017年进一步完善该方法[14].本文利用该假设检验框架实现对基因互作的检测.下面将分别介绍U统计理论、集成学习方法以及基于该假设检验框架提出的基因互作检测方法.
1.2 U统计量

θ=Ε(h(Z1,Z2,…,Zk))
(6)
其中,h是一个函数,有k≤n个变量,则参数θ的最小无偏估计如下:
(7)
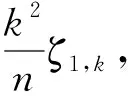

(8)

1.3 基于树模型的集成学习
集成学习使用多个分类器来解决同一问题,通过组合多个弱监督的基分类器以期得到一个更为全面的强监督模型.通过合理的选择并组合基分类器,集成学习可以在显著提高一个学习系统的泛化能力的同时提高学习器的分类精度.该方法已在多个领域成功应用[16-17].在1.2节U统计量的框架下,任何类型基分类器,只要能够写成式(7)的形式,均可以应用到本文的方法中.考虑到基因互作问题中存在严重的非线性相互作用,本文选取决策树模型作为集成学习中的基分类器.假设训练集有n个样本,

(9)
其中X=(X1,X2,…,Xd)是一个特征向量,y∈是目标函数值.选取一个小于n的k值,(Xi 1,yi 1),(Xi 2,yi 2),…,(Xi k,yi k)是训练样本的一个子样例集.给定一个待测样本x*,我们把一个树模型在该子样例集上的预测模型记为Tx*.为个子样例集都训练一棵树,那么最终待测样本x*的预测可表示为

(10)
1.4 基于U统计理论的基因互作检测方法GBUtrees
针对1.1节中式(4),(5)对应的假设检验问题,我们设计如下方法:
首先,我们要构建一个用于作为测试集的测试网格(test grid).测试网格中的数据并非真实数据,其重点在于模拟真实数据中特征的分布.例如本文研究的是2个基因相互作用,所以设计一个二维网格.网格大小为N1×N2,网格中每个位置代表G1,G2的一组取值情况.为了避免测试数据与真实数据重复,我们预先从原始数据中抽取N1+N2个样本用于构建网格.将前N1个样本的G1与后N2个样本的G2分别组合,从而生成N1×N2的网格.

(11)
则有:
(12)
(13)
式(12)表示G1取第i个SNP组合时,遍历测试网格上所有G2时的预测平均值,同理可得式(13)是G2取第j个SNP组合时,遍历测试网格上所有G1时的预测平均值.如果G1,G2之间是加性关系,则网格中所有的点(g1i,g2j)都可以表示成Fi,j=fi ·+f·j-μ,其中μ表示测试网格中所有点预测值的真实期望.因此,1.1节中的假设检验也可以表示为
H0:Fi,j-fi ·-f·j+μ=0,
∀(g1i,g2j)∈XTEST.
(14)
H1:Fi,j-fi ·-f·j+μ≠0,
∃(g1i,g2j)∈XTEST.
(15)
令N=N1×N2,我们引入一个维度为N×N的差异矩阵D:

(16)

(17)

实验中存在一个问题,当测试网格数据样本量超过50时,方法性能会大幅下降,因此考虑降低测试网格的维度.Johnson-Lindenstrauss定理保证了任何降维方法的精度上下限.影响降维精度的因素主要是维数、数据大小等,与降维方法本身无关.在维数差不是特别大时,用任何方法都可以保证一个较高的精度.本文采用随机投射(random projec-tion)方法.该方法是机器学习中常见的降维方法.通过随机生成一个p×q的投射矩阵,并对矩阵中的每一个轴(即每一行)归一化,之后左乘数据,便可将X∈q降至p.实验中我们构造1 000个随机矩阵,降维的维数设为15.详细方法描述见算法1.
算法1. 基于U统计量的基因互作检测方法GBUtrees.
输入:2个基因的基因型数据X=(X1,X2)、样本的类标签Y∈[0,1]n;

① 将原始样本集划分为训练集和测试集,测试集样本个数为N1+N2;
② 计算差异矩阵D;
③ 选取测试网格约简的维度r=15;
④ 生成M=1 000个随机映射矩阵R1,R2,…,RM;
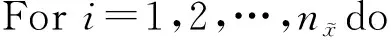
⑦ Forj=1,2,…,Ndo



算法1中涉及到的主要参数分为以下2个部分:
2) 构造每一棵树时,需要考虑每个分裂节点至少包含样本个数(minsplit)以及树的最大深度(maxdepth).利用网格搜索(grid search)方式,对每个minsplit与maxdepth组合做5重交叉验证(5-fold cross-validation),最终选取minsplit=3,maxdepth=4.
2 实验与结果
本文实验分为仿真模拟数据与真实数据2部分.
2.1 仿真模拟实验
2.1.1 仿真数据来源
仿真实验选用经典的基于重采样仿真的SNP遗传数据生成软件gs2.0.该软件以单体型数据为模板,通过设定疾病优势比(OR)、人群患病率(population prevalence)以及样本大小,可以高效产生大量疾病-对照SNP仿真数据.
本文使用的模板数据是Hapmap 高加索人群(CEU)数据,使用NCBI build37作为参照基因组进行注释.该数据共有90个单体型,以1 000 Genome数据为参考基因组,通过使用SHAPEIT[18]与IMPUTE2,对缺失的位点进行基因型填充.随后分别在一号染色体与二号染色体上各选取了一个基因[11-12],一号染色体上基因选取了14个tag SNP,二号染色体上基因选取了10个tag SNP.2个基因内部连锁不平衡(LD)模式见图1.选取SNP的详细信息见表1.

Fig. 1 LD patterns of two empirical loci used in simulation studies图1 仿真数据2个基因模板的连锁不平衡模式图

IndexSNP name:positionLocus1(chr1)Locus2(chr2)1rs11589332:120273204rs12712643:396263882rs512854:120275063rs11680220:396306573rs539426:120275647rs1558854:396395724rs593911:120288463rs7598583:396472215rs536662:120292733rs10779925:396895886rs668156:120293568rs11891871:397284317rs17186233:120297163rs17467001:397354628rs1441010:120301432rs13420425:397358139rs1441009:120307515rs7585512:3973589910rs12563433:120308975rs17532603:3974010211rs3828089:12030927412rs1441008:12031029213rs753425:12031674614rs10737757:120320726
2.1.2 仿真模型
gs2.0共有8种可选的两位点疾病遗传风险模型.根据方法不同性能的考量,实验分为以下2个方面:
1) 为了考察方法第1类错误率的表现,设定优势比OR=1.0,此时生成不存在相互作用.分别生成样本数为1 000,2 000,3 000,4 000,5 000的样本集各100个,观察第1类错误率在不同样本规模时的变化规律.
2) 为了考察方法在不同交互程度时的表现,将优势比设为1.5,2,2.5,3,3.5,4共6个取值,人群患病率(population prevalence)设为0.1,样本由2 000疾病样本、2 000对照样本组成.8种疾病模型共有48种组合,每种组合生成100个数据集.
2.1.3 实验结果分析
为了验证基于U统计框架方法的有效性,本文采用功效(power)与假阳率2个指标.功效即在每种参数设置下,可以成功检测到模拟数据中插入的相互作用的数据集占100个数据集的比例.GBUtrees与GBIGM[10],KCCU[8-9],AGGrEGATOr[11]共4种方法进行了比较.其中,GBIGM与AGGrEGATOr两种方法没有参数限制;KCCU方法采用文献中推荐的参数,设定修剪摺刀法(trimmed jackknife)的修剪比例为ω=0.15.
在假阳性方面,设定显著性阈值α=0.05,随着样本规模增加,GBUtrees犯第1类错误的概率均可控制在显著性阈值以内,可以用于后续的相互作用检验.
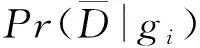

(18)
则基因型gi的外显率为

(19)

Fig. 2 Power comparison between GBUtrees and competitive methods under four disease models with different odds ratio图2 4种交互作用检测方法在8种疾病模型的不同OR值下的功效比较
由此我们可以得到2个位点基因型组合的外显率表,见表3.

Table 2 Table of Odds for Recessive-Recessive Model表2 隐性-隐性模型的疾病比率表

Fig. 3 Power comparison between GBUtrees and competitive methods under four disease models with different sample size图3 4种交互作用检测方法在4种疾病模型的不同样本量下的功效比较


Table 3 Penetrance Table for Recessive-Recessive Model表3 隐性-隐性模型的疾病外显率表
3种对比方法中,AGGrEGATOr在8种疾病模型下均表现出与GBUtrees相似的变化趋势与性质,而KCCU与GBIGM在该模拟实验中几乎无法检测出相互作用.本文中仿真实验与GBIGM中模拟实验[8]的区别在于选取的模板数据不同,不同的模板数据由于内部不同的连锁不平衡结构会对方法的性能产生影响.
此外,样本量对方法性能影响的结果如图3所示.随着样本量增加,GBUtrees与AGGrEGATOr性能均呈现单调递增的趋势,另外2种方法性能没有随样本数量的增加而发生改变.图3只展示了4个模型下方法的表现,GBUtrees在剩余疾病模型上均表现出类似的变化趋势,且优于其他3种方法.
2.2 真实数据实验
2.2.1 真实数据描述及预处理
为了评估方法在处理真实疾病对照数据时的表现,我们选用了一组类风湿关节炎(rheumatoid arth-ritis, RA)的真实基因型数据.RA是一种遗传相关的慢性的自身免疫性疾病,持续性的炎症会影响骨重塑,进一步导致骨坏死.我们使用WTCCC(2007) 数据集,该数据使用Affymetrix GeneChip 500K进行基因型鉴定.为了验证潜在的基因之间的相互作用,我们参考了KEGG①上的RA 通路hsa05323.该通路共包含90个基因,其中MHCII与V-ATP是2个蛋白质结合体,内部存在许多的相互作用.因此,对这2个复合体各选取了一个代表基因.通过使用NCBI发布的人类基因组序列NCBI build36的注释文件确定每个基因在染色体上的起始终止位置,并为每个基因的上下游增加了10 kb的缓冲区,我们从RA数据中为最终剩余的48个基因确定其包含的SNP.随后借助软件PLINK对数据进行质量控制,共包括3个步骤:1)删除性别与性染色体不匹配的数据;2)设置SNP缺失率(missing rate)小于10%、低频等位基因频率MAF>5%,以及显著影响表型的缺失;3)删除不满足Hardy-Weinberg平衡的SNP.经过质量控制之后,共剩余385个SNP和4 966个样本,其中4 966个样本包括1 973个病例样本以及2 993个对照样本.
2.2.2 真实数据结果分析
为了避免人群结构、性别成为干扰因素,我们将性别作为变量加入数据.随后使用软件GCTA对数据做主成分分析,并将前10个分量加入数据用于校正潜在人群结构带来的影响.
Table4RankingofSignificantGGIResultsintheWTCCCRheumatoidArthritisDatasetAnalysis
表4WTCCC人类类风湿数据集上显著相互作用关系在不同方法中的秩次

Gene 1Gene 2RankingGBUtreesAGGrEGATOrKCCUGBIGMAng1Tie211099560260Tie2Flt121108685460Tie2LFA1311217391035MHCIIAng14109534270MHCIITie25858950680MCSFAng163320590MCSFTie271033485495Ang1Flt181029265500Tie2RANK91117720524TGF-betaTie2101037745580CD86CCL290011066650TGF-betaAP12702605260MCSFAng163320590CD86TLR4650450565CXCL1RANKL7705130825CCL20TGF-beta6606300350RANKLAPRIL5407270180RANKTGF-beta340887568IL23LFA17509395530IL1V-ATPase102010360905
GBUtrees检测出最显著的相互作用来自血管生成素(Ang1)与Tie2.该相互作用是一对RA致病机制中已被证实的互作关系[19].血管翳是RA病变过程中的一个特征性的病例产物.滑膜血管增生是RA早期关键事件,是促进和维持血管翳的重要因素.而RA血管生成是由滑膜组织髓细胞和纤维母细胞(包括血管生成素Ang1)释放的促血管生成因子驱动和维持的.内皮细胞(EC)的特异性因子Ang1及其酪氨酸激酶受体Tie2在生理性和病理性的血管生成发育中至关重要.Ang1/Tie2在RA滑膜组织中上调表达.有研究表明Ang1/Tie2信号通路介导了肿瘤坏死因子(TNF-)、白介素(IL)以及toll类受体TLR2在RA中促进血管生成的作用.AGGrEGATOr方法发现的第7对是RANKL与APRIL之间的互作[20].研究表明纤维细胞样滑膜细胞FLS是RA发病机制中的主要效应细胞,而APRIL促进了RANKL的FLS表达.KCCU与GBIGM方法给出了太多显著性结果,因此没有对这2种方法的结果进行进一步分析.
3 总 结
检测基因-基因相互作用的研究在理解人类复杂疾病致病机理方面具有重要意义.本文提出一种基于U统计量与集成学习结合的假设检验方法GBUtrees用于基因相互作用检测.我们将检测基因之间的相互作用问题转化为假设检验问题,定义零假设为2个基因与疾病标签的LOR之间满足加性关系.这一假设对基因之间互作的形式没有限制,增强了方法对不同类型作用关系的检测能力.仿真数据实验结果表明,在可控第1类错误率的前提下,GBUtrees在模拟的8种疾病模型上均优于相比较的其他方法,且方法效力随着作用强度的增大以及样本量的增大呈现单调递增.此外,在真实类风湿关节炎数据验证实验中,GBUtrees成功复现了已被证实的Ang1/Tie2相互作用.以上结果表明该方法在基因相互作用挖掘中的有效性.
GBUtrees采用集成学习方法作为底层学习方法,增强了方法的泛化能力.同时,以树模型作为基分类器,发挥其强大的非线性建模能力,大大增加了方法检出不同类型相互作用的功效.此外,通过设计重采样的策略,使预测结果具有U统计量的渐进正态性质,从而可以设计用于表征相互作用关系强度的统计量.获得相互作用关系强度p值对于检验结果的复现以及应用到后续的全基因组关联研究中都具有至关重要的意义.仿真模拟数据以及真实人类疾病数据的实验结果表明,本文提出的GBUtrees方法在检测效力方面优于现有的方法,可以有效用于疾病相关基因相互作用的挖掘研究.

GuoYingjie, born in 1987. PhD candidate. Her main research interests include machine learning and bioinformatics.

LiuXiaoyan, born in 1963. PhD. Associaate professor and master supervisor. Her main research interests include bioinformatics and data mining.(liuxiaoyan@hit.edu.cn).

WuChenxi, born in 1988. PhD. Assistant professor. His main research interests include flat surface, three dimension topology.

GuoMaozu, born in 1966. Professor. PhD supervisor. Member of CCF. His main research interests include machine learning, smart city and bioinformatics.

LiAo, born in 1995. Master. His main research interests include machine learning and deep learning.
