面向微博短文本的社交与概念化语义扩展搜索方法
2018-08-06崔婉秋杜军平寇菲菲李志坚LeeJangMyung
崔婉秋 杜军平 寇菲菲 李志坚 Lee JangMyung
1(智能通信软件与多媒体北京市重点实验室(北京邮电大学) 北京 100876)2 (釜山国立大学电子工程系 韩国釜山 46241) (wanqiucui@foxmail.com)
近年来,社交网络信息在微博等社交平台上得以广泛的传播和共享.由于社交媒体上用户发布信息的字数受平台限制,并且描述具有随意性,缺乏语义的短文本大量涌现.为了用户在社交媒体平台上更加有效、及时的交流和信息获取,针对短文本的语义分析和搜索成为了目前的研究热点[1].传统的文本语义分析技术中,通常仅考虑文本字面语义[2],对于短文本的查询则采用基于语义的扩展方法[3-4].然而,微博短文本的稀疏性和语义局限性使单纯的文本语义分析方法不能很好地实现对文本语义的有效挖掘.本文利用微博短文本特有的社交属性,包括引导性辅助信息标签、“@提及”和链接信息URL.这些辅助信息大多被作为外部元数据来描述文本内容,对其充分挖掘会使微博文本在搜索中体现更多的社交语义信息.本文在微博搜索中结合概念化语义信息,融合标签引导的话题趋向以及微博互动文本内部的关联,解决微博短文本的语义稀疏性问题,使搜索更具话题指导性.
社交网络搜索是目前研究的热点问题.贾焰等人[5]对社交网络智慧搜索技术进行了全面地分析与总结.传统的扩展搜索方法如用搜索结果扩展的伪相关反馈方法[6],或通过外部知识库的概念化扩展方法[7-8]都是单纯地从文本语义出发,没有考虑文本之间的联系.此外,在已有利用标签[9-10]和微博结构信息[11]进行辅助搜索的研究中,没有分析文本的语义.本文融合文本语义和标签等社交结构信息,用社交语义对文本做进一步扩充,使用户在标签指引的主题一致性和社交紧密度等特征的辅助下,挖掘微博文本之间更多的潜在语义关系,提高微博短文本搜索的精确性.
在相关短文本研究的基础上,本文基于维基百科的显性语义分析算法(explicit semantic analysis, ESA),获取短文本的概念化语义信息.利用标签和社交关系构建语义标签图模型,生成关联标签特征,从而表示短文本的社交语义信息.提出基于社交与概念化语义的扩展搜索(expanded search based on social and conceptual semantic, SCS-ES)算法.通过实验验证,SCS-ES算法能够有效地提高微博短文本搜索的性能.
本文的主要贡献有4方面:
1) 提出一种基于社交与概念化语义的扩展搜索方法SCS-ES,挖掘社交网络中特有的社交属性,扩充短文本语义,从而提高搜索准确性.
2) 提出利用Wikipedia生成的最具语义表示的概念词作为纯文本的标签.解决微博数据集中标签使用少的问题,并实现微博结构的统一表示,为抽取标签构建图模型奠定基础.
3) 在概念空间内利用社交关系,构建社交语义标签图模型.挖掘出社交关联下语义相似的文本,丰富短文本的社交语义.
4) 在不同微博数据集上的实验结果表明,本文提出的SCS-ES算法能够有效地增强短文本的语义,改进微博短文本的搜索准确性.
1 相关工作
随着社交网络的发展短文本形式不断涌现,针对短文本的研究变得非常重要.由于其自身短小的特点,在搜索中文本语义分析和扩展方法具有重要的研究价值和意义.本节对短文本在搜索中的相关技术进行概述.
1.1 文本语义分析
近年来,在文本搜索领域存在大量的研究成果,包括大量地从纯文本中分析语义提高搜索有效性的方法.经典的LSA和LDA等语义分析方法,基于统计思想来构建语义学习模型,忽略了词语间的语义关系,因而容易造成文本语义信息的缺失.
此外,由于概念模型在短文本语义学习中的有效性,被认为是一种有效的语义挖掘方法,受到了广泛的关注.如基于Wikipedia知识库[12-13]的ESA[14]方法,以及基于Probase的LexSA[15]等计算语义的方法[16-17],它们提供了跨领域背景知识的相关概念,构建了概念袋向量,用于表示短文本的深层语义结构,扩展了短文本的含义.以上方法优于词袋和主题模型等仅关注词及统计思想的方法,能够提供更多可参考的文本语义信息.
1.2 短文本搜索
由于短文本自身简短、描述随意且缺乏语义信息的特点,使得在搜索中单纯的字面语义分析面临一定的困难.王仲远等人[1]针对短文本的理解方法分析了多种处理技术,在搜索中提供给用户可理解的语义关系解释.针对短文本的搜索方法主要着重于扩展的形式,可以增强文本特征词的语义描述能力,特征词数量的增加也可以在一定程度上解决短文本特征向量稀疏性问题.如基于时空特性[18]的扩展、概念袋[7-8]及两者结合的反馈概念模型[19],这些方法采用相关文本或概念携带的信息来扩充文本的表示.

Fig. 1 Short text extended search algorithm based on social and conceptual semantics图1 基于社交与概念化语义的短文本扩展搜索算法
基于概念语义的搜索利用外部知识源提供在文档集合和查询中没有显性表现出来的额外背景知识和上下文.与主题模型等方法相比,基于外部知识库的方法具有更好的词汇覆盖率,计算模型可以有效地应用于不断更新的语料库.但单纯的概念袋及概念反馈扩展模型,仅从文本表面进行分析,虽然在语义理解上形成了统一的知识模式,但是在微博短文本中,短小和歧义性会导致概念化的方法受到一定的局限.因此,充分挖掘微博的社交属性,利用社交结构和标签等辅助信息进行语义挖掘是面向微博搜索的发展趋势[9-11].
2 基于社交与概念化语义扩展的搜索算法
2.1 问题描述
在微博搜索中,将微博短文本扩展为一种包含3个域的虚拟文本结构:原始文本域ST(short text)、概念化语义特征域CS(conceptual semantics)和标签社交特征域HS(hashtag semantics).该扩展过程在离线阶段完成,数据集中短文本形成的语义特征结构ST′表示为
ST′={ST+CS+HS},
(1)
其中,将微博中的标签和纯文本部分统一称为短文本,即原始文本域ST={ST1,ST2,…,STn},n为微博文本处理后的短文本总数,包括文本和标签2部分,短文本由一组词或短语组成,表示为STi={t1,t2,…,tk};CS为借助Wikipedia外部知识库对ST进行概念化后生成的概念化语义特征域;在标签短文本被概念化的基础上,将其根据微博中的社交属性构建语义标签图模型,并通过模型生成短文本的社交特征域HS.
给定查询Q,将其类似于短文本的扩展表示为3部分语义结构Q′={Q+CS+HS}.其中,CS的获取过程与微博短文本生成过程相同,社交特征则通过与微博中标签(短文本)生成的HS进行语义相似性计算,获取最相近的一组标签作为Q的标签社交特征.在2.3节中将给出其详细的生成过程.针对微博短文本的搜索结果由Q′与ST′的top-K相关性排序分数给出,计算为

(2)
其中,idf(ti)为典型的逆文档频率,weight为词在扩展短文本所有域中的累积权重,本文2.4节将对式(2)进行详细说明.
SCS-ES算法的实现由3部分组成,分别为对微博短文本的概念语义特征扩展、社交语义特征扩展以及基于语义扩展的微博短文本搜索,如图1所示.下面将分别对每部分进行说明.
2.2 短文本概念特征扩展
由于Wikipedia是目前最大的知识密集型网络仓库,它是动态更新、快速增长的事件资源,具有一定的新闻价值和事件覆盖性,因此它非常适合作为在社交网络信息快速传播的环境下进行搜索的外部参考资源.将Wikipedia作为微博短文本概念化语义生成的知识库,将它的文章标题作为概念,页面内容作为相应概念的描述,从而构建一个概念语义空间模型.由于概念空间的概念词语是从Wikipedia抽取出来的,因此短文本通过概念化表示后语义属性具有良好的可读性.
2.2.1 概念化
采用显性语义分析算法ESA[14]进行短文本的概念语义分析.对Wikipedia页面描述中显性存在的词语进行分析,将每个概念都表示为相应页面词语的属性向量,即转换为概念空间的向量模型来表示,并在概念空间中进行概念提取和估计.利用倒排索引技术将短文本中每个词项映射为与其相关的Wikipedia概念的加权序列,在该方式下原始文本被表示为概念化空间下的权重向量C.其中,短文本中的词语t在相应概念c下的映射概率为P(c|t),以概念的代表性分数表示为
(3)
其中,count(·)为词语t与概念c的共现次数;M是在Wikipedia中抽取出来的概念页面的集合,ci∈M.
短文本进行概念映射后,从词向量空间转换为概念空间,被向量化为C=(wc 1,wc 2,…,wc k).每一项为短文本STi在概念ci下的对应权重,表示概念与短文本的关联强度,计算为

(4)


(5)

(6)
其中,|M|为Wikipedia的概念页面总数;N(ti)为词语ti在概念页面ci内出现的次数;N(ci)是概念ci在所有词语映射中出现的次数.
2.2.2 概念特征扩展
在离线和在线阶段分别对微博数据集和查询(统称为短文本)进行概念化,使其服从概念空间内的概念关联权重分布.将ST基于Wikipedia的概念知识映射到统一的概念空间下,生成一列相关概念集合,由概念与文本的相应概率表示.取排序top-k的最具代表性的概念词语组成CS.原始文本被统一扩展为ST+CS.
例1. 微博短文本“天津滨海新区爆炸现场发巨响腾起蘑菇云”,对其分词和去停用词等预处理后,概念化特征扩展生成的概念特征为CS={天津市,爆炸,蘑菇云,2015天津港危化品仓库爆炸事故,开发区}.
2.3 社交语义特征扩展
从短文本中提取概念后,整个建模过程转化到概念空间内.结合概念空间与社交属性,对标签短文本进行建模,生成社交语义标签图.同时对短文本实现社交语义(关联标签特征)的扩展,作为SCS-ES算法的主要部分.
2.3.1 社交语义标签图模型构建
微博文本中的辅助信息“@提及”指向一个活跃的微博用户,该用户讨论了此话题或者在该问题上具有一定的权威性.通过“@”作为微博实体的链接,用户可以将他们共同感兴趣的话题联系起来.同样地,涉及到相同URL链接的用户,他们讨论和关注了同一个链接内容.因此通过上述信息可以将整个微博网络形成一种潜在的关联,以图的形式来表征和计算社交网络中的自然语义,充分考虑了社交特征的关联,并在概念空间下将标签之间的相关性组织起来.
在对短文本进行语义概念化转换后,它们被映射到统一的概念空间中.不同概念之间是相互独立的,我们通过在概念空间的基础上构建社交语义标签图,将概念之间通过社交关系、标签共现等辅助属性进行连接,形成具有话题一致性的图结构.由于微博文本信息中包含标签的仅占少部分,因此我们对微博中纯文本内容进行标签信息的补充.由于概念化词语是对短文本内容的语义总结,与标签微博中的话题总结作用类似,所以将纯文本的top-n相关的概念词作为标签,将微博数据空间统一格式为:#标签#和纯文本.将整个微博数据之间建立社交关联,从而生成社交语义信息.
构建完整紧凑的社交概念化语义标签图G=V,E,W.其中,V为标签表示的节点;E表示标签之间的关联关系;W为连接边的权重,反映了标签之间相关性的紧密程度,包括每条边上各种社交关系的平均累加权重以及标签概念化词语的重叠度,在关联标签的生成过程中,连接标签之间重叠的概念化词语越多,标签表达的语义越相关.将社交概念化语义标签图导入适用于社交网络图形结构的Neoj4图数据库[20],使节点关系更直观,关联操作更灵活.为了使社交语义标签图结合微博信息传播中的社交关系,定义标签之间的连接规则如下:
规则1. 标签共现在同一短文本中,则标签之间存在连接(表示2个标签具有同一话题倾向性);
规则2. 标签出现的文本中具有相同的URL,则标签之间形成连接边(包含相同链接信息的文本内容,文本可能讨论同一事件或主题);

Fig. 2 Social semantic hashtag graph model with an instance of node enlargement for a part of the same event图2 社交语义标签图模型同一事件部分节点放大实例
规则3. 标签出现的文本包含@同一个人或组织,标签之间建立连接(2个标签的内容与同一个人或组织相关时,它们在语义上相似.例如,2个微博内容中都@天津防火,则其均涉及“天津爆炸”的话题).
图2为社交语义标签图模型中同一事件部分节点的放大实例表示,节点分为标签和概念(由网格节点表示)2类.节点属性包括mid,mention,URL,concept.其中mid为微博编号,mention为微博内容中带有@字段的信息,URL为链接信息,concept为节点信息(标签或文本)概念化映射生成的一组概念.由于每个节点可能出现在同一话题下的多条微博信息中,因此节点所在微博内的mid,mention和URL会对应多个不同的取值,将其作为节点相应属性的值.其次concept属性能够使标签图充分地融合文本语义信息.如标签节点#天津港爆炸事故#,其4个属性内容如下:
mid={CvA0nw9EH,CvA33xInC,CvA3ggmJV,…};
mention={天津消防,人民日报,法制晚报,…};
URL={http://t.cn/RL3J6I4,http://t.cn/RL39DD,…};
concept={天津市,爆炸,蘑菇云,2015天津港危化品仓库爆炸事故,消防员,…}.
2.3.2 社交语义特征的生成
在关联标签生成的过程中,利用共享概念及社交规则实现节点之间连接紧密度的测量,进而生成语义一致性的标签集合,通过关联标签对短文本进行社交语义的扩展.
针对微博短文本关联标签特征的扩展,在概念空间内进行关联标签的度量.定义语义一致性分数来评估标签n与短文本st中的目标标签v的相关概率.在社交语义标签图中,针对标签对应的概念集,生成一组与给定短文本包含的标签语义一致性的标签集.原始标签节点v与其邻居标签n的语义一致性分数计算为
S(ni|v,sti)=e(ni,v)+Ssim(ni|v,sti),
(7)
其中,e(ni,v)为ni与v节点之间边的权重,即两节点之间满足连接规则的情况下,3种规则中权重的平均值.对于每一个规则,边的权重是2个标签节点共现的属性数与目标节点中包含该属性的数量的比值.例如,2个标签节点共现mid的个数与目标节点包含的mid个数的比值.利用每个标签的概念词语重叠的数量衡量标签之间的语义相似性,计算为

(8)

Table 1 Extended Instance of HashtagText Generated Associated Hashtags Feature
表1 标签纯文本生成的关联标签特征扩展实例

Table 1 Extended Instance of HashtagText Generated Associated Hashtags Feature
Hashtag∕Plaint TextAssociation Hashtags#天津港爆炸事故##天津塘沽大爆炸#,#天津滨海新区码头爆炸#,#祈福天津#,#突发#,#今夜与滨海同在#,etc.暴雨Concepts“雨”,“强降雨”,“泥石流”,#暴雨#,#武汉暴雨#,#暴雨直播#,#暴雨成灾#,etc.
① https:dumps.wikimedia.orgzhwiki
由于查询短文本的社交语义扩展是在线阶段实现的,所以更新标签图模型存在响应时间的问题,将查询短文本概念化后生成的一组概念语义特征,表示为CSQ.离线阶段生成微博短文本(除去标签部分)的概念化特征表示为CSs t.将两者进行相似性匹配,选择CSs t中与CSQ相关性top-k的概念集所对应的标签,作为Q的关联标签扩展部分HS.其中,根据CSs t和CSQ中的公共概念来表示语义相关性,如式(9)所示:

(9)
其中,|CSQ∩Cs t|为2个概念集公共概念的个数;p(ci|CSQ)与p(ci|Cs t)表示公共概念集内ci在对应集合内的概念代表性分数.
对微博短文本和查询分别进行社交语义特征的生成计算,如对例1中的微博短文本进一步获得社交语义特征为HS={天津塘沽大爆炸,天津滨海新区码头爆炸,祈福天津,突发,今夜与滨海同在}.最后所有短文本扩展为2部分语义特征表示的形式ST′=ST+CS+HS.即例1中短文本扩展表示为ST′={天津,滨海新区,爆炸现场,蘑菇云;天津市,爆炸,蘑菇云,2015天津港危化品仓库爆炸事故,开发区;天津塘沽大爆炸,天津滨海新区码头爆炸,祈福天津,突发,今夜与滨海同在}.
2.4 微博短文本扩展搜索
对原始短文本的2部分扩展操作使文本具有了结构化特征,每个域代表短文本不同的语义信息.选择适用于该类型文本数据的搜索技术BM25F[21]排序算法,在搜索中体现3个域对文本解释的不同重要程度,在扩展的紧密语义空间内得出相似性最高的搜索结果.
由于标签在微博事件发展的一致性中起到聚集和指导作用,因此标签在搜索中十分重要,将HS域在搜索中定义为最大的权值,概念化语义在语义层面上对搜索起到理解作用,因此将CS域赋予高于原始文本ST的权重.词在所有域中的累积权重可计算为

(10)

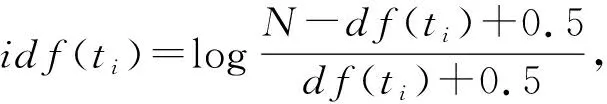
(11)
其中,N是在数据集中的文档数,df是出现词t的文档数.
3 微博短文本搜索实验
采用本文提出的SCS-ES算法对微博短文本进行搜索测试,分别对数据集及预处理、实验中参数的设置、对比算法和评价指标进行介绍,最后展示搜索实验的结果.
3.1 数据集及预处理
采用维基百科离线数据集作为外部知识库,用于短文本概念语义的映射.在新浪微博3个事件组成的数据集上评估SCS-ES算法的有效性.
3.1.1 维基百科外部知识库
从中文维基百科网站①下载数据zhwiki-2017 0701-pages-articles.xml.bz2,分别以数据库的形式存储,如page.sql,interlinks.sql等.为了减少对概念化操作产生噪声和干扰,对概念进行筛选.删除数据中对语义理解和扩展没有作用的页面,包括非概念页面(如Talk)、字数少于200的短页面以及在关系结构中链接少于3的概念页面.将候选概念页面通过wikiExtractor解析为文本格式,由opencc进行繁化简操作.下载的数据大小为1.4 GB,解析后包含948 835篇文章,筛选后剩余167 328候选概念页面.
将抽取出来的信息利用Apache Lucene①构建倒排索引,完成概念化过程中词与概念的映射和匹配操作,同时加速短文本的概念映射.在映射中只对描述事件的关键词语进行概念化,避免生成噪声概念词对搜索产生影响.
3.1.2 微博数据集及预处理
对新浪微博中与国民安全相关的热点突发事件的数据通过相应的关键词进行爬取,采用关键词及组合形式进行搜索,得到包含精确事件及少量噪声的数据集.爬取了2个主要事件的168 199条数据,将其处理形成以下4个数据集.
1) 数据集1.它是由“天津、塘沽、爆炸、仓库、滨海新区”及各自组合获得的单一事件数据.
2) 数据集2.它是由关键词“暴雨,湖北,武汉,防汛、灾害”及各自组合获得的单一事件数据.
3) 数据集3.它是由数据集1和数据集2合并组成的混合事件数据.
4) 数据集4.它是参照文献[22],选取实验室10名成员对数据集1进行分类标注获得带有分类标签的数据集4.为了减少标注过程的误差,给定类别描述的关键词及对应的类别标签:爆炸现场(0)、消防员救援(1)、医疗伤亡(2)、祈祷(3)、爆炸无关信息(4).每个成员分别对每一条微博文本进行标注,在10个类别标签中选取数量最多的作为该文本的类别标签.
将每一个数据集中的内容进行抽取,获得纯文本、#标签#、“@”提及和链接信息URL字段(可以为空).将纯文本和标签内容进行繁化简、分词和去噪声处理,以便概念化.通过对社交辅助信息之间的关联关系进行计算,构建社交语义标签图模型,并将其导入图数据库Neoj4中,形成标签节点和概念节点的连接图结构.抽取后微博内容中包含的辅助信息数量及分别占数据集的比例统计如表2所示:

Table 2 Auxiliary Information of Microblog Datasets
3.2 评价指标
信息检索的评价指标主要包括搜索到相关文档的能力和对相关文本正确排序的能力.采用准确率P@K、平均准确率MAP和归一化折扣累积增益NDCG指标来评估搜索算法的性能(K为搜索返回结果的阈值).相应的评价指标和计算公式如下:
1) 准确率

(12)
其中,tr是返回结果中正确的文档数;fr为结果中错误文档的数量.两者之和为结果列表中文档的总数K.
2)MAP值在准确率的基础上考虑了返回文档在列表中的位置信息.其公式为
(13)
其中,Qn为查询次数,position(r)为第r个相关文档在返回列表中的位置,R表示相关文档的个数.
3)NDCG是衡量排序质量的指标.它为连续值的索引,基于返回的前K个搜索结果进行计算.

(14)
其中,R(j,d)是文档相关性等级,m是文档返回的位置.
3.3 实验设置
3.3.1 对比算法
我们参照文献[10]的方法,邀请10名经验丰富的微博用户参与搜索任务,对搜索结果进行评价.其中,每人任意给出10条事件相关的搜索作为搜索集Q.为了评估SCS-ES的有效性,分别选取了概念化和主题扩展的4种对比搜索算法进行实验.每种算法分别返回top-K个搜索结果组成结果集合.为了避免由多个搜索之间的学习效果引起的认知偏差,对每个搜索算法的搜索结果集进行匿名和随机组合分配给实验参与者,并让参与者在其中指定K个与搜索最相关的结果.计算被用户标记为相关的结果与每个算法返回的K个结果之间的相关匹配程度.此外,为了验证人为因素对算法有效性的影响,我们采用文献[3]客观评价的方法,在分类数据集中将搜索的返回结果是否与查询属于同一类别作为搜索的正确性依据.
对比算法介绍如下.
1) ESA-ES[14](explicit semantic analysis-extended search).基于ESA的概念搜索扩展方法,通过显性语义分析对文本进行概念扩展.
2) Topic-ES[23](topic-extended search).利用主题词代替概念,利用LDA生成短文本的主题分布,并作为短文本的扩充部分.
3) SEMD[10](semantically enriched microblog document).语义化扩充微博文档算法.对微博短文本标签和文本信息分别进行概念化扩展,文档结构包含5个域:纯文本、标签、分词后的标签、维基百科链接实体扩展的分词标签和纯文本.
4) ESAC[24](explicit semantic analysis confidence).通过结合ESA和概念-词语之间的关联规则置信度对查询进行概念化扩展,进而实现短文本扩展搜索.
3.3.2 参数设置及讨论
文献[25]表明在伪相关反馈中,作为扩展词进行扩展搜索的词数设定为20时,对于扩展搜索的效果最佳,因此设定ESA-ES的概念扩展词个数k=20.Topic-ES算法中选取主题模型LDA.根据文献[23],设定模型参数α=50/l(设主题数l=10),β=0.01,吉布斯采样迭代次数为1 000,每个主题返回20个主题词进行搜索扩展.此外,在SCS-ES算法中由于概念和标签长度不固定,分词后扩展的词语数量不能保持一致,因此根据经验将概念特征扩展和关联标签特征扩展的词数均设置为k=5.
利用top-n纯文本的概念化词语作为文本标签进行标签图的构建,参数n的取值会影响算法构建社交语义标签图的结构紧凑性,从而影响关联标签特征的生成,因此SCS-ES算法的搜索有效性会随着n值的变化而改变.为了验证n值何时能够使SCS-ES算法达到最佳状态,在3个数据集上进行了实验比较,图3为SCS-ES算法在参数n的不同取值下搜索MAP@10指标的敏感性结果.

Fig. 3 The influence of parameter n on the search accuracy of SCS-ES algorithm图3 参数n对SCS-ES算法搜索准确率的影响
如图3所示,当n=2时,在3个数据集上搜索的平均准确率均相对较高,说明取2个概念词语作为标签能够拟合微博环境下标签存在的实际数量,使社交网络结构紧凑且标签不冗余,保证了社交语义标签图生成社交特征的有效性.此外,数据集1表现的搜索效果最佳,数据集3中的搜索效果优于数据集2.结合表3内统计的各数据集中微博辅助信息的数量可知,SCS-ES算法的搜索性能与数据集内微博文本包含的辅助信息的比例成正相关,说明SCS-ES算法中标签数量对扩展搜索性能起到了一定的作用,所占比例越大,指导搜索的效果越好.
3.4 SCS-ES与对比算法搜索性能的比较
为了分析SCS-ES算法在微博短文本数据集上的搜索性能,在P@K,MAP和NDCG三个指标上验证其搜索的有效性,并与对比算法进行了比较和分析.
3.4.1P@K指标上的对比结果与分析
为了充分展示SCS-ES算法的搜索效果,以下实验中均设置作为纯文本标签的概念化词语的个数top-n中n=2.此外,由于数据集1包含的标签等辅助信息数量最大,使SCS-ES算法能够充分发挥优势,因此为了排除数据集对SCS-ES算法的影响,并充分验证SCS-ES在搜索上与对比算法性能的优势,本节在数据集1中分别选取搜索结果返回值K为10,20,30,40,50时,计算SCS-ES和对比算法搜索准确率P@K的结果,如表3所示.随着K值的增大,SCS-ES与所有对比算法的P@K值均呈逐渐下降的趋势.

Table 3 Comparison of P@K on Dataset 1表3 在数据集1中P@K指标对比

Fig. 5 Comparison of NDCG under two datasets图5 2个数据集下NDCG指标对比
从表3结果中进一步分析可知,SCS-ES算法的总体性能最佳,相比SEMD算法P@K值提升了10%左右,SEMD与Topic-ES算法在搜索准确率上差距不大,均优于ESA-ES算法,这表明单纯的概念化方法并不理想,利用标签的SCS-ES和SEMD方法具有较好的准确率.当K=10时各算法准确率达到峰值,说明K=10时每个搜索算法的性能均最显著,SCS-ES算法与对比算法相比能够实现最好的搜索准确率.
为了排除人为因素的影响,选择数据集1和数据集4(相同的数据,区别为有无分类信息)进行搜索实验.在数据集4的每一类数据中选取10条作为2个数据集的搜索集合,并根据人为判断和客观类别区分的方法计算P@10的结果,对比结果如图4所示.从图4中可以看出,对于同一算法在2个数据集上的P@10结果非常接近,并且客观评价的数据集4上的效果优于人为评价的数据集1,说明通过人为评价的方式更加严格,在返回结果相关性的判断上,会更加的趋于用户搜索意图.验证了本文实验设置中无分类数据集中所用的评价方式具有一定的可信度.

Fig. 4 Comparison of P@10 of algorithms under two datasets图4 2个数据集下算法P@10指标对比
3.4.2NDCG指标上的对比结果与分析
为了研究不同数据集对实验中算法性能的影响,选取单一事件数据集1和数据集2以NDCG指标进行实验,得出数据集上SCS-ES与对比算法的搜索性能.
图5为在数据集1和数据集2中SCS-ES及对比算法NDCG指标的对比.实验结果表明,当K=30时数据集1和数据集2中SCS-ES及所有对比算法均达到最好的搜索效果.从图5中可以看出,SCS-ES和SEDM算法在数据集1中的搜索效果优于数据集2的对应实验结果,因此数据集的变化对SCS-ES和SEMD算法的影响最明显,说明在利用了标签信息的算法中,标签所占数据集的比例会影响算法的整体性能,而其他对比算法在2个数据集上的NDCG值并没有明显变化,说明利用微博辅助信息进行扩展搜索的性能会受到微博内容中标签等辅助信息数量的影响,且包含的辅助信息越多,搜索效果越好.
图5(b)展示为数据集2中SCS-ES和对比算法的实验结果.虽然数据集2内包含的辅助信息数量并没有使算法SCS-ES达到最佳搜索效果,但是其搜索结果仍优于其他对比算法.对于概念化方法ESA-ES只分析了文本的字面语义,通过外部知识库进行概念转换时,短文本和描述随意的特点使概念表示存在噪声,因此搜索结果最差.主题词扩展的Topic-ES算法通过分析文本的主题分布获得主题语义,由于其训练语料库存在局限性,搜索的效果并不理想.SEMD算法利用标签进行了扩展搜索,针对微博短文本的搜索效果比ESA-ES和Topic-ES算法有一定提升.但SEMD算法仅根据微博中现有的标签进行扩展,微博中存在大量无标签的纯文本,无法获取标签语义,因此搜索效果没有SCS-ES算法的NDCG指标高.在SCS-ES算法中对纯文本进行了标签的补充,同时通过社交关系构建了社交语义标签图模型,使短文本的语义扩展通过文本语义和社交语义2部分实现,实验结果表明,SCS-ES算法能达到最佳的搜索效果.
3.4.3MAP指标上的对比结果与分析

Fig. 6 Comparison of MAP under three datasets图6 3个数据集下MAP指标对比
为了去除单一数据集在搜索中事件一致性的指导效果,对混合事件数据集3进行实验.图6为3个数据集中SCS-ES及对比算法MAP值的实验结果.从图6中分别可以看出K=10时,SCS-ES及所有对比算法的MAP值均达到最优,本文算法SCS-ES在3个数据集中的MAP值显著优于对比算法.图6(a)为数据集1中的MAP结果,SCS-ES的效果明显优于图6(b)和图6(c)中分别表示的数据集2和数据集3中SCS-ES算法的MAP值.3个数据集上SEMD算法MAP值变化幅度大于其他对比算法,受到标签比例的影响.此外,在单一事件数据集1和数据集2及混合事件数据集3下,SCS-ES均体现了较好的MAP值,在数据集1上效果最佳.在数据集3上的实验略优于数据集2上的实验结果,说明数据集包含的辅助信息(标签、@提及和URL)的数量对于SCS-ES算法具有一定的影响,成正相关.数据集包含的辅助信息数量越多,算法的性能越好,并且混合事件对SCS-ES算法并没有影响和限制.对上述实验结果进行分析可知,在P@K,NDCG和MAP值3个评价指标中,本文算法SCS-ES优于所有对比算法;其次是利用了标签信息分域搜索的SEMD算法和主题词扩展的算法Topic-ES;最差的是概念词扩展算法ESA-ES.
我们在表4中展示了SCS-ES及所有对比算法在3个数据集上进行的搜索实验中3个指标总体性能的平均值.从表4中可以看出,SCS-ES算法的搜索性能的平均值最佳,说明该算法具有很好的稳定性.仅通过概念化(ESA-ES)或主题词进行扩展搜索的算法(Topic-ES)比没有引入标签文本分域的算法(SEMD和SCS-ES)的性能好.由于SEMD算法没有考虑各个文本域的语义信息,没有对微博中大量缺乏标签的文本进行处理,也没有融合微博环境下的社交关系等信息,因此搜索效果没有本文提出的SCS-ES算法的效果好.SCS-ES算法在进行微博短文本扩展搜索中,有效地利用社交属性信息扩充了微博短文本的语义,并且对缺乏标签的纯文本进行了补充,在搜索中结合了文本概念化语义和社交语义,满足微博环境下的搜索需求,并且显著提高了微博短文本的搜索效果.

Table 4 Comparison of Average Search Performance on Three Datasets表4 在3个数据集上的平均搜索性能比较
3.5 SCS-ES与对比算法搜索响应时间的比较
在面向搜索的研究中,搜索反馈时间是重要的,虽然本文是针对短文本语义扩展搜索精度的研究,但是为了验证该算法在搜索反馈时间上是否在用户可接受的范围内,我们选取对比算法SEMD[10]、ESAC[24]与SCS-ES算法进行搜索响应时间的对比实验.在搜索数据集大小变化的情况下,验证算法搜索响应时间的有效性,实验结果如图7所示:

Fig. 7 Comparison of the average search response time图7 平均搜索响应时间的对比
图7展示了在数据集1、数据集2和数据集3上分别进行搜索,返回P@10结果时算法的平均搜索响应时间.从表2数据集信息统计中可知,每个算法的平均搜索响应时间都随着数据量级的增长而增大.SEMD算法的响应时间略长,这是由于SEMD在扩展过程中需要将微博文本分为5个域并分别进行语义扩展.ESAC与SCS-ES算法的搜索响应时间非常接近,说明SCS-ES在线搜索部分的效率与对比算法是同一量级的,没有激增的现象.因此说明SCS-ES算法在注重搜索精度的前提下能够保证搜索效率的稳定.
4 结束语
在微博短文本搜索中,由于文本描述的随意性和不规范性,使得基于文本语义的搜索具有一定的挑战性.本文提出了短文本的社交与概念化扩展搜索方法SCS-ES,利用概念词语和关联标签丰富短文本语义进行扩展搜索,从而提高搜索质量.实验结果表明本文提出的方法在微博短文本的搜索任务中表现的搜索性能优于其他语义分析及扩展搜索方法,对于P@K,NDCG和MAP指标有明显的提升.下一步的工作将围绕如何有效地在微博环境下利用标签等社交属性挖掘微博热点话题,以及如何进一步提高微博事件挖掘和搜索的质量.

CuiWanqiu, born in 1990. PhD candidate. Her main research interests include social network analysis, machine learning and information retrieval.

DuJunping, born in 1963. Professor, PhD supervisor. Distinguished member of CCF. Her main research interests include artificial intelligence, data mining, social network analysis and search, computer applications.

KouFeifei, born in 1989. PhD candidate. Her main research interests include semantic learning and multimedia information retrieval and recommendation (koufeifei000@126.com).

LiZhijian, born in 1994. Master candidate. His current research interests include machine learning and cross-media search (114898070@qq.com).

LeeJangMyung, born in 1957. Research Group Leader for Logistics and IT. His current research interests include intelligent robotic systems, ubiquitous port, and intelligent sensors (jmlee@pusan.ac.kr).
