数据驱动知识资源配置服务研究
2018-08-03蒋仲仁马瑶珠
蒋仲仁,马瑶珠
(浙江国际海运职业技术学院,浙江舟山 316021)
0 前言
2018年,我国社会制造业发展迎来新的时代。“互联网+”和“大数据”已经成为当前社会的热门话题。传统的生产模式和制造技术已经无法满足用户日益增长的产品个性化需求。取而代之的是先进设计理念和现代制造技术。而这些关键方法和技术都蕴藏在各类知识资源中——包括文献、专利、著作等,并且以知识载体——人的形式体现[1]。因此制造企业寻求技术突破,关键问题是做好知识资源优化配置。即如何让正确的“人”采用正确的“方法”解决“正确问题”。文献[2]首次提出3层次模式知识需求架构;文献[3]提出数据驱动产品概念设计需求模型的构建方法;文献[4]提出了知识模块搜索算法和面向知识资源配置服务的知识模块推荐研究;文献[5]、[6]对小世界网络模块分析进行详细研究。本文在以上研究基础上,提出一种模块化知识资源配置服务,首先采用数据挖掘技术构建产品知识需求模型,其次采用复杂网络的方法构建知识资源协同网络,最后采用模块分析方法为产品知识需求配置资源。
1 产品知识需求模型的构建
互联网时代,用户对产品的个性化需求日趋复杂,他们常常通过论坛、微博等渠道对产品进行评价,用户作为产品的使用者,关注的是性能、功用和服务等需求,统一称之为产品的功能需求。企业作为产品的生产者,需要关注的是产品功能需求背后所涉及的技术、流程和标准等(即知识需求),并将它们转化为面向知识资源配置服务的统一模型,称之为知识需求模型。如图1所示。

图1 数据驱动产品知识需求模型构建体系
从该模型中可以看到,用户对产品的需求是基于产品的功能,包括了基本功能和个性化功能。基本功能是指产品的外观、操作、结构、性能、材料、价格等包含产品本身制造、购买和使用时所具备的通用功能;个性化功能是指产品在满足基本功能的前提下,对某一部分功能进行增删、改进等使之满足用户的特殊需求。
1.1 面向用户的产品功能需求模型的建立
用户对产品的需求通常通过评价来表现。互联网时代更多采用网络获取的方式获得用户的评价。运用网络爬虫的方式对用户在论坛等社交媒体上发表的相关评论予以检索,获取关键字和比较词,结合情感分析技术获取用户的需求,对其按一定量化规则进行多维建模,形成面向用户的产品功能需求模型。
1.2 面向知识配置服务的知识需求映射方法
功能需求与知识需求之间具有复杂的映射关系。一种功能(问题)的实现(解决)或许需要用到多种知识(操作、文本、软件等)。比如解决“转轴与滑动轴承之间容易出现磨损”所需的知识可能是“降低光滑圆柱面的加工误差”、“降低光滑圆柱面的圆度误差”或者是“减少表面粗糙度”等。通过映射建立知识需求模型,实际上是对功能需求的专业化描述。如图2所示。定义功能单元集合法有两种,一种是通过多个专家进行打分取算数平均数的方式;一种是采用历史数据中的出现与出现的次数比,即随着数据库的扩张,两种方式可互作修正。通过对计算后的N中的元素进行筛选,获取元素的分布,采用0~5整数优化的方法,即0表示不需求;5表示需求度很高。最终获得所需要的知识单元集合N*,N*即知识需求模型。

图2 功能需求-知识需求模型映射
2 基于知识资源协作网络的的知识资源配置服务
本文所提知识资源配置是指对人的配置。人作为知识主体,不同于文本、软件等,具备集团性和主观能动性。研究发现,任何具备一定规模的集团、组织内部,人员之间的协作具备网络拓扑特性,即小世界特性。人们倾向于和具有特定知识、能力、性格的人互相合作,即网络模块化特性。因此,本节的思路是找到关键节点,再利用复杂网络进行模块化配置。
首先构建知识资源协作网络,本文选取本单位206名教师作为节点,将他们之间有过任何合作关系(比如发表论文、课题研究、合作授课等)的连接为边,边权为合作次数。这就组成一个小世界网络,本文称之为知识协作网络。如图3所示。
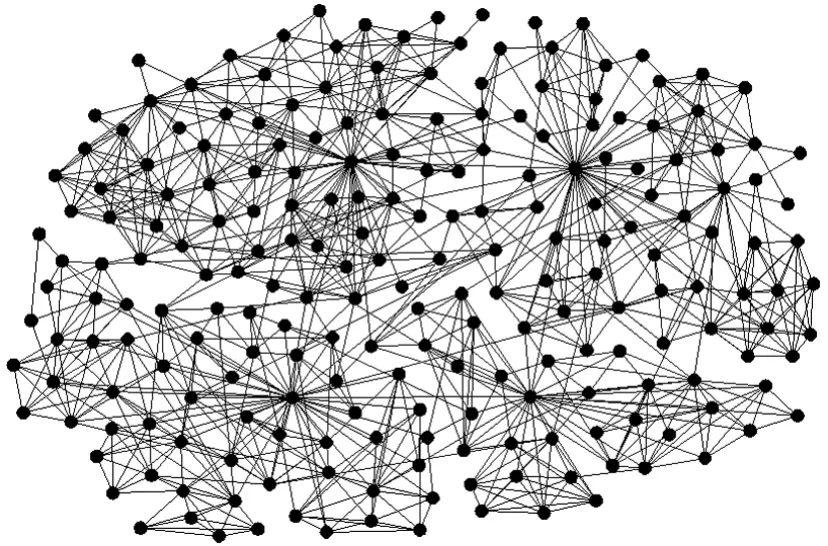
图3 包含206个节点的知识资源协作网络构建
2.1 知识资源协作网络的模块划分
任何一个小世界网络都呈现模块特性,模块中的各个节点协作较为密切而与外部的协作较为稀疏,每个模块都有一个关键节点(队长)和多个合作节点(队员),每个人的重要性不同却都扮演者不可或缺的角色。知识资源配置的核心其实就是找到关键节点,对其所在的知识模块进行配置。因此首先对网络进行模块划分。
采用谱分析算法进行模块划分。令元素w为节点i与j的边权(合作次数),给出206阶协作矩阵A,计算它的拉普拉斯矩阵L=K-1A

计算表明,矩阵L存在多个接近1的特征值(特征向量),也存在多个特征值偏离1特征值。那些较大的特征值对应的特征向量,其元素往往呈现阶梯状分布。利用这种梯度分布的特点划分模块。具体操作如下:选取一定数量的特征值(接近1),通常根据网络规模的大小取4~8个。本文将大于u(u=0.9)的特征值筛选并按照降序排序并选择前4名。如果保留下来的特征值数量小于4个,则稍微减小u的值并重新筛选。计算特征值的最大值对应的特征向量,将向量中的元素按照升序进行排序,最小元素为初始模块(模块数为1),若第n个元素与第n-1个元素的差小于d(初始d=0.02),则这两个元素隶属统一模块,反之模块数+1。实际操作中需要不断减少d以细化划分粒度。

表1 知识资源协作网络的模块划分
模块相关度检验:按照上述方法划分模块,每个模块中包含的节点数量会有很大的差异,因此需要对模块进行相关度检验以便于进一步划分。定义:节点i、j的相关系数计算公式为:

令p为模块中包含的节点数量。给出模块相关度R的计算公式:

本文认为R≥0.8为有效模块,知识模块的节点数量p为6~16个,则两个条件①R≥0.8;②6≤p≤16同时满足则输出模块,否则修正d=0.015进行细化,直到两个条件同时满足或者p≤5为止。
根据以上规则对包含206个节点的知识资源协作网络进行模块划分,结果如表1所示。
2.2 基于关键节点的模块化配置
文献[7]中详细介绍了对人员的知识建模方法,提出在历史信息中提取知识情境,通过“时间、地点、问题、设备、标准、资源、费用、形式”八个维度对人员知识进行表述。而“问题”主要包括“目的、方法、工艺、技术”等信息,其包含内容与本文中的知识需求描述非常接近,因此该维度可以作为知识需求与知识资源之间的接口,将用户需求的知识单元与人员具备的知识单元通过关键词匹配的方式建立连接通道,从而为知识需求匹配相应的关键节点。如图4所示。
2.3 知识模块参数分析
随着网络规模的增大,符合知识需求的知识模块数量会逐渐增多,本文对知识模块内部关键参数进行分析,提供两种模块筛选依据。
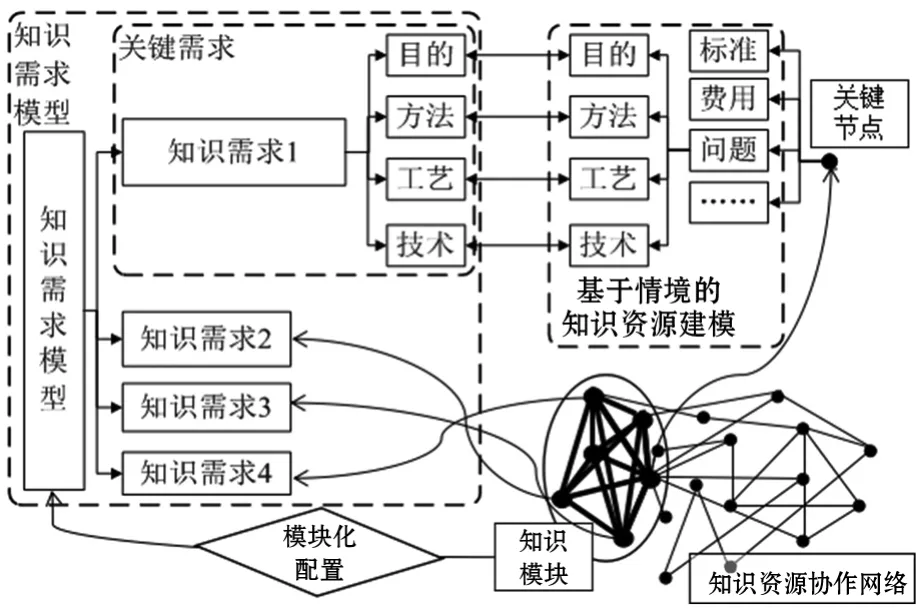
图4 基于关键节点的模块化配置方法
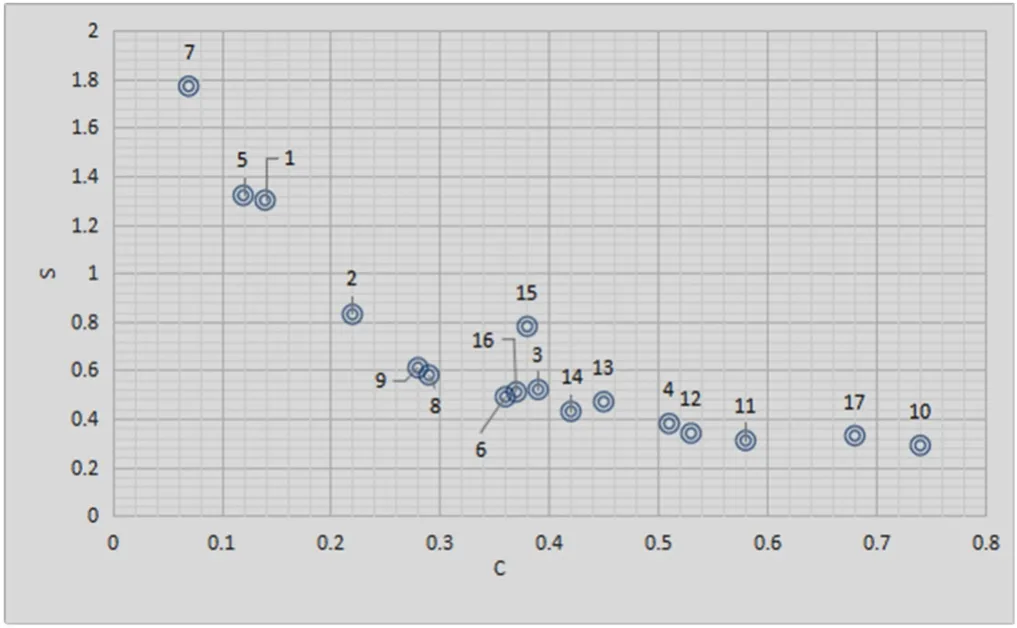
图5 知识模块的C-S分布
图5 反映了上文中17个知识模块的头结点群居系数和协作强度的分布(C-S分布)。在解决实际问题中,建议对于专业性较强、对攻克瓶颈能力要求较高技术问题以前者为主要筛选依据;工作量大、对团队工作效率要求较高的问题已后者为主要筛选依据。
3 总结与展望
本文主要介绍了如何利用大数据和复杂网络,挖掘用户的需求,建立产品功能-知识需求之间的映射关系;核心技术是通过网络模块化以及合理的建模方法实现知识资源优化配置。今后的研究的重点一是进一步优化知识需求模型的多维建模方法,建立更完善的需求-资源数据接口;二是突破现有技术,寻求更优化的模块划分方法和知识资源配置方法。
