基于深度学习的中学生英语口语自动评测技术
2018-08-02罗德安夏林中张春晓王立新
罗德安,夏林中,张春晓,王立新
(1. 深圳信息职业技术学院人工智能技术应用工程实验室,广东 深圳 518172;2. 深圳市海云天科技股份有限公司创新研究院,广东 深圳 518057)
引言
随着计算机自动语音识别(Automatic Speech Recognition,ASR)技术的发展,基于ASR的口语自动评测技术(Automatic Scoring)成为语音人工智能技术的一个重要应用[1-3]。近年来,随着深度神经网络(Deep Neural Network,DNN)结合传统的隐马尔可夫模型(Hidden Markov Model,HMM)在语音识别上取得的巨大成功,基于DNN的口语评测技术备受关注,已经成为计算机辅助语言学习(Computer-Assisted Language Learning, CALL)领域的主流研究方向。随着外语口语自动评分技术可靠性的不断提高,机器评分不仅仅广泛应用于学生平时的口语练习,近年来在升学和资格考试等相关考试中也得到了采用[1-2]。
在实际的大规模口语考试环境中,相对于实验室里可控制条件,考场音频因为设备的多样化、多人同时说话、考场实际状况等因素,不可避免的带来不稳定的噪音干扰。此外,目前主流的外语口语评分技术,是通过大规模母语说话人的语音数据建立用于描述正确发音概率分布的声学模型(Acoustic model),对非母语的考生录音进行语音识别并计算代表发音流利度的后验概率,以及其它跟发音和语言运用能力相关的指标特征量作为机器对考生音频进行评分和诊断的基本依据。然而,声学模型训练使用的海量母语说话人语音数据与本研究口语评测对象的中学生的音频数据相比,在说话人的年龄构成、说话习惯、录音条件等存在着各种差异,会造成语音识别和评分性能的降低。在语音识别领域,这种模型和测试数据之间的不匹配(mismatch)现象可以通过说话人及环境自适应(Speaker and environment adaptation)来提高识别精度。而在基于ASR的口语评测领域,本文第一作者做了大量的研究, 取得了明显的效果[3-4]。
过去的研究主要针对公开数据集或实验室等限定环境下的录音数据,针对外语学习者的朗读(Reading aloud)、影随跟读(Shadowing)、英语配音(Dubbing)等各种外语口语练习方法的学习者语音进行自动评测,成果发表在INTERSPEECH等语音界顶级国际会议中[5-7],并应用在日本、澳大利亚及中国的大学和中学英语口语教学中。近年来,最前沿的语音技术应用到了大规模口语考试中,如2017-2018年,口语评测技术在浙江省数市的中考、深圳市高三英语质量调研统一考试等大规模考试中获得了成功的应用,取得了良好的社会和经济效益[8]。
本文基于深度学习的语音识别及口语评测基本原理,介绍了中学生英语口语考试自动评测技术上的最新研究。通过合作企业考试系统实际采集的大规模统一考试音频数据集进行了实验,验证了改良算法的有效性。
1 口语自动评测原理和算法
1.1 基于深度学习的语音识别

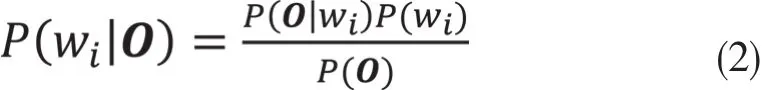
深度学习在语音识别中的应用,并没有改变语音识别基于HMM模型的基本架构。在当前最为流行的深度神经网络/隐马尔可夫模型混合系统(DNN-HMM hybrid system)架构中,DNN的作用在于通过深度神经网络输出的后验概率除以从训练数据中获得的先验概率来近似地计算出HMM每一个状态生成的似然度概率,并取代传统的通过高斯混合模型(Gaussian mixture model,GMM)获得的似然度,从而获得性能上的大幅提升。大部分研究文献中,把传统的GMM模型称为GMM-HMM,而基于深度学习的混合模型称为DNN-HMM,本文亦沿用这种称法。
1.2 用于口语评测的GOP算法
基于音素后验概率的Goodness of Pronunciation(GOP)算法,最早由剑桥大学S.M. Witt等人提出[9],作为发音流利度的指标,被广泛应用于口语评测中。GOP分数的定义如下:

在DNN-HMM 混合模型中, 微软亚洲研究院W.Hu等人提出了帧平均后验概率的GOP实现方法[10],其定义如下:

1.3 本研究对传统方法的改进
在对不同的口语考试数据集进行的实验中发现公式(4)中基于深度学习的GOP比公式(3)中用传统GMM-HMM模型计算的GOP性能更加优越。这主要得益于DNN模型更能从海量训练数据的高维度特征中获得对各音素发音概率分布的更正确描述,建立的声学模型更具备区分度。
但是在对上述两种方法进行深入分析后发现,公式(4)的方法只是简单地把DNN针对测试数据输出的后验概率,对于识别出来的音素 p 的长度,求出该音素的帧平均概率。而公式(3)的方法尽管使用的是GMM-HMM声学模型,其分子和分母都使用到了声学模型对考生测试音频的识别结果,如引言所提,声学模型一般是用母语说话人的海量语音数据训练而来,与测试数据(在本研究中是指考生音频)不可避免的存在着录音环境和说话人特性的不匹配。尤其是真实场景下的口语考试数据,与训练声学模型用到的相对安静环境下录音数据相比,具有较大的差异。公式(4)的GOP算法只用到了一次DNN声学模型计算考生音频的后验概率,模型和测试数据在环境和说话人的不匹配因素会影响它的评分性能。而公式(3)因为分子和分母同时运用了声学模型对考生数据进行识别,不匹配的因子因为同时出现在分子和分母中,某种程度得到了抵消。
因此,公式(4)的GOP计算方法更能利用DNN模型的高区分度优势,而公式(3)的计算方法则更不容易受环境及说话人不匹配因素的影响,具有更强的抗噪鲁棒性。结合两种方法的优点,本文提出一种新的GOP计算方法,该算法既能充分利用DNN带来的高区分度模型优势,又能抵消噪音干扰。其计算过程如下:
首先针对公式(3)的分子部分,用DNN输出的状态后验概率除以状态先验概率来取代GMM的似然度:


其中 S 是所有DNN-HMM状态的集合(又称作senone),把式 (5) 和式(6) 代入到式(2), 得到新的GOP实现方式:

公式(7)既使用了深度神经网络的后验概率输出,又因为在分子和分母中同时进行了声学模型和测试数据的比对计算似然度概率,相对于公式(4)的方法更具抗噪鲁棒性。
由于公式(7)和公式(4)一样,还是基于每一帧的后验概率在音素长度范围内进行平均。而发音的过程是连续变化的,按帧切分计算每一帧相对于某个音素 p 的后验概率,尤其在三音子跨音素模型(Triphone models)中,HMM状态(或者DNN里的senone)和每一帧特征量的对齐未必非常精准,容易造成局部误差。因此,把音素 p 的整个发音段看作一个整体,将状态级别的对齐模糊化,从而提高GOP的准确率。具体做法是从DNN-HMM模型中把中间音素为 p 的所有senone(状态)找出来形成一个集合,每帧相对于 p 的后验概率不是根据状态强制对齐的结果,而是集合内的所有状态后验概率的最大值。具体的公式如下:
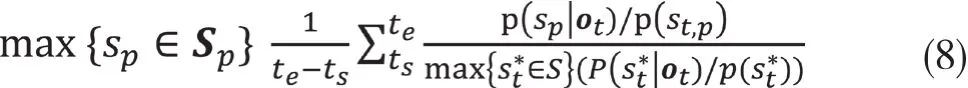
2 实验设计和结果
为了验证改良GOP算法的有效性,本研究使用了两套真实考试场景下的口语数据进行了验证实验。第一套数据是浙江省某市2017年中考口语模拟考试,共有5400人的朗读题录音,每位考生的答题录音都由当地教育部门组织专家进行人工评分,作为测试我们评分系统的指标。第二套数据是2014年深圳市高三英语质量检查口语统一考试的朗读题录音数据,排除异常后选取了6000人考生的答题音频。跟中考数据一样,每位考生都有教育部门组织的专家评分。
计算GOP得分的声学模型采用开源语音识别平台Kaldi进行训练[11],训练语料为开放的大规模朗读语音库Librispeech[12],包含了共960小时的母语朗读数据。DNN-HMM的训练方法采用Kaldi平台业内最先进的TDNN_F深度神经网络[13],而GMM-HMM模型的训练则遵循Kaldi官方发布的训练脚本。值得一提的是,为了体现本研究提出的算法的普遍优越性,本次实验并未对声学模型进行针对测试集数据的优化,而采用开放的工具与数据。
基于GMM-HMM的公式(2)的算法称为GMM-GOP,公式(4)的算法称为DNN-GOP,改进后的两种GOP算法,即公式(7)和公式(8)的算法分别称为DNN-GOP2和DNN-GOP3。用这四种不同的算法,对考生朗读音频求出每一个音素的GOP分数,并按照识别出的所有音素个数求平均,最终得到该音频的整体GOP分数。这四种算法在浙江中考模拟考试数据集中,GOP分数和专家评分的相关系数在表1中显示。表2则是机器评分在深圳高三模考数据集中的表现。

表1: 中考模考数据集中机器分与专家分的相关系数.Tab.1 Correlations between automatic scores and manual scores in the dataset of Senior High School Entrance Exam

表2: 高考模考数据集中机器分与专家分的相关系数.Tab.2 Correlations between automatic scores and manual scores in the dataset of College Entrance Exam
由两表中可见,基于DNN的GOP算法优于传统GMM-GOP算法,而本文提出的改良算法DNNGOP2表现比微软亚洲研究院提出的DNN-GOP1优越,DNN-GOP3进一步提高了评分性能。无论在中考还是高考模考数据集中都得到了同样的验证。
本文针对这四种GOP特征训练了单回归模型,通过留一交叉验证,求出机器拟合分数和专家分数的一致率,结果分别在表3、表4中体现。其中完全一致率和基本一致率是业内统计高考和中考多方评分一致度的指标,完全一致率指的是两者误差范围在15%以内,基本一致率是指误差范围25%以内的分数。从一致度的角度分析,我们提出的DNNGOP2和DNN-GOP3也比传统的GMM-GOP和微软亚洲研究院提出的DNN-GOP1性能更优越。从而验证了前面这两种方法更具抗噪鲁棒性。
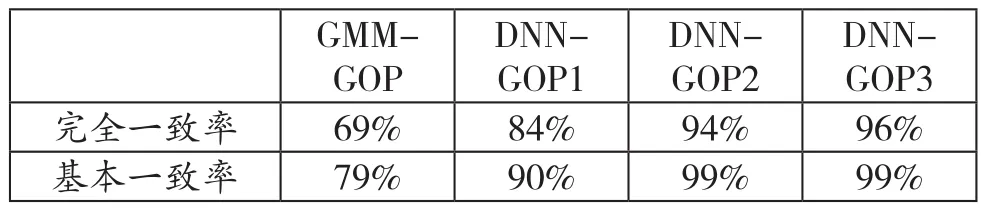
表3: 中考模考数据集中机器分与专家分的一致度Tab.3 Concordance rates between automatic scores and human scores in the dataset of Senior High School Entrance Exam

表4: 高考模考数据集中机器分与专家分的一致度Table 4 Concordance rates between automatic scores and human scores in the dataset of College Entrance Exam
3 结束语
本文介绍了基于深度学习的口语自动评分基本原理,针对传统方法和相关研究进行了对比分析,提出了两种更具抗噪鲁棒性的GOP算法,并在中考和高考模考真实场景数据集中验证了其优越性。
今后我们将在环境与说话人自适应方面对考生和考场数据进行更有针对性的语音建模,同时对发音错误检测和中学生口语特点进行更深入的分析,形成完整的口语教学辅助系统。
