基于VMD-SE-IPSO-BNN的超短期风电功率预测*
2018-07-30殷豪董朕孟安波
殷豪,董朕,孟安波
(广东工业大学 自动化学院, 广州 510006)
0 引 言
为满足不断增长的全球电力需求,可再生能源的使用有了明显的提升。在这些可再生能源中,风力发电所占比重最大。风电的不稳定性是风电系统与主电网结合的障碍之一,为了更安全有效的利用持续增长的风能,高精度的风电功率预测方法对电网运行有着重要意义[1]。
风电功率预测面临的最大挑战是它的间歇性和不确定性特征,这种随机波动是引起预测误差的主要因素。目前的预测方法可分为基于物理模型和基于历史数据预测两类方法[2]。复杂的物理模型总是依靠数字天气预报(NWP)系统,但所需的输入数据通常很难获得。基于历史数据预测的方法较多,它们包括时间序列法[3],灰色模型方法[4],人工神经网络[5],支持向量机[6]等。每种方法都有自己的优点和限制。人工神经网络具有自适应的特点,因此在风电功率预测中得到广泛应用,但神经网络训练过程中容易陷入局部最小值。粒子群算法[7-8]由于简单、鲁棒性好、易于实现和收敛速度快等特点被广泛应用于神经网络的参数优化问题,但常规粒子群算法在迭代时可能存在早熟收敛问题。组合预测由于其高精度性逐渐得到比上述单一预测方法更广泛的应用,如文献[9]利用经验模态分解和支持向量机建立风电功率预测模型,比支持向量机和灰色预测模型表现出更高的精度。文献[10]用改进的集成经验模态分解和时间序列建立组合预测模型,将风电功率时间序列分解成若干固有模态函数,然后建立ARMA模型对各分量进行预测,叠加重构全部分量的预测结果作为风电功率的最终预测值,实例验证组合预测模型可以有效降低超短期风电功率预测的误差。
基于此,提出一种基于可变模式分解-样本熵和改进粒子群算法优化贝叶斯神经网络的超短期风电功率预测模型。首先,采用可变模式分解-样本熵将原始序列分解为多个不同带宽的子模式。然后,对各子模式分别建立贝叶斯神经网络的预测模型,采用改进粒子群算法优化贝叶斯神经网络的权值和阈值提高预测精度。最后,叠加全部分量的预测值得到实际预测值。实例验证表明:所提超短期风电功率预测模型能获得优良的预测精度。
1 可变模式分解-样本熵
1.1 可变模式分解
VMD是将实值信号分解成不同模式分量uk的信号处理技术,其在产生主信号时具有特定的稀疏特性。设每个模式uk具有一个在分解过程中确定的中心频率ωk,则每个模式的稀疏特性是其在频谱域中的带宽。获得模式带宽的步骤如下:(1)对每个模式uk应用希尔伯特变换以获得单侧频谱;(2)对每个模式uk通过与其对应的中心频率ωk的指数项混叠,将频谱变换到“基带”;(3)通过解调信号的H1高斯平滑即L2范数梯度的平方根估算每个子模式的带宽。则其求解可转化为以下优化问题来实现分解处理[11]:
(1)
式中f(t)是待分解主信号;{uk}:={u1,…,uK}和{wk}:={w1,…,wK}分别表示所有模式的集合及其中心频率;δ(t)是狄拉克分布;*表示卷积。为解决约束,采用惩罚项和拉格朗日乘数λ将式(1)变为如下一个无约束优化问题[11]:
L({uk},{wk},λ)=
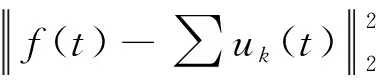
(2)
式中α为平衡参数;λ为拉格朗日乘子。使用乘子交替方向法来求解最小化问题,可变模式分解的完整算法可以在文献[11]中找到。由此可得:
(3)
(4)

VMD具体步骤如下:
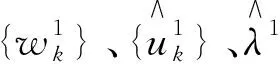
(3)对拉格朗日乘子依式(5)进行更新:
(5)
式中τ为更新参数。
(4)判断下式的收敛条件是否满足,若满足分解过程结束;否则,迭代次数n加1,转(2)。
(6)
1.2 样本熵
样本熵由Richman[12]于2000年提出,用于评价时间序列的复杂度。若序列的自相似性越高,样本熵值就越小,序列越复杂,其样本熵值就越大。具体计算熵值步骤见文献[13],样本熵的参数设置与文献[13]相同。
2 贝叶斯神经网络
神经网络性能优劣与其网络规模息息相关,网络规模主要由神经网络的权值和阈值大小决定,小权值和阈值的神经网络具备更好的泛化能力。贝叶斯神经网络通过正则化的方法对网络的训练性能函数进行修正,限制权值和阈值大小,从而提高神经网络泛化能力。传统前馈型神经网络采用均方误差公式MSE作为训练性能函数:
(7)
式中N为样本总数;ei为误差;ti为目标输出值;ai为神经网络预测输出值。
贝叶斯正则化法在原有训练性能函数的基础上,将网络权值的均方差引入到性能函数中,构成式(8)所示的新的训练函数:
msereg=βEd+αEw
(8)
(9)
式中msereg为改进后的误差函数;α、β为正则化参数;Ew为网络所有权值平方和的平均值;Wi为网络权值。
网络训练过程中,正则化参数通过式(10)进行自适应地调整,从而达到最优训练的目的。
(10)
式中γ=N-2αtr(H)-1;H为msereg的海森矩阵。
修正后的训练性能函数可以使神经网络在训练的过程中能够减少陷入局部最小值或者过度训练情况的发生,但传统的权值阈值调整方法很难保证得到最佳的网络参数。
3 预测模型的参数优化
贝叶斯神经网络虽然通过修正误差性能函数提高了泛化能力,但传统的神经网络参数优化方法无法获得最优网络参数,而基本粒子群算法在针对神经网络这种大规模参数优化问题时存在早熟收敛问题,故本文提出一种改进的粒子群算法用于贝叶斯神经网络的权值和阈值寻优。
3.1 标准粒子群算法
PSO算法由于参数设置少和收敛速度快的特点而得到广泛应用,但算法寻优过程中存在早熟和局部最优问题[14]。粒子更新过程中产生个体最优极值和全局最优极值,个体最优极值是个体寻优过程中的最优解,全局最优极值则是全部粒子寻优过程中的最优解。其更新公式如下:
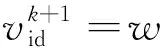
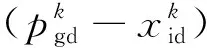
(11)
(12)
式中r1、r2为[0,1]之间的均匀分布随机数;c1、c2为加速因子;w为惯性权重;v是粒子的飞行速度;x表示粒子;pgd和pid分别表示全局最优极值和个体最优极值。
PSO与遗传算法、蚁群算法等绝大多数启发式算法相似,在算法迭代后期种群多样性会急剧下降,形成“聚集”现象[15],导致过早收敛的问题。
3.2 改进粒子群算法
3.2.1 种群方差计算
针对PSO的早熟收敛问题,本文提出以下改进:由式(11)、式(12)可知,PSO是向个体极值和全局极值运动产生新的个体,当迭代达到一定次数时会出现“聚集”现象,种群中的个体差异几乎为0,即式(13)求出的整个种群的方差E趋于0。
(13)
式中M为种群大小;D为粒子维数;gen为粒子当前迭代次数。
由于个体间无差异导致无法产生新的突变个体,导致整个种群陷入局部最优值,故本文提出在执行粒子群算法之前进行种群方差计算,当种群方差E小于某一极小值MV(通常取10~20)时则不执行粒子群算子,转而进入引进的维度交叉算子。
3.2.2 维度交叉算子
维度交叉算子是对种群中所有维进行随机两两不重复配对后,以概率Pv的形式选择配对维执行纵向交叉的一种算数交叉操作。由于不同维之间取值范围可能不同,执行维度交叉算子前对个体的每一维进行归一化处理。每次维度交叉只需产生一个子代维,其目的在于在保证其他正常维不被破坏的前提下,使陷入局部最优的维从中顺利跳出。例如粒子X(i)的第d1维与和d2维进行维度交叉,则根据式(14)产生新的子代维:
MSvc(i,d1)=r*x(i,d1)+(1-r)*x(i,d2)
(14)
式中d1,d2∈N(1,D);r∈[0,1];i∈N(1,M);MSvc(i,d1)为父代粒子x(i)的第d1维和第d2维执行维度交叉后产生的子代;x(i,d1)和x(i,d2)分别是第i个粒子的第d1、d2维。
绝大部分算法存在的收敛过早问题通常是由于种群个体中的局部维停滞不前,称为维局部最优。故对粒子群算法引入维度交叉算子,利用维度交叉特有的摆脱维局部最优能力,有效解决PSO的早熟问题,改善PSO迭代到一定程度后种群多样性不足的缺陷,从而提高PSO的全局搜索能力。
3.2.3 参数优化步骤
基于IPSO的BNN权值和阈值优化步骤如下:
(1)确定BNN结构为“m-k-n”形式,则粒子变量维数D=m*k+k*n+k+n,m和n分别为神经网络的输入和输出个数,k为隐含层节点数;
(2)参数初始化。设置IPSO种群大小M,最大迭代次数Maxgen,初始权重和加速因子,维度交叉概率Pv。随机生成IPSO的初始种群;
(3)迭代次数t置1。将IPSO初始种群粒子转换成BNN的权值和阈值,进行网络训练,由式(8)计算训练误差,即为粒子的适应度值;
(4)fort=1:Maxgen,进入迭代过程;
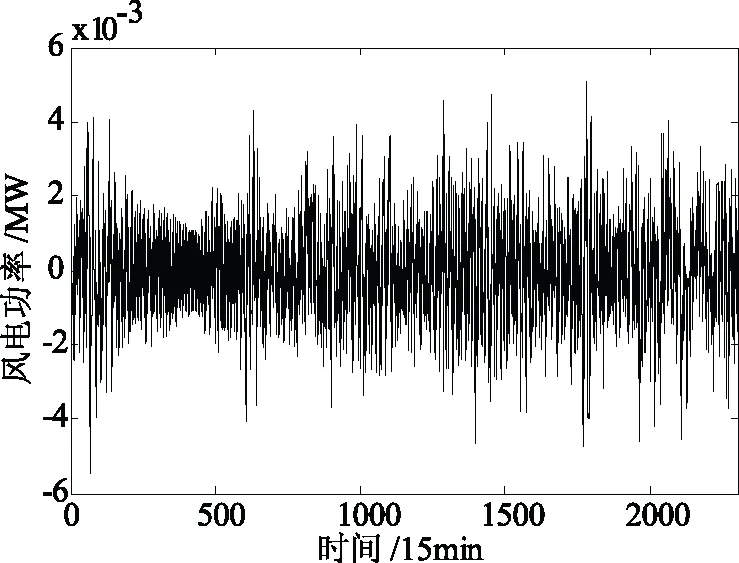
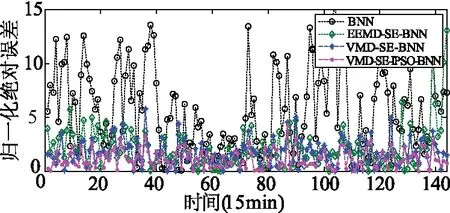
(a)执行式(13)计算IPSO种群的方差E,若E>MV,则转(b);若E (b)执行标准粒子群算法中的粒子更新算子,将其产生的子代种群保存在矩阵SPSO中,然后根据式(8)计算矩阵SPSO每个粒子的适应度,并将其与父代种群X中所对应的粒子进行对比,选择适应值更优的粒子作为新的父代粒子保留在X中,记录最优粒子Xbest,转(5)。 (c)对粒子所有维进行随机配对(共D/2对),选取一对维数,若rand() (5)当迭代次数t 本文实验样本为广东某一风电场2016年1月实际采集的24d(1月1日到1月24日)风电功率数据,每15 min一个数据点,每天共96个数据点,风电场的额定装机容量是10.02 MW,风电功率时间序列如图1所示。 (1)由于图1所示风电功率时间序列无明显的变化规律和趋势,非线性程度较高,故采用VMD对图1所示数据进行分解,得到多个呈现一定波动趋势的不同带宽的子模式。 图1 风电功率时间序列 (2)采取交叉验证的方式确定模式个数,即计算不同模式个数情况下VMD-BNN的模型训练误差。如图2所示,结果表明随着分解模式个数增加时,模型训练误差逐渐减小,但在模式个数达到8个以后,训练误差无明显改善,几乎保持不变,此时增加分解模式个数仅增加计算成本,而不会对预测精度有较大的改善。鉴于此,选取分解模式个数为9个。 图2 不同模式个数下的模型训练误差 (3)VMD分解后得到9个子模式,若直接利用IPSO-BNN对每一个子模式分别建模预测,会增大计算的规模。故采用样本熵理论,对各子模式的复杂度进行分析,得到的结果如图3所示。 图3 各子模式的样本熵 从图3 可知,第3~6个子模式的样本熵相差不多,可以把这4个归为一类,叠加重构后作为一个新的子模式输入BNN进行训练和预测。同理全部子模式的归类重构结果如表1所示,归类重构后的各子模式如图4所示。图5为分解重构风电功率信号的重构误差。从图5可以看出,分解重构误差值较小,相对于实际功率值可忽略不计。 表1 各子模式合并为新子序列的结果 图4 经VMD-SE处理后的风电子模式 图5 风电功率信号重构误差 (4)建立4个IPSO-BNN预测模型,对上述4个子模式分别进行训练与预测,最后各子模式预测值的累积即为风电功率预测输出值。 (5)误差分析。预测误差评价函数采用归一化绝对平均误差eNMAE和归一化均方根误差eNRMSE。 (15) (16) 文章将第4节中1月22日12点前的数据进行模型训练,即前2 160个点为训练样本,第22日12点15分到24日的数据进行测试验证,测试数据共144点。采用输入维数为8维提前4步的一次多步预测,一次预测得到4个点即1 h的测试数据,反复进行36次多步预测,即一次4步预测后,把刚测试完的实际功率数据输入预测模型中进行训练,继续新一轮的4步预测。同时为验证本文模型的有效性,建立BP-NN、BP-BNN、PSO-BNN、IPSO-BNN、EEMD-SE-BNN、VMD-SE-BNN、VMD-SE-PSO-BNN和VMD-SE-IPSO-BNN 8种预测模型进行对比分析。本文所有的仿真实验均在Matlab R2011b版本环境下进行, 采用宏基4 750 G.2.3 GHz双核处理器, 3.0 G内存的计算机平台。 BNN结构为“8-6-4”形式,选择Tansig函数和purelin函数作为隐藏层和输出层的传输函数,学习率设置为0.1,目标误差为0.01,训练最大次数500。IPSO种群大小设为30,最大迭代次数设为300代,初始权重设为0.9,加速因子设为0.2,维度交叉概率设为0.55。 为避免随机性对预测结果的影响,各模型每次实验均独立运行30次,取平均误差,表2给出了不同模型的预测误差,图6给出了文章模型的最优预测曲线,4步预测归一化绝对误差如图7所示。 表2 不同模型的预测误差 由表2可知: (1)对比BP-NN和BNN可知:后者的eNMAE和eNRMSE分别提高了0.26%和0.44%,说明贝叶斯神经网络能取得比传统BP神经网络更高的预测精度,具有更强的泛化能力; (2)PSO-BNN和IPSO-BNN与BNN相比,eNMAE和eNRMSE均有所提高,说明采用智能算法优化神经网络的权值和阈值有利于提高预测精度; (3)IPSO-BNN的eNMAE和eNRMSE较PSO-BNN提高了0.18%和0.45%;VMD-SE-IPSO-BNN的eNMAE和eNRMSE较VMD-SE-PSO-BNN提高了0.17%和0.32%,说明改进的粒子群算法比基本粒子群算法具备更强大的全局搜索能力,提高了模型的预测精度; (4)VMD-SE-BNN的eNMAE和eNRMSE较EEMD-SE-BNN分别提高了0.5%和0.29%,说明基于 VMD-SE 的组合模型具有更优良的预测性能; (5)文章所提VMD-SE-IPSO-BNN模型具有最高的预测精度,相对于单一的BNN模型,它的eNMAE和eNRMSE分别提高了4.57%和4.45%,预测精度得到大幅度提升,说明所组合预测模型的有效性和高精度性。 由图6可以看出,单一的BNN和IPSO-BNN虽然能大致跟踪风电功率的变化规律,但各点的预测值与实际值相差较大,而本文VMD-SE-IPSO-BNN在各个预测点的预测值均与实际值较为接近,是一种较高精度的超短期风电功率预测模型。由图7可知,与单一的BNN模型相比,组合模型的在各预测点的预测误差更小,说明组合预测模型的有效性和高精度性;本文所提VMD-SE-IPSO-BNN在大部分预测点的归一化绝对误差相对较小,能够取得较高精度的超短期风电功率预测结果。 图6 本文模型的风电功率预测曲线 图7 4步预测归一化绝对误差 针对非线性风电功率时间序列的超短期预测,提出一种基于可变模式分解-样本熵和改进粒子群算法优化贝叶斯神经网络的组合预测模型,实例研究表明: (1)贝叶斯神经网络比传统BP神经网络具有更高的预测精度,显示出其在超短期风电功率预测中的应用潜力; (2)与PSO相比,采用IPSO对神经网络进行权值和阈值寻优时预测精度更高,表明IPSO具有更优良、更稳定的全局寻优能力; (3)与EEMD-SE相比,基于VMD-SE的组合模型具有更优良的预测性能,有效提高了预测精度。本文所提组合模型能取得较高精度的超短期风电功率预测结果。4 基于VMD-SE和IPSO-BNN的风电功率预测模型






5 算例及结果分析


6 结束语
