基于Spark框架的能源互联网电力能源大数据清洗模型*
2018-07-30曲朝阳张艺竞王永文赵莹
曲朝阳,张艺竞,王永文,赵莹
(东北电力大学 信息工程学院,吉林 吉林 132012)
0 引 言
随着《中国电力大数据发展白皮书》[1]的发布,带动了电力行业内对能源大数据研究热潮,准确、可靠是保证能源大数据分析处理精准性的基本要求,因此对能源大数据质量提出了更高的要求,能源大数据清洗可有效保证能源大数据质量的正确性、完整性、一致性、可靠性。
能源大数据具有数量大、维度高,数据模式繁多等特征,在能源大数据的采集过程中,其不可避免的存在异常数据,对能源大数据清洗有很强的必要性。国内外对能源大数据清洗研究主要有聚类和关联分析[2]、条件函数依赖[3]、马尔科夫模型[4]、DS证据理论[5]。大部分数据清洗技术都需要依赖数据模型本身构建异常数据识别规则,对检测到的异常数据做删除或均值填充处理,破坏了数据的连续性、完整性、准确性。综合国内外研究,能源大数据清洗难点表现在以下几点:(1)能源大数据数据模型繁多,数据种类各异,不宜直接构建能源大数据异常数据识别规则。文献[3]提出一种基于hadoop的不一致数据检测和修复算法,但是在预处理阶段,需要用户给定在属性集上的一个关系模式的条件函数依赖CFD。这种方法需要人为因素干预,且能源大数据关系模式复杂、数据信息表样式繁多,很难为每一个关系模式划定条件函数依赖;(2)正常数据多,异常数据少,不同类型的能源大数据很难通过设定阈值来进行简单异常识别;(3)异常识别将异常数据剔除,破坏了数据的连续性;(4)对异常数据进行重构时,需要依赖外源数据。文献[6]提出了基于四分位原理的异常识别和基于风电出力模式性的重构方法,这种异常识别方法容易剔除未识别的正常数据,对缺失的风电功率数据在进行构建时需要依赖临近的风电场功率数据,很容易造成误差。
针对以上能源大数据清洗难点,本文提出一种基于Spark框架的能源大数据清洗模型。模型的基本思想是:首先,用改进的CURE聚类算法对测试样本进行聚类,剔除掉测试样本中的离群点,获取样本点正常的簇,并根据边界样本获取方法获取边界样本集;然后设计边界样本的异常识别算法检测历史或实时流能源大数据中的异常数据;最后通过指数加权移动平均数对检测出的异常数据进行修正,从而达到对能源大数据中异常数据清洗目的。相比一些能源大数据清洗模型,本文数据清洗模型减少人为干预,不需要根据数据关系模式设定识别规则,异常识别算法依赖于历史数据中的正常样本数据,且对异常数据修正是建立在其同一时间序列数据分析的基础上,最终能够实现对历史或实时数据中的异常数据清洗。
1 基于Spark框架的能源大数据清洗模型
能源大数据清洗是对检测到的能源大数据中异常数据进行修正的过程,利用Spark框架构建能源大数据清洗模型时分为以下几个阶段:数据准备、正常簇样本获取、异常数据识别、异常数据修正、修正数据存储。数据准备即将存储在传统关系型数据库中的数据转存在适合于大数据处理的非关系型数据库中,然后加载到Spark的弹性分布式数据集(RDD)中;通过抽取一定数量的能源大数据样本,应用层次聚类算法将其中的异常点抽取,获取可用于实现边界样本异常识别算法的正常样本簇;异常数据识别是建立在边界样本的基础上,通过边界样本异常识别算法完成对能源大数据中的异常数据检测;异常数据修正完成对检测到的能源大数据中的异常数据的修复。基于Spark框架的能源大数据清洗模型框架(见图1),清洗步骤如下:
(1)数据准备:将数据存储在分布式文件系统HDFS中;
(2)从分布式文件系统上读取数据并执行cache操作生成RDDs,将数据读入到内存;
(3)利用改进的并行CURE聚类算法获取正常簇;
(4)从正常簇中选取边界样本数据;
(5)设计基于边界样本的异常数据识别算法,并对测试样本识别异常数据;
(6)标记异常数据所在检测样本中的位置;
(7)对异常数据应用指数加权移动平均数进行修正;
(8)形成修正数据集并保存。
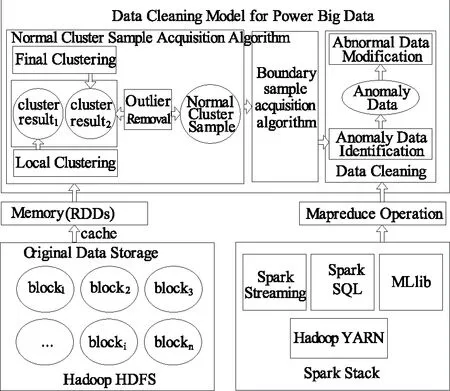
图1 基于Spark框架的能源大数据清洗模型
文中接下来针对能源大数据清洗模型中的几个核心步骤进行分析介绍。首先详细描述了改进CURE聚类算法获取正常簇;其次介绍了边界样本的选择过程,并对边界样本的异常数据识别算法进行了详细分析;最后阐述了指数加权移动平均数对异常数据进行修正。本文在最后给出了实验验证及分析,并对本文工作进行总结并指出进一步的研究方向。
2 正常簇样本获取算法
在对能源大数据进行异常识别时,由于能源大数据在采集过程中采集设备具有数据校验功能,因此采集的数据大多为正常数据,异常数据较少,同时能源大数据的种类繁多导致不能直接构建单一规则或设定阈值进行异常识别。直接对采集上来的能源大数据进行异常识别计算量大且识别效率低。因此可以从能源大数据历史数据样本中获取正常样本簇,在正常簇的边界样本集的基础上对历史或实时能源大数据进行异常识别,这种异常识别不依赖数据属性阈值及属性数学模式规则,同时可提高检测的效率。
如表1所示,CURE聚类算法在对测试样本进行聚类时通过消除离群点降低对聚类结果的影响,可通过CURE聚类算法对测试样本进行聚类获取正常样本的聚类簇。CURE聚类算法分别在两个阶段对离群点进行删除:第一阶段是在聚类增长非常缓慢的类作为离群点删除;第二阶段是在聚类结束时将对象数据明显少的类作为离群点删除。但是通过CURE聚类算法对离群点进行删除时存在以下的问题:(1)很难界定第一阶段的增长速度快慢的类[7];(2)对离群点删除后因局部数据的分布特征存在掩盖现象[8]。

表1 基于改进CURE算法正常簇样本获取算法
针对CURE聚类算法剔除异常点时存在的问题,本文使用离群程度用于判定离群点,可有效解决增长缓慢的离群类难界定及局部离群点被淹没的现象。相关定义如下:
定义1:对每个划分的数据块进行聚类,得到的数据簇表示为,其中表示块中第i个簇,表示为第i个簇的中心点,表示每个中心点的权重值,是每个簇中数据的个数。因此每个划分的数据块可以使用若干个代表,称为代表点。
定义2:设代表点的集合为P,每个代表点的中心点到簇外任意一点的偏差距离表示为离群程度:
(1)
用欧氏距离表示一个点的偏离程度,当某点离簇中心点越远,则离群程度值越大。
定义3:设离群程度集为D,定义离群程度判定值为:
(2)
定义4:设离群参数为,离群程度最小值为,
(3)
定义5:对于离群程度集D中任意di,若di所对应的代表点pi为离群点,其所在的簇中的数据即为离群数据。
3 基于边界样本的异常数据识别算法
本文提出了基于边界样本的异常数据识别算法,首先通过获取正常簇的边界样本集;然后根据异常数据识别算法检测异常数据;最后标记异常数据并记录所在位置。异常数据识别是对能源大数据中历史或实时流数据中的异常数据检测的过程,是建立在正常簇的边界样本的基础上。每个正常簇的边界样本必须具有以下特点:(1)距离质心最远;(2)分散在正常样本的四周;(3)能够代表正常样本的形状。
下面给出一个正常簇的边界样本定义:距离簇质心最远的样本点,且能够代表整个簇的形状,一个聚类簇的边界样本节点是由自己样本节点决定的,与其他样本节点无关,称这类样本节点为边界样本。
在对边界样本点进行选择时,应保持边界样本点的特点,下面给出边界样本的选择过程:
步骤1:计算簇的中心点(n1+n2+...+nm)/m,ni为簇的点,m为簇的点个数;
步骤2:第一个边界样本点为离中心点最远的点,第二个边界样本点为离第一样本点最远的点。
步骤3:接下来选择的边界样本为离前两个样本点距离之和最大的点,直到选取的样本点能够代表聚类簇,则选择停止。正常簇的边界样本选择过程,为每步选出的边界样本点(见图2)。

图2 正常样本簇的边界样本选择过程
边界样本点分散在聚类簇的四周,能够表示聚类簇的形状。利用正常簇的边界样本来识别待检测样本,可以减少异常识别算法的计算量。基于边界样本的异常数据识别算法步骤:
步骤1:计算待测样本T到边界样本bi的距离,T={t1,t2,…,tm},D={d1,d2,…,dn};
步骤2:找到最小距离dmin,边界样本点为l1=dmin=min(di);
步骤3:找到离边界样本最远的点dj,计算到的距离l2=distance(ti,dj);
步骤4:如果l1≥l2,则ti为异常样本点;若l1
步骤5:标记异常数据的所在检测样本中的位置。
通过边界样本异常识别算法,在进行异常识别时,不必设置异常识别的阈值,同时可以避免因使用数据模式带来的复杂性,可以提高异常识别的效率。
4 基于时间序列分析异常数据修正
能源大数据是在一定时间周期内采集的数据的积累,能源大数据因其种类多,随时间变化一般呈现三种规律:周期变化型数据、幅值变化较小型数据、缓慢增加型数据[9]。异常数据在对能源大数据时间序列的影响表现为两种形式:第一种是加性异常点,这类异常点只影响异常点发生的那一时刻上的序列,而不影响该时刻后的序列值。第二种是更新异常点,造成这种异常点的产生不仅作用于在该时刻,而且还会影响该时刻后的一段时间内的所有测量值。
对异常数据进行修正时要根据异常数据所在数据区间数据特点及异常数据表现形式,对不同类型的异常数据进行分析修正[10]。对缓慢增加或衰减型能源大数据中的异常数据进行修正时,选取的参考数据序列为异常数据所在序列的[n,m]区间;对周期性变化型能源大数据中的异常数据进行修正时,选取的数据序列为包含异常数据在内的n个周期内的异常数据所在的时刻t的数据序列。
在对异常数据进行修正时,一般采用的方法是使用该异常数据所在序列的平均数进行代替。这时修正的值为,式中是对给定的一个权值。但是,某一序列值对后面序列值的影响作用是衰减的,而不是一直是。因此对异常数据进行修正采用指数加权移动平均数:
(5)
5 实验及结果分析
本文采用“Spark On Yarn”集群模式构建能源大数据清洗模型实验环境,实验采用6台服务器组成数据清洗集群节点,其中一个节点为Master,其余五个节点分别为Slave1-Slave5,每个节点的配置如表2所示。每个服务器节点采用Ubuntu-12.04.1操作系统,使用Hadoop-2.6.0,Spark-1.3.1,Scala-2.10.5,JDK-1.7.0_79搭建节点的软件环境。实验平台在Scala的Intellij Idea开发环境上进行开发实现,以hadoop的hdfs实现数据结果的存储。

表2 集群配置
以某风电场风力发电监测数据作为数据清洗研究对象[11]。该风力发电监测数据大小为5 GB,分别从5台风力发电机采集,采集间隔为1 s,记录了从2012年2月1日到2012年2月29日风力发电监测数据。文章将从异常识别的准确性、异常修正的效率对能源大数据清洗模型进行验证分析。
实验1:针对正常样本获取过程中离群点删除算法,本文测试了几种离群点检测算法的检测率和误检率,测试结果见表3。与Apriori算法相比,本文算法在检测率相似的情况下,误检率较低。较低误报率有利于保证获取的正常样本质量,保证构建基于正常样本的边界样本异常识别算法的准确性。同原始CURE聚类算法比较,文本所改进CURE聚类算法在检测率和误检率都有所提高。

表3 离群点检测算法比较
实验2:为了验证能源大数据异常识别算法的检测异常数据正确性,实验保持集群节点数固定,不断调整测试数据样本大小,检测算法的准确率,结果如表4。可以看出模型检测到了大部分的异常数据。

表4 能源大数据异常识别算法的准确率测试
实验3:为了验证能源大数据清洗模型的高效性,测试了传统单机数据清洗与基于Spark框架的能源大数据清洗模型不同数量的清洗所需要的时间[12]-[13]。集群节点数固定,不断调整待清洗数据样本大小,测试数据清洗时间,测试结果见表5。排除节点间的网络通信以及任务调度的开销等因素,基于Spark的能源大数据清洗在效率上高于传统单机数据清洗,但执行效率与实验中算法、集群的节点及数据量有关。
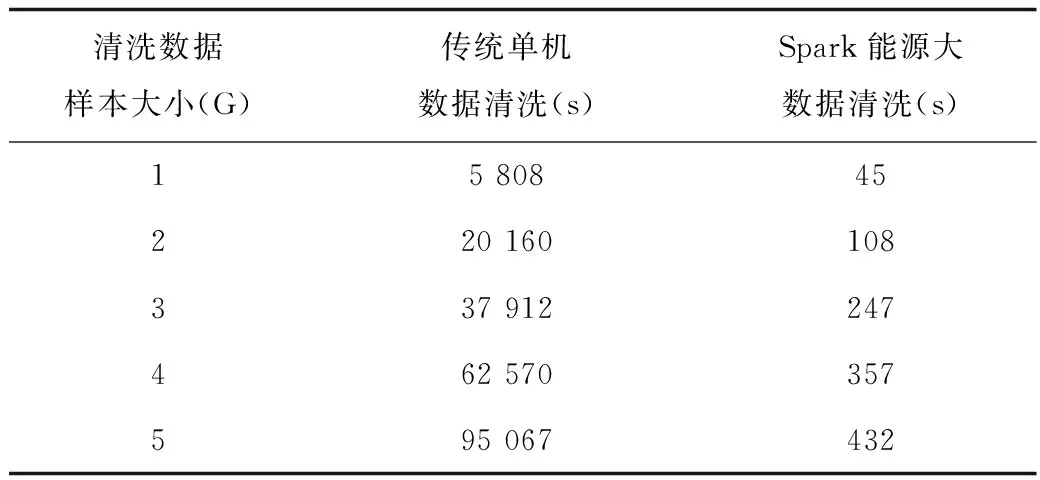
表5 单机及并行数据清洗清洗时间比较

表6 基于边界样本的异常信息识别方法实验结果
实验4:固定测试数据样本大小,从中随机抽取15 000条数据作为实验测试样本,正常簇样本个数为5,每个正常样本簇的边界样本个数分别为25,35,45,55,65,在待识别样本数目固定的情况下,对上述测试样本采用基于边界样本的异常信息识别方法进行异常信息识别,检测正常样本簇的边界样本个数对检测结果的影响,结果如表6所示。
6 结束语
本文分析了能源大数据清洗过程中的若干难点,并针对能源大数据的特点及清洗难点提出了基于Spark框架的能源大数据清洗模型。该清洗模型具有以下特点:(1)异常数据识别无须外源数据;(2)异常数据识别及修正准确性高;(3)利用并行Spark大数据处理框架,具有高效性。但是,本文在选取正常簇的边界样本时仍然存在问题,即何时达到最优边界样本数;其次,对异常数据的修正是建立在同一时间序列的样本上,若该时间序列出现异常对异常数据修正的准确性仍会有影响。针对以上解决问题需要在以后的工作中进一步探讨优化并完善能源大数据清洗模型。
