基于语义网络的英语机器翻译模型设计与改进
2018-07-27卢蓉
卢蓉


摘 要: 针对传统基于规则的机器翻译模型存在英语翻译结果不够精确、难以准确描述词语间关系的弊端,设计并改进基于语义网络的英语机器翻译模型。该模型采用基于向量混合的短语合成语义统计英语机器翻译方法,在翻译相似度模型中,采用余弦相似度的方法获取两个向量的语义相似度,经过带权向量加法的计算极易辨别两个相似向量的不同之处,获取精准的英语翻译结果,对句子实施权值训练获取构成句子的主要短语,保证翻译结果归纳出句子的中心思想。改进基于语义网络的英语机器翻译模型,针对用户需求引入大数据的同时让语言学家参与到机器翻译的过程中,使得英语翻译结果既能独立进行语义表达,又能准确描述词语间关系。实验结果表明,所设计的模型能够精准高效地进行英语翻译。
关键词: 语义网络; 机器翻译; 模型设计; 语义相似度; 语料库; 权重训练
中图分类号: TN912.3?34; TP391.2 文献标识码: A 文章编号: 1004?373X(2018)14?0126?04
Design and improvement of English machine translation model
based on semantic network
LU Rong
(Hainan University, Haikou 570028, China)
Abstract: In allusion to the deficiencies existing in the traditional rule?based machine translation model for its inaccurate English translation results and difficulty to accurately describe the relationship between words, an English machine translation model based on semantic network is designed and improved. In the model, the phrase semantic synthesis statistical English machine translation method based on vector hybrid is adopted. In the translation similarity degree model, the cosine similarity degree method is adopted to obtain the semantic similarity degree of two vectors. The differences between two similar vectors are very easy to be discriminated after addition calculation of weighted vectors, so as to obtain accurate English translation results. The weight training is conducted for sentences to obtain the main phrases that constitute sentences, so as to ensure that the central idea of the sentence is summarized in translation results. In the improved English machine translation model based on semantic network, big data is introduced to meet users′ needs and linguists are invited to participate in the machine translation process, so that not only can semantic expressions be independently conducted, but also the relationship between words can be accurately described in English translation results. The experimental results show that the designed model can conduct an accurate and efficient English translation.
Keywords: semantic network; machine translation; model design; semantic similarity; corpus; weight training
0 引 言
隨着我国综合国力与国际竞争力的增强,与世界各国的贸易往来、文化交流日益加深,英语作为应用最为广泛的语言成为我国与其他国家之间沟通的桥梁[1?2]。因此英语翻译成其他语言的需求日益增强,各种英语翻译机器应运而生。英语机器翻译的历史可以追溯到20世纪80年代,而近十余年来,英语机器翻译技术发生了翻天覆地的变化。现有关于英语的翻译模型设计数不胜数,在某种程度可以满足用户的需求[3?4]。但同样存在问题,大部分都是基于词义排歧、语义角色标注等进行的英语机器翻译模型,本文设计的基于语义网络的英语机器翻译模型既能具备独立进行语义表达的能力,又能具备描述词语间关系的能力,为各领域的用户提供精确的翻译服务。
1 英语机器翻译模型的设计与改进
1.1 基于语义网络的英语机器翻译模型设计
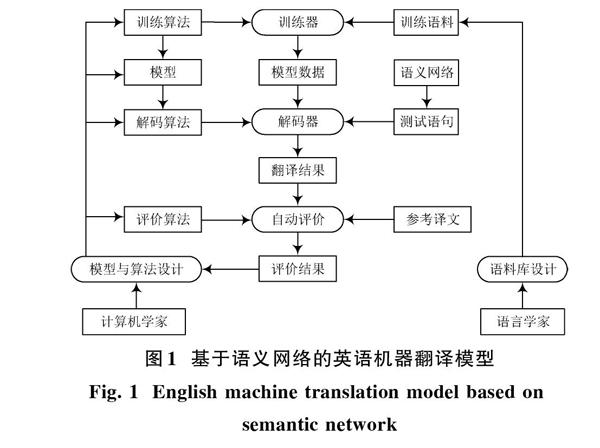
语言学家严格分析翻译结果并进行知识库更新,改善英语翻译器的使用效果。计算机学家的功能是向机器输入固定数值,系统设计成功后,对于翻译结果的灵活度较低,不能进行调整。因此,在基于规则的英语机器翻译研究范式中融入语义网络,塑造基于语义网络的英语机器翻译模型如图1所示。
图1引入了语义网络部分,基于语义网络的统计机器翻译模型的翻译结果更加精确,使得语言学习者的学习效果更加明显,更能在有限时间内高效率地学习英语。知识库变成了包含大量信息的语料库,计算机学家对于算法的设计也更加全面系统。
1.2 短语合成语义统计英语机器翻译方法
1.2.1 翻译相似度模型
相同语义空间中两个不同多维向量[u],[v]的相似程度可以通过语义相似度来描述。向量[u],[v]相似度越大其所代表的向量[u],[v]描述的语义相似程度就越大。予以相似的实际应用越来越广泛,例如,在自然语言分析领域中也融入了语义相似度的概念。语义相似模型在统计机器翻译中的具体表现是翻译相似度模型[5]。在验证分析的过程中,可以通过多种方式获取两个向量[u],[v]的翻译语义相似度,本文对最常用的方法余弦相似度进行举例说明。
1.2.2 余弦相似度
余弦相似度又称为余弦距离,在多维空间中,用两个向量夹角的余弦作为衡量这两个向量间差异大小的标准。当余弦值增大的情况下,两个语义向量间的夹角会减小,那么两个单词的语义就越接近[6];当余弦值减小的情况下,两个语义向量间的夹角会变大,那么两个单词的语义就越不接近。双语向量[u=a1,a2,…,an]以及[v=b1,b2,…,bn]的英语翻译相似度为:[Simu,v=u·vu×v=i=1nai×bii=1na2i×i=1nb2i] (1)
1.2.3 带权向量加法
通过式(2)能够获取相同语料库中两个单词语义向量[u,v]的合成语义向量[p]:
[p=u+v=a1+b1,a2+b2,…,ai+bi]
(2)
设置单词“机器”的语义向量为5维向量[u=2,6,8,7,1],单词“翻译”的语义向量为5维向量[v=1,3,4,5,6],那么根据式(2)得出合成短语“机器 翻译”的语义向量[p=3,9,12,12,7]。
通过带权向量加法获取合成短语的合成语义向量的方式有效地解决前面的错误[7?8],具体的公式如下:
[p=αu+βv] (3)
同樣分析合成语义“机器翻译”的步骤,通过语料库训练后得到的“机器翻译”短语中“机器”的权重是[α=0.6],翻译的权重[β=0.4],根据式(3)获取“机器翻译”的语义向量是[p=2.6,4.8,6.4,6.2,3.0]。
这种情况下,把短语“翻译机器”当成是新的短语,对“翻译”“机器”实施新的权重训练,设置其权重分别是0.3,0.7,获取“翻译机器”的语义向量是[q=1.7,5.1,6.8,6.4,2.5]。再将两者的语义向量结果进行比较发现,这次可以简单地辨别两个短语的不同之处。
通过式(4)可以得到多字短语的合成语义向量:
[p=i=1nλiwi] (4)
式中:多字短语各组合单元的单词语义向量用[wi]表示;各组合单元单词的权重用[λi]表示。
1.3 基于语义网络的英语机器翻译模型改进
上面对机器翻译的现有水平进行了探讨研究,接下来对其未来发展趋势进行展望。
未来的研究中应引进更深层次的语言与知识储备,更加精准先进的技术[9?10]。具体方法是让语言学家参与到机器翻译的过程中,增加新的语言信息、更新语料库的知识储备,以此改进基于语义网络的英语机器翻译模型流程,从科学、高效的角度调整研究范式的工作流程。获取新的基于语义网络的英语机器翻译模型如图2所示。
2 实验分析
2.1 实验数据
为了验证本文设计的基于语义网络的英语机器翻译模型能够获取精确的翻译结果进行实验。实验的数据采用LDC语料的部分子集,包含400万句平行句对;其中包括中文单词9 890万个,英文单词11 260万个。实验的开发集是NIST 05,其中包括1 082个中文句子,每个中文句子下属4个翻译结果,也就是总计4 328个英文句子。实验测试集分别是NIST 06,NIST 08,测试集NIST 06包含1 664个句子,下属4个英文句子,即6 656个英文句子;测试集NIST 06包含1 357个中文句子,下属4个英文翻译句子,即5 428个英文句子。
2.2 实验设置
实验采用层次短语解码器的C++实现版本作为解码器。详细操作步骤如下:英汉、汉英两个方向的词语信息对齐是通过GIZA++工具来实现的,发挥grow?diag?final?and的启发作用达到多对多的词语对齐的状态,翻译结果中的词对齐的交叉连接数越小说明系统的翻译性能更好一些。通过采用SRILM工具的方式在Gigaword新华部分获取四元英语语言模型。由于MERT的不稳定性需利用Clark等人提出的方式重复实施实验3次,把最后的平均值当作实验结果。
2.3 实验结果
1) 为了验证本文设计模型在英语翻译方面的精确度,实验检测层次短语翻译模型、加入单词分布语义信息模型以及本文模型,对不同数据集的翻译结果见表1。
本次实验评价指标为BLEU值,分析表1 可得,基于测试集NIST 06,NIST 08,本文模型获取的翻译结果比层次短语翻译模型的翻译结果分别增长了0.35,0.23。同样基于测试集NIST 06,NIST 08,本文模型获取的翻译结果比加入单词分布语义信息的层次短语翻译模型的翻译结果分别增长了0.12,0.03。说明采用本文模型获取的英语翻译结果更加准确、科学。采用显著性检验的方式获取本文模型翻译结果符合[ρ<0.05]的条件,说明其翻译结果的性能明显的进步。
语义信息的层次短语翻译模型以及本文模型进行英语翻译,获取三种模型在英语翻译方面的性能。实验结果如表2所示,本次试验给出参考译文进行对比。
分析表2可得,在具体的翻译过程中,三种模型对于“物价局”这一词语均未翻译,再分析“做出解释”这一词语,前两者模型给出的翻译结果是explained。本文模型给出的翻译结果是gives explaination of,与参考译文相一致,说明本文模型的英语翻译结果更加精准、正确率较高。
3) 实验设置提到,翻译结果中的词对齐的交叉连接数越小说明系统的翻译性能更好。实验分别采用三种模型对英语翻译结果的交叉连接数进行实验分析。
分析表3可得,采用层次短语模型翻译结果的交叉连接数是29.2,加入单词分布语义信息的层次短语翻译模型翻译结果的交叉连接数比前者减少4.7,表明其翻译结果性能有所提高;而本文模型翻译结果的交叉连接数是16,比前面两者明显大幅缩减,说明本文模型具有较高的翻译性能。
4 结 论
本文设计的基于语义网络的英语机器翻译模型具有较高的翻译性能,既能独立进行语义表达,又能在排除歧义的基础上描述词语间关系,最终给出精确的英语翻译结果。狭义上来说,为用户提供了英语翻译参考介质,广义上来说有利于促进各国文化交流、贸易往来。在未来的发展中,英语机器翻译会朝着大数据、多信息的方向发展。
参考文献
[1] 刘宇鹏,马春光,张亚楠.深度递归的层次化机器翻译模型[J].计算机学报,2017,40(4):861?871.
LIU Yupeng, MA Chunguang, ZHANG Yanan. Hierarchical machine translation model based on deep recursive neural network [J]. Chinese journal of computers, 2017, 40(4): 861?871.
[2] 李响,南江,杨雅婷,等.泛化语言模型在汉维机器翻译中的应用[J].计算机应用研究,2014,31(10):2994?2997.
LI Xiang, NAN Jiang, YANG Yating, et al. Application of generalization language model in Chinese?Uyghur machine translation [J]. Application research of computers, 2014, 31(10): 2994?2997.
[3] ZHANG J, LIU S, LI M, et al. Towards machine translation in semantic vector space [J]. ACM transactions on Asian and low?resource language information processing, 2015, 14(2): 9.
[4] MUZAFFAR S, BEHERA P, NATH G. A Pāniniān framework for analyzing case marker errors in English?Urdu machine translation [J]. Procedia computer science, 2016, 96(C): 502?510.
[5] 惠浩添,李云建,钱龙华,等.一个面向信息抽取的中英文平行语料库[J].计算机工程与科学,2015,37(12):2331?2338.
HUI Haotian, LI Yunjian, QIAN Longhua, et al. A Chinese?English parallel corpus for information extraction [J]. Computer engineering and science, 2015, 37(12): 2331?2338.
[6] 薛征山,张大鲲,王丽娜,等.改进机器翻译中的句子切分模型[J].中文信息学报,2017,31(4):50?56.
XUE Zhengshan, ZHANG Dakun, WANG Lina, et al. An improved sentence segmentation model for machine translation [J]. Journal of Chinese information processing, 2017, 31(4): 50?56.
[7] ROMOOZI M, FATHY M, BABAEI H. A content sharing and discovery framework based on semantic and geographic partitioning for vehicular networks [J]. Wireless personal communications, 2015, 85(3): 1583?1616.
[8] 王俊华,左祥麟,左万利.基于证据理论的单词语义相似度度量[J].自动化学报,2015,41(6):1173?1186.
WANG Junhua, ZUO Xianglin, ZUO Wanli. Word semantic similarity measurement based on evidence theory [J]. Acta automatica sinica, 2015, 41(6): 1173?1186.
[9] MALLAT S, MOHAMED M A B, HKIRI E, et al. Semantic and contextual knowledge representation for lexical disambiguation: case of Arabic?French query translation [J]. Journal of computing & information technology, 2014, 22(3): 191?215.
[10] BOULARES M, JEMNI M. Learning sign language machine translation based on elastic net regularization and latent semantic analysis [J]. Artificial intelligence review, 2016, 46(2): 145?166.
