基于用户重复购买记忆的推荐策略研究
2018-07-25张沁哲
张沁哲
1 引言
随着互联网不断深入人们的日常生活,已经成为生活中不可或缺甚至最重要的组成部分。但同时,信息量的井喷式增长,也给数据的处理带来前所未有的困扰,尤其在电子商务推荐方面,商品的种类不断被创新,商品的数量不断增长,用户的交易量以指数级的速度爆发式增加。当用户面对如此之多的信息量时,难以寻找到自身需求并且满意的商品,因此电子商务推荐系统便应运而生,同时高质量高精准的推荐系统更是有助于用户在海量商品中进行选择,并且缩短了用户购买商品所消耗的时间,同时提升用户对电商网站的忠诚度以及体验感,对于电商领域的商业利益最大化起到了至关重要的作用。
传统协同过滤算法主要基于项目[1]和用户[2]进行推荐,然而在对用户重复购买商品方面存在推荐弊端,经常存在错误推荐,并没有合理地依据用户近期的兴趣爱好的变化进行相关的推荐。本文则对用户已经购买过的商品进行分析,通过用户重复购买的记忆函数,预测用户对曾经购买过商品的再次购买意图进行判断,并在不同的记忆概率执行相应的推荐,以解决目前电子商务推荐系统存在的推荐不精确的问题。
2 相关工作
2.1 传统的协同过滤算法
传统的基于用户的协同过滤算法使用与目标用户有关联且行为以及交易记录具有较高相似度的用户群进行匹配,通过相似用户群购买的商品进行分析,将相似用户购买过且目标用户未曾购买过的商品对目标用户进行推荐。传统的基于项目的协同过滤算法将目标用户购买过的商品类目进行分析,分析出购买此类商品的用户仍购买其他哪些商品,并将已购买此类商品的用户群仍购买的商品对目标用户进行推荐。与基于用户和项目的推荐方式不同,基于模型的推荐算法则采用用户对商品的评分和评价进行推荐,并利用搭建的模型对用户未来可能购买的商品进行预测评分。当前基于模型的主要推荐算法有聚类模型[3]、概率模型[4]等。
传统的协同过滤推荐在执行相应的推荐时对于用户的评分信息过于依赖,对于用户重复购买商品的时间信息以及记忆留存则存在一定的忽略,因此分析并掌握用户重复购买商品的记忆留存对推荐并预测用户再次购买此类商品具有较高的价值。
2.2 基于遗忘函数的推荐算法
用户兴趣和商品类别以及商品的属性有着密不可分的关系,用户对商品的喜好随着年龄、职业、地区、时间等信息都不是固定不变的,尤其用户在日常实际消费的过程是一个动态变化的过程,因此当用户的记忆或遗忘融入推荐算法中将对推荐的精确性有很重要的影响。
郑先荣等[5]借鉴心理学遗忘规律,提出了线性逐步遗忘协同过滤算法来解决协同过滤算法没有考虑用户兴趣变化的问题,并且主要通过依据用户的评价时间点信息,通过逐步减小没想评分的权重进行推荐。邢晓春等[6]提出两种改进度量,包括采用时间的数据权重和项目相似度的数据权重,并通过融合策略,提出匹配用户兴趣变化的协同过滤推荐算法。
2.3 艾宾浩斯记忆遗忘曲线
德国心理学家艾宾浩斯(Ebbinghaus)对遗忘现象做了系统的研究,得出人对于事物的遗忘过程是非线性的,如图1所示。
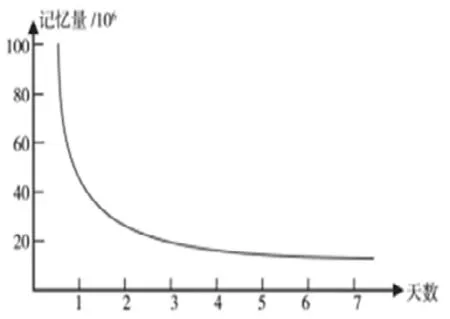
图1 艾宾浩斯遗忘曲线
艾宾浩斯遗忘曲线,叙述了人对现实事件的记忆随着时间的流逝逐渐降低的过程。可以将用户对一类事物的兴趣爱好看作记忆,并根据图像得出用户对一类事件的感兴趣程度逐渐降低。
运用艾宾浩斯曲线的过程主要是在每一个时间点上,都存在对应的兴趣的热度,记为h。有学者将艾宾浩斯曲线总结为一个持续量的函数,如式(1):

式中t为自变量,e为自然底数,t、c为常数,t0=0.00255,t0的值采用文献[7]中通过实验所得到的值。
3 融合记忆函数的协同过滤算法
3.1 用户重复购买记忆函数
用户近期内频繁购买同一类型的商品受第一次购买的行为有很大影响。而且随着时间的消磨,用户的购买记忆同样在一定程度上衰减,对用户下一次购买商品的影响也不断消减,因此对用户重复购买时我们需要将重复购买的记忆考虑到推荐中。
尤其是在电商网购中存在数据丢失的现象,例如用户第一次在网上购买零食后,用户下一次也许会去另一家电商进行购买,也可能在线下的商场进行购买,因此对用户重复购买记忆函数进行计算时我们需要考虑以上情况。
11月30日,由北京市商务局主办,北京烹饪协会承办,北京各兄弟协会、饿了么星选及有关新闻媒体协办的为期3个月的第二届中国京菜美食文化节活动落下帷幕。北京市区和郊区累计有100多个餐饮品牌、3000多家餐饮门店参加文化节。据不完全统计,有近两亿人次关注与参与,总消费收入达到61亿元,占北京市同期餐饮总收入的21%,京菜引领作用明显,中国京菜美食文化节的覆盖范围和传播力显著提升。
为此我们将预测目标用户u在时间点t对y类商品的购买记忆函数,如式(2)所示:

其中,Rm(y)是指目标用户对曾经已经购买过的y类型商品之后仍有购买可能性的记忆程度,代表着目标用户已购买后仍重复购买y类商品的概率,通过公式(3)对Rm(y)进行计算:

其中,M(y)代表用户群中第一次购买y类商品的数量,Mt(y*)代表第一次购买y类商品后仍然再次购买y*(y*是指与y同类型的商品)类商品的用户数。
Rm(u,t,y)代表用户群对y类商品在不同间隔时间段内的购买记忆函数,并且使用指数函数对记忆函数存在的遗忘以及衰弱性进行估算,因此购买记忆函数为:

其中,Y代表时间点t到来的瞬间已经执行完购买记录的集合,指数函数的概率参数值用Y表示。
因此通过式(2),我们可以得出用户购买商品的记忆函数图像,通过图像可以得到不同重复购买时间点上用户尚留存的记忆概率,同时可以通过y轴所对应的数据得到用户对y类商品的最高留存记忆时间点对应的概率。最后通过归一化来对所有的用户重复购买记忆时间点所对应的概率进行计算,如式(5)所示:

其中,Dit代表用户对y类商品不同时间点t所对应的购买记忆留存的概率,通过式(5),可以将购买记忆留存的概率值归一化为介于(0,1)之间。
3.2 融合于协同过滤算法
传统的协同过滤算法主要基于用户对于商品的评分进行推荐,本文则将用户在已购买商品后,在不同时间点重复购买商品的记忆留存概率与传统协同过滤算法进行融合,并在不同间隔时间执行相应的推荐排序集,使得推荐更加精确。
步骤一:创建用户和商品类别矩阵;
步骤二:采用Pearson[8]计算用户之间的相似性sim(a,b):
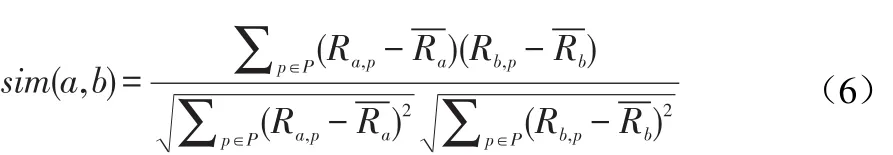
其中,R为用户a和b购买并评分的商品;-Ra、-Rb代表用户a和b的交易记录中的平均评分。
步骤三:选取前K个评分较高的用户,并根据相似度和用户购买商品评分,预测目标用户对商品c的购买评分Pc。
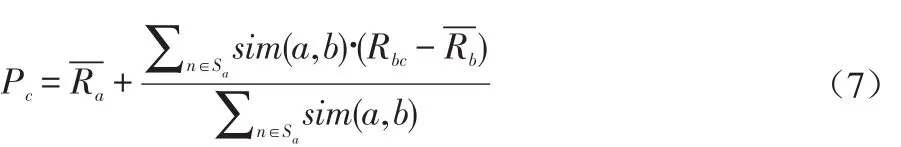
通过式(7)得出评分前10作为商品推荐集P。
步骤四:通过计算用户重复购买不同时间点所留存的记忆概率与推荐预测评分的相乘得出新的评分排序,并且得到最终的推荐集P*,如式(8):

4 实验
4.1 实验数据
本文实验数据采用2014年阿里巴巴集团举办的“天池”大数据竞赛所用的数据,数据包括六个月内851名用户对9456件商品的购买以及评分记录。本文使用用户购买商品属性、购买时间和对商品的评分进行实验并分析。前四个月的数据作为训练集,后两个月的数据作为测试集进行预测并对照传统的协同过滤推荐算法。
4.2 生成推荐集P*
如表1,通过将用户重复购买记忆函数与传统的基于协同过滤推荐算法进行融合,生成最终的推荐集P*。
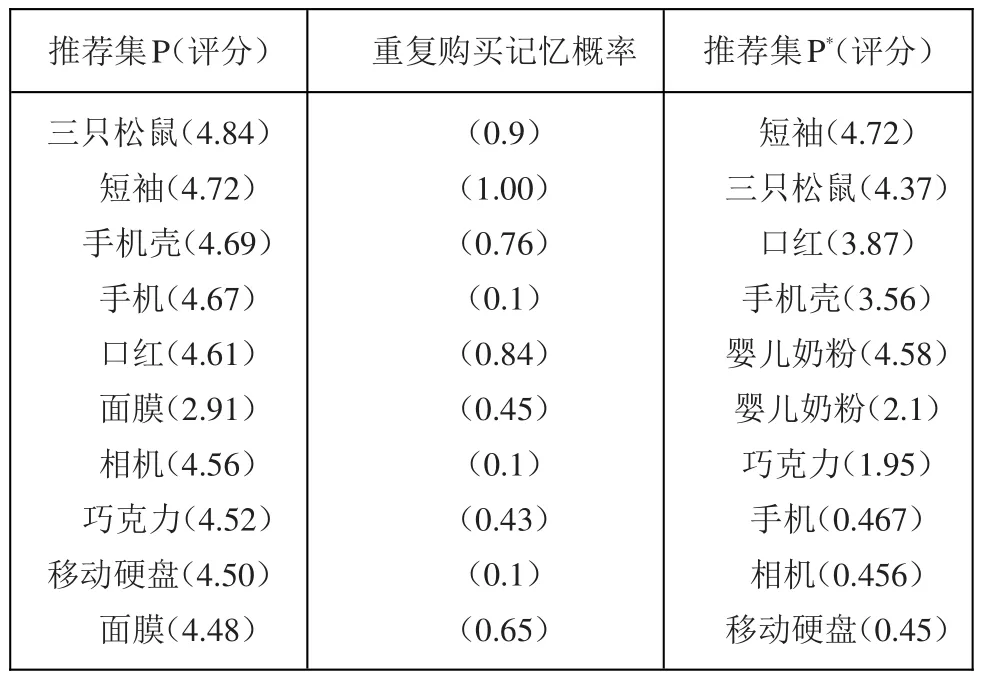
表1 推荐集P与P*
4.3 商品推荐准确性的评价标准
本文提出基于用户记忆函数的协同过滤推荐算法,采用推荐准确率(Precision)作为该算法的评价标准。它是一个最基础的衡量推荐系统精确度的评价方式,表示在推荐的所有商品中,用户点击并访问或者用户成功购买所占的比例,比例越大则证明推荐精确度越高。

其中Hits代表推荐集中被用户所产生购买的数量,N则表示推荐的总数量。
4.4 实验结果
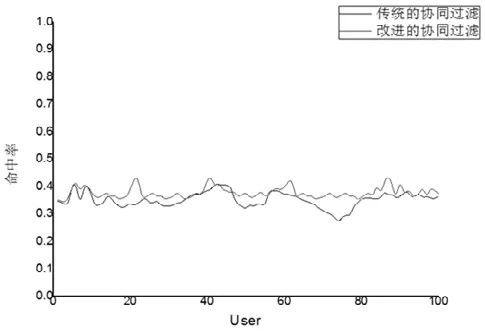
图2 改进协同过滤与传统协同过滤推荐算法比较
通过图2我们可以看出,与传统协同过滤推荐算法相比,融合了重复购买记忆函数的协同过滤算法在推荐精确度方面有明显的提高,同时能够给用户更适合的推荐体验。
5 结论
与传统的协同过滤算法相比,考虑了用户购买记忆的协同过滤推荐算法,在推荐时更能够了解用户的实时兴趣爱好的动态变化,针对个性化推荐更有效,避免了一些错误的推荐,不仅为电子商务系统节省了推荐资源,同时减少了对用户不必要的困扰,在一定程度上提升了推荐的精确度。
