基于LDA主题模型的格调挖掘
2018-07-25李江宇宋添树张沁哲
李江宇 宋添树 张沁哲
1 引言
近年来,微博、微信朋友圈等社交平台快速崛起,由于使用方便、操作简单等优点被广大用户所使用。用户不仅可以在社交平台上发表自己的看法,还可以通过点赞、评论以及转发的方式参与别人讨论的话题。过去关于社交平台的研究多为人格以及情感研究,本文首次提出发布者格调的概念,旨在通过微博用户的庞大数据量分析刻画出发布者的格调极性分布。格调是指发布者的风格、品味,往往由其文艺作品中导出,而发布者的微博文本就是他们的文艺作品。挖掘得到发布者的格调极性对微博的定向推荐有重要的意义。
2 相关工作
本文采用的主要研究方法是引入LDA主题模型,通过主题分布来反映发布者的格调极性。徐戈等人[1]对主题模型的发展以及各阶段主题模型的推导进行了详细的阐述,并对改进的主题模型进行了展望。欧阳继红等人[2]提出了一种多粒度情感混合模型,该研究对LDA主题模型进行了改进,考虑两个粒度上,即整体以及局部的情感分布来刻画发布者的情感。王永贵等人[3]提出了基于用户层的四层贝叶斯主题模型,解决了LDA挖掘短文本效果不佳的问题。Daniel Preotiuc等人[4]则从性别、年龄、职业三个方面使用社交文本释义的方式刻画不同发布者的风格。
3 格调刻画模型
3.1 传统的LDA主题模型
2003年Blei等人[5]提出了LDA(Latent Dirichlet Allocation)主题模型,LDA主题模型主要是通过无监督学习的方式来抽取文档集的潜在语义信息,这个语义信息就表现为文档集的主题,把文档集的高维度表示方式降到主题的低维度表示方式。LDA主题模型一般认为“每篇文档都是按照一定的概率选择了某个主题,而每个主题又是按照一定的概率选择了某个词项”,其中“文档-主题”分布及“主题-词项”分布都是服从一定参数的多项式分布。如果要生成一篇文档,每个词出现的概率如式1所示:

图1表示为LDA主题模型的三层贝叶斯表示图,其中wm,n为可观测值,在语料库中,我们唯一可以观测到的变量就是词项,而其他的元素均为无法观测的隐含变量。K表示训练语料库后生成主题的数量,M表示生成文档的数量,Nm表示第m篇文档涵盖词项的数量。
3.2 SLDA主题模型
传统的LDA主题模型多被应用于长文本主题挖掘,长文本包含较多的文字信息,表达语义更加明确,已有的多项研究已经证明传统的LDA主题模型对长文本主题挖掘效果比较显著。而社交平台的文本均属于短文本,发布者发布的短文本被限制在140个字符以内,通过传统的LDA主题模型对发布者的短文本进行主题挖掘效果并不理想。
本文借鉴AT(Author Topic)模型[3],对传统LDA主题模型进行了改进,在“文档-主题-词”的三层贝叶斯模型的基础上,引入了发布者层,通过加入发布者的格调参数来挖掘出发布者的格调主题分布,最终得到刻画发布者格调极性的SLDA主题模型。
相比于传统的LDA主题模型,SLDA模型的可观测值为词项wm,n以及发布者am,n,而其他的元素均为无法观测的隐含变量。对于一个完整的发布者社交文本文档,某个词wm,n按照一定的概率选择发布者am,n,然后根据选择的发布者am,n的格调极性π是高的(π=s1)还是低的(π=s2)又以一定的概率选择其对应格调的主题zm,n,主题zm,n在词分布上服从Multinomial的多项式分布,并按一定概率产生一个词。反复上述的迭代过程,最终生成一篇完整的文档。
SLDA主题模型的四层贝叶斯网络图如图2所示:
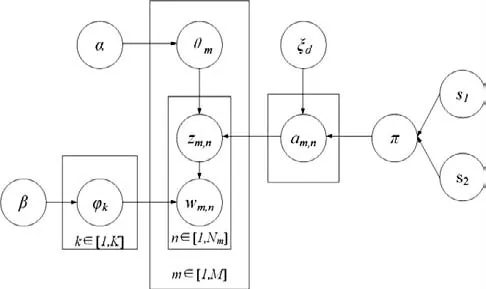
图2 SLDA主题模型的四层贝叶斯网络图
主题模型参数含义如表1所示:

表1 参数及含义说明

参数wm,n am,n α β ξd π含义第m篇文档的第n个词第m篇文档的第n个词对应的发布者关于文档-主题多项式分布的参数θm的Dirichlet分布参数关于主题-词多项式分布的参数φk的Dirichlet分布参数发布者am,n服从参数为ξd的均匀分布发布者的格调极性,s1为格调极性高,s2为格调极性低
4 吉布斯抽样
本文采用吉布斯采样的方法对SLDA模型进行推导。根据式2,通过吉布斯采样对每位发布者博文的每个词项进行采样,反复迭代使结果趋于稳定。

其中zi=k,am,n=π表示在一篇文档中的第i个词项分配到的主题为k以及发布者am,n的格调极性为π。z-i表示除了第i个词项的主题分布。Nw,k,π表示词项w在主题k和格调极性π中出现的次数,Nk,π,d表示文档d中主题k和格调极性π中出现的次数,Nk,d表示文档d中k中出现的次数,Nk,π表示主题k和格调极性π出现的次数,Nd表示文档d中词项总数。
SLDA模型参数估计的吉布斯采样迭代方式为:
(1) 设定发布者am,n博文文档的格调极性为π;
(2) 更新格调分布的先验ζd;
(3) 更新词项的主题分布z和情感极性π。
经过吉布斯采样后,SLDA主题模型对φk、θm和π估计如式3、式4和式5所示:

根据上述吉布斯采样公式可以得到发布者文档d的词项分布φk、主题分布θm以及情感极性π,通过概率计算,对发布者的整个博文文档进行分析,就可以挖掘出每位发布者的格调极性是高的(π=s1)还是低的(π=s2)。
5 实验分析
5.1 实验准备
本文以新浪微博作为数据来源,利用网络爬虫爬取100位截止2017年7月的微博数据。由于采样数据中常常包含不完整以及冗余的数据,因此在获取数据之后必须对数据进行预处理,提高数据的质量,从而更好地完成挖掘任务。
5.2 困惑度分析
困惑度(Perplexity)[6]作为一种概率图模型的性能评价指标,因其计算简单、易于实现等优点被广泛应用于不同概率图模型的比较分析中。在不同模型中输入相同参数的情况下,困惑度越低表明模型的性能越高,主题模型困惑度的计算公式如式6所示:

其中,W表示关于发布者完整的文档集,Nm表示第m篇文档词项的数量,p(wm)表示产生第m篇文档的概率。p(wm)的计算公式如式7所示:
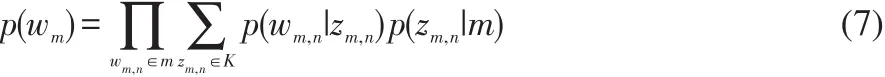
在LDA主题模型及SLDA主题模型输入不同的迭代次数训练文档集,得到的困惑度对比如图3所示:

图3 LDA主题模型与SLDA主题模型困惑度对比
由图3可以看出,在设定固定参数α=50/K,β=0.01以及输入确定主题数K=10的情况下,随着迭代次数的增加,LDA主题模型以及SLDA主题模型的困惑度均在逐渐减小。当迭代次数小于200时,两种主题模型的困惑减小幅度较大,当迭代次数达到200后,困惑度减小的幅度平缓,困惑度曲线开始收敛,趋于一个较稳定的范围。SLDA主题模型在不同的迭代次数情况下,困惑度均小于LDA主题模型,可以发现SLDA主题模型对微博文本的主题提取效果更佳,性能也更高。
5.3 主题提取效果分析
在上一节的困惑度分析中,当迭代次数达到200时,模型困惑度趋于平稳,所以在本实验中设定迭代次数为200。选取10位发布者,把10位发布者的博文文档输入到改进前后的LDA主题模型中,提取10位发布者的主题,得到分主题词分布情况如表2及表3所示:

表2 LDA主题模型挖掘发布者博文主题结果

表3 改进LDA主题模型挖掘发布者博文主题结果
表2和表3分别反映了改进前后的LDA主题模型对发布者的主题提取情况,可以发现经过不同主题模型的训练后,每位发布者的主题分布存在差异。在表3中ID为“母其弥雅”的用户主题词为“演员”、“健康”、“养生”、“瑜伽”、“健身”等,从这些词中很容易可以发现发布者的主要兴趣爱好为健身或者演艺类。而在表2中的主题词出现了“没有”、“共享”、“国家”等无法读出兴趣爱好的主题词,对发布者的兴趣爱好分析造成了一定的影响。对其他的发布者主题词提取结果同“母其弥雅”类似,LDA主题模型提取得到的主题词存在较多的无关主题词,影响了主题的可读性,对挖掘发布者的兴趣爱好加大了难度。相反SLDA主题模型的挖掘效果要优于LDA主题模型,减小了主题的区分难度。
5.4 格调提取分析
本实验主要对发布者的格调主题词进行了分类提取,通过LDA主题模型和SLDA主题模型抽取出格调相关词项,总体来看,SLDA主题模型提取的格调词项更加丰富。提取结果如表4所示:

表4 LDA主题模型与SLDA主题模型格调抽样结果
从表4可以看出,LDA主题模型和SLDA主题模型提取的格调词项存在一定的差异,而SLDA主题模型提取到的主题词更能表达出发布者的主题。另一方面,两种不同的主题模型都可以提取到格调极性不同的主题词。
6 结束语
通过微博用户的行为状态等数据对发布者的格调进行分析和预测,对于推荐系统及个性化广告等方面都有着巨大的价值。本文通过困惑度分析、主题提取效果以及对用户的格调词汇提取实验证明了SLDA主题模型合理有效。
