基于概率的语言研究发展简述
2018-07-25陈衡
陈 衡
关于语言特性,有这样一组对立的观点:一种观点是把语言看作是判定性的规则,另一种观点是把语言看作有意义的趋势[1-3]。前者认为语言特性可以用逻辑或规则加以描述,后者认为语言特性是一种概率性或盖然性[4-6]。
认为语言特性是判定性的规则的以乔姆斯基为主要代表。乔姆斯基把索绪尔对语言与言语的区分重新解释为语言能力和语言行为,认为语言学家应该研究的是语言能力而非语言行为,而且其对语言能力研究的判定标准就是看是否符合这一语言母语者的语感,而非真实的语言文本。
与语言是判定性相对的观点是认为语言是概率性的。德·波格兰德(De Beaugrande)统计出乔姆斯基在《句法结构》和《句法理论要略》两书中分别分析了28个和24个人造句子,这种只靠研究者内省的方式是不能够令人信服的[7]。对语言是判定性的提出批评最多的是功能语言学家,尤其是系统功能语言学家,如Halliday认为乔姆斯基的举例不是来自真实语篇,因此它无法如实概括语言的实质[1]。
对于语言学中的这两种观点,到目前为止仍各有人坚持,仍是讨论的热点之一[8]。
一、概率语言学的产生及背景
2001年美国语言学会在华盛顿召开,并举行了第一次“语言学中的概率理论”专题讨论会,讨论结果一是认为概率理论的应用让语言学家们在探究语言理论以及具体问题时有了可以测量语言特性梯度 (gradience)的方法;二是Rens Bob,Jennifer Hays,Stefanie Jannedy等人主编的《概率语言学》出版。这本书介绍了概率理论的基本知识,以及其在语言学各个分支中的应用研究。在前言中,编者这样说道:“众多的证据表明语言是概率性的。在语言理解及生成过程中,概率在读取(access)、歧义消解以及语言生成方面起着重要作用。在学习方面,概率在切分和总结方面发挥作用。在音系和形态方面,概率在可接受度判断和交替(alternation)方面发挥作用。在句法和语义方面,概率在范畴梯度、句法合法性判断以及翻译方面发挥作用。而更重要的是,概率在模拟语言演变和变异方面发挥关键作用。”[7]vii
其实,早在这次会议之前,就有运用概率研究语言的传统。在英国,马琳诺夫斯基最早对数量统计和概率做过间接陈述,将语言看作是说话人脑子中的思想转移到听话人的脑子中的方法是错误的,我们需要因经验和情境而论[9]。即在不同的情境下每个句子出现的概率是不一样的,这个思想就是语境论的思想。弗斯非常强调意义的语境理论,他认为真实的语言在作为语篇的语言中出现,因此记录下来的真实语篇才是语言学家要关注的主要内容[10]。Halliday和Sinclair继承了弗斯的思想。
在欧洲,自1930年以来,布拉格学派的语言学家们就一直从事某些语法过程中频率作用的定量研究,如音节类型和结构的概率分布,句子中信息位置的概率分布,言语不同部分出现的相对频率等[11]。
而在美国,语文学家Zipf也非常关心语言的定量研究。他研究了词频与语篇长度的关系,文本中词频与秩次的关系等。Zipf发现,如果把一个文本中的词语(该次运用的英文文本)进行频次统计,并把频次按从大到小的次序排列,即排在第一的秩次为1,频次为f1,排在第二的秩次为2,频次为f2,以此类推,那么秩次r与其对应的频次f满足下列关系[12]:
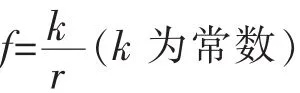
这个定律表明,在英语中,只有少数高频单词被使用,大部分单词很少被使用。Zipf将其解释为“最小努力原则”,即为语言学中最常用、最具解释性的“经济性原则”:人们总是习惯用少量的词语来表达较多的内容。Halliday曾评论说这个词语频率作为语言的一个特性是可以接受的,如英语的“gd”比“walk”出现频率高,比“stroll”更高,因此,没有必要将语法的定量范式拒之门外[13]。
Zipf定律是一种简单的幂函数,它描述的这种词语分布又被称为幂率分布,其实,不止词语,其他很多自然、社会现象都符合幂率分布定律,像人均收入的分布、姓氏的分布、网页点击次数分布等都是一种幂率分布,因此Zipf定律也被借鉴到其他类型的统计中去,它是一个具有社会学意义的普适规律。这是运用概率研究语言对其他学科的一大贡献。
二、概率语言学的分支研究
(一)概率音系学
音系学研究人类语言传达意义的语音结构知识。人们在利用语音造词时会经常利用已有的语音元素和结构,因此它具有很强的能产性。语音结构的能产性是生成音系学的基础,而这种带有变量形式语法的概念常常被认为与音系学是概率的这一观点相对。实际上,这是一种偏见,因为概率理论就是要把概率赋给这些变量;如果没有变量,也就不会有统计学习模型了。一旦我们从语音结构中抽象出了一些变量,原则上,我们就可以根据我们的研究需求而给某个变量赋上概率值,以获取科学的结果。
概率音系学理论既包括抽象的变量部分,也包括概率分布部分。在概率分布部分,它是分层次的,包括:(1)参数语音学;(2)语音编码;(3)词典中的词型;(4)音系语法;(5)形态音位对应。概率音系学要研究的就是什么样的分布对应什么样的变量,以及各个层次分布之间的关系等。这样的研究对于我们理解人类语言的本质有重要意义,而这是非概率类研究所不能达到的。
(二)概率句法学
研究概率句法学的学者主要集中在计算语言学或统计语言学方面,如Daniel Jurafsky、Christopher D.Manning、Michael Collins等。概率句法包括n元模型、概率上下文无关语法(PCFG),词汇化的概率上下文无关语法(LPCFG)、概率依存语法(PDG)。
n元模型是一种统计语言模型,严格说它不是语言学本体中的句法理论,它主要利用的是词的共现频数信息,因此更多的是基于信息论的理论。n元模型最初用来识别语音,取得了较好的效果。n元模型的提出者贾里尼克,是一位自然语言处理的大师,他曾听过信息论鼻祖香农,以及语言学大师雅各布森和乔姆斯基的课,博士毕业后任教于康奈尔大学,后到IBM,领导华生实验室,在自然语言处理尤其是语音识别方面做出重要贡献。
PCFG是在乔姆斯基概率上下文无关语法的基础上在每个生成过程中增加概率因素,用以判断不同句法树的合法性程度,但它有其局限性:一是概率估计基于纯粹的结构因素,没有考虑词汇的共现因素,即没有考虑局部词汇上下文;二是相对较长的句子,较短的句子的概率值要偏大。因此,在实际的语言描述能力上,它比n元语言模型的描述能力要更差些。
LPCFG是在PCFG的基础上发展完善而来,针对PDFG的两个问题提出解决办法。针对问题一,在派生过程中加入中心词这一特征;针对问题二,规范派生。基于LPCFG的句法分析的正确率能达到91.4%,远远超过 PDFG[14]。
PDG是建立在依存语法的基础之上的,各种类型的依存语法与对应的短语结构语法实质是同构的。Macdonald等认为,基于PDG的句法分析的正确率与基于LPCFG差不多,但在效率上要远远超过后者[15]。
(三)概率社会语言学
社会语言学探究的是人类各个层次上的语言学现象与社会的关联模式,包括语音、句法、语义及话语等。但社会语言学有其不同于其他分支的特点。其他语言计量研究的分支是与基于直觉和范畴思考的流派相竞争,而社会语言学从产生开始就是基于经验前提的。过去社会语言学研究的内容包括寻找统一的统计模型和工具,连接社会结构与语言形式的相关系数的解读等。而随着社会学理论的发展以及对社会语言学理解的加深,研究者们面临着社会语言学观点的极大改变:从静态社会范畴分析转变为先于数据分析的简单决策分析。而范式理论这一基于频率的模型在语言学的各个分支中的出现,融合了社会理论对社团实践中的参与人所起作用的理解。在范式理论中,范畴并不是预先存在的,而是动态的,是通过对大量数据的概括总结而来。这样,社会语言学又与概率重新结合。概率社会语言学研究的中心问题包括:是什么因素影响说话者选择使用这一个而不是另一个语言变体的决定?怎样最好地对这一决定发生时的语言与社会同步影响过程进行建模?某一语言变体是怎样反映社会成员关系的?某些语言形式在社会景观中的交替出现反映了语言结构内部什么样的共时与历时工作机制?
(四)概率心理语言学
20世纪50年代有许多基于统计和概率的心理语言学的研究,但这种研究在60到80年代停滞了,直到90年代才开始复苏。尽管概率理论不是很好的描述模型,但却是很好的规范模型(normative model)。概率理论起源于人们在面对不确定性时进行推理的认知建模。
概率在语言理解的过程中有三个已被证明的作用。第一,从心理词汇或语法中获取语言结构任务。一般地,概率大的语言结构获取的速度更快,所需时间更短。第二,歧义消解。歧义在语言理解的过程中无处不在:分词、词性标注、词义标注、句法语义理解等。概率在此发挥的作用是,一个释义的概率越大,那么它被选择的概率也就越大。第三,概率还可能在解释语言处理的复杂性上发挥作用。在语言处理模型中,那些复杂性比较高的往往是由于一些低概率释义情形的存在,或者是释义的突然转换。概率的计算往往必须依赖于语言单位在实际使用中的出现频率。
三、概率语言学的拓展
从概率出发研究语言是正确的,但从目前的研究成果来看,如果去掉自然语言工程方向的一些成果[8],其在语言学本体研究中并没有引发重大的改革或发现。正如Munro在评论Probabilistic Linguistics一书时所作的批评:这本书主要关注的是概率,而非语言的层级性[1];Jurafsky在书中所声称的在2000年的计算语言学大会上77%的文章都在一定形式上使用了概率模型,其实际情况是没有一篇探究语言的层级性或渐变性作为主要目标,他们非常乐意将概率知识加进他们的模型中,却使用基于范畴(理性主义方法)准确性的方法去评测结果。这就完全颠倒了将概率理论引入语言学中的目的,因此Munro发出了这是否会阻碍概率语言学发展的强烈疑问。
从概率出发研究语言的还有从功能语言学中分化出的语料库语言学,以及继承了Zipf定量研究方法并发展起来的计量语言学。
Michael Halliday和John Sinclair都是Firth的直接学术继承人,前者开创了系统功能语言学,后者开创了语料库语言学,并都保留了Firth的语言学思想精髓。从对概率的直接运用程度上,语料库语言学要更贴近概率语言学,而系统功能语言学在语境论和社会论的方向上走得太远,逐渐剥离了语言事实。语料库语言学在概率的运用上也不是没有问题,基于语料库的研究所遇到的问题与前面Munro所批评的基本类似,即其研究似乎只是对基于范畴方法的一种验证,尽管也有所拓展,但本质还是如此。不过随着语料库语言学的发展,以及新的统计手段的不断创造与运用,语料库驱动的方法逐渐推广开来,这将对从根本上改变语料库语言学只是对理性方法的一种验证这一偏见发挥重要作用。
计量语言学继承了Zipf的语言定量研究方法,而且更加注重在概率的基础上构建语言学的理论[16-18]。关于计量语言学的产生,一个有趣的现象是,美国语言学家Zifp所运用并倡导的语言定量研究方法没有在美国散开,却在欧洲开花结果。“目前这一领域的主要代表人物大多来自德国、奥地利及东欧国家,其中最著名的是德国波鸿大学的Altmann教授。他在计量语言学的诸多领域均有重要贡献,是Zipf之后最重要的计量语言学家,被誉为现代计量语言学的奠基人之一。”[19]计量语言学有自己的国际学会,以及会刊《计量语言学学刊》,其主编特里尔大学的科勒教授是一位计量语言学的重量级人物。
计量语言学相较于语料库语言学以及统计语言学来说,更加注重语言学理论的建设,这就是为Munro所诟病的后两者所缺乏的东西。经过几十年的努力,各国计量语言学学者已经发现了不少的具有普适性的计量语言学定律,主要有:以Zipf定律为代表的分布定律、以Menzerath-Alttman定律为代表的函数定律和和以Piotrowski-Alttman定律为代表的演化定律。除了这些单个的定律外,协同语言学理论作为一个完整理论发展起来,并从词汇层向句法层拓展。另外,值得一提的是,目前,中国的计量语言学蓬勃发展,取得了一些成果[20],计量语言学会会长Köhler教授甚至说,国际计量语言学的研究中心正在从欧洲转移至中国。
四、结语
概率性是语言的一个主要特性,运用概率来研究语言是符合客观规律的,也是符合语言事实的。当然,概率语言学在发展过程中也遇到一些问题,解决问题的办法一是真正地用概率的思想来研究语言,而不是基于范畴方法的一种验证,要在概率研究的基础上发现规律,加强理论构建,形成系统。二是把握当前多学科交叉研究的潮流[21],积极吸收其他相关学科如数学、计算机科学、认知科学、心理学、物理学等值得借鉴的地方,以促进自身快速发展。其中尤其值得一提的是,当前大数据研究成为潮流[22],而语言研究所需的语料在互联网上取之不尽、用之不竭,这是概率语言学发展的一大机遇。
