融合用户背景和用户人格的话题推荐方法
2018-07-25范洪博杨笑锋
范洪博 杨笑锋 张 晶
(昆明理工大学信息工程与自动化学院 云南 昆明 650500)
0 引 言
基于用户喜好程度的高质量话题推荐是目前互联网产品的核心竞争力。传统话题推荐模型主要包括基于聚类的模型[1]、基于关联的模型[2]、基于协同过滤的模型[3]等,这些推荐模型将各话题对应文本根据关键词相似率等指标进行关联,一旦用户关注了某一话题,则根据文本关联度由高到低对用户推荐与该话题相关的其他话题。
但这些推荐方法存在下述缺点:1) 难以深入挖掘用户潜在需求;2) 推荐文本间信息重叠严重,话题单一,降低受众阅读信息量;3) 难以推荐新话题。这严重影响了用户的阅读体验,急需从新的视角研究用户话题推荐方法。
在网络用户中,物以类聚人以群分的现象非常严重。通常,具有相同或相近的人格属性特点的用户,思维方式比较接近,所关注的话题具有较强的相关性。由弗洛伊德的人格动力理论和奥尔波特的人格特质理论总结得出:人格是决定用户对特定话题是否无意识的喜好/厌恶,并形成阅读行为的重要因素。
而专业知识、从事职业、语言上下文环境,对特定话题的喜好/厌恶有较大的影响。用户背景相近的用户,因他们之间具备接近的专业知识等,对同一话题更容易产生接近的喜好/厌恶,即用户背景相似度也可能成为一种重要的话题推荐参考指标。
基于上述分析,本文提出一种融合用户背景和用户人格的话题推荐方法(CBG-CF)。计算用户之间人格特质和用户背景信息的相似度,通过协调过滤算法对于目标用户进行文本推荐。实验表明,相对用户间背景相似的文本推荐算法(BG-CF)和人格特质相似的文本推荐算法(CS-CF),本文提出的算法在用户文本推荐上有较好效果,推荐的质量得到一定的提升。实验表明,相对用户间背景相似的文本推荐算法(BG-CF)和人格特质相似的文本推荐算法(CS-CF),本文提出的算法在用户文本推荐上有较好效果,推荐的质量得到较大的提升。如当文本推荐的数等于9时,在MAE指标上,CBG-CF相对BG-CF约提升19.74%,相对CS-CF约提升8.92%。
1 用户人格分析
人的行为是其人格特质的有效表现,建立人格特质识别模型对于用户人格特质分析尤为必要。
近年,对于人格特质研究呈现较热趋势。Caci等[7]根据网络用户人格特质预测对于Facebook的接收程度。Mairesse等[10]利用SVM算法预测用户的人格特质,准确率达到60%。张磊等[9]综述人格特质预测面临挑战,提出相对的解决方法。Selfhout等[6]根据用户的人格与商品的购买关系进行商品的推荐。Rentfrow等[5]根据不同人格的用户对不同音乐的偏好,进行个性化音乐的推荐。上述基于人格的预测模型均获得了良好的预测效果。
1.1 情感统计特征
人格特质决定用户对事件的态度,不同人格特质用户在文本中体现出的情感词汇、表情、图片各不相同,如外倾特质用户对待事件往往表现较为乐观、积极向上。可见,情感特征是预测用户人格特质重要因素。
在本文中,我们通过文本、图片、表情等因素,综合考量用户情感,设用户i发布文本中正面情感词比例P(i),负面情感词比例N(i),则:
(1)
(2)
式中:Totali表示用户i发布文本中情感词汇总个数,npi表示文本中正面情感词出现个数,nni表示文本中负面情感词出现个数。pp(i)表示图片正面情感,pn(i)表示图片负面情感,其中0≤pp(i)≤1,0≤pn(i)≤1。TEi表示用户发布文本中出现表情总个数,epi表示出现正面情感表情个数,eni表示出现正面情感表情个数。
1.2 特征权重计算
不同的特征对于用户人格特质的预测有不同的影响,特征权值分配合理对人格特质准确预测起决定作用。由皮尔森相关系数存在特征数据需满足正态分布的问题,本文采用肯德尔检验计算五大人格特质与特征之间相关性,得到各个特征权值。其中,随机变量M和N的肯德尔相关系数计算为:
(3)
式中:A表示随机变量M和N中一致元素的对数,B表示随机变量M和N中非一致元素的对数。X1表示M之中重复元素的对数,其计算为:
(4)
式中:s表示重复元素对数,U表示第i个元素拥有的相同元素个数。X2表示N之中重复的元素对数,计算同式(4)。X3表示合并的总个数,计算如下式:
(5)
式中:X表示随机变量的维数。随机变量M和N的肯德尔相关系数φ(M,N)∈[-1,1],其中φ(M,N)=0表示随机变量M和N相互独立,反之φ(M,N)值越大表明相关性越强。因此,拟通过计算属性与用户人格特质之间的肯德尔相关系数来量化特征的重要性。则第i个特征gi的重要性量化计算为:
(6)
式中:φ(gi,pj)表示gi与第j维用户人格特质pj之间的肯德尔相关系数。p表示五大人格特质的集合。根据gi重要性计算对应权重W(gi)的值:
(7)
式中:G表示用户人格特质预测的属性集合。
2 融合用户背景和用户人格推荐算法
2.1 用户背景信息相似度计算
用户背景信息对分析用户性格和挖掘用户兴趣提供很大帮助。其中,蒋胜等[10]结合用户背景信息和用户行为解决推荐系统冷处理问题。吴一帆等[11]根据用户背景相似解决推荐系统数据缺失问题,提升推荐系统的精准度。仲兆满等[13]将文本语义与用户背景相结合用于微博信息的推荐。仅依赖用户文本信息来分析用户人格特质,准确率不高,因而影响推荐系统的精准度。本文提出融入用户背景信息与用户文本分析用户人格特质,提高用户人格特质预测准确度。
用户背景信息由不同的特征属性描述,包含连续特征属性和二元特征属性。连续特征属性包括年龄,二元特征属性如性别、教育背景等。通过对属性特征加权计算用户之间背景相似,用户i与用户j背景相似度计算如下:
(8)
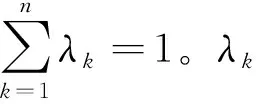
1) 若ak为数值型属性,则:
(9)
2) 若ak为二元型属性,则:
(10)
3) 若ak为分组型属性,则:
(11)
式中:s为同一属性之间的最大差值,Δx为aik和ajk之间分组差。
2.2 融入用户背景和人格特质相似度计算
基于用户人格特质计算用户之间相似存度在一定偏差,本文融入用户背景信息,结合用户人格特质计算用户间相似度。用户i与用户j相似度计算如下:
tsim(i,j)=α×sim(i,j)+β×gsim(i,j)+γ
(12)
式中:tsim(i,j)为用户i与用户j的相似度,sim(i,j)为用户i与用户j的背景信息相似度,gsim(i,j)为用户i与用户j的人格特质相似度。α、β、γ分别为用户背景信息相似度加权值、用户人格特质相似度加权值、修正参数。由式(7)可得特征属性与人格特质之间的关联,根据用户发布文本信息对该用户人格特质量化。用户i与用户j的人格特质相似度计算如下:
(13)
式中:mit表示用户i的五大人格特质量化值,mjt表示用户j的五大人格特质量化值。推荐算法如下:
输入:用户—背景信息矩阵Um×n、用户—文本信息矩阵Rm×l和目标用户矩阵Ue×n。
输出:Top-N推荐结果。
1) FOR用户—背景信息矩阵Um×n每一列DO。
2) 根据式(8)计算用户i与目标用户矩阵Ue×n的背景信息相似度,结果保存在用户—背景信息相似矩阵SUm×e。
3) END FOR。
4) FOR用户—文本信息矩阵Rm×l每一列DO。
5) 对于文本信息进行处理,使用式(7)对用户五大人格特质量化计算。计算结果存入用户—人格特质矩阵Cm×5中。
6) 对目标用户矩阵Ue×n五大人格特质量化计算,计算结果存入目标用户—人格特质矩阵Ce×5。
7) END FOR。
8) FOR矩阵SUm×e、矩阵Cm×5和矩阵Ce×5DO。
9) 根据式(12)计算用户间相识度,结果存入用户—目标用户相似度矩阵Rm×e中。
10) END FOR。
11) 对于矩阵Rm×e中的值进排序。
12) WHILEtsim(i,j)>ε,其中tsim(i,j)表示用户i与目标用户j的相似度(i∈Um×n,j∈Ue×n),ε表示相似度阈值。
13) 对目标用户j进行Top-N推荐。
14) END。
2.3 时间复杂度分析
根据上述的描述算法,设m是用户、e是目标用户、用户背景特征维度b,关于用户集合与目标用户背景相似度的计算,时间复杂O(m×e×b)。而算法的步骤1-步骤3在离线的情形下可以完成计算,固该部分时间复杂度不影响算法的整体运算性能。步骤4-步骤7主要计算五大人格特质与文本的关系,设n为数据的集合,d为特征数量,即该部分的时间复杂度O(n×n×d)。步骤8-步骤10主要用户与目标用户之间的相似度,时间复杂度O(m×e)。步骤11-步骤14主要对于相似度数据进行排序,我们采用堆排序的方式,时间复杂度O(m)。本文算法与CS-CF算法相比,时间复杂度相同,不会影响推荐系统的性能,但推荐的质量有所提升。
3 实验分析与结果
本文基于新浪微博(http://weibo.com)的数据对上述算法的推荐质量进行验证,并与BG-CF算法和SC-CF算法进行比较。新浪微博是国内社交通信的主流平台,每日在线人数达到2.2亿。本文通过爬虫技术抓取16 059位用户和3 248 907条微博信息,主要包括用户的注册信息、用户发布文本信息、用户点赞信息。
用户的背景信息主要包括年龄、性别、教育等特征属性,本文根据用户注册的特征属性通过式(8)计算用户间背景相似度。用户发布的文本信息主要包括表情、文字内容等,本文通过式(7)计算五大人格特质与用户发布文本的关联,进一步量化用户人格特质。数据集分成5份,其中任意4份做测试数据集,剩余1份做训练数据,通过交叉验证法检验该算法精准度。本文采用平均绝对偏差[13](MAE)评价推荐结果的精准度,MAE的值越小表示推荐的精准度越高,算法的效果越好。
(14)
式中:sum表示测试的集合,Pi表示对于目标用户i推荐微博文本的情感,Ui表示目标用户i点赞微博文本的情感。当推荐的微博文本情感与目标用户点赞文本情感误差较小时,可以认为该推荐有效。
本实验通过分析α和β的值,其中α+β=1,设定γ=0.015。通过MAE的变化选取最优α和β的值。实验如图1所示。
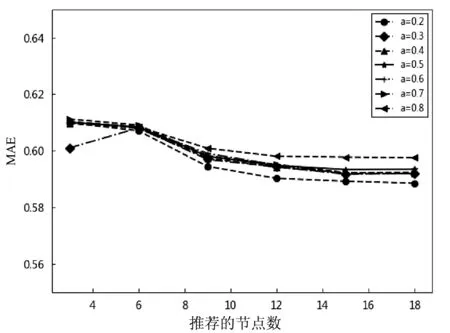
图1 不同权值的推荐
根据图1可知,随α的值递增,MAE也呈现增加趋势,当α=0.2时文本推荐的质量相对较好。推荐文本数量的增多,推荐文本精度得到提升。推荐文本数目小于10时,文本推荐的精度随推荐文本数目成正比;当推荐文本数目大于10时,推荐的精度趋于平稳,该现象符合用户阅读现象。
通过实验,我们得到基于用户间背景相似的文本推荐算法(BG-CF)、基于人格特质相似的文本推荐算法(CS-CF)和本文提出的算法在文本推荐的MAE值,如图2所示。
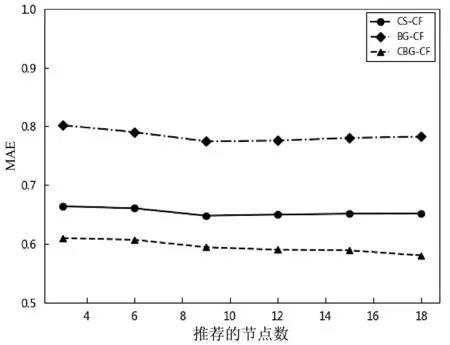
图2 不同算法的推荐
根据图2,我们可以得到本文提出的算法相对另外两种算法MAE值较低,推荐精度相对较高。随着文本推荐数目的增多,MAE值趋于降低。当文本推荐数目大于10时,MAE值趋于平稳。当文本推荐的数等于9时,新算法相对基于用户间背景相似的文本推荐算法(BG-CF)约提升19.74%,相对人格特质相似的文本推荐算法(CS-CF)算法约提升8.92%,可见本文算法对提升文本推荐精准度有效可行。
4 结 语
结合用户背景信息的文本推荐精准度较低,文本情感分析推荐无法准确挖掘出用户潜在兴趣的问题,本文提出融合用户背景信息和用户人格特质的文本推荐方法。该方法根据用户发布文本量化用户人格特质,结合用户背景信息深度挖掘用户隐藏的爱好,针对不同的人格特质结合用户背景信息进行文本推荐。与仅有人格特质的用户文本推荐相比,本算法在推荐精准度上有一定提升。在本算法的基础上,如何将多维特征如用户地理位置、文本视频信息等融入用户文本推荐中,进一步提高推荐的精准度。而这些问题是我们下一步的研究内容。
