一种基于序列模式挖掘的trace探测方法
2018-07-25廖湖声
潘 龙 廖湖声 苏 航
1(北京工业大学计算机学院 北京 100124) 2(北京工业大学软件学院 北京 100124)
0 引 言
即时编译技术JIT compilation(just in-time compilation)是一种在程序运行时刻识别出其中频繁运行的程序片段,并将其编译为目标代码然后执行的程序优化技术,可以有效地提升程序执行效率,最早可追溯至20世纪60年代McCarthy提出的在运行时刻翻译的函数。即时编译技术可以分为基于方法和基于踪迹(trace)两种,其中基于方法的即时编译对频繁执行的整个方法进行编译,粒度较大;基于trace的即时编译在运行时动态地识别出频繁执行的代码序列,并将其作为编译的基本单元,粒度较小,可以减少整体编译时间并提高目标代码质量。
数据挖掘是从大量数据中挖掘有价值的模式的核心过程,旨在提取有效的、新颖的、潜在有用的、易被理解的知识。序列模式挖掘作为数据挖掘的一个重要研究方向,是一种在序列数据库中挖掘频繁出现的子序列作为模式的知识发现过程。序列模式挖掘在基因序列分析、购物行为分析,商业分析等实际领域得到了广泛应用。应用序列模式挖掘,能够发现潜在的知识,帮助决策者进行更好的决策和规划,从而获得巨大的经济效益与社会效益。程序解释执行过程中,按顺序执行的基本块便可以看作是序列数据。
服务器端程序运行于网络环境下,服务器响应用户请求的解释型语言程序通常是动态生成或用户提交的,无法事先进行编译优化处理,可以使用即时编译技术提高程序执行效率。同时,服务器端程序具有并发执行的特点,并发执行的解释型程序可以看作是多个基本块序列,通过对这些基本块序列应用序列模式挖掘,可以识别服务端程序中的热点代码序列,即热点trace。服务器端的trace探测能够利用服务器端并发的特点,更为高效地识别trace,从而提升程序执行效率,提高用户请求的响应速度。
为了更好地识别服务器端程序中的热点trace,提高服务器端程序的请求处理速度,本文提出了一种基于序列模式挖掘的trace探测方法,将并发执行的服务器端程序产生的多个基本块序列作为序列数据库,通过识别其中的序列模式来发现程序中的热点trace,解决了现有的trace探测方法无法针对服务器端程序进行高效探测的问题。该方法主要分为基本块数据准备、序列模式挖掘和序列模式去重与合并三个部分,在序列模式挖掘部分设计并提出了Pisat算法,用于识别热点trace。实验结果表明这种方法有效地提高了热点trace的探测效率。
1 相关工作
1.1 基于trace的即时编译
基于trace的即时编译是一种在运行时动态地识别出频繁执行的代码序列,并将其作为编译的基本单元的技术。第一个实现基于trace的即时编译系统是Dynamo[1],它是一个能提高指令流执行效率的动态优化系统。DynamoRIO[2]对Dynamo进行了扩展,它能够动态地减少解释过程中的开销,然而DynamoRIO的trace仍然在机器指令层面,没有包含解释器层面的高级信息,一些编译优化在这一层面也无法进行。
2006年,Gal等[3]开发了第一个针对高级语言的基于trace的虚拟机HotpathVM,它将字节码作为探测对象。该虚拟机动态地探测频繁运行的字节码,将这些字节码编译为SSA(Static Single Assignment)作为中间表示,并将其翻译为机器码。
Häubl等[4]基于HotSpot虚拟机,开发基于trace的即时编译系统。但该解决方案不能跨越函数,trace都很短小,节约了探测和编译的时间,但增大了环境切换的开销。
2015年,陶胜召等[5]提出了基于trace的CMinus语言即时编译技术,在该技术中,CMinus程序经过词法分析和语法分析之后得到抽象语法树,并按照一定的规则将其转换为基本块流图。解释执行将针对基本块流图进行,在解释执行过程中,采用基于计数的热点trace探测策略。虽然该研究较好地实现了基于trace的即时编译技术,但是对于trace的探测是针对程序的单次执行,无法利用服务器端程序的运行特点来高效进行trace探测。
1.2 序列模式挖掘
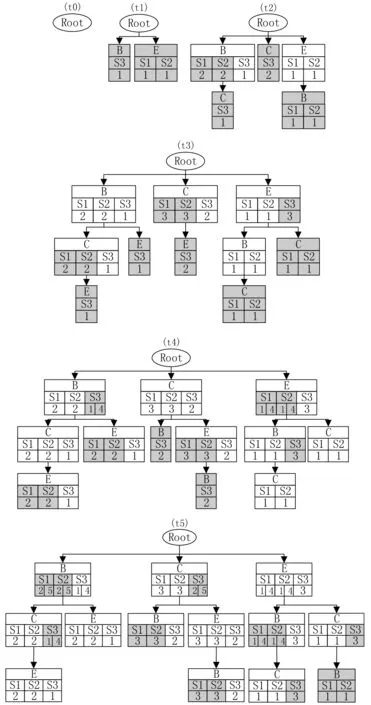
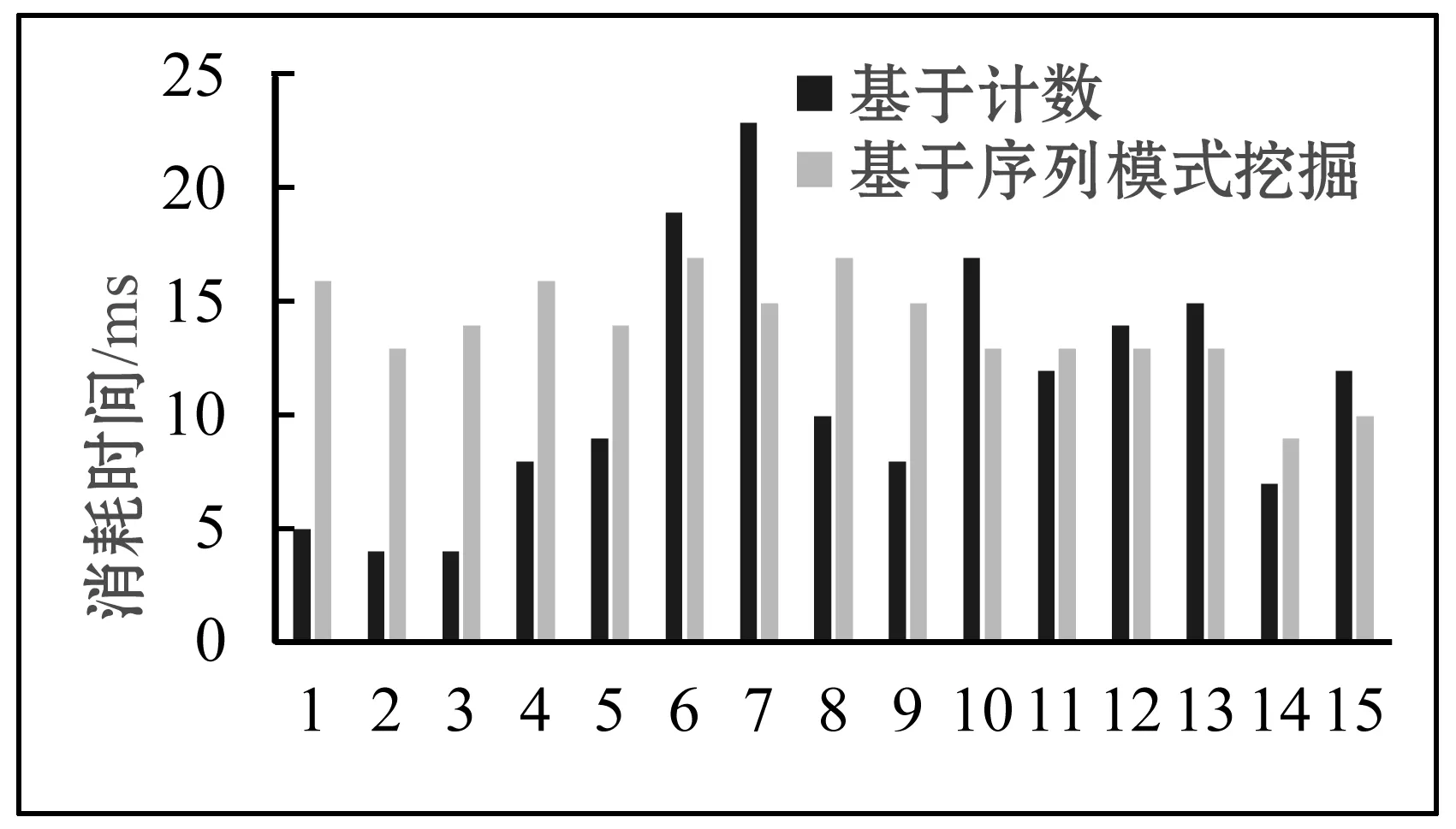
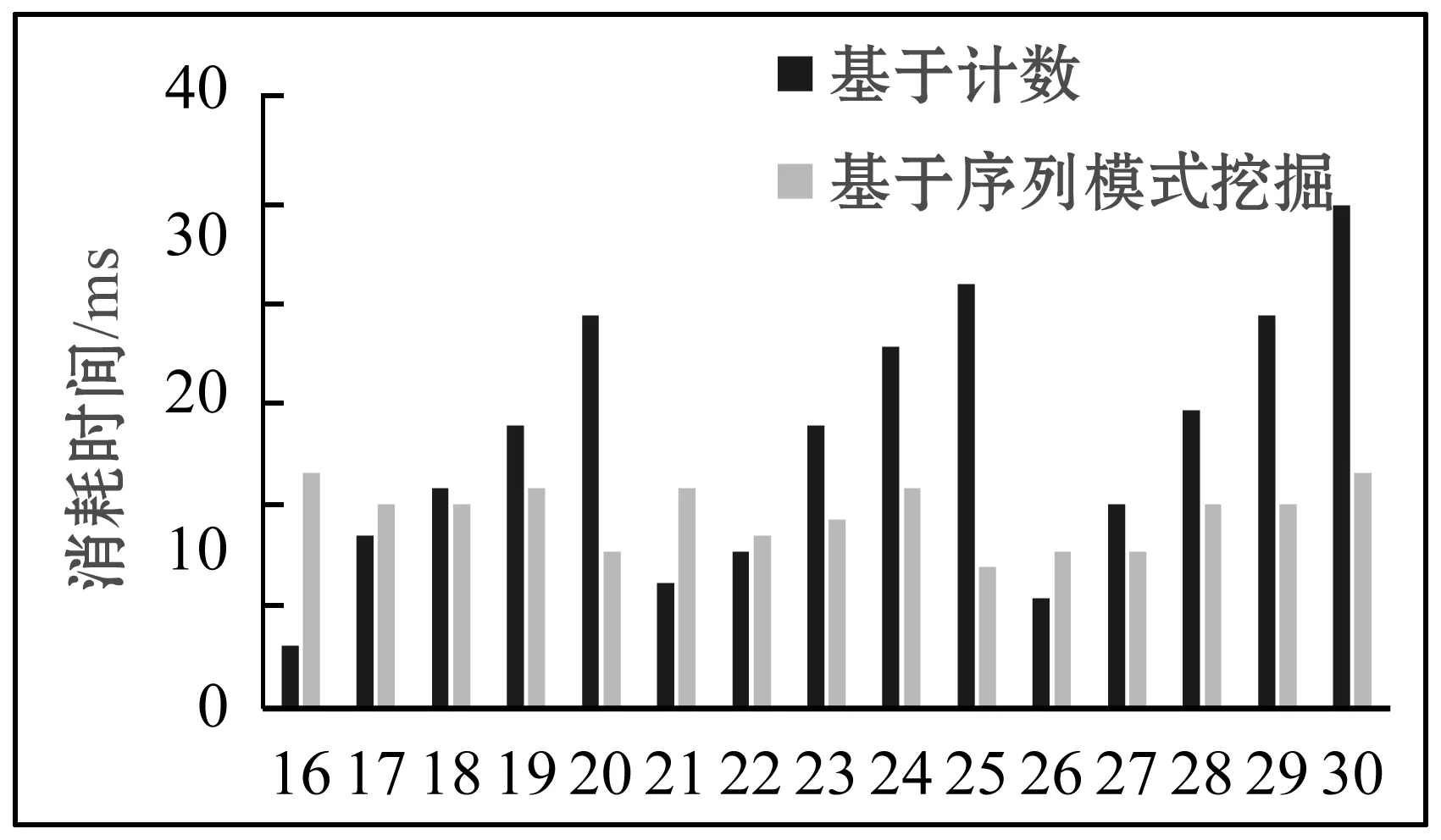
设I={x1,x2,…,xn}为所有数据项的集合。元素e是由各种数据项组成的数据项集。序列s= 序列模式挖掘最早由R.Agrawal和R.Srikant在1995年提出,是数据挖掘一个重要的研究领域。经典的静态序列数据库的序列模式挖掘算法主要有两种类型。第一种是类apriori算法,例如:R.Agrawal和R.Srikant提出的AprioriAll算法、GSP算法[6];F.Masseglia等[7]提出的PSP算法;Zaki[8]提出的SPADE算法和J.Ayres[9]提出的SPAM算法,都需要创建候选集并多次扫描整个序列数据库以得到序列模式。第二种是基于模式增长的方法,例如FreeSpan算法[10]、PrefixSpan算法[11]等,这些算法在挖掘过程中不产生候选序列,通过分而治之的思想把搜索空间划分成更小的空间,通过连接实现序列模式的增长。 在许多实际应用中,数据通常是动态变化的,传统的静态序列数据库的序列模式挖掘算法难以适用于这种情况。Huang等[12]提出了渐进式序列模式挖掘算法Pisa,支持在挖掘过程中对序列数据库进行增加和删除。Pisa算法的基本思想是构造一棵PS-tree,来保存滑动窗口内的序列信息。在PS-tree中,节点代表了序列中的元素,其数据结构如图1所示。Pisa算法根据序列数据库中新到来的数据和PS-tree中记录的序列id和时间戳,逐步地更新PS-tree节点。同一序列中先后出现的元素,在PS-Tree中表现为父子节点关系,作为候选序列模式。PS-tree不仅存储了序列中的元素和时间戳,而且有效地计算了每个候选序列模式的发生频率。虽然Pisa算法解决了数据动态变化的问题,但该算法在识别序列模式的过程中忽略了同一序列中的频繁子序列,并且在序列数据库Db只包含一条序列时无法正常工作。 图1 PS-Tree一般节点 设所有的基本块对象的集合为I={x1,x2,…,xn},数据项xi(1≤i≤n)为基本块ID。元素e代表某一时刻执行的基本块集合。程序执行产生的序列s= 在解释执行每个基本块时都会触发如图2所示的trace探测执行过程,如果解释执行遇到的基本块已经编译,直接执行已编译版本。如果解释执行遇到的基本块未被编译,则进行解释执行并收集基本块(数据准备)。收集一定数量的基本块后利用序列模式挖掘的方法识别trace,并进行trace编译。 图2 trace探测执行流程 基于序列模式挖掘的trace探测主要分为3个步骤,分别是数据准备、序列模式挖掘算法和序列模式的去重与合并。数据准备阶段接收解释器发送来的基本块数据,并转换为序列数据库,序列数据库作为序列模式挖掘算法的输入生成序列模式,通过序列模式生成热点trace返回并请求即时编译系统编译trace。 数据准备工作在基于序列模式挖掘的trace探测任务中所占的工作量比较大,是保证数据挖掘成功先决条件,主要工作有基本块数据采集和通过数据预处理生成序列数据库。若有表1中的示例程序和如图3所示的按照基本块转换规则生成的基本块流图,数据准备工作就是针对程序执行过程中产生的这些基本块进行的。 表1 示例程序 图3 基本块流图 数据准备阶段负责收集服务器端程序执行过程中产生的基本块数据。每次程序执行对应一个基本块数据缓冲区,缓冲区具有固定长度,程序解释执行过程中发送基本块数据到对应的缓冲区中,以固定的时间间隔将缓冲区中的数据转换为序列数据库发送至序列模式挖掘模块。缓冲区中只保留最近一个时间间隔的基本块数据,当基本块数据个数大于缓冲区大小时旧的基本块数据将会溢出,其中基本块数据包括基本块标识、执行基本块的程序的标识等信息。处理所有缓冲区中的数据,按照基本块产生的顺序转换生成基本块序列数据库,为了实现方便,设置同一时刻的基本块集合只包含一个基本块。基本块序列数据库是序列模式挖掘的输入数据。由于在程序执行过程中基本块的解释执行存在先后关系,所以整个序列数据库也按照逻辑上的时间先后关系创建。 本文采用CMinus语言作为基于序列模式挖掘的trace探测的中间语言,使任何可以翻译为CMinus的程序设计语言都能利用本文提供的技术提升效率。以表1中程序为例,当程序输入数据为5 947,且有3个程序实例在同时执行,也就是3条基本块序列S1、S2和S3。可以生成如表2所示的序列数据库。 表2 序列数据库 我们提出了一种序列模式挖掘算法Pisat(Progressive Mining of Sequential Patterns for Trace),用来识别基本块序列数据库中的序列模式。Pisat算法改进了Pisa算法,使其支持单序列的序列模式挖掘,并修改了子序列频繁程度的判定方法。 2.2.1 PST-tree PST-tree通过存储序列数据库中各序列的信息来帮助Pisat算法识别序列模式。PST-tree是一颗多叉树,父子节点表示同一序列中元素出现的先后关系。与PS-tree一样,PST-tree也分为根节点和一般节点,除根节点外的所有其他节点都是普通节点。根节点只包含指向其孩子节点的指针。一般节点的数据结构如图4所示,存储了三种信息,节点的标签(label),序列列表(seq_list),以及序列列表中每个序列id(sequenceID)对应的时间戳集合(timestampSet)。时间戳集合表示同一个元素多次出现,Pisat算法通过时间戳集合解决了pisa算法无法有效识别同一序列中序列模式,以及单一序列无法识别序列模式的问题。 labelsequenceID…sequenceIDtimestampSet…timestampSet 图4 PST-tree一般节点结构 2.2.2 Pisat算法 Pisat算法利用PST-Tree存储所有序列的信息,Pisat算法接收最新时刻的所有序列的元素,后序遍历PST-Tree并更新PST-Tree信息,直到没有新的元素到来。遍历PST-Tree的算法如表3所示,其主要思想是将新到来的元素插入到PST-Tree中。后序遍历PST-Tree过程中,如果处理的是根节点,对于新到来的元素,如表2(t1)时刻序列S1,S2和S3对应的元素E,E和B,如果该元素之前出现过,即新到来的元素中的基本块id与根节点的某个孩子节点标签一致,那么检查新到来元素的所属序列是否在该孩子节点的序列列表中,如果存在,算法为节点中该序列添加一个当前时间戳,表示多次出现,如果不存在,算法为节点中序列列表添加这个序列,并对应当前时间戳。如果新到来的元素之前没有出现过,算法为新到来的元素创建一个新的孩子节点,包含其所属序列和当前时间戳。处理一般节点时,如果新到来元素所属序列在节点的序列列表中,并且新到来元素不存在于根节点到当前节点的路径上,开始处理一般节点,过程类似于对根节点的处理。处理完一般节点之后,如果节点的序列列表长度不小于支持度阈值support1×|Db|或者节点中某个序列对应的所有时间戳数量不小于支持度阈值support2时,根节点到该节点的候选序列模式为序列模式,support2是新增加的支持度阈值,目的是帮助算法识别同一序列中的序列模式。 算法1traverse 输入: 当前时间戳ct 需要遍历的PST-Tree PS 新到来的所有序列的元素集合ES 序列数量sn 支持度1 support1 支持度2 support2 输出:序列模式集合SP 算法traverse 1. foreach n of PS in post order 2. if(n is root) 3. foreach e of every seq in ES 4. if(e==label of one of node.child) 5. if(seq is in n.child.seq_list) //添加时间戳 6. addTimestamp(n.child, seq, ct) 7. else //创建序列 8. createSeq(n.child, seq, ct) 9. else //创建孩子节点 10. createNode(n, e, seq, ct) 11. else //节点是一般节点 12. foreach seq in n.seq_list 13. if(e=hasNewEle(ES, seq) && isNotOnPathFromRoot(e, n)) //ES中seq序列有新元素e,且e不在从根节点开始的路//径上 14. if(e==label of one of node.child) 15. if(seq is in n.child.seq_list) //添加时间戳 16. addTimestamp(n.child, seq, getLatestTimestamp(n,seq)) 17. else //创建序列 18. createSeq(n.child, seq,getLatestTimestamp(n, seq)) 19. else //创建孩子节点 20. createNode(n, e, seq, getLatestTimestamp(n, seq)) 21. if(节点n的序列列表中序列数量≥sn*support1‖n.seq_list中某序列对应的所有时间戳数量≥support2) 22. 根节点到该节点的标签作为序列模式,收集序列模式至集合SP 辅助函数: addTimestamp(n, seq, ts): 为节点n的seq序列添加一个时间戳ts createSeq(n, seq, ts): 为节点n创建一个sequenceID为seq且对应时间戳为ts的序列 createNode(n, e, seq, ts): 为节点n创建一个label为e的子节点,包含一个sequenceID为seq且时间戳为ts的序列 hasNewEle(ES, seq): ES中seq序列是否存在新元素,存在则返回新到来的元素e isNotOnPathFromRoot(e, n): 元素e包含的基本块是否不在n到root的路径上 getLatestTimestamp(n, seq): 返回节点n中seq序列对应的时间戳集合中,最新的时间戳 如果有如表1所示的CMinus程序及转换成的基本块序列数据库表2,可以对应如图5所示的建树过程,若support1设置为1.5,support2设置为2,在(t5)时刻最左侧的标签为C的节点,其序列列表长度 图5 建树过程 挖掘得到的序列模式是程序中频繁执行的基本块,但可能存在序列模式之间互相包含、有部分相同的情况,需要进行一些去重与合并的处理,将处理后的序列模式作为trace发送至即时编译系统。如果不进行模式的去重与合并,会导致重复的trace被多次编译,增加编译开销。对序列模式的处理包含以下几种情况: 1) 当前序列模式包含其他已存在的序列模式,则将已存在的序列模式合并至当前序列模式。 2) 已存在的序列模式包含当前序列模式,则将当前序列模式合并至已存在的序列模式。 3) 已存在的序列模式包含当前序列模式的一部分,且起点一致,则将当前序列模式去重合并到已存在的序列模式中。 如图 5所示PST-Tree中,若support1设置为0.5,support2设置为2,可以识别出序列模式SP1:{B,C,E}和SP2:{C,E,B},对SP2中的元素按照基本块id排序后为{B,C,E},与SP1一致,将SP2合并至SP1:{B,C,E},对序列模式进行去重与合并之后可以有效地减少需要编译的trace数量。 本文使用CMinus程序作为即时编译系统的输入,输出是计算后的结果。首先对服务器端响应用户请求的CMinus语言程序进行分析并生成基本块流图,生成基本块流图之后,即可对基本块进行解释执行。解释执行过程中,不断将处理的基本块发送至服务器端共用的基于序列模式挖掘的trace探测器。trace探测器识别的trace存放至trace集合,并通知JIT编译器编译trace。编译完成后如解释器再运行到热点trace,即可直接运行编译好的代码。 为了验证本文提出的基于序列模式挖掘的trace探测方法的性能,实现了一个即时编译系统,并设计了一组实验程序来比较基于计数的热点trace探测策略与基于序列模式挖掘的热点trace探测方法的效率。测试环境为:Windows 10操作系统,Intel(R) Core(TM) i5-4590 CPU@3.30 GHz,8.00 GB内存,2 000 GB硬盘。开发环境为IntelliJ IEDA+jdk1.8。 本文在实验中使用的测试程序均为自定义用例,测试程序中包含了循环与分支等情况,并分别测试了程序在基于计数的热点探测策略与基于序列模式挖掘的trace探测方法,比较识别第一条trace的耗时。识别第一条trace的耗时代表着trace探测策略效率的高低,trace探测策略的效率决定基于trace的即时编译技术的优化效果。 第一组测试程序如表3所示,图6为测试结果,在程序只有单重循环的情况下,程序1-程序5无分支语句或只有一层分支语句,基于计数的策略耗时远小于基于序列模式挖掘的策略。程序6具有两层分支语句,基于计数的策略耗时略高于基于序列模式挖掘的策略。程序7具有四层分支语句,基于计数的策略耗时远高于基于序列模式挖掘的策略。在程序具有双重循环的情况下,程序8、程序9无分支语句,基于计数的策略耗时大于单重循环的情况,但仍小于基于序列模式的策略。程序10-程序13具有一层或两层分支语句,基于计数的策略耗时接近或高于基于序列模式挖掘策略。在程序具有三重循环的情况下,程序14无分支语句,基于计数的策略耗时小于基于序列模式挖掘策略。程序15具有一层分支语句,基于计数的策略耗时略高于基于序列模式挖掘策略。 表3 第一组测试程序 图6 识别第一条trace消耗的时间 为了更好地分析识别第一条trace的耗时与程序结构的关系,本文设计了如表4所示的第二组实验。测试结果如图7所示,程序在循环嵌套层数一定的情况下,基于计数的策略耗时随着分支语句嵌套层数的增加而增加,而基于序列模式挖掘的策略耗时相对稳定,一般情况下,基于序列模式挖掘的策略比基于计数的策略在效率上有所提升。 表4 第二组测试程序 图7 识别第一条trace消耗的时间 实验结果表明:分支语句嵌套层数固定时,循环嵌套层数越多,基于计数的策略耗时越多。在循环层数固定时,程序内分支语句的嵌套层数越多,基于计数的策略耗时越多,而基于序列模式挖掘的策略耗时相对稳定,可以带来效率上的提升。 为了更高效地识别服务器端程序的热点trace,本文提出了一种基于序列模式挖掘的trace探测方法,解决了现有的trace探测方法无法针对服务器端程序进行高效探测的问题。本方法收集程序解释执行过程中的基本块,并转换为基本块序列数据库,以固定的时间间隔发送至序列模式挖掘模块。针对基本块序列的特点,本文提出并使用Pisat算法作为序列模式挖掘模块的核心算法。为了减少编译开销,本方法对识别出的序列模式进行去重与合并作为热点trace,最后对热点trace进行编译。 通过实验证明,程序复杂程度足够高时,该方法与基于计数的热点trace探测方法相比,切实有效地提高了trace识别的效率。在今后的工作中,我们将对针对trace探测的序列模式算法Pisat进行并行优化,以期进一步提高trace探测效率。2 基于序列模式挖掘的trace探测

2.1 数据准备阶段



2.2 序列模式挖掘算法

2.3 模式合并
3 实 验


4 结 语
