面向SaaS应用基于多宽表模式的多租户索引研究
2018-07-25张雅文刘春霞党伟超白尚旺
张雅文 刘春霞 党伟超 白尚旺
(太原科技大学计算机科学与技术学院 山西 太原030024)
0 引 言
在SaaS应用中,一个应用实例为多个租户服务,即虽然多租户数据同属于一个应用,但是被不同的租户进行了不同的定制[1-2]。多宽表模式是一种有效存储多租户数据的解决方法,通过元数据驱动实现租户定制需求[3]。传统数据库索引是在关系的某个特定属性列上建立索引,多宽表存储模式是将所有租户不同数据模式的数据共享存储,所以传统的数据库索引技术无法适用于多宽表模式[4]。因此本文给出元数据驱动下改进的Indexes Pivot Table IIPT(Improved Indexes Pivot Table)索引模型,该模型充当多宽表模式下的租户逻辑索引,以此提高数据访问速度。
1 SaaS应用下的索引模型
在现阶段,面向SaaS应用的多租户数据管理是国内外研究的重要内容,由于多租户数据库在满足租户数据隔离和按需定制要求的同时,在性能上也需使用户有较好的体验,因此这对数据的存储机制和索引机制提出了挑战[5]。多租户数据存储已经成为热点,但是在索引方面的研究还比较少[6]。
SaaS应用采用单个数据节点对多租户数据进行共享存储,但是由于单个数据节点的能力有限,无法满足租户数量日益增长的要求,因此采用多数据节点进行存储是必然的[7]。为解决多数据节点大规模数据索引的问题,采用租户节点索引、租户逻辑索引和关系数据库物理索引三级索引相结合的索引模型[8]。租户节点索引根据当前访问的租户,定位到存储该租户数据的数据节点。租户逻辑索引在单节点上为租户数据提供支持定制、共享的索引技术,保证租户快速访问数据。关系数据库索引是一个单独的、物理的数据库结构,在底层数据库基础上提供索引技术支持[9]。
本文主要针对单数据节点的索引技术进行研究。单数据节点下的数据存储为共享模式,如果一个租户在某个属性上建立索引,其他租户也会被动地在该属性建立索引,所以在创建索引时租户间会相互干扰[10]。为了解决该问题,M-Store提出了单独建立租户索引,不仅优化了索引结构,而且提高了查询效率,但是索引数据随着租户数量的增加也会越来越多,给数据库造成很大的负担[11]。Salesforce采用建立Indexes Pivot Table来存储租户索引数据,该方法有效地提高了租户访问数据的速度,但随着租户数量的增加,Indexes Pivot Table会产生大量的空值,其占用的存储空间也会暴涨[12-13]。为了解决传统数据库索引不能适用多宽表共享存储模式的问题,以及现有的索引模型导致数据库存储空间增长的问题,给出了一种元数据驱动的IIPT索引模型,不仅存储空间不会随租户数量急速增长,而且有效提高了租户访问数据的速度。
2 多宽表模式下的租户逻辑索引
在SaaS模式下,数据库不但要提供存储的功能,还要支持租户按需定制、数据隔离以及数据扩展。结合国内外研究现状,同时比较多种存储模式优缺点,本文选择了多宽表模式来存储租户业务数据,以及给出一种适合该模式的多租户索引模型。
2.1 多宽表模式介绍
在SaaS应用中,多租户的特性支持单个应用实例被不同租户进行不同定制。宽表模式作为一种有效解决多租户数据存储问题的方法,是将所有租户不同数据模式的数据存储到一张宽表中,为了解决宽表存在大量空值的问题,提出了多宽表的存储模式。
多宽表模式提供较好的可定制性,在该模式下,租户按需定制数据项,将其定制信息保存在元数据(MetaDataFields)中,租户定制的数据项经过模式映射后,根据数据表的元数据信息(MetaTable)存储在与租户定制列数相近的宽表Data x中,多宽表的数据定义如图1所示。

图1 基于多宽表的多租户数据库
如表1所示,租户从视图层看到的是传统的关系数据模式,但是在实际的多宽表存储模式中,基于定制的元数据信息,该关系通过模式映射机制被透明的转换到宽表(Data x)中,如表2所示。

表1 租户1从视图层看到的关系
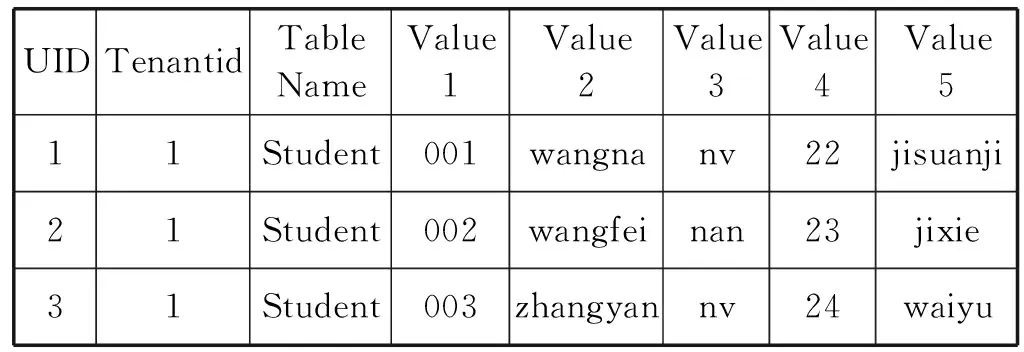
表2 租户1存储层的关系
多宽表共享存储多租户不同业务下不同的数据模式,随着租户数量的不断增加,数据量也会急剧增加,访问数据时通过顺序扫描查询势必会影响查询效率,因此建立多宽表数据存储模式下的多租户索引模型势在必行。传统索引是在关系的某个特定属性列上建立索引,该属性列下数据的数据类型、数据模式是相同的,但是多宽表存储着多种不同的数据模式,同一属性列数据可能是不同的数据类型或代表不同的数据含义。因此给出了一种元数据驱动改进的Indexes Pivot Table索引模型。
2.2 基于Indexes Pivot Table的多租户索引模型
Salesforce建立Indexes Pivot Table存储索引数据。Indexes Pivot Table中包含字段如StringValue、NumValue和DateValue等,Salesforce将索引数据按数据类型存储在相应的字段中。例如,Salesforce会将数据表中字符串数据类型的数据复制到索引表中的StringValue字段,日期类型的数据复制到DateValue字段等。该Indexes Pivot Table在存储索引数据时,如果其中一个数据类型字段存储了索引数据,则其他数据类型为空值。随着数据量的增大,空值的数量也会逐渐增大,浪费了存储空间。针对产生大量空值的情况,对Indexes Pivot Table进行改进,将多种数据类型字段合并存储在一列中,有效解决了空值产生的问题。
2.3 基于多宽表的多租户索引模型
本文对多宽表模式的多租户数据库进行扩展,增加了基于元数据驱动改进的Indexes Pivot Table。图2描述了IIPT多租户数据库模型,模型中的表分为两种。一种为元数据表,另一种为数据表。元数据表包括字段元数据MetaDataFields、多宽表的元数据MetaTable以及索引元数据IndexDataTable。数据表包括一系列的宽表Data。

图2 IIPT多租户数据库模型
下面给出本模型的表结构定义。
定义1MetaDataFields
表示字段元数据,用于存储Data宽表的信息以及其中属性的各种信息。租户标识TenantId、租户逻辑私有表标识TableName,以及宽表所属列名fieldName联合作为主键,通过RealTableName可以映射出租户业务数据fieldName实际物理存储位置,而RealFieldName可以映射Data宽表中fieldName的真正含义。fieldType、fieldLength、isIndexed、DataType分别表示fieldName的属性:类型、长度、是否为索引、真正的数据类型。
定义2MetaTable
表示多宽表的元数据,用于存储所有Data宽表的基本信息,包括宽表的表名和列数等信息,该信息作为租户选择宽表进行存储的依据。
定义3IndexDataTable
表示索引元数据,用于共享存储多宽表的索引。Indexes Pivot Table存储多种数据类型的索引数据,造成索引表中空值的增多。本文对Indexes Pivot Table进行改进,将多种数据类型共同存储在一列中。通过访问字段元数据表,对于需要建立索引的数据,将其从宽表复制到索引表中,无需关注数据类型。
定义4Data1, Data2, Data x
表示数据表,宽表的列数呈递增趋势分布。租户根据数据模式具有的属性列数选择合适的宽表存储业务数据。UID是全局唯一标识作为宽表的主键,与租户标识TenantId和租户逻辑私有表标识TableName一起对租户的业务数据进行共享存储,它们的最大列数分别为valueMax、columnMax、rowMax。
3 基于多宽表的多租户索引维护策略
租户索引具有可定制性,定制过程就是根据租户需求及对关系模式中某字段适合作为索引的判断,将字段元数据表(MetaDataFields)中的isIndexed字段设置为yes。在对实时性要求较高的SaaS应用中,如果没有索引更新策略是不可行的。当业务数据插入、删除、修改时,索引元数据需同时更新;当业务数据查询时,首先根据字段元数据表判断是否存在索引,如果存在按照索引查询,并返回结果,如果不存在,则顺序查询,返回查询结果。本文给出IIPT索引模型的索引插入算法IIPTIA(Improved Indexes Pivot Table Insert Algorithm),索引删除算法IIPTDA(Improved Indexes Pivot Table Delete Algorithm),索引更新算法IIPTUA(Improved Indexes Pivot Table Update Algorithm)及查询算法IIPTQA(Improved Indexes Pivot Table Query Algorithm)。
算法1索引插入算法(IIPTIA)
输入:insert into R (A,B,…) values(value1,value2,value3,…)
输出:null
1. 获取当前租户标识Tenantid;
2. 根据输入语句更新数据库中的业务数据表Data,保存全局唯一标识(UID);
3. 根据租户标识Tenantid,for私有表R中的字段A,B,…,在字段元数据表MetaDataFields中判断出R定制的索引列;
4. 取出索引列上更新的值;
5. 根据索引元数据表的结构对索引值进行存储。
算法2索引删除算法(IIPTDA)
输入:delete from R where A=′b′;
输出:null
1. 获取当前租户标识Tenantid;
2. 根据输入语句获得私有表名称R与列名A,查询字段元数据表MetaDataFields取得实际存储表名与实际列名;
3. 根据步骤2得出实际删除业务数据的SQL语句;
4. 根据步骤2对实际存储的表进行查询,保存要删除信息的全局唯一标识UID;
5. 根据步骤4中所得UID对索引表进行删除操作,由此当对业务数据进行删除操作时,业务数据所对应的索引数据也同步进行删除。
算法3索引更新算法(IIPTUA)
输入:update A set B=′b′ where C=′c′;
输出:null
1. 获取当前租户标识Tenantid;
2. 根据输入语句获得私有表名称R、列名A与列名B,查询字段元数据表MetaDataFields取得实际存储表名与实际列名,以及set的列是否为索引列;
3. 对sql语句进行解析,获得索引更新值b与条件值c;
4. 根据步骤2与步骤3得出实际更新业务数据的SQL语句;
5. 根据步骤2与步骤3对实际存储的表进行查询,保存要更新信息的全局唯一标识UID;
6. if步骤2中结果为yes
根据步骤5中得到的UID对索引数据表进行更新
else步骤2中的结果为no。
无需对索引表进行更新。
算法4数据查询算法(IIPTQA)
输入:select A,B,… from R where D=value1
输出:符合条件的目标结果集
1. 获取当前租户标识Tenantid;
2. 解析查询语句中的私有表R和所查字段A,B,…;
3. 查询字段元数据表(MetaDataFields)获得私有表R实际存储表名Data,以及所查字段(A,B,…)在Data表中的实际字段名value n(n=1,2,…,n);
4. 查询字段元数据表(MetaDataFields)获得where条件D是否为索引;
5. If 步骤4中结果为yes
查询索引元数据表(IndexDataTable)获得数据行全局唯一标识UID;
在Data表中,根据UID字段上的数据库物理索引B-树,直接查;
返回符合条件的目标数据集。
Else 步骤4中的结果为no
依次将A,B,…,D用查询到的实际字段名value n替换,将R用Data表替换;
替换后拼接成可直接作用于Data表的查询语句,进行查询;
返回符合条件的目标数据集。
4 实验结果与分析
本文实现了基于关系型数据库,在多宽表共享数据存储模式下元数据驱动的索引机制。实验主要针对空值数量进行分析,并对本文给出的索引策略进行验证。实验环境如下:
数据库版本为MySQL Server 5.5,运行环境为Eclipse 3.7.2。
4.1 空值数量的分析
在存储单元的基础上对空值数量进行分析,假设存储N个索引数据。若采用Indexes Pivot Table存储,其中表示数据类型的字段有M个,则存在(M-1)×N个空值。
若采用IIPT存储,所有索引数据只存储在一个字段中,没有空值产生。
分析可得,采用改进的Indexes Pivot Table,相对于Indexes Pivot Table,解决了空值问题,节省了存储空间。
4.2 索引策略验证
实验数据采用3个关系模式作为实例,分别为:学生(Student)关系模式、课程(Course)关系模式和地址(NativePlace)关系模式。定制关系模式中的一个属性为索引属性,分别为CNo、NNo和SOld。3个关系模式的数据经过模式映射存储在合适的Data表中,Data表中字段UID上有主码索引,Data表数据量为10 000条。
由租户发起insert插入数据的更新操作,实验算法1中的索引插入。例句如下:
insert into Course (CNo,Cname,CGrade) values (8,yuwen,2)
insert into NativePlace(NNo,Nname,NPlace) values (001,wangli,beijing)
insert into Student(SNo,Sname,SSex,SOld,Spart) values (001,wangna,nv,22,jisuanji)
分别更新数据到各自的Data表中,如表3和表4所示。
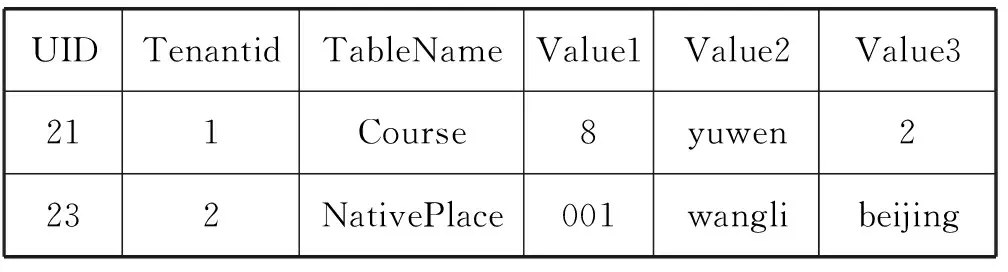
表3 Course和NativePlace所在Data表

表4 Student所在Data表
根据更新的数据对索引表同步更新,如表5所示。
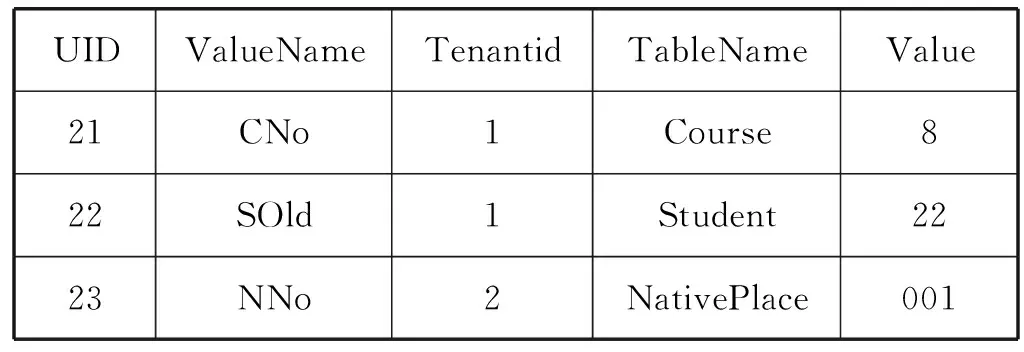
表5 改进的Indexes Pivot Table
以上实验实现了算法1的索引插入的更新策略。
由租户发起delete删除数据的更新操作,实验算法2中的索引删除。例句如下:
delete from Student where SNo=′000′
根据算法2可成功删除实际存储表中Student 学号为′000′的数据,同时也删除了索引表中该学生的所有索引信息。
由租户发起update数据的更新操作,实验算法3中的索引更新。例句如下:
update Student set SOld=′30′ where SNo=′000′
根据算法3,判断得出SOld为索引列,因此在更新业务数据的同时对索引表也进行更新。
update Student set SName=′zhangli′ where SNo=′000′
根据算法3,判断得出SName不是索引列,因此只需更新业务数据,索引表保持不变。
为了模拟多租户环境,本实验开启40个线程作为40个租户对数据进行操作。记录有索引机制与没有索引机制40个租户分别对数据进行查询的时间,实验结果如图3所示。

图3 查询时间对比
如图3所示,图中上方的曲线是没有加入索引机制的查询时间,下方是加入索引机制后的查询时间。在无索引机制下,40个租户的平均查询时间为123.675 ms;在索引机制下,平均查询时间为30.025 ms,比无索引机制的平均查询时间低75.72%。通过实验验证可得,在两级索引即租户逻辑索引和关系数据库物理索引的基础上,本文给出的算法是可实现的,并且提高了多租户数据查询效率。
综上所述,给出的多宽表模式下的索引模型,较好地解决了SaaS应用索引的定制问题,以及在查询效率上实验效果也较为理想。
5 结 论
本文基于MySQL关系型数据库,在多宽表数据存储模式下引入改进的Indexes Pivot Table,减少了Indexes Pivot Table作为索引表产生的空值数量。同时给出了在该模型下的索引维护策略,包含索引更新策略和在索引机制下的查询策略,通过实验实现了同步更新索引表以及有效提高数据查询效率。在下一步研究中,如何对索引列更全面地进行设置是需要考虑的问题。
