数字保存的可理解性风险检测
2018-07-24臧国全王秀娟郑州大学信息管理学院公共管理学院
臧国全,王秀娟,李 哲(郑州大学 .信息管理学院;.公共管理学院)
1 可理解性涵义及其风险类型
1.1 可理解性涵义
可理解性是指针对保存的数字对象,保存系统的目标用户群体能够理解其内容。[1]理解方式有三种。
(1)基于结构信息的概略理解。[2]比如,数字对象的标题、作者信息、出版信息等有助于用户了解数字对象的基本范畴,而这些信息都是用于描述数字对象的内部构成。再如,一件数字对象与其他多件数字对象存在关联,前者可称为中心数字对象,后者可称为关联数字对象,后者围绕前者形成了一个数字对象的网状结构。其中,中心数字对象与关联数字对象之间的结构有多种,如整体部分结构、同位结构、依赖结构等,这些结构以及由结构关联的数字对象也有助于用户概略理解中心数字对象的内容。
(2)基于语义信息的精确理解。当对数字对象的内容无法准确理解时,保存系统应提供附加信息帮助用户理解。这些附加信息被称为语义信息。语义信息可分为整体式语义信息和知识点式语义信息,前者用于整体理解数字对象内容所需的附加信息,后者用于理解数字对象中知识点内容所需的附加信息。
(3)基于展现信息的识别理解。数字对象只有展现出来方可被用户识别理解。使用浏览软件可对数字对象进行展现浏览;使用解码工具对编码数字对象解码后进行展现浏览;使用信息摘要检验数字对象的真实性后进行展现浏览。
1.2 可理解性风险类型
基于理解方式,影响用户理解数字对象的因素包括以下几方面。
(1)数字对象的内部组成结构不完整。比如主要部分缺失,或因数字转化过程导致、或因原始文献残缺导致、或因原生型数字资源本身问题导致的缺失,会妨碍用户从数字对象内部结构角度对数字对象的概要理解。
(2)数字对象与保存的其他数字对象之间关联结构识别不完整,或识别出现偏差,或结构类型界定错误,导致以被理解数字对象为中心的关联数字对象构成的结构网络存在缺陷,妨碍用户从数字对象之间关联结构角度对数字对象的概要理解。
(3)用于用户理解数字对象整体内容所需的附加信息,保存系统识别不够全面,或与数字对象之间相关度欠佳。原因可能是保存系统对目标用户群体界定不够清晰,或对目标用户群体的知识储备识别不够准确,影响用户利用附加信息帮助理解数字对象的整体内容。
(4)用于用户理解数字对象中知识点所需的附加信息,保存系统识别不够准确,或不够全面,或已遭到破坏,影响用户利用附加信息帮助理解数字对象的知识点。
(5)用于帮助用户准确理解数字对象的整体内容或知识点所需的附加信息无法有效浏览,或浏览效果存在瑕疵,影响用户对这些附加信息的准确使用,从而可能降低用户对数字对象整体内容或知识点的理解。
(6)数字对象无法浏览,或浏览效果不佳,导致用户无法有效识别数字对象,从而无法理解数字对象。
(7)经过编码的数字对象无法还原,导致用户无法浏览、识别数字对象,致使数字对象失去可理解性。
(8)保存系统的一些保存操作导致数字对象改变,这些改变可能影响用户对数字对象内容的理解。
上述类型(1)和类型(2)的风险将影响可理解性涵义中的第一种理解方式;类型(3)-类型(5)的风险将影响可理解性涵义中的第二种理解方式;类型(6)-类型(8)的风险将影响可理解性涵义中的第三种理解方式。
总之,可理解性风险主要存在于数字对象的内部结构、数字对象的关联结构建立、用于用户理解数字对象所需附加信息的识别、保存系统对目标用户群体及其知识储备的界定、数字对象有效识别和浏览、保存系统实施保存活动对数字对象的影响等方面。
2 可理解性风险型元数据
2.1 数字对象方面的可理解性风险型元数据
这类元数据有助于理解数字对象内容的数字对象方面的属性,以及帮助用户理解数字对象内容所需的附加信息,是数字对象的可理解性风险的检测点。这些属性和附加信息的缺失,将影响数字对象的可理解性。
(1)数字对象唯一标识符,[3]用于识别被检测的数字对象。如果数字对象没有被赋予唯一标识符,则无法被保存系统识别,也就无法进行可理解性风险检测。该元数据不作为可理解性风险的检测点。
(2)数字对象类型,用于过滤不被检测的数字对象。在所有类型的数字对象中,比特流和知识实体不具可理解性,所以,检测之前,需通过该元数据将这两类数字对象过滤掉。该元数据也不作为可理解性风险的检测点。
(3)数字对象内部结构信息,指数字对象内部的基本组成部分。内部结构信息依据数字对象的类型不同而有所区别。如,会议文献的内部结构信息有会议名称、篇名、作者、摘要、正文、参考文献、基金、论文集名称等;专利文献的内部结构信息有专利名称、申请号、公开号、申请人、发明人、正文、参考文献等。内部结构信息有助于用户对数字对象的大概判断和了解,这类信息的错误可能会导致用户对数字对象的概要了解偏差,这类信息的缺失可能会导致用户对数字对象的概要了解困难。因此,这类信息是数字对象可理解性风险的检测点。
荫元素。(a)数字对象的类型。(b)内部结构信息的名称。(c)内部结构信息的内容。
荫检测项目。(i)基于元素(a)描述的数字对象类型,检查保存政策中对应的内部结构信息列表,当出现不一致情况,输出风险。(ⅱ)检查元素(b)和(c)描述的正确性,可与数字对象直接对比实现,当出现描述值与实际值不一致的情况,输出风险。
(4)数字对象外部结构信息,指数字对象与保存系统中的其他数字对象之间的结构描述。如,网站对象与其包括的各个网页对象之间呈现包含结构,同一网站对象内所包含的各个网页对象之间呈现同位结构。因此,保存系统中,一件数字对象及与其存在关联的其他数字对象就形成一个网状结构。该结构中,中心数字对象是检测对象,其他数字对象为节点对象。呈现各节点数字对象以及每个节点数字对象与中心数字对象之间的结构,有助于用户对中心数字对象的概要理解。节点数字对象的缺失可能会降低用户对中心数字对象的可理解性。同样,节点数字对象与中心数字对象之间结构的描述错误也可能会导致用户对中心数字对象的理解偏差。因此,外部结构信息是数字对象可理解性风险的检测点。
荫元素。(a)节点对象的标识符。(b)中心数字对象与节点数字对象之间的结构描述。
荫检测项目。(i)检查元素(a)和元素(b)的内容,任一元素无描述值,都无法完整构建中心数字对象的外部结构信息,影响用户对中心数字对象的可理解性,输出风险。(ⅱ)检查中心数字对象与节点数字对象的实际结构,比较实际结构与元素(b)描述结构的一致性,当两者出现偏差时,节点数字对象可能无助于用户对中心数字对象的理解,输出风险。
(5)整体式语义信息。整体理解一件数字对象内容所需的附加材料,是数字对象可理解性风险的检测点。它包括:单维整体式语义信息和多维整体式语义信息。
单维整体式语义信息。整体理解一件数字对象,只需一件附加材料提供帮助,该附加材料称为单维整体式语义信息。如,一篇研究《红楼梦》的文献,如果用户没有《红楼梦》的知识背景就不太容易理解其内容,故需参考《红楼梦》原著,这样,后者就成了前者的可理解性的单维整体式语义信息。另外,一件数字对象中,没有加注定点标注的单项参考文献也是该数字对象可理解性的单维整体式语义信息。
多维整体式语义信息。整体理解一件数字对象,需多件附加材料从不同的角度提供帮助,这些附加材料称为多维整体式语义信息。如,《蒙娜丽莎》是一件艺术品,对该作品的所有研究成果都有助于用户对该作品的理解,因此,这些研究成果构成了该艺术作品的可理解性的多维整体式语义信息。另外,一件数字对象中,没有加注定点标注的多项参考文献也是该数字对象可理解性的多维整体式语义信息。
实际上,任何一个保存系统都有一个特定的目标用户群体。该群体的成员中,有的由保存系统构建和维护的资金提供者指定,有的由数字资源提交者指定,还有的由保存系统根据其服务政策界定。不同保存系统的目标用户群体不一样,甚至存在很大差异,这种差异不仅表现在目标用户群体的大小上,还表现在目标用户群体的构成上。不同用户群体具备的知识储备不同,有时,理解一件数字对象所需的语义信息很多,保存系统只需保存目标用户群体知识储备之外的语义信息,所以,针对一件保存到不同保存系统中的数字对象,保存系统应该提供的语义信息也不同。另外,用户的知识储备也会随着时间的推移而变化,针对一个保存系统,即使目标用户群体没有发生变化,理解数字对象所需的语义信息也会随着时间的推移而不同。所以,既不存在一个适合所有保存系统的语义信息提供的通用方案,也不存在适合一个特定保存系统中各个时期的通用方案。因此,语义信息的提供方案是具体保存系统的决策和实施问题。
荫元素。(a)语义信息名称。(b)语义信息获取的方式,包括唯一标识符和链接。(c)语义信息获取的值,包括唯一标识符的值(若类型为唯一标识符)和URL(若类型为链接)。(d)语义信息的最佳浏览工具,语义信息也是一种类型的文件,用户的使用必须借助浏览工具,包括浏览工具名称和版本。
荫检测项目。针对一件数字对象,很难判断保存系统提供的语义信息的全面性,只能判断其相关性,所以无法检测全面性,仅检测相关性。(i)检查前三个元素,若任一内容缺失,要么语义信息缺失名称,要么无法找出具体的语义信息,输出风险。(ii)检查基于元素(b)和元素(c)析出的语义信息与检测数字对象的相关性,若不相关,提供的语义信息无助于用户对检测数字对象的理解,输出风险。(iii)析出语义信息存在的文件格式,在保存政策中找出该格式对应的最佳浏览工具,再与元素(d)描述的浏览工具比较,若不一致,将导致用户不能浏览语义信息或浏览效果有瑕疵,致使语义信息无法为理解数字对象提供帮助或帮助效果欠佳,输出风险。
(6)知识点式语义信息。理解数字对象中一个知识点所需的附加材料,是数字对象可理解性风险的检测点。包括单维知识点式语义信息和多维知识点式语义信息。
单维知识点式语义信息。理解数字对象中一个知识点,只需一件附加材料,该附加材料为单维知识点式语义信息。如,一篇文献中包含一个概念,而文献本身并没有对该概念给予解释,如果用户不具备该概念的知识储备,就需在百科全书中找到该概念的词条,该词条就是该知识点的可理解性的单维知识点式语义信息。
多维知识点式语义信息。理解数字对象中一个知识点,需多件附加材料,这些附加材料为多维知识点式语义信息。比如,一件数字对象中,针对一个知识点标注的多项参考文献,这些参考文献就构成了该知识点的可理解性的多维知识点式语义信息。
知识点式语义信息的风险型元数据元素设置和检测项目的设置与整体式语义信息基本相同。但在检测项目(ⅱ)中,相关性判断的对象是检测数字对象中的一个知识点,不是整个数字对象。
(7)最佳浏览软件。有些情况下,一种格式文件可通过多种软件浏览,但有时浏览效果不完全一样,应选择最佳软件;当最佳软件有多款时,应都予以记录。如果该元素描述的软件无法打开被检测的数字对象,或虽可打开但浏览效果不是最佳,那么,该数字对象对用户来说不可浏览使用,更不具可理解性,或浏览效果欠佳,影响用户理解。所以,浏览软件是数字对象可理解性风险的一个检测点。
实际上,对于大多数类型的数字对象,格式都是常用的,一般用户都知晓也容易获得这些格式的最佳浏览软件。但是也有一些格式是专用的,浏览所需软件也是专用的,如,CAJ是专用格式,浏览软件是Cajviewer专用工具,这类浏览软件需描述和保存,以便需要时用户获取。为了便于统一,该元数据可设置为必备元数据,无论是常用格式还是专用格式,最佳浏览软件均需描述。
荫元素。(a)软件名称。(b)软件版本。
荫检测项目。析出被检测数字对象的文件格式,在保存政策中找出该格式的最佳浏览软件,与元素(a)和元素(b)描述的软件对比。若不一致,可能是因描述出现问题,或长期保存过程中保存系统实施了某项保存活动(如数字迁移),导致数字对象格式发生了变化,但该元数据的描述内容没有及时更新,导致浏览软件难以胜任数字对象的有效呈现,输出风险。
(8)还原信息。[4]如果数字对象是一个压缩包或加密文件,无法直接呈现,用户也无法浏览,更谈不上理解。此时需要实施还原操作,还原过程所需的信息(比如密码、还原工具等)称为还原信息。如果还原信息错误,导致还原过程无法完成,或虽完成但出现偏差,致使无法获得原始文件,也无法浏览,更无法理解。所以,还原信息是数字对象的可理解性风险的检测点。
荫元素。(a)还原级数,如果数字对象需要多次还原方能获得原始文件,记录每次还原的级数,原始文件的还原级数为0。(b)还原工具,每次还原所需的软件工具。(c)还原密码,每次还原操作所需的密码,若无密码,记录为“无”。当还原级数大于1时,需要分别记录每个级数的还原工具和还原密码。
荫检测项目。(i)依据元素(a)和元素(b),检查每一级数的还原工具,若还原工具记录缺失,导致在该级数上可能无法实施还原操作,输出风险。(ii)依据元素(a)和元素(c),检查每一级数的还原密码,若缺失,在该级数上无法实施还原操作(因为根据标引规则,即使无密码,元素(b)的内容也应记录为“无”),输出风险。(iii)析出数字对象,依据元素(a)、元素(b)和元素(c)的内容,依次检查每一级别的还原工具的适用性和还原密码的正确性,当任一还原操作无法完成时,输出风险。
(9)信息摘要。当数字对象的内容发生变化时,也会影响用户对其的理解。判断数字对象在长期保存过程中因为一些保存活动的执行而导致其是否发生改变的一种可信任方法是信息摘要的使用。[5]因此,信息摘要可作为一种手段来判断数字对象的可理解性是否发生了风险。
荫元素。(a)摘要算法,数字对象被收录到保存系统时对其进行摘要计算所使用的算法。(b)摘要值,数字对象被收录到保存系统时对其进行摘要计算的执行结果。
荫检测项目。(i)析出数字对象,按照元素(a)描述的摘要算法对其重新计算摘要,将重新计算的结果与元素(b)的描述内容对比,当不一致时,数字对象已经发生了变化,产生可理解性风险,输出风险。(ii)检查元素(a)的值和元素(b)的值,当前者没有值时,无法重新计算数字对象的摘要;当后者没有值时,虽可重新计算数字对象的摘要,但与之对比的原始摘要值缺失。这两种情况都无法判断数字对象是否发生了改变,输出风险。
2.2 保存事件方面的可理解性风险型元数据
保存系统实施的影响数字对象可理解性的保存活动是可理解性风险的检测点。
(1)外部结构判定。在数字对象被收录到保存系统之时,保存系统执行该保存活动,建立被收录数字对象的外部结构信息。该事件是否被执行以及执行的结果将直接影响数字对象方面的可理解性风险型元数据中的第4个元素内容的赋值。若没有执行,数字对象的外部结构网络无法建立,输出风险。
(2)摘要计算。保存系统收录数字对象时,实施摘要计算,形成信息摘要,为以后固定性检测提供依据。该事件是否被执行将直接影响数字对象方面的可理解性风险型元数据中的第9个元素内容的赋值。若没有执行,数字对象的信息摘要无法建立,输出风险。
(3)语义信息识别。在数字对象被收录到保存系统之时,保存系统执行该保存活动,建立被收录数字对象的语义信息。该事件是否被执行以及执行的结果将直接影响数字对象方面的可理解性风险型元数据中的第5个元素和第6个元素内容的赋值。若没有执行,保存系统不提供理解数字对象所需的附加信息,输出风险。
(4)病毒检测。数字对象一旦遭到计算机病毒损坏,可能会造成其内容的篡改或不可用,影响数字对象的可理解性。因此,病毒检测需按保存政策规定实施;否则,输出风险。
(5)介质刷新。用来存放数字对象的存储介质如果损坏或者过期,数字对象可能不能正常读取,影响其可理解性。因此,介质刷新需按保存政策规定实施;否则,输出风险。
(6)迁移事件。数字对象格式过时,用户无法正确读取数字对象内容,影响数字对象的可理解性。因此,迁移事件需按保存政策规定实施;否则,输出风险。
2.3 保存政策方面的可理解性风险型元数据
保存系统设置的一些指标用于可理解性风险型元数据的检测基准,但不作为可理解性风险的检测点。
(1)内部结构信息列表。保存系统根据不同类型数字对象的特征,界定每种类型数字对象所包含的内部结构信息,用于第一类元数据的第3个元素的检测项目 (i)。
(2)最佳浏览工具判定。保存系统根据浏览工具对相应格式数字对象的支持程度,选择出的最佳浏览工具和版本,用于第一类元数据的第5个元素的检测项目(iii)和第7个元素的检测项目。
(3)病毒检测周期。病毒检测的频率设置,用于保存事件中的病毒检测事件的风险检测。
(4)介质刷新频率。介质刷新的频率设置,用于保存事件中的介质刷新事件的风险检测。
(5)迁移准确率。数字对象迁移前后内容没有发生改变部分占迁移前数字对象整个内容的比率,用于保存事件中的迁移事件的风险检测。
3 实验
3.1 术语界定
样本数据来自“中国知网”。为便于实验操作和结果的展示,界定相关术语见表1。
3.2 样本集形成
3.2.1 数字对象样本集的形成
数字对象样本来源:中国知网。样本总量:1万件。采集方法:分层随机抽样法。采集步骤如下所示。
(1)构建样本单元。样本单元是指在时间区间、文献类型、学科三个维度的交集点上数字对象集合,可表示为:{TDi,CDj,SDk}(i∈ [1,7],j∈ [1,9],k∈[1,8])。因此,样本单元总数:7×9×8=504个。
(2)计算样本单元的样本抽取量。公式:SES{TDi,CDj,SDk}=TS{TDi,CDj,SDk}÷TT×ST。其中:SES代表样本单元的样本抽取量;TS代表样本单元的数字对象总量,可根据样本单元中的时间区间、文献类型和学科构建检索条件,检索获得;TT代表中国知网中的数字对象总量,可由将上述计算的各个样本单元的数字对象总量求和获得;ST代表设定的样本总量。
表1 术语界定表
(3)样本单元中的样本抽取。首先,检索获得样本单元的数字对象集合,检索条件构建同上述样本单元的数字对象总量计算中的检索条件。其次,在检出的样本单元数字对象集合中,简单随机抽取上述计算出的样本单元抽取数量(SES)的数字对象序号。再次,依次套录对应序号的数字对象,形成样本单元的数字对象抽取样本。最后,采用上述步骤,依次获得各样本单元的数字对象样本,形成数字对象的总样本。
3.2.2 可理解性风险型元数据内容的形成
首先,本研究的合作单位中国知网帮助提供数字对象样本集的相关元数据的赋值内容,主要包括描述型、管理型和保存型三类元数据。其次,对采集的每件数字对象的可理解性风险型元数据元素的内容赋值,若有对应元素或相似元素,直接套录自上述三类元数据中对应元素的内容,若无对应元素或相似元素,则无赋值。因此,可理解性风险型元数据元素的赋值真实地反映了样本数字对象的可理解性风险状态。
3.3 检测算法
基于数字对象样本集的维度属性,设计各类检测算法的描述(见表2)。
3.4 检测结果
3.4.1 零维度检测结果
执行检测算法中的零维度检测算法,检测结果的可视化形式见图1。
表2 检测算法描述
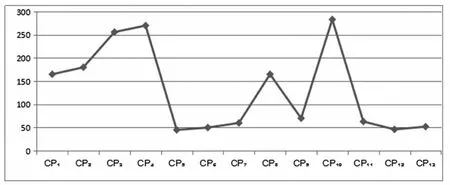
图1 零维度检测结果
数字对象样本在可理解性风险型元数据上风险值较 高 的 检 测 点 依 次 为 : CP1、 CP2、 CP3、 CP4、 CP8、CP10。
3.4.2 单维度检测结果
(1)TD的单维度检测。执行TD(时间维度)单维度检测算法,检测结果的可视化形式见图2,描述形式见表3中TD单维度检测结果的风险点分布{TDi}部分。
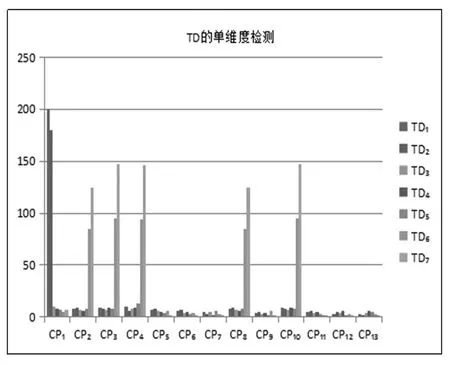
图2 TD单维度检测结果
(2)CD的单维度检测。执行CD(文献类型维度)单维度检测算法,检测结果的可视化形式见图3,描述形式见表3中CD单维度检测结果的风险点分布{CDj}部分。
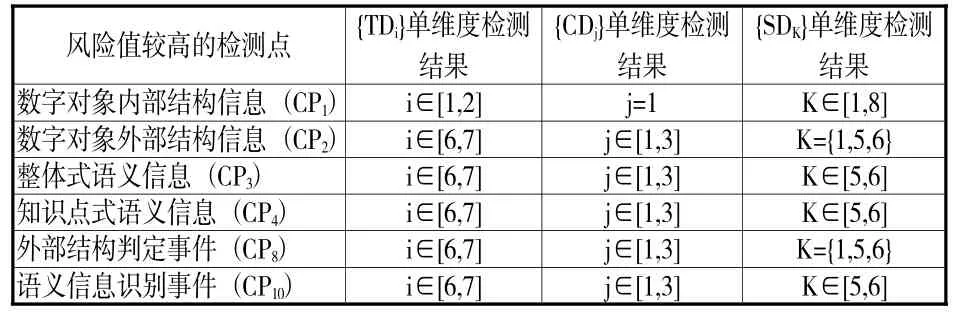
表3 单维度检测结果
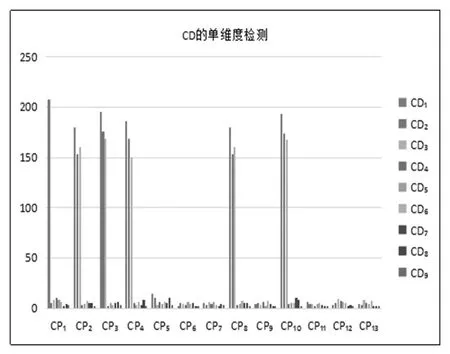
图3 CD单维度检测结果
(3)SD的单维度检测。执行SD(学科维度)单维度检测算法,检测结果的可视化形式见图4,描述形式见表3中SD单维度检测结果的风险点分布{SDK}部分。
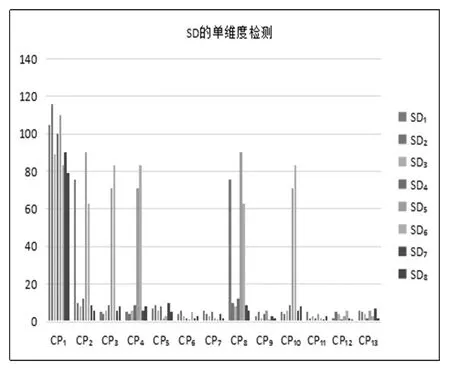
图4 SD单维度检测结果
3.4.3 双维度检测结果
(1){TD,CD}的双维度检测。检测结果见表4中的第2列。
(2){TD,SD}的双维度检测。检测结果见表4中的第3列。
(3){CD,SD}的双维度检测。检测结果见表4中的第4列。
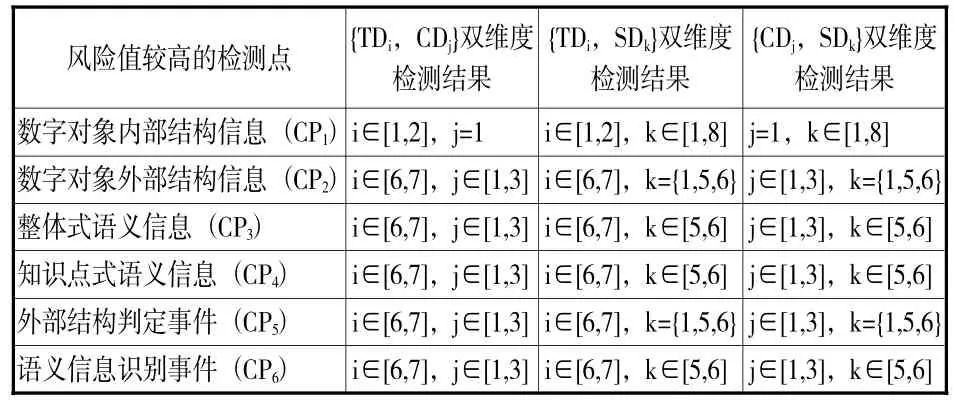
表4 双维度检测结果
3.4.4 三维度检测结果
{TD,CD,SD}三维度检测。检测结果见表5。
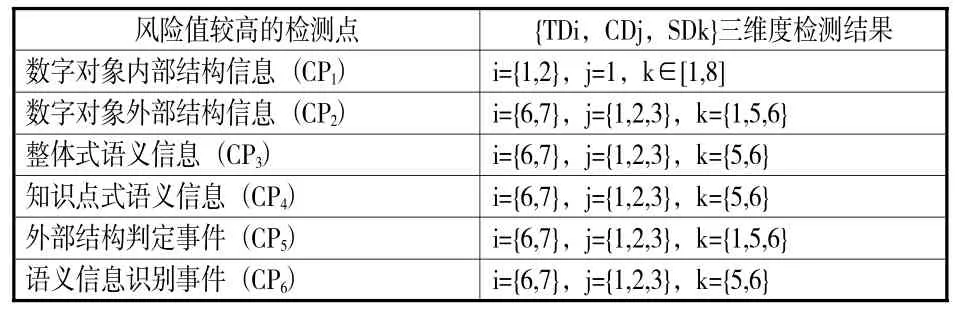
表5 三维度检测结果
3.5 检测结果分析
基于上述实验结果,分析得出可理解性主要风险点及其产生的主要数字对象集合如下。
(1)数字对象内部结构信息。集中在{TDi,CDj,SDk}(i={1,2},j=1,k∈ [1,8]),即 1995年之前所有学科的期刊文献之中。可能原因在于,数字扫描是1995年之前期刊文献采用的数字转换主要方式,扫描结果为图片格式。故,数字对象的内部结构信息难以自动析出,需人工提取,导致该元素可能无赋值内容或赋值内容出现偏差。规避和降低该风险点产生的风险概率的方法是:保存系统对该数字对象集合中每件数字对象,人工提取、补充和核实其内部结构信息,赋值到该风险型元数据元素中。
(2)数字对象外部结构信息、外部结构判定事件。这两个风险点均主要集中在{TDi,CDj,SDk}(i={6,7},j={1,2,3},k={1,5,6}),即 2011年之后基础学科、哲学与人文学科和社会科学的期刊、硕博论文和会议论文。可能的原因是,保存系统收录该集合数字对象时,没有执行外部结构判定事件,导致中心数字对象与节点数字对象之间的结构描述缺失或出现偏差。规避和降低这两个风险点产生的风险概率的方法是:保存系统对该集合中每件数字对象,识别与之关联的保存系统中其他数字对象,并进行关联类型界定,赋值到上述相关风险型元数据元素中。
(3)整体式语义信息、知识点式语义信息、语义信息识别事件。主要集中在{TDi,CDj,SDk}(i={6,7},j={1,2,3},k={5,6}),即 2011年之后哲学与人文学科和社会科学的期刊、硕博论文和会议论文。可能的原因是,保存系统收录该集合数字对象时,没有执行语义信息识别事件,导致用于理解数字对象和知识点的相关附加材料缺失。规避和降低这三个风险点产生的风险概率的方法是:保存系统针对该集合中每件数字对象,识别和补充相关辅助资料,赋值到上述相关风险型元数据元素中。
4 结语
本研究在界定可理解性涵义的基础上,设计可理解性风险元数据,并基于元数据构建可理解性风险的检测方法。因此,可理解性风险型元数据的科学性决定了数字保存可理解性风险检测方法的可靠程度。所以,完善该类风险型元数据是后续研究的一项内容。
