社会标注系统自适应网页聚类算法研究
2018-07-23郭红建陈一飞
郭红建,陈一飞
(1.南京审计大学 管理科学与工程学院,江苏 南京 211815;2. 南京审计大学 工学院,江苏 南京 211815)
Web1.0到Web2.0的革新,使得互联网的应用更加广泛。用户越来越多地参与互联网信息建设,从被动的信息浏览者成为主动的参与者,用户标注信息、评论、标签等越来越流行。作为 Web2. 0 环境下用户生成内容的典型应用,标注系统允许用户以自由的形式对Web 资源进行标注形成标签,如www.delicious.comwww.flickr.com,www.youtube.com。通过标注人们可以对大量信息进行组织分类,并可以与其他用户共享这些标签。
聚类算法是文本数据挖掘的一个重要方法,它的应用非常广泛。其中网页聚类和文本聚类算法的研究成果已经非常多,总结起来,主要有3类:(1)基于文本内容的文本聚类算法。该方法将文本表示为文本模型, 如VSM(Vector Space Model)模型[2]、N-gram模型、基于短语的模型、基于概念的模型、文本的图表示及概率模型[3]。文本特征抽取与权重计算的方法主要有Salton 等[1]提出的TF×IDF函数[2]、互信息(Mutual Information)、布尔函数、频度函数、期望交叉熵(Expected Cross Entropy)、二次信息熵(QEMI)、信息增益(Information Gain) 等。然后采用标准聚类算法(例如k-means算法[3]等)对文本向量进行聚类。优化方法只是基于内容中的特征选项改进或者聚类算法的调优, 提高聚类质量;(2)基于用户标签的聚类算法。该聚类算法采用标签取代了文本特征词语,也考虑了用户和链接之间的关系等, 然后对网页进行聚类分析。但这种算法经常只考虑了用户标签和其链接关系, 忽略了用户标签和文本内容之间的信息。何文静等[4]以社会标签和特征词语抽取方法, 采用k-means 聚类算法对文本内容进行聚类,提高了文本聚类的效果。杨鲲等[5]分析了社会标注系统中用户、标签和被标注资源间的关系, 由此提出了基于用户标签的Web 资源语义描述获取算法。Li 等[6]针对互联网上网页标签过少的问题, 提出了一个与用户相关的标签扩展的方法, 添加标签到原文件, 设计了Folk-LDA 模型有效地阻止主题漂移并取得了较好的聚类效果。Lu 等[7]用Tripartite Clustering聚类算法对标注网页中3种类型的节点(网页、用户和标签)进行聚类, 实验结果表明Tripartite Clustering 显著优于基于内容的k-means 方法;(3)基于内容和标签的网页聚类方法。该聚类算法选取标签和特征词语的并集对网页进行聚类,只是将标签作为文本内容的补充而已。贺秋芳等[8]提出一种挖掘用户标签的增强型社区网页聚类算法, 用多种距离度量挖掘网页链接关系, 结合网页的内容信息相似度和链接关系进行聚类。Ramage等[9]采用生成的大规模标签的社会书签网站作为网页文字和锚文字的补充数据信息来提高网页聚类质量。李鹏等[10]提出基于标签的网页关键词抽取方法,通过目标网页中的每个标签引入相关文档计算词项图的边权重, 进而计算得到词项的重要度, 最后综合考虑不同Tag 下的词项权重计算结果。顾晓雪等人[11]探索社会标签与文本内容的结合对文本聚类的影响。使用TF×IDF、TextRank、TextRank×IDF共3种特征抽取方法, 线性函数和Sigmod函数进行相似度加权, AP算法进行聚类。卢露等人[12]针对Web用户聚类时社会标注系统中用户访问资源数据稀疏从而导致传统聚类算法效率不高的问题,提出了一种3向迭代聚类算法,对用户、标签和资源分别聚类,利用三者之间的关联关系不断相互交叉迭代调整,直到各聚类簇达到稳定为止。
1 社会标注系统自适应网页聚类算法
社会标注系统网页之间的链接类型有多种。如图1所示,u,r和t分别代表用户,网页和标签。每当用户对网页注明标签时,也就建立了一个标签,网页和用户的三元关系。

图1 用户,网页和标签的关系图
假设D={di,i=1,2,…,n}是网页文档集, 能够用一个无向图G来表示。训练数据构成节点vi(i=1,…,Ntr)的邻接表,用Vtr表示训练数据节点集,Ntr表示训练数据节点集的基数,用Vvalid和Vtest分别表示验证集和测试集,基数分别为Vvalid和Ntest。
使得e=Φω+bNtr,=1,…,k-1。其中,是在特征空间的投影是核矩阵Ω的逆,Φ是Ntr×dh特征矩阵,γ∈+是常量。
Ωi,j=K(xi,xj)=φ(xi)Tφ(xj)可以通过xi和xj之间的余弦相似度计算而获得。聚类模型可以通过下面的公式表示:
其中,φ:N→dh是到高维特征空间dh的映射。
如何利用验证集的节点来评估聚类的数目,在文献[13]提出了一个称为平衡度适应BAF的评估标准。该标准的思想是属于相同类的节点在特征空间有近乎零或者非常小的角度距离。
本文所采用的自适应选择类别数目k的算法如下:
输入E=[e1,e2,…,eNvalid]。
输出类别数目k。

(2)设定td=[0.1,0.2,…,1];
(3)对于每一个t∈td:
将A临时保存为B,即:B=A;
将SizeCt初始化为空向量;
如果B是非空矩阵,采用公式CosDist(ei,ej)≤t定位验证节点ei使得节点数达到最大值,将这些节点加入到向量SizeCt中,并将这些节点的行和列信息从矩阵B中移除;

(4)根据F-measure值达到最大值来设定阈值maxt;
(5)根据向量SizeCmaxt的元素个数来设定类别数k。
本文所采用的自适应网页聚类算法如下:
输入用户,网页和标签的关系图G=(V,E)。
输出关系图G聚成K个类。
步骤
(1)转换和存储关系图G为矩阵形式;
(2)采用FURS算法[13-14]选择训练节点集Xtr;
(3)采用FURS算法移除子图S后选择有效地节点集;
(4)对∀i,j,vi,vj∈Xtr进行余弦相似度计算得到核矩阵Ω;
(5)对核矩阵Ω进行特征分解得到α,b;
(7)通过自适应选择类别数目k的算法计算出k,再根据余弦相似度计算将测试样本划分到合适的类中,直到满足结束条件。
2 实验结果与分析
2.1 实验结果评测方法
本文采用准确率、召回率、F-Measure值、Purity和NMI这五个指标评测聚类的结果质量[8]。
假设聚类i和一个分类j,N为在文档集i中属于类别j的个数,M为聚类i中所有文档的个数,K为分类j中所有文档的数目,则召回率R可以定义为[8]
R=N/K
准确率P可以定义为
P=N/M
分类j的F-Measure可以定义为
本文也采用了Purity[15]和Normalized Mutual Information (NMI)[16]进行评测。Normalized Mutual Information (NMI)是根据即将要归类的变量和已经分类的变量之间的互信息值来计算的。计算NMI的公式如下
其中,变量X是将要归类的随机变量,变量Y是已经分类的随机变量,变量k是聚类的数目。
2.2 实验过程与结果
为了下载真实社会标注网页作为语料进行实验,本文下载了www.delicious.com网站2013年1月~2014年1月的683 529个网页。
为了使得实验结果具有对比性,选择k-means聚类算法进行对比实验,k-means聚类算法的一个关键问题是预先选定的类别数目k,而本文可以自适应选择类别数目k。利用随机选择的50 000个网页对类别数目k的取值进行k-means聚类算法结果对比实验,结果如表1所示。
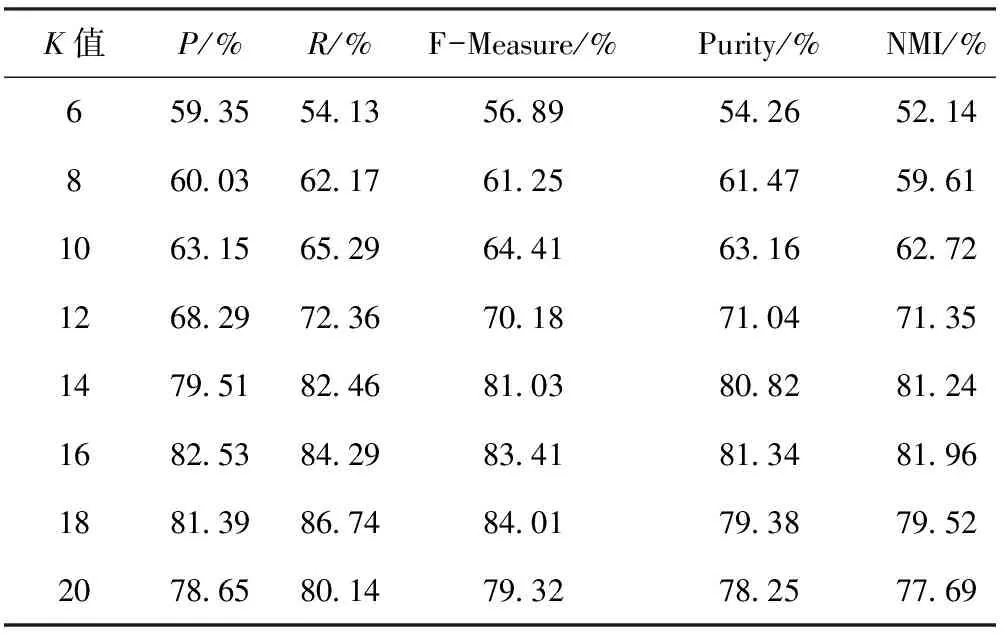
表1 类别数目k不同时k-means聚类算法结果对比
从表1可以看出,最初选定k的取值对聚类效果影响很大,如果k过大,相关的网页被迫分开,影响聚类质量;如果k过小,不相关的网页聚在一起。当k=16时,聚类效果较好。当然,如果网页语料不同,适当调整类别数目k的取值。
然后将这50 000个网页采用自适应网页聚类算法进行聚类,得到的结果如表2所示。

表2 自适应网页聚类算法进行聚类实验
从表1和表2可以看出,自适应网页聚类算法得出的k值为15并不是最好的结果,但是与k值为16得到的结果非常接近。如果网页语料产生变化,数目k的取值就需要随之调整,这会给k-means聚类算法造成障碍。本文尝试进行了另一个对比实验。随机选择15组网页语料,每组语料均含有50 000个网页,每组语料采用k-means聚类算法取最好记录,采用本文自适应网页聚类算法进行结果对比。

表3 15组网页语料进行聚类对比实验
从表3可以看出,15组网页语料中采用本文算法有12组得到的k值和k-means聚类算法最佳k值相同,第5、8、13的k值不同。除了第6组和第13组在 五个评测指标P、R、F-Measure、Purity、NMI上本文算法偏低外,其他13组的结果均优于k-means聚类算法,可见本文提出的自适应网页聚类算法效果较好。
3 结束语
本文提出了一种社会标注系统自适应网页聚类算法,可以自适应找出类别数目k并完成聚类。随机选择了15组网页语料进行聚类对比实验,实验结果表明,本文提出的自适应网页聚类算法效果较好。下一步研究将下载更多的真实社会标注网页进行聚类实验,比如新浪微博、腾讯微博等标注网页;另外,将研究如何改进聚类算法的聚类速度,减少聚类迭代的次数。
