双微阵列语音增强算法在说话人识别中的应用
2018-07-20毛维曾庆宁龙超
毛维,曾庆宁,龙超
双微阵列语音增强算法在说话人识别中的应用
毛维,曾庆宁,龙超
(桂林电子科技大学信息与通信学院,广西桂林 541004)
针对复杂噪声环境下识别性能显著降低的问题,提出一种用于说话人识别系统前端的双微阵列语音增强算法。该算法采用的是相干滤波和频域宽带最小方差无畸变响应波束形成器后置结合改进的维纳滤波器。其基本原理是首先求出双微麦克风阵列信号中两个相邻通道间的相干函数,再利用通道间信号的相干性来进行初始噪声抑制。其次,通过一个频域宽带最小方差无畸变响应(Minimum Variance Distortionless Response, MVDR)波束形成器保留目标声源方向的信号并抑制其他方向的信号干扰,再通过改进的维纳滤波器去除噪声残留提升语音质量。最后,使用梅尔频率倒谱系数(Mel Frequency Cepstral Coefficients, MFCC)和伽马通滤波器组频率倒谱系数(Gammatone Filter-bank Frequency Cepstral Coefficients, GFCC)对增强后的语音信号做特征参数提取并进行说话人识别。仿真过程采用声学人工头模拟双耳采集数据,实验结果表明,该语音增强算法在复杂噪声环境下能够获得较好的增强效果,能有效提升说话人识别系统的识别率。
双微阵列;语音增强;相干滤波;最小方差无畸变响应;改进维纳滤波;说话人识别
0 引言
说话人识别是利用说话人的语音特征来确定或鉴定说话人身份的技术。实际的说话人识别系统受到周围环境噪声的影响,系统识别率严重下降,语音增强[1]是解决这一问题的一种方式,其主要目的是从带噪语音中尽可能地恢复出原有的纯净语音。语音增强算法种类繁多,其中大多数算法是使用各种噪声消除方法结合语音信号的特征来进行研究,如基于短时谱估计的单通道语音增强算法有:谱减法[2],最小均方误差方法[3-4],维纳滤波方法[5]等。常见的多通道语音增强算法[6]有固定波束形成法、广义旁瓣抵消器等。在噪声抑制方面,固定波束形成法有着明显的缺陷,且处理后的语音信号中仍存在较多的噪声残留;而广义旁瓣抵消器则是在抑制混响和非相干噪声方面有一定的限制。近年来,说话人识别技术得到进一步的发展。在无噪声干扰的情况下,当前说话人识别系统可以获得较高的识别率。但是在电噪声、房间混响等复杂噪声情况下,说话人识别系统的识别效果较差,而且存在适用性差以及实用性不足等诸多缺点。而采用麦克风阵列,与单个阵元相比,可以利用麦克风阵列信号的时域、频域以及空域信息更好地处理说话人的语音并提升语音质量。本文针对此问题,利用声学人工头模拟头部双耳距离,采用一种双微麦克风阵列来获取说话人的语音,用相干滤波先将各通道间的含噪语音进行初步的信噪比提升,再通过最小方差无畸变响应(Minimum Variance Distortionless Response, MVDR)波束形成器对非目标声源方向的信号进行噪声抑制,最后通过一个改进的维纳后置滤波器去除残留噪声并对语音做增益补偿提升可懂度,以此来提升说话人识别系统的识别率。
1 语音增强
1.1 双微阵列
双微阵列是由2个子阵元个数为的麦克风阵列构成,其中单个子阵列阵元间距大约为1~2 cm,而两个子阵列之间的间距一般设置为15~18 cm,本文采用的子阵列之间间距为16 cm,其中双微阵列中单个子阵列中的阵元个数都为2,组成一个2×2的4元阵,双微阵列的简易结构如图1所示。
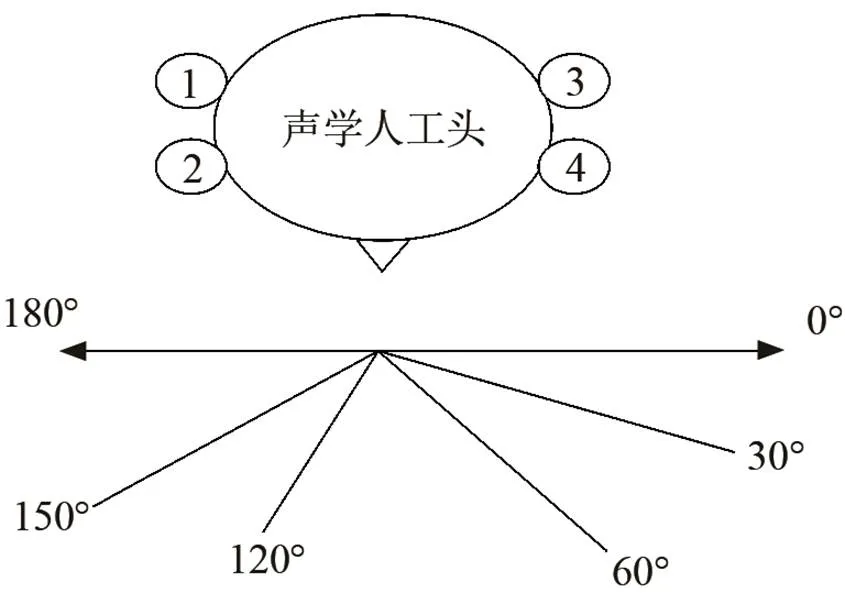
图1 双微阵列的简易结构
1.2 相干滤波器

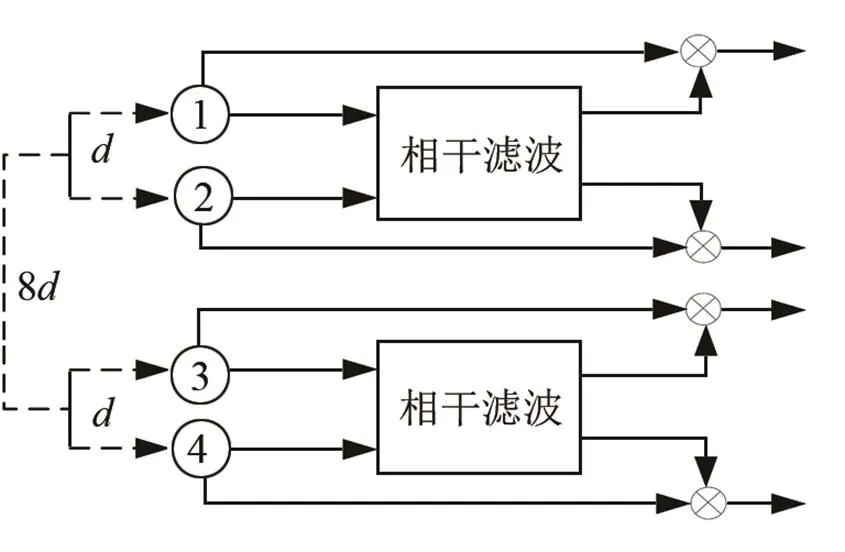
图2 相干滤波原理图
首先,对各个麦克风接收到的语音信号进行加窗分帧,接着对每个麦克风信号中的每帧信号进行傅里叶变换,然后求出求出各个麦克风中输入信号的互功率谱密度(Cross-power Spectral Density, CSD)[9]为

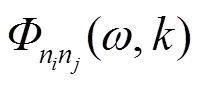
两个相邻麦克风接收到的信号的相干函数可用式(2)定义:

通过式(3)判决式来设置相干滤波阈值,得到相干滤波的增益函数:
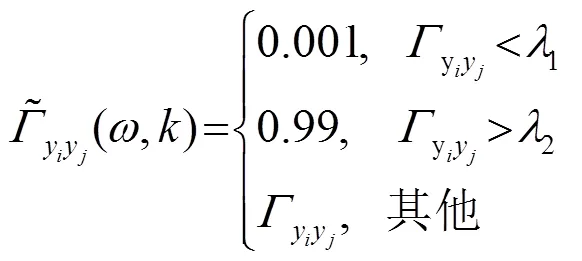
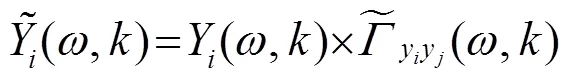
1.3 广义旁瓣抵消器
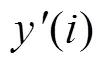

图3 广义旁瓣抵消器原理图

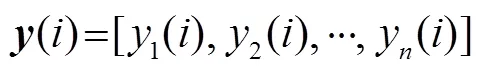
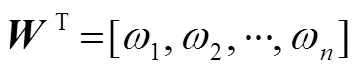

1.4 频域宽带最小方差无畸变响应
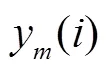

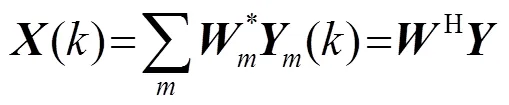
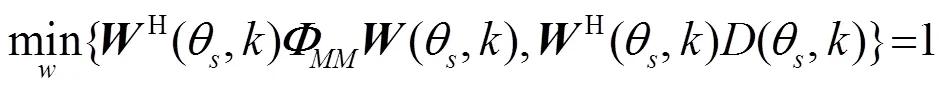
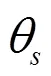
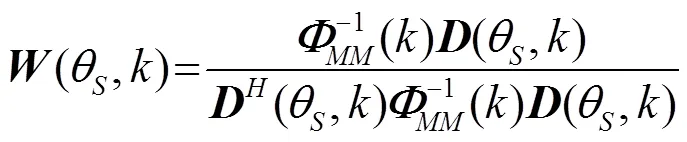
1.5 改进的维纳滤波
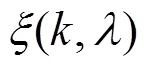

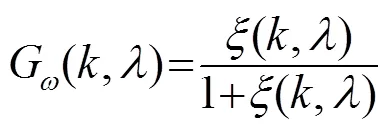
研究表明[16],对先验信噪比和后验信噪比的高估和低估会对语音的可懂度有一定的影响,在低于-10 dB区域,估计的先验信噪比往往会高于理想情况,此区域所产生的误差将会明显降低增强语音的可懂度;在大于6.02 dB区域,则存在低估的情况,因此,进一步的处理方法如下:
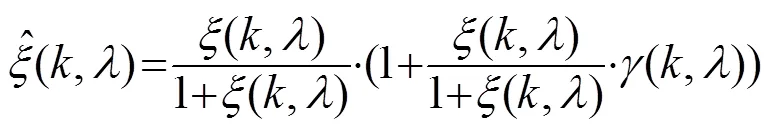
在小于-10 dB以下区域,引入偏差值修正频谱增益函数:
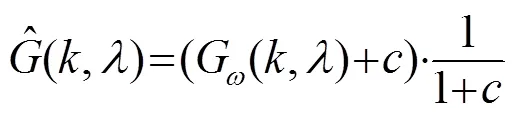
在大于6.02 dB区域,有:
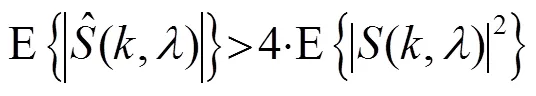
最终可推得:
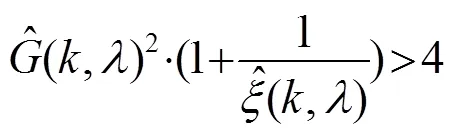
通过式(17)~(18)中先验信噪比和增益函数,可以判定幅度谱大于6.02 dB的放大畸变区域,对此区域的幅度谱进行一定的约束为
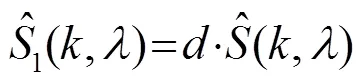
本文采用的是双微麦克风阵列系统,模拟头部双耳距离,其中通道1、2和通道3、4距离为,为2 cm,而由通道1、2构成的子阵列和通道3、4构成的子阵列之间的距离为8;因通道1、2和通道3、4相距较远,麦克风子阵列之间的时空域信息可以获得更多的有效信息,相干滤波后将输出信号通过MVDR波束形成器,用于抑制非目标声源方向上的干扰,并将输出信号通过改进可懂度的维纳滤波器,去除噪声残留提高语音质量。本文算法结构如图4所示。
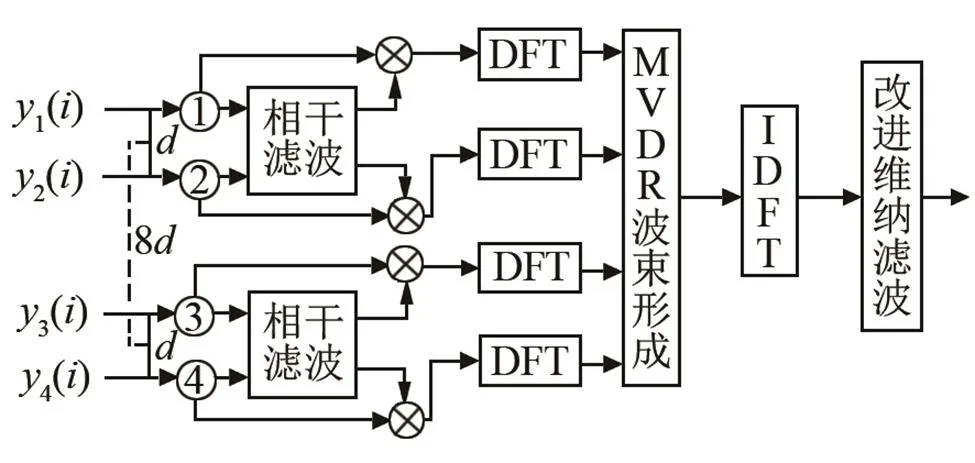
图4 本文算法结构图
为了验证该双微阵列对于说话人识别系统的可行性,给出了单个麦克风阵列、双麦克风阵列以及双微阵列在f16噪声和m109噪声情况下的主观语音质量评估(Perceptual Evaluation of Speech Quality, PESQ)得分,如表1和表2所示。
根据表1和表2的PESQ得分可知,双微阵列情况下的去噪效果是较好的,因此,将该双微阵列应用在说话人识别系统前端是可行的。
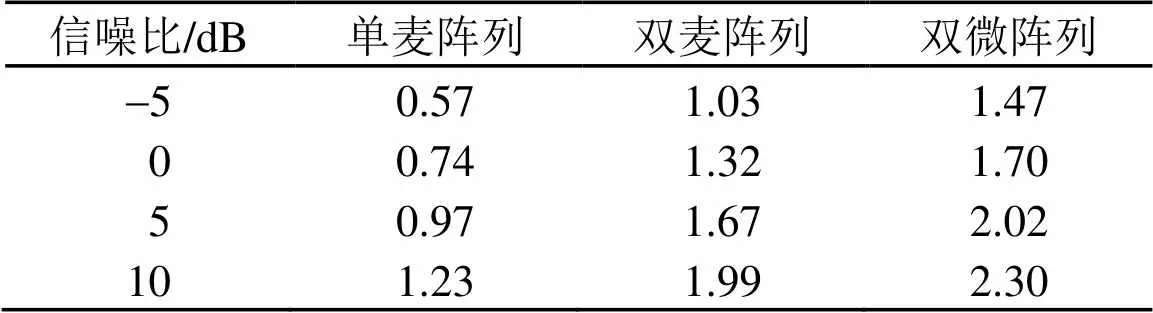
表1 f16噪声情况下,不同信噪比下的PESQ得分
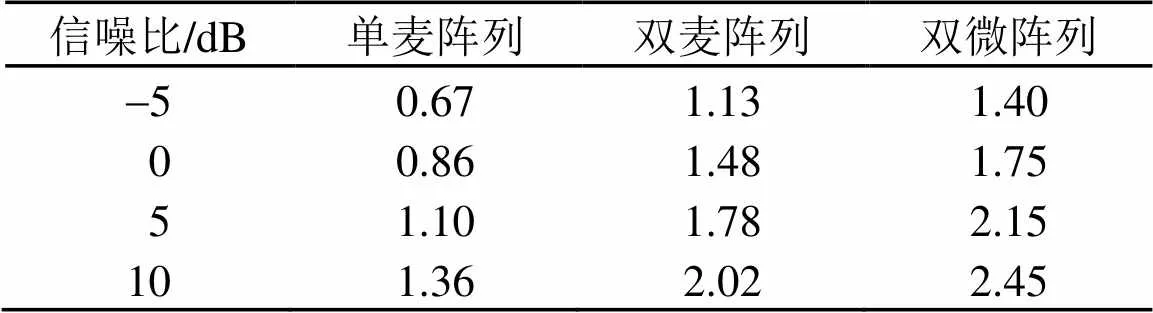
表2 m109噪声情况下,不同信噪比下的PESQ得分
2 说话人识别
本文使用的说话人识别系统是基于高斯混合模型[17-18](Gaussian mixture model, GMM)的文本无关的说话人辨认系统,系统分为两个阶段,一是训练阶段,二是测试阶段。在判定阶段,对测试语音的特征与训练模型中的各个特征进行对比,并计算对数似然度,得分最高的说话人模型为识别结果,简易流程图如图5所示。

图5 说话人识别系统简易流程图
2.1 梅尔频率倒谱系数(Mel Frequency Cepstral Coefficients, MFCC)
线性预测倒谱系数(Linear Prediction Cepstrum Coefficient, LPCC)是一种谱估计方法,语音信号在获取线性预测倒谱系数后在频域上是线性的,但这与人耳的实际听觉属性有所不符合,并且LPCC中的大量的噪声细节都出现在语音信号的高频区域,这些都会影响系统的性能。基于MFCC系数对于人耳更为敏感这一听觉属性,在说话人识别中得到了广泛的应用。MFCC系数的基本原理是将经过采样后的信号进行预加重处理,提升语音信号中的高频分量,然后对预加重处理后的语音信号进行加窗分帧,求每一帧信号的快速傅里叶变换,得到信号的能量,接着通过一个梅尔滤波器组并计算每个滤波器组输出信号的对数能量,最后进行离散余弦变换(Discrete Cosine Transform, DCT),最终得到MFCC系数[19]。
2.2 伽玛通滤波器组倒谱系数(Gammatone Filter-bank Frequency Cepstral Coefficients, GFCC)
伽马通(Gammatone)滤波器组[20]最初用在模拟听觉神经响应,是一种常见的耳蜗听觉滤波器[21]。本文采用的滤波器组的公式如下:

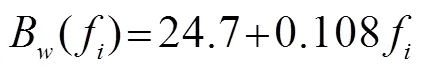
GFCC系数提取过程如图6所示,首先对语音信号进行预加重处理提升高频分量,然后对其进行加窗分帧,对每帧语音信号进行快速傅里叶变换,得到的幅度谱通过一个Gammatone滤波器组;最后对其进行离散余弦变换(Discrete Cosine Transform, DCT)。

图6 GFCC提取过程
3 仿真实验
本次实验数据录制环境为学校教学楼楼顶空旷的天台,采集设备为M-AUFIO多路音频采集器,双耳采用双微阵列来模拟,且单个微型阵列中的阵元间距为2 cm,两个微型阵列之间的距离为16 cm,说话人距离阵列的距离为1~1.5 m。语音和噪声采集都是在同样的录制环境下,除了说话人位置,在麦克风正前方的任意角度设置了若干噪声源。本次实验采集了20位同学的声音数据,其中男生15人,女生5人,每个说话人有10句语音,每段语音时间约3 s,从每个说话人语音中选出5句语音作为训练模型,同时对每个说话人使用5句语音来测试,总共测试100句,语种为汉语普通话。采集语音和噪声数据时均采用16 kHz的采样率,采样精度为16 bit,帧长为32 ms,帧移为16 ms,窗函数为Hamming窗。为了验证本文算法在说话人识别系统前端的可行性,对比了以下四种方法:广义旁瓣抵消(GSC)、相干滤波结合MVDR、MVDR结合改进维纳滤波以及本文使用的相干滤波结合MVDR波束形成后置改进维纳滤波。图7为0 dB白噪声情况下各算法增强后的时域仿真图,图8为0 dB白噪声情况下各算法增强后的时频图。
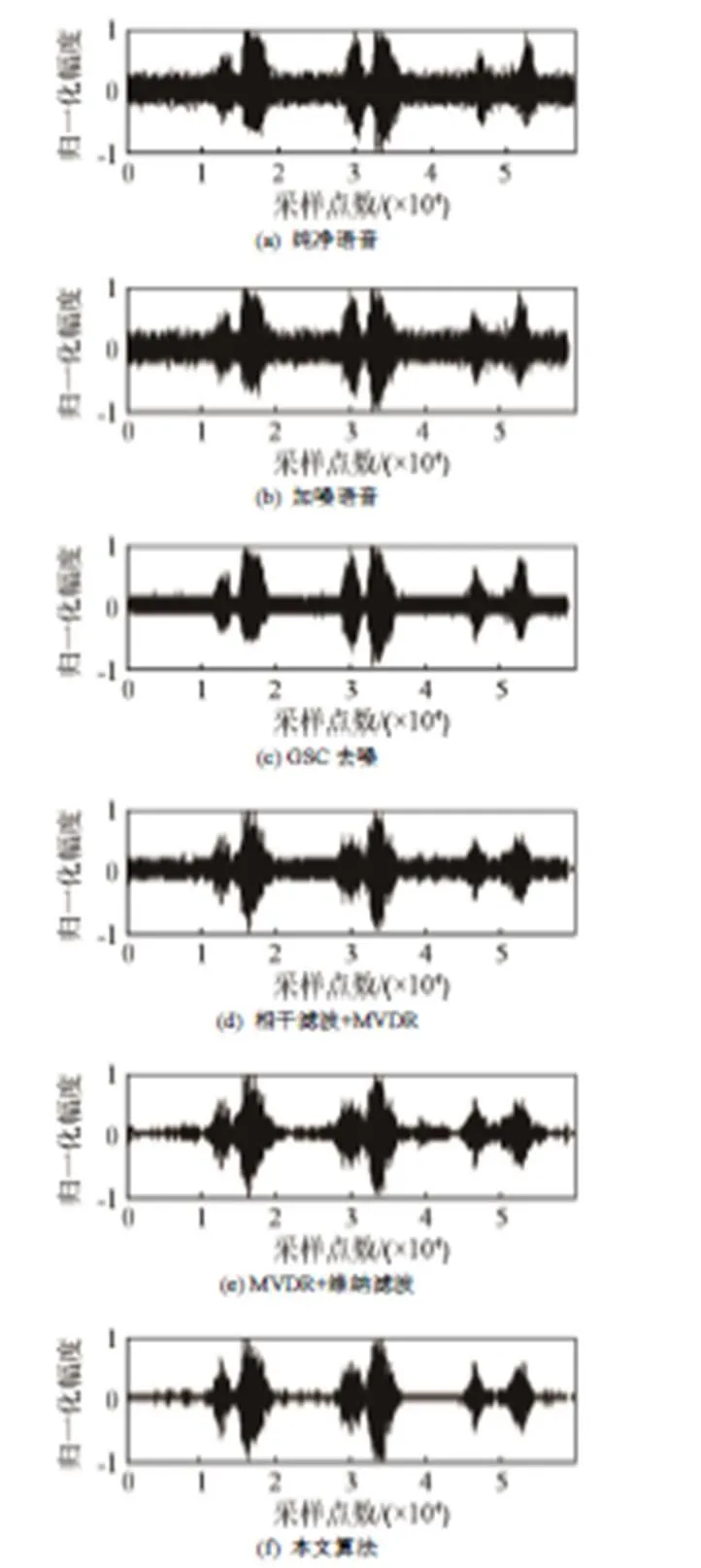
图7 白噪声环境下各算法增强后时域仿真图
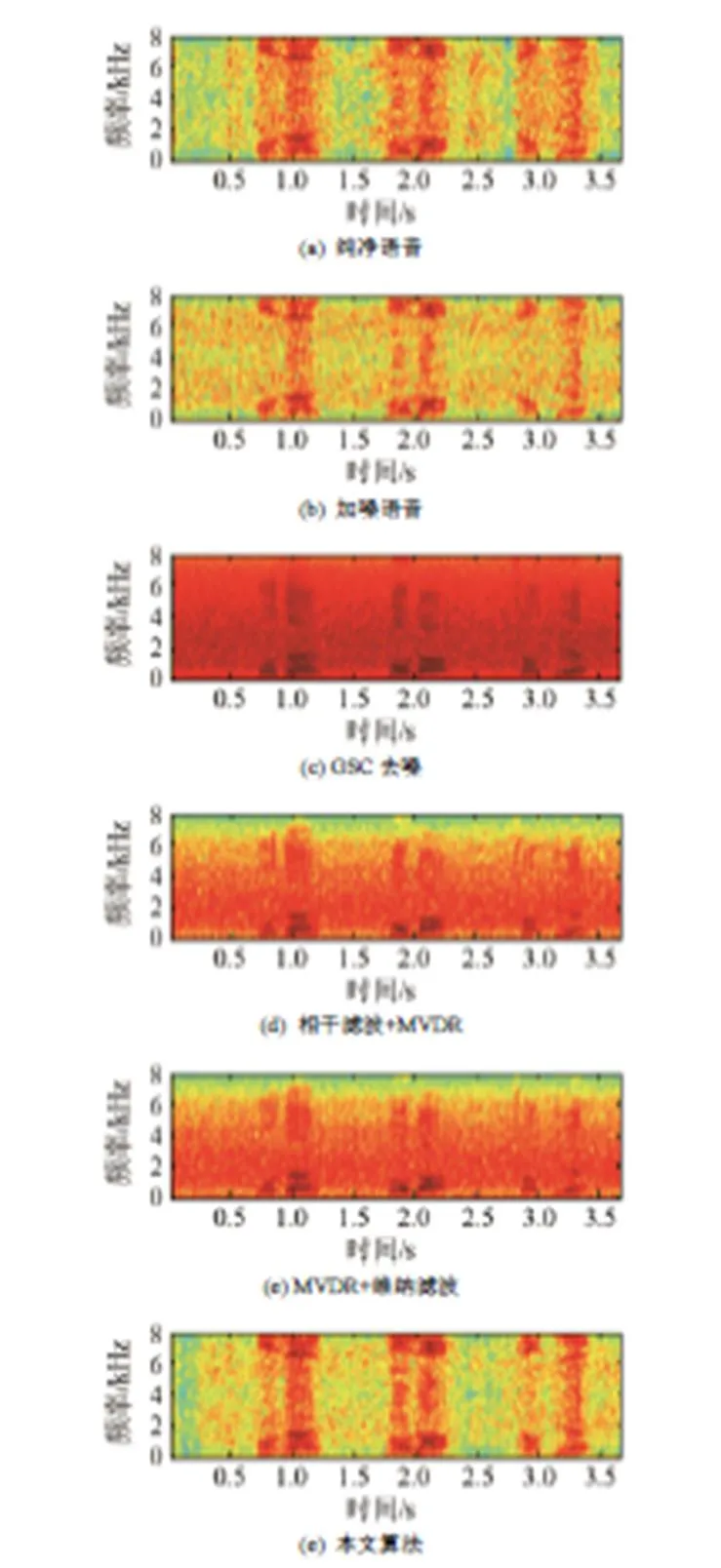
图8 白噪声情况下各算法增强后的时频图
从图7的时域仿真图中可见,广义旁瓣抵消器的去噪效果较差。相干滤波结合MVDR虽有一定的效果,但是噪声残留较大;而MVDR结合改进的维纳滤波增强后信噪比得到一定的提升,但仍然存在一定的毛刺和部分噪声残留。本文提出的相干滤波结合MVDR波束形成后置改进维纳滤波方法不仅在去除噪声残留方面得到了提升,同时还通过改进维纳滤波器降低了语音的失真度,改善了语音质量,在低信噪比环境下,这些影响是可以忽略的。因此本文提出的双微阵列语音增强算法适合用于说话人识别系统的前端处理。
3.1 实验1
在说话人识别系统中选取了LPC、MFCC、GFCC这三种特征参数对白噪声进行测试,仿真结果如表3所示。
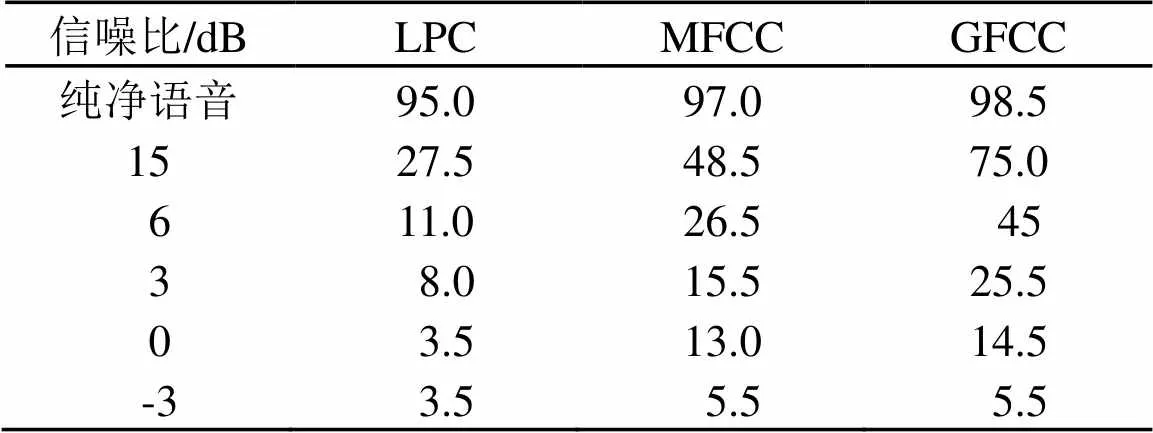
表3 三种特征参数在白噪声环境下识别率(%)
如表3所示,在无白噪声干扰的环境下,三种特征参数的识别率都达到了较高的水平,但总体上,GFCC的识别率明显高于其他两种特征参数提取的识别率。
3.2 实验2
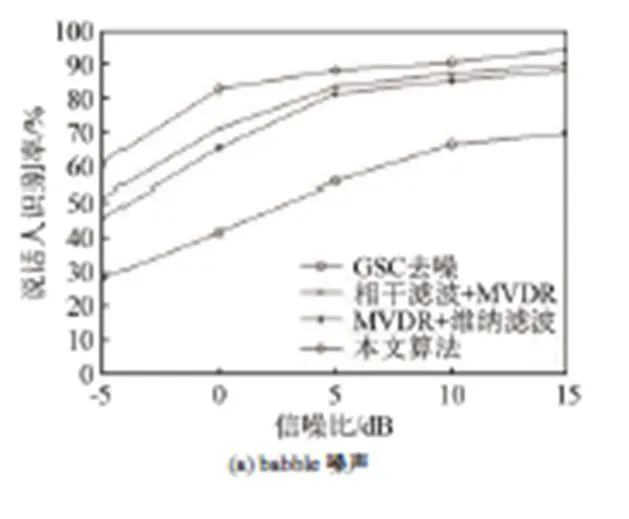
为了验证本文算法在不同噪声环境下的可行性,分别在babble噪声、volvo噪声、白噪声、f16噪声的环境下进行测试,计算四种增强算法在说话人识别系统中的识别率。结合实验1的仿真结果,选取26维GFCC作为说话人识别特征,四种噪声的说话人识别率如图9所示。
从图9中可以看到,广义旁瓣抵消器由于去噪效果的限制,表现出较低的识别率;而MVDR结合改进维纳滤波算法由于信噪比的提升比GSC去噪算法的识别率更高,但是其去噪效果仍然存在残留噪声和部分毛刺。本文提出的双微阵列语音增强算法通过对相邻通道间的信号进行初步的相干滤波增强,而后通过一个MVDR波束形成后置改进维纳滤波器,使其增强效果更明显,同时减少残留噪声。在后置改进维纳滤波部分,对有产生失真的语音段进行了增益补偿,进一步提高了说话人识别系统的识别率。因此,证明了本文算法的可行性。
4 结束语
针对复杂噪声环境识别性能显著下降的问题,提出双微阵列语音增强算法,该算法先在基于两个相邻麦克风通道基础上,进行相干滤波增强,再通过一个MVDR结合改进的维纳滤波器,抑制非目标声源方向的干扰信号,同时去除噪声残留,最后得到增强后的信号。采用声学人工头模拟头部双耳距离采集数据,实验结果表明通过该算法对说话人识别系统前端进行初步增强后的说话人识别率提升明显,可应用到人工智能机器人的信号采集和说话人识别身份确认系统中。
[1] LOIZOU P C. Speech enhancement: Theory and Practice[M]. America: The Chemical Rubber Company Press, 2013: 75-109.
[2] STEVEN F B. A Spectral Substraction Algorithm for Suppression of Acoustic Noise in Speech[J]. IEEE International Conference on Acoustics Speech & Signal Processing, 1979, 27(2): 200-203.
[3] EPHRAIM Y, MALAH D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator [J]. IEEE Transactions on Acoustics Speech and Signal Processing, 1984, 32(6): 1109-1121
[4] 张鑫琪, 冯海泓, 徐海东. 改进的最小均方误差语音增强算法的研究[J]. 声学技术, 2008, 27(2): 230-234.
ZHANG Xinqi, FENG Haihong, XU Haidong. A study of an improved minimum mean-square error speech enhancement algorithm[J]. Technical Acoustics, 2008, 27(2):230-234.
[5] 李宁, 蒋建中, 郭军利. 一种听觉掩蔽效应和维纳滤波的语音增强算法[J]. 计算机工程与应用, 2011, 47(29): 161-163.
LI Ning, JIANG jianzhong, GUO Junli. Speech enhancement algorithm based on auditory masking effect and Wiener filter[J]. Computer Engineering and Applications, 2011, 47(29):161-163.
[6] ALLEN J B, BERKLEY D A, BLAUERT J. Multimicrophone Signal-Processing technique to remove room reverberation from speech signals[J]. J. Acoust. Soc. Am., 1977, 62(4): 912-915.
[7] YOUSEFIAN N, LOIZOU P C. A dual-microphone speech enhancement algorithm based on the coherence function[J]. IEEE Transactions on Audio Speech & Language Processing, 2011, 20(2): 599-609.
[8] GHOSH P K, TSIARTAS A, NARAYANAN S. Robust voice activity detection using long-term signal variability[J]. IEEE Transactions on Audio Speech & Language Processing, 2011, 19(3): 600-613.
[9] 马金龙, 曾庆宁, 胡丹, 等. 基于麦克风小阵的多噪声环境语音增强算法[J]. 计算机应用, 2015, 35(8): 2341-2344.
MA Jinlong, ZENG Qingning, HU Dan, et al. Speech enhancement algorithm based on microphone array under multiple noise envrionments[J]. Journal of Computer Applications, 2015, 35(8): 2341-2344.
[10] 王群, 曾庆宁, 郑展恒. 低信噪比环境下的麦克风阵列语音识别算法研究[J]. 科学技术与工程, 2017, 17(31): 101-107.
WANG Qun, ZENG Qingning, ZHENG Zhanheng. Speech recognition based on microphone array in low SNR[J]. Science Technolpgy and Engineering, 2017, 17(31): 101-107.
[11] GRIFFIITHS L J, JIM C W. An alternative approach to linearly constrained adaptive beamforming[J]. IEEE Transactions on Antennas & Propagation, 1982, 30(1): 27-34.
[12] CAPON J, GREEENFIELD R J, KOLKER R J. Multidimensional maximum-likelihood processing of a large aperture seismic array[J]. Proceedings of the IEEE, 1967, 55(2): 192-211.
[13] 郑恩明, 黎远松, 陈新华, 等. 改进的最小方差无畸变响应波束形成方法[J]. 上海交通大学学报, 2016, 50(2): 188-193.
ZHENG Enming, LI Yuansong, CHEN Xinhua, et al. Improved bearing resolution approach for MVDR beam-forming[J]. Journal of Shanghai Jiaotong University, 2016, 50(2): 188-193.
[14] 马金龙, 曾庆宁, 龙超, 等. 多噪声环境下可懂度提升的助听器语音增强[J]. 计算机工程与设计, 2016, 37(8): 2160-2164.
MA Jinlong, ZENG Qingning, LONG Chao, et al. Intelligibility improved speech enhancement for hearing aids in complex noise envrionment[J]. Computer Engineering and Design, 2016, 37(8): 2160-2164.
[15] SCALART P, FILHO J V. Speech enhancement based on a prior signal to noise estimation[C]//IEEE International Conference on Acoustics, 1996, 629-632.
[16] 郭利华, 马建芬. 具有高可懂度的改进的维纳滤波的语音增强算法[J]. 计算机应用与软件, 2014, 31(11): 155-157.
GUO Lihua, MA Jianfen. An improved wiener filtering speech enhancement algorithm with high intelligibility[J]. Computer Applications and Software, 2014, 31(11): 155-157.
[17] 蒋晔, 唐振民. GMM文本无关的说话人识别系统研究[J]. 计算机工程与应用, 2010, 46(11): 179-182.
JIANG Ye, TANG Zhenmin. Research on GMM text-independent speaker recognition[J]. Computer Engineering and Applications, 2010, 46(11): 179-182.
[18] 程小伟, 王健, 曾庆宁, 等. 基于调制域谱减法的鲁棒性说话人识别[J]. 科学技术与工程, 2017, 17(3): 252-257.
CHENG Xiaowei, WANG Jian, ZENG Qingning, et al. Robust speaker recognition based on modulation domain spectral subtraction[J]. Science Technology and Engineering, 2017, 17(3): 252-257.
[19]余建潮, 张瑞林. 基于MFCC和LPCC的说话人识别[J]. 计算机工程与设计, 2009, 30(5): 1189-1191.
YU Jianchao, ZHANG Ruilin. Speaker recognition method using MFCC and LPCC features[J]. Computer Engineering and Design, 2009, 30(5): 1189-1191.
[20] 王玥, 钱志鸿, 王雪, 等.基于伽马通滤波器组的听觉特征提取算法研究[J].电子学报, 2010, 38(3): 525-528
WANG Yue, QIAN Zhihong, WANG Xue, et al. An auditory feature extraction algorithm based on gammatone filter-banks[J]. Acta Electronica Sinica, 2010, 38(3): 525-528.
[21] 林琳, 陈虹, 陈建. 基于鲁棒听觉特征的说话人识别[J]. 电子学报, 2013, 41(3): 619-624.
LIN Lin, CHEN Hong, CHEN Jian. Speaker recognition based on robust auditory feature[J]. Acta Electronica Sinica, 2013, 41(3): 619-624.
Application of dual-mini microphone array speech enhancement algorithm in speaker recognition
MAO Wei, ZENG Qing-ning, LONG Chao
(School of Information and Communication, Guilin University of Electronic Technology, Guilin 541004, Guangxi, China)
Aiming at the problem of lowering recognition performance in noisy speech environment, a dual-mini microphone array speech enhancement algorithm is proposed for the front-end processing of recognition system. The speech enhancement algorithm based on Coherent Filter and MVDR-wiener is presented. First, the dual-mini microphone array signals are collected to derive the coherence function between adjacent channels and to carry out the initial noise suppression by using the coherence between elements. Then, the information of target speech is processed by the broad-band MVDR algorithm to keep the signal in the desired sound source direction and suppress the interference signals in other directions. The improved Wiener filter which can get better voice quality by removing residual noise is utilized to process the enhanced signal. Finally, a speaker recognition system using Mel frequency cepstral coefficients (MFCC) and GFCC for feature extraction is used to recognize the enhanced speech. Binaural data are acquired with acoustic artificial head in simulations, the experimental results show that the speech enhancement algorithm can obtain better enhanced effect in noisy environment and effectively improve the recognition rate.
dual-mini array; speech enhancement; coherence filtering; minimum variance distortionless response; modified Wiener filter; speaker recognition
TN912.34
A
1000-3630(2018)-03-0253-08
10.16300/j.cnki.1000-3630.2018.03.011
2017-06-21;
2017-08-18
国家自然科学基金项目(61461011)、教育部重点实验室2016年主任基金项目资助(CRKL160107)、桂林电子科技大学研究生科研创新项目(2017YJCX16、2017YJCX20)
毛维(1992-), 男, 湖南岳阳人, 硕士研究生, 研究方向为语音增强、语音识别等。
龙超, E-mail:bishe006@163.com
