基于web挖掘的网站信息推送个性化服务研究
——以“网页动画设计”课程网站的信息推送为案例
2018-07-19肖宏飞
肖宏飞
随着互联网的迅速发展,Internet技术不断完善,网络已成为人们获取信息不可或缺的渠道.20世纪90年代中期以来,web挖掘理论得到广泛而深入的研究.如何将web挖掘的理论知识应用到个性化信息推送服务中去,在学界是一个备受关注的课题.截止至今,国内外在理论和实践方面的相关研究都有很大的发展,同时出现了很多基于web挖掘的个性化信息服务系统原型和实际的应用系统.
网络信息的迅猛快速发展使用户有可能享受丰富的网络资源,然而没有相应的服务模式来服务用户,让用户无法有效利用这些资源.个性化服务应运而生,是Internet发展和用户需求相结合的必然结果.所谓个性化服务,是指针对不同兴趣爱好的用户提供不同的服务模式和服务策略,它会根据用户的不同特点,为用户提供不同的服务,以满足用户多样化的需要.
本文结合“网页动画设计”课程网站,提出一种集合了web日志和web内容挖掘的混合挖掘策略,此策略的实施包括了几个部分:访问用户会话的识别,基于N-gram技术的web日志和web内容混合挖掘策略,构建用户访问模式描述文件,用户访问模式的分类和用户访问兴趣预测及推送.通过对web数据的收集与预处理,分析得出用户访问模式,同时对访问模式进行分类,然后对来访用户进行归类,找到相关模式描述文件,然后根据此类进行信息推送.
1 信息推送方法概述
随着网络和电子商务的快速发展,信息推送也越来越受到重视,逐渐成为数据挖掘领域研究的热点[1].目前,国内外信息推送的研究工作主要集中在对基于web内容的信息推送方法和基于web日志的信息推送方法的研究.
基于web页面信息的个性化推送方法是根据用户浏览web站点的信息资源,推送和此用户浏览信息相似或者相关的一种个性化推送方法.基于页面信息推送的基本原理是通过用户浏览资源描述文件,根据用户浏览习惯,推送与用户以往访问习惯比较相似的信息资源,见图1.比较典型的基于web内容的推送系统有igoogle、Adaptive Web Site等,可以实时地对web服务器提供的相关页面进行自动或者半自动的调整[2].
基于web日志的推送方法是根据对web日志文件进行分析,通过聚类算法得出用户访问模式,对在线的用户进行归类,给相似用户推送相似信息的一种方法.基于web日志推送方法的原理是通过对用户访问习惯进行数据分析和挖掘,找出其相似性资源信息进行推送,见图1.比较典型的基于web日志的推送系统有webwatcher、firefly、let’s browse等.
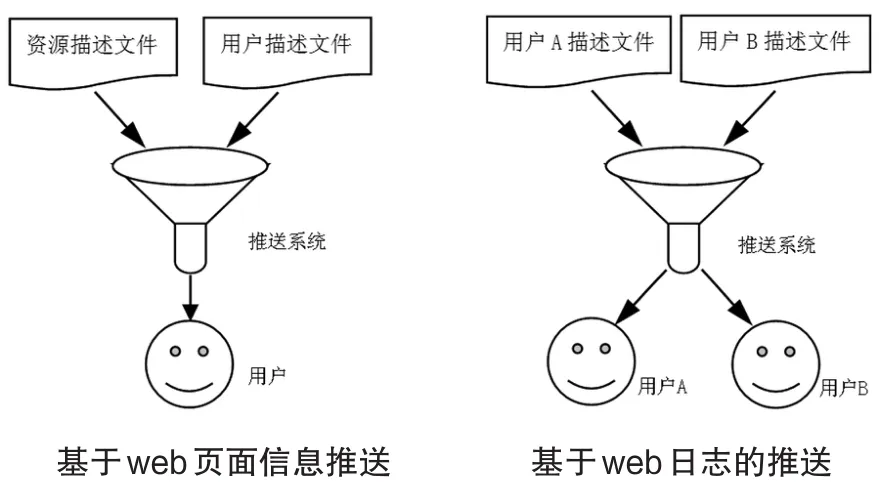
图1 基于web页面信息推送和基于web日志的推送的基本原理图
基于web内容的推送具有简单、快速的特点,缺点是由于无法对用户浏览的网页按用户进行分割和分组,因此进行信息推送所依据的模式和知识一般是以单张网页为单位进行组织的,具有局限性和孤立性,所推送的信息不会太准确.基于web日志的推送方法在推送信息时更加准确和具有针对性,但是由于在初期没有足够多的web日志信息可供挖掘,因此完善的用户访问模式库需要在系统运行过程中逐渐建立和完善,系统进入稳定状态所需要的时间较长.
可见,单一的推送方法有各自的优点,但是不足之处也很明显,所以结合多种推送方法的优点,取长补短构造混合推送方法近年来越来越受到重视,这也是该领域学者和研究人员目前最感兴趣的研究热点之一.
2 基于web日志和web内容的混合信息推送方法
基于单一的挖掘策略的信息推送方法具有一定的局限性,本文提出了基于web日志挖掘和web内容挖掘的混合挖掘策略构建个性化信息推送系统.基于内容挖掘和web日志挖掘的混合策略原理图如图2所示.
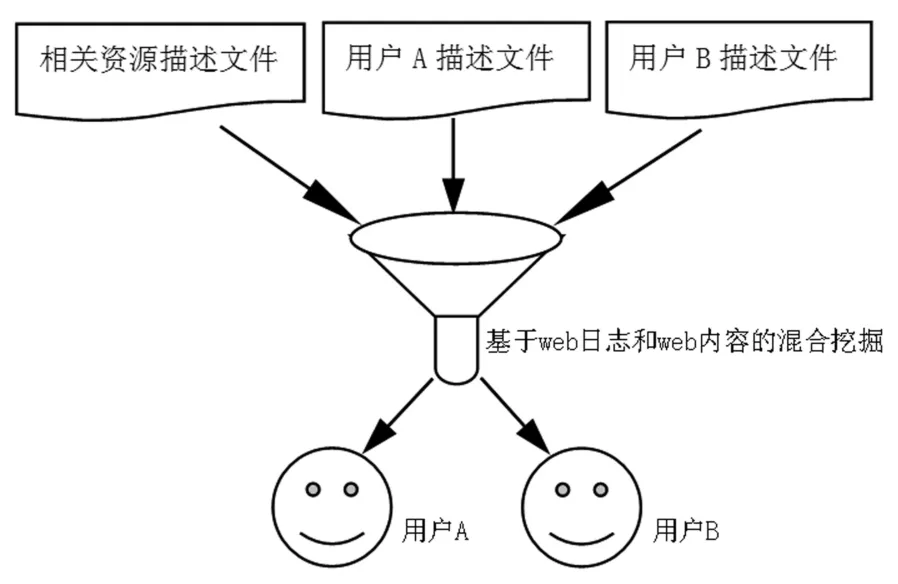
图2 基于web日志挖掘和web内容挖掘的混合方法的基本原理
基于内容挖掘和web日志挖掘的混合挖掘信息推送方法的基本原理是:在离线阶段,首先对用户的访问会话进行识别,从web日志文件中提取用户的访问会话信息;使用K-Medoids聚类算法,依据访问会话记录集来对用户进行分组,识别不同的用户访问类别[3];将用户访问类别和所访问网页的主题内容通过N-gram技术结合起来,建立融合了web日志和web内容的挖掘结果的用户访问模式,形成用户访问模式描述文件.在线信息推送阶段,依据用户的当前网页浏览序列,判断其用户访问模式,辨别其所属的用户类别,以预测用户的浏览兴趣和可能的访问内容,并据此进行信息推送服务.图3为信息推送系统流程图.
信息推送系统的设计包括两种关键技术:离线web数据挖掘技术和在线信息推送技术.下文分别介绍这两种关键技术的具体步骤.
离线数据挖掘技术步骤如下:
(1)利用向量P来表示用户浏览的页面集合,通过对web站点信息页面集合P进行数据清洗,清除多余无用的html标签、空格空行等,提取出网页文本信息.
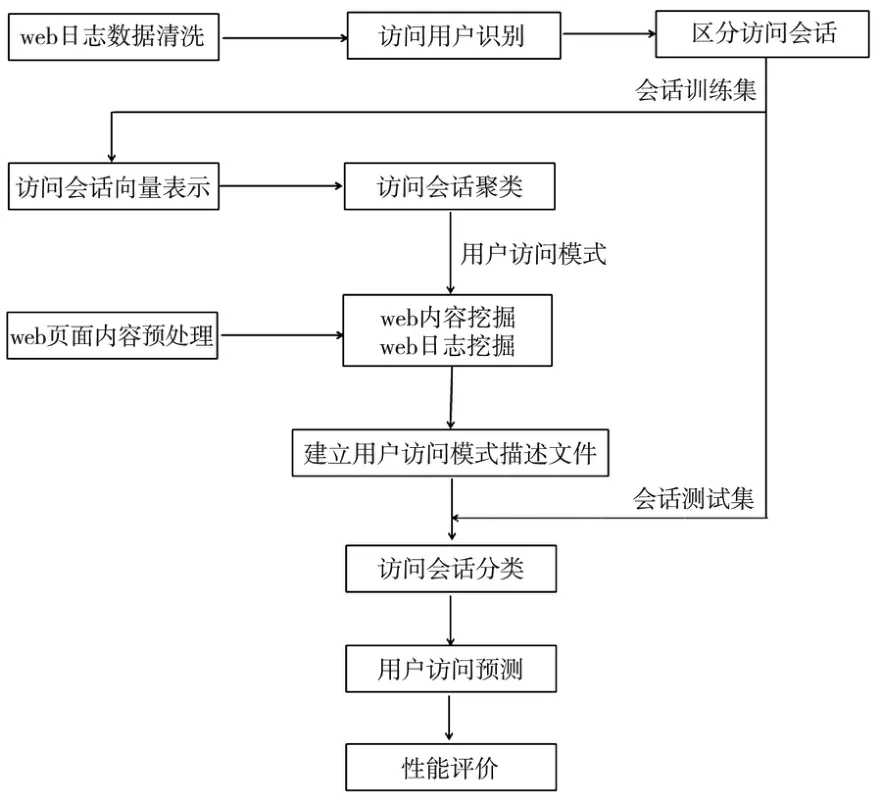
图3 信息推送系统流程图
(2)通过使用主动策略对网站注册用户进行识别,使用被动策略对网站匿名用户进行识别,实现对访问用户身份识别.
(3)设定用户访问会话持续访问时间为30分钟,如果超过,则认为是新的会话开始.
(4)利用K-Medoids聚类算法对用户会话进行聚类分析,将具有相同兴趣爱好的用户分到同一组.
(5)通过建立N-gram信息项对用户访问模式进行分类描述,建立用户访问模式描述文件.
在离线数据挖掘技术中,最后得出的用户访问模式分类描述是非常重要的,也是信息推送的基础和依据[4].访问模式中包括用户会话的访问网址序列信息,网页文本关键字信息、用户信息、会话分类信息和与此类会话相关联的信息.
在线信息推送技术步骤如下:
(1)设置测试会话集s,将当前用户的会话和已有的会话集合进行对比,找出当前用户访问会话的类别.
(2)结合离线数据挖掘出来的用户访问模式描述文件,对当前用户进行信息推送.
混合挖掘方法的基本模块关系如图4所示.
通过对web日志文件和web站点文件信息的数据预处理,实现对用户的访问会话进行识别和分类,利用N-gram技术的关键词频率和文档频率建立一个N-gram三元组向量来表示用户访问模式[5].在用户访问会话中既包括了来访用户信息,也包括了网站页面信息,因此重点通过对访问会话的聚类来分析得出用户访问模式.
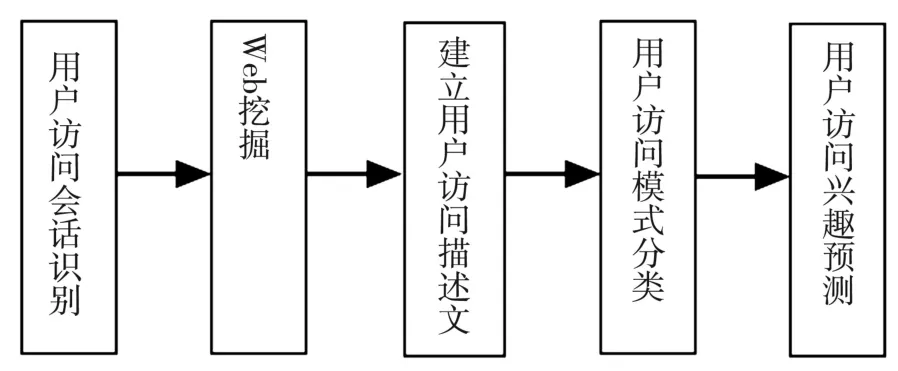
图4 web日志和web内容挖掘主要模块
3 基于向量模型的网站信息内容预处理
Web网站上面的信息基本上是非结构或者半结构化的动态信息,很难直接利用,因此需要对web网页文件进行数据预处理,然后对清洗后的web网页文件上面的数据信息再进行web挖掘.
Web网页内容的挖掘是从网页自身资源抽取信息项来表示网页主题信息,本文是通过提取网页关键字来对网页主题内容进行表述.用向量P={p1,p2,p3,…,pn}来表示用户浏览所有网页的集合[6].每个网页文件包括了一定的网页代码和图片或者相关视频等信息,不同于单纯的文本文件,因此在对网页内容进行数据挖掘前,首先需要对网页信息集合P进行数据清洗,过滤与网页主题不相关的文字内容等.
本文提取<title></title>、头文件keywords标签中的信息和网页中的文本信息.对于提取的网页文本信息,清除多余无用的html标签、空行等信息,用集合PC={pc1,pc2,pc3,…,pcn}来表示数据预处理后的网页集合.
4 基于主动策略和被动策略的用户识别
在进行web挖掘前,首先要进行的就是确定一个机制来对不同用户的身份进行识别,进而分析此用户的访问行为.本文采用主动策略和被动策略的方法对用户进行识别.
所谓的主动策略就是指在用户进行浏览访问的时候,让用户进行登记注册,然后通过登录ID,来唯一识别一个用户.在本文研究的课程网站中,采用了会员制,即在课程网站中,每个学员都有自己注册的账号和密码,据此可以快速准确地区分不同的用户.在后台数据库中为用户建立了一个user表,每个ID和用户名唯一定义一个用户,这样就可以通过数据库表中的ID和用户名对应每一个用户.快速准确地识别出注册用户.
被动策略是指通过对访问者的web日志信息来进行用户识别.本文采用以浏览者的IP地址、客户端的相关信息来区分不同的用户.如果IP地址、操作系统、浏览软件等客户端信息全部相同时,则认为是同一用户.
5 利用用户访问模式对用户访问会话进行分类
通过给定的用户访问模式描述文件和每个用户会话,如何来确定用户会话属于哪一个访问模式类型,这是具体信息推送的关键点.N-gram信息项比较普遍的是二元和三元的,本文以二元为研究对象,为N-gram建立一个二元组向量{(x1,tfx1),(x2,tfx2),(x3,tfx3)......(xn,tfxn)},其中 xi是指通过用户访问会话所访问的web页面上的N-gram信息项,tfxi是信息项的频率.当前已经获得的用户访问模式,对照N-gram的访问模式描述文件集中的每个 pfi,计算它与访问会话描述文件 p的DV(p,pfi).如果会话和系统中某个已有访问模式比较地相似或者接近,那么它们应当具有类似的N-gram数据分布,则DV(p,pfi)也就是在所有的相异值中差距最小的一个值,可以确认会话访问模式描述文件为p的会话是属于pfm类型的访问模式.
对于相异值DV(p,pfi)的计算,算法描述如下:
输入用户会话描述文件p和用户会话模式描述文件pfi.
在用户会话描述文件p和用户会话模式描述文件 pfi中,都有N-gram信息项 xi,tfp是 xi在用户会话描述文件 p上的信息项频率,tfpfi是xi在用户会话模式描述文件 pfi上的信息项频率,获取这两个频率的值.
按照公式1进行计算相异值dv(tfp,tfpfi) .
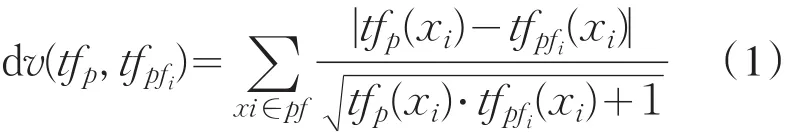
将所有的dv(tfp,tfpfi)进行求和运算,得到的就是相异值DV(p,pfi).
用户访问会话分类的步骤:假设访问会话s是一个含有n个被访问页面的测试会话集.基于N-gram为s建立一个用户访问描述文件 p,比较会话访问描述文件p和用户访问模式文件pfi的相异值DV(p,pfi),其中如果DV(p,pfm)值为最小,那么则认为s是属于用户会话描述文件pfm的用户访问模式类型.
6 基于测试会话集的信息推送
课程网站的个性化信息推送要求对在线用户实时推送其感兴趣或者可能需要访问的页面信息.对用户感兴趣的预测是建立在用户访问模式分类的基础之上的,信息推送要求对当前访问用户的会话进行分类,预测出来当前用户未来可能的访问会话模式,根据建立的会话模式,进行信息推送.
用户访问兴趣预测分为两个步骤:第一步是根据已有用户访问模式预测当前用户的访问会话模式,第二步是根据预测的结果对当前的用户进行信息推送.
假设s是一个包含n个被访问页面的测试会话集.会话s分为两个部分:第一部分用来做测试集,建立用户访问模式描述文件.第二部分用来模拟当前用户可能将要进行的访问请求结果的预测.首先为此会话建立一个基于N-gram信息项和信息项频率的用户访问描述文件p,通过用户访问模式描述文件p和用户访问模式描述文件 pfi的相异值DV(p,pfi)的比较,来决定此段会话将属于哪一种会话访问模式.根据会话访问模式对当前用户进行信息推送.
7 实验数据
本文对挖掘策略的性能评价主要看分类精确度A(C)和预测精确度A(F)值的分布.预测精确度是指模拟活跃会话的数量占总的测试会话数量的比例.分类精确度是指能正确反映用户会话分类中的测试会话占总的测试会话总量的比例.分类精确度和预测精确度越大则说明挖掘策略的效果越好.
基于web日志挖掘和web内容挖掘的分类精确度A(C)如图5所示.
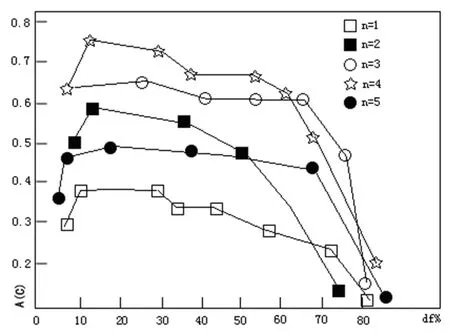
图5 分类精确度A(C)分布
从图5中,可以明显地看出N-gram的N值过大或者过小会话分类的效果都不理想.本文的实验中,N-gram的N的值是4,用户访问描述文件的大小在文档频率df=20%的时候达到最佳的分类精确度.
8 结论
本文在研究了web挖掘技术和个性化服务之后,分析了web日志挖掘和内容挖掘的方法,提出了基于web日志挖掘和web内容挖掘的混合挖掘方法,通过混合挖掘方法可以方便准确地获得用户访问的模式,利用用户访问模式进行模式分类和用户将来的访问请求的预测.通过实验数据,验证了本文所研究方法的效果,对个性化学习的信息推送效果要明显地高于单一的挖掘算法.本方法可以更好地应用于个性化信息推送服务,更高效率地提高用户的访问效率和自主学习的动力.
