一种基于分布式存储系统中多节点修复的节点选择算法
2018-07-19蒋梓逸
刘 佩 蒋梓逸 曹 袖
1(复旦大学计算机科学与技术学院 上海 201203) 2 (网络信息安全审计与监控教育部工程研究中心(复旦大学) 上海 200433) (13210240020@fudan.edu.cn)
随着云计算和“互联网+”应用的普及,分布式存储系统在各行各业中得到广泛的应用,用户访问不良特征和系统软硬件的错误导致节点的失效非常之多.Kondo等人[1]跟踪27个不同规模系统在一段时间内的节点失效状况,并给出了的真实失效数据集FTA(failure trace archive),如微软公司的桌面计算机系统数据集Microsoft99、P2P系统PlanetLab的数据集、高性能计算机PNNL等.本文通过用Mysql和Matlab对所得到的数据进行分析和统计得到云存储中节点的失效情况,经过归一化处理得到平均每个系统每周内的失效率为60.29%.从FTA中可以看出节点的失效率是非常高的,如何保证系统的可靠性是一项非常重要的课题.
为了提高分布式存储系统的可靠性,系统通常引入良好的数据冗余机制和数据修复策略.经典的冗余方式为副本机制[2],例如HDFS[2]系统和Ceph[3]系统.在大数据时代,因纠删码(erasure coding)比副本机制具有更低的存储成本,广泛应用于实际系统中[4-5].当系统发生节点失效时,保证持续的可靠性,系统需要将失效节点上的数据重新修复到新的节点上.修复时提供数据下载的存活节点称为供应节点,修复时存储再生数据的新节点称为新生节点.传统纠删码方式的失效数据修复需要先将源文件恢复出来,因此会引入不必要的修复带宽开销[6].在此基础之上,Dimakis等人[7]通过研究节点存储开销和修复带宽开销之间的关系,提出了再生码,其可以下载比纠删码更少的数据块把失效的数据再生出来.在拥有相似的存储效率的情况下,再生码可以很好地降低数据修复时的修复带宽(数据传输量)[8].


Fig. 1 The performance of data repair progress with different methods图1 数据修复过程中不同优化方法的性能
存储系统的修复过程中默认参与修复的节点已经给定,传统的算法包括具有随机性的BHS(blind helper selection)算法和SHS[10](static helper selection)算法.Gong等人[11]首次提出了单个节点失效场景下的最优节点选择机制SPSN(select provider select newcomer).其本质为贪心算法,对已有带宽进行排序之后,优先选择带宽较大的节点进行传输数据,从而降低了数据的修复时间.
理论研究和实际系统中,往往存在多个节点同时修复(也叫延迟修复)的情况.此时SPSN算法由于具有串行选择的特征而不再最优.随着系统中节点失效规模的扩大,这将给数据修复带来很大的时间开销和空间开销.基于这些问题,本文提出了多节点失效场景下的节点选择机制B-WSJ(bandwidth based weak and strong judgement),其对节点关系的运算进行建模,利用此模型并行地进行新生节点的强弱判断,在很大程度上优化了多节点失效时的数据修复时间.实验结果表明B-WSJ较SPSN算法有很大的性能提升.
1 相关工作
Ahmad等人[10]研究在什么条件下,再生码修复时对节点进行动态选择优于随机选择.本文提出了一个FR(family repair)模型,并分析得到在某些情况下,应用此节点选择机制的数据修复比随机选择能够获得更低的存储开销和修复带宽开销.Ahmad等人[12]继续针对本地修复再生码(locally repairable regenerating codes, LRRC)提出了动态供应节点选择机制(dynamic helper selection, DHS),并分析在特定的编码状况下,DHS节点选择机制比SHS算法和BHS算法具有更低的存储开销和带宽开销.
Gong等人[11]针对单节点失效场景提出了最优节点选择算法SPSN,其特征为优先选取带宽较大的节点作为供应节点和新生节点,本文分别探讨了在固定的修复带宽和弹性修复带宽场景下的节点选择机制.研究结果表明SPSN算法较随机选择算法有很大的性能提升.齐凤林等人[13]在此基础上,将节点的计算能力考虑进来,提出了不同拓扑模型上的供应节点的选择,结果表明节点的选择机制对修复性能具有较好的性能提升.Jia等人[14]考虑节点之间的实际物理链路,将同时选择供应节点和节点传输数据的路由路径建模成整数线性规划问题,并提出了近似最优解.
以上的研究针对单节点失效场景,然而理论研究和实际系统均表明多节点失效的延迟修复非常常见.在实际存储系统[15]中,由于软硬件错误或用户不良的访问需求等,节点的性能相差很大.Shen等人[16]利用Lyapunov方法,根据失效节点的等待时间和网络拓扑中的可用带宽,确定延迟修复何时开始.此研究成果表明,与逐个修复相比,延迟修复可以很好地降低系统的再生时间.在Wuala[17],Total Recall[18]等实际系统中,当节点失效的个数达到设定的阈值时,失效数据才开始再生;因此多节点失效的延迟修复是一种非常常见的现象.Hu等人[19]基于单节点失效时修复的性能,首次提出了多节点失效场景下的合作修复编码(mutually cooperative recovery, MCR).理论证明,与单节点失效时的MSR码和MBR码相比,MCR码消耗更小的存储成本和修复带宽.为了进一步降低修复带宽,Shum等人[20]基于合作修复编码,应用信息流图的最大流最小割定理得到关于修复带宽和节点存储量的权衡曲线,满足此曲线上的编码方式被称为线性合作再生码.曲线上2个极点分别为存储开销最低的编码(minimum-storage cooperative regenerating, MSCR)[21]和修复带宽最小的编码(minimum-bandwidth cooperative regenerating, MBCR).
已有的延迟修复过程中,SPSN算法的性能不再最优.随着系统中节点失效规模的扩大,这将给数据修复带来很大的时间开销和空间开销.
2 问题描述
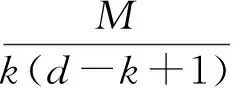

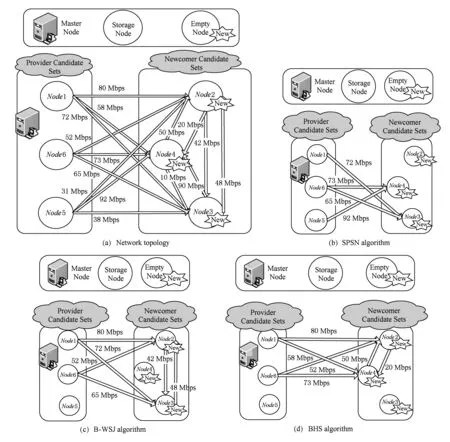
Fig. 2 Example of node selection algorithm图2 节点选择算法示例
从图2可知,节点选择机制对于数据的修复性能具有很大的影响,已有的节点选择算法在多节点修复场景下具有很大的局限性.首先,SPSN算法仅仅考虑供应节点和新生节点之间带宽的选择,而没有考虑到新生节点之间带宽的选择.这将使得新生节点之间的带宽在后续多节点修复过程中造成性能瓶颈;其次,SPSN算法串行选择节点,使得数据再生过程中产生很多冗余信息,增加了网络的负担;最后,SPSN算法由于其具有串行贪心选择的特征,随着系统中节点失效规模的扩大,这将给数据修复带来很大的时间开销和空间开销.
基于这些问题,本文提出了多节点失效场景下的节点选择机制B -WSJ,主要贡献有4个方面:1)算法对带宽中节点的关系进行分类,并在操作中将已有算法所忽略的节点关系存储起来;2)算法分为浅度和深度判断,逐层过滤,去掉冗余信息,浅度判断中加入了已有算法忽略新生节点信息;3)算法继续对弱判断结果进行强判断操作,找出两两相连的r个节点,随着失效节点规模增大,这将具有很大的挑战性;4)算法中加入了大量的预处理和剪枝思想,从而有效地降低算法的时空复杂度.实验结果表明,B-WSJ较SPSN算法有很大的性能提升.下面我们对算法进行详细的描述,并进行多维度的分析和验证.
3 系统模型
3.1 拓扑模型
分布式存储系统利用一定的通信技术,将文件分布到物理位置独立的服务器中[4],最终提供相应的接口给用户端上传、下载或更新.
定义1. 网络拓扑.实际系统中网络拓扑结构有星型、树形、网状等,基于已有的研究,不失一般性,本文将网络拓扑抽象成overlay结构,记为G(V,E).其中:
1)V=Vp∪Vf∪Vn.V为所有节点的集合;Vp为存活节点的集合;Vf表示失效节点的集合;Vn表示空闲的节点集合,此处的空闲是指相对于目标文件空闲.
2)E={C(u,v)|u∈Vp∪Vn,v∈V}.E表示网络中所有带宽.实际分布式存储系统中,块服务器间歇性的向主节点发送信息,数据中心的链路带宽可以由主节点获取[11,17].根据文献[22]可知带宽满足C(u,v)~U[0.3,120].
定义2. 链路上节点之间关系.网络中某节点w,我们对其邻居节点关系记录如下:
1) 其下游的邻居节点集合被记作T(w),集合中的元素个数记为count+T(w).即对于拓扑中任意节点v∈T(w),存在一条从节点w到节点v链路带宽;
2) 其上游的邻居节点如果属于集合Vn,即候选新生节点集合,我们将这些邻居节点的集合记为Hn(w),集合中的元素个数记为count+Hn(w).即对于拓扑中任意节点v∈Hn(w),存在一条从节点v到节点w链路带宽;
3) 其上游的邻居节点如果属于集合Vp,即候选供应节点集合,我们将这些邻居节点的集合记为Hp(w),集合中的元素个数记为count+Hp(w).即对于拓扑中任意节点v∈Hp(w),存在一条从节点v到节点w链路带宽;
4) 既为其上游邻居节点,也为下游邻居节点集合记为HT(w),集合中的元素个数记为count+HT(w).即对于拓扑中任意节点v∈HT(w),既存在一条从节点v到节点w链路带宽,也存在一条从节点w到节点v链路带宽.
证明.
① 当S=1时,假设这个节点为v1,很明显1个节点两两相连,结论是成立的;



证毕.
文件以(n,k,d)的编码方式存储到此拓扑网络中.存储模型可以描述为源文件从虚拟节点VS发出,系统首先将其均匀分成k块;然后经过某种编码方式将这k个数据块编成n块;最后将通过Hash或者其他分布算法将这些数据块放到n个存储节点上,每个节点上存储的数据量为α.我们设定源文件的存储具有MDS性质,即目标节点DS可以访问n个存储节点中任意k个节点上的数据,经过相应的解码操作将源文件还原出来.当节点失效时,每个新选择出的节点需要从d供应节点下载数据.
3.2 多节点失效场景下的修复模型
在分布式存储系统中节点失效的个数达到r(r≤n)时,我们才对其进行合作修复.时间被切割成不同的阶段,直到此时间段内所有的数据修复完才进入到下一个时间段[20-21].已有文献对分布式存储系统中带宽的预测方法表明未来带宽大小的变化与历史带宽大小是相关联的[23-24],在很短时间内带宽大小变化很小.因此,我们假设系统中主节点获得的带宽大小在此修复时间段内保持不变,而且修复过程中每个节点之间传输的数据量均为β.
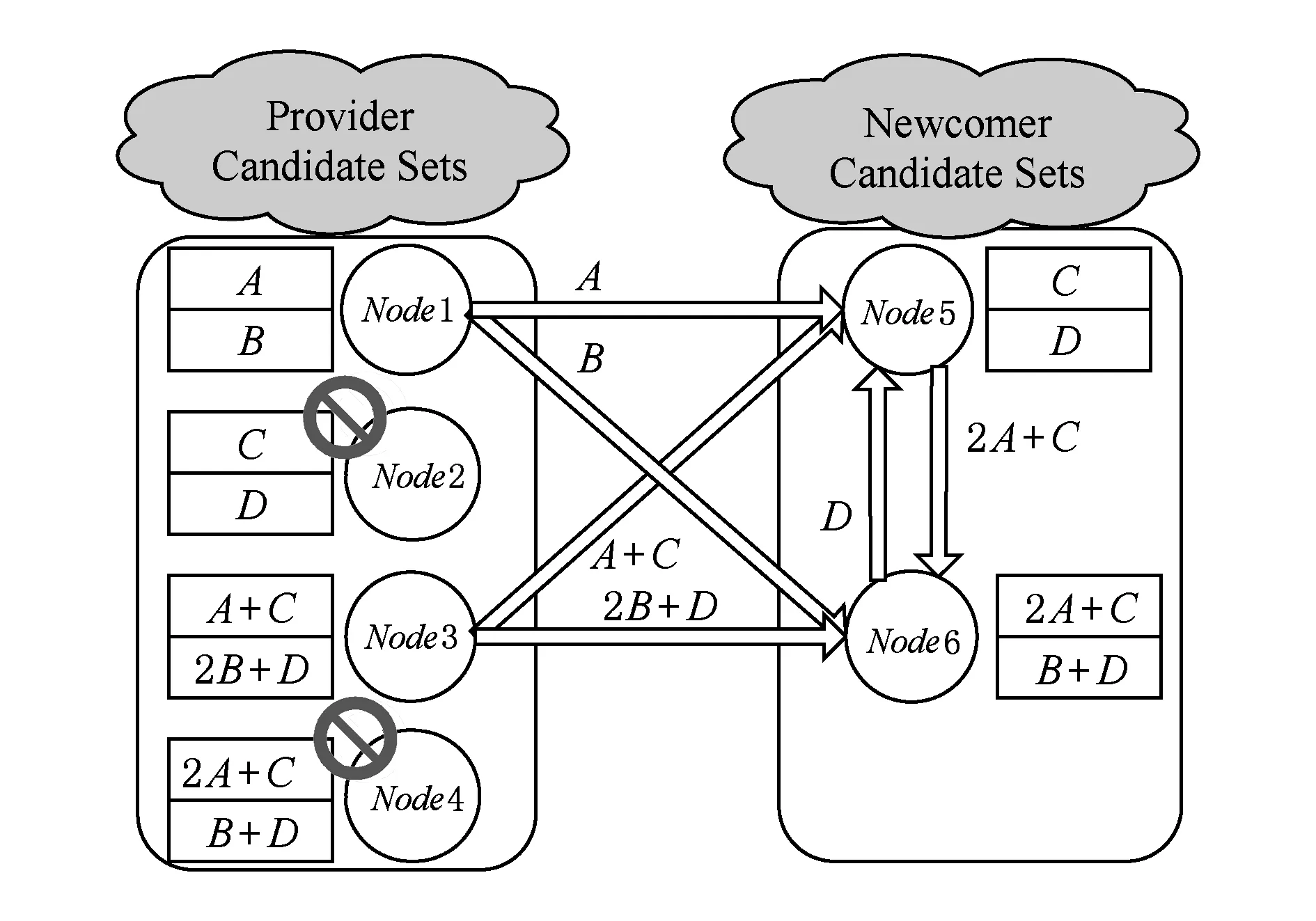
Fig. 3 Cooperative recovery of distributed storage systems from multiple losses图3 分布式存储系统中多节点失效时的合作修复
定义3. 多节点修复模型.首先,系统从空闲节点集Vn中找出|Vf|个节点作为新生节点(被称为newcomer),并且为每个newcomer从存活节点集合Vp中选出d个节点(n-r≥d≥k)作为供应节点(被称为provider).其次,每个newcomer从每个provider下载相应的数据量β并存储到newcomer上,这个操作记为ψα→ψβ;与此同时,每个newcomer需要从其他r-1个newcomer下载的数据,此过程可以记录为ψd β→ψβ;最后,每个newcomer通过计算所得到的数据量,恢复出失效的数据,记录为ψ(d+r-1)β→ψα.
下面通过图3来详细说明多节点修复模型(合作修复模型),源文件被均分为4个块A,B,C,D,这些原始文件块经过编码生成8个数据块,新数据块中每2块作为一个包按照某种布置策略分布到4个节点上.那么节点1将存储数据块A,B;节点2存储数据块C,D;节点3存储数据块A+C,2B+D;节点4存储数据块2A+C,B+D.此时文件存储采用的编码方式(n,k,d)为(4,2,2),鉴于文件存储具有MDS性质,即任取拓扑中2个节点上的数据可以将源文件恢复出来,因此,所用文件存储模型可以容忍2个节点失效.
在某个时间点,节点2和节点4上的数据失效了,即r=2,此时系统的数据修复开始.假设选定的新生节点为节点5和节点6,供应节点为节点1和节点3,每一个所选新节点需要从2个供应节点上下载数据.新生节点5需要从节点1下载数据块A,从节点3下载数据块A+C,计算出数据块C,并将中间计算结果2A+C传输给节点6;与此同时,从节点6下载数据块D,此时节点2上的失效数据被再生出来.新生节点6从节点1下载数据块B,从节点3下载数据块2B+D,计算出数据块D,并将中间结算结果D传输给节点5;与此同时,从节点6下载数据块2A+C,此时节点4上的失效数据被再生出来.通过此种新生节点之间互相交换信息的合作修复方式,可以很大程度上降低链路上传输的数据量.
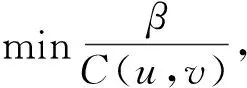
4 算法及分析
4.1 节点选择算法

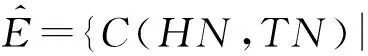

Fig. 4 Algorithm design idea 图4 算法设计思想

从图4还可以看出,对比已有的算法,B-WSJ算法有很多特征:
1) 算法不但存储节点的入度,而且存储了节点的出度和相邻节点信息用于后续判断;
2) 算法在弱判断过程中考虑了对每个节点的出度信息,以初步满足新生节点的个数;
3) 算法继续对弱判断选择出的节点集合进行强判断操作,确定是否存在r个节点两两相连,找出满足合作修复的新生节点.强判断的过程具有很大的挑战性,算法利用定义2以及定理1可以快速找出两两相连的r个新生节点;
4) 算法中加入了大量的预处理和剪枝思想,从而有效地降低算法的时空复杂度.
算法1. B-WSJ算法.
输入:网络拓扑G(V,E)、带宽E={C(u,v)|u∈Vp∪Vn,v∈Vn};


④ if (count+Hp(v)≥d+r-1 &&
count+T(v)≥r-1) then
⑤CANDI←v;
⑥ if (CANDI.size≥r) then
⑦DCGS←∪sHT(vi),vi∈CANDI;
⑧ if (s≥r) then
⑨vn←DCGS;
⑩ returnvn及相应Hp的前d个元素;
关于算法1中实现弱判断的步骤④,T(v)是通过计算所有选取带宽中上游节点的出度来实现的.Hp和Hn是通过计算所有选取带宽中下游节点的入度来实现的.并把候选新生节点邻接供应节点存储进集合Hp,邻接新生节点存储进对应的Hn和T.
算法2. 弱判断中count+Hp(v)和count+T(v)的实现.
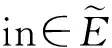
② if (v∈Vn)
③ if (u∈Vn) then
④T(u)←v;
⑤count+T(u)++;
⑥Hn(v)←u;
⑦count+Hn(v)++;
⑧ else if (u∈Vp) then
⑨Hp(v)←u;
⑩count+HP(v)++;
算法1中实现强判断的步骤⑧是通过判断2节点是否均在彼此的邻接新生节点集合Hn中得到的,直到最后得到r个相互连接的节点.
算法3. 强判断中DCGS的实现.
① for eachiinCANDIdo
② if (HP(i).size≥d&&Hn(i).size≥r-1) then
③ for eachjin hashsetvndo
④ if (vn.size=0)
⑤vn.add(i);
⑥ break;
⑦ else if (j=i‖!(j∈Hn(i))‖!(i∈Hn(j)))
⑧ continue;
⑨ else
⑩vn.add(i);
下面列举一个实例来对强判断进行说明.假设弱判断选择出的节点如图5所示,图5(a)表示弱判断选择出的集合CANDI包含元素为{Node2,Node1,Node4,Node3},它们是满足供应节点和新生节点个数条件的候选新生节点,并且每个节点i的Hn集合里的元素为图5(a)所示.假设失效节点个数为3,我们进行4项强判断:①取集合CANDI中第1个元素Node2,由于此时集合为空,Node2将被放入集合中vn;②取CANDI中下一个元素Node1,由于Node2∈Hn(Node1),并且Node1∈Hn(Node2),因此将Node1加入集合.由于vn的长度未到达2,算法继续进行;③取元素Node4,由于Node4∈Hn(Node2),而Node2∉Hn(Node4),故忽略Node4;④取最后一个元素Node3,由于Node3∈Hn(Node1),并且Node1∈Hn(Node3),Node3∈Hn(Node2),并且Node2∈Hn(Node3),因此将Node3加入集合如图5(b)所示.此时集合中元素的个数满足条件,算法终止,并输出最后集合vn及相应Hn的前d个元素.

Fig. 5 An example of strong judgement图5 强判断的实例
4.2 算法分析
本算法由Gong等人[11]所作研究的思想拓展而成,其核心想法是优先选取最大的带宽传输数据,下面对算法的性能进行分析.首先对B -WSJ算法的最优性进行证明;然后对其时间复杂度进行分析;最后我们考虑算法对不同编码方式的影响.
1) 证明算法的最优性
定理2. 分布式存储系统中多节点失效场景下,对于已有的修复模型,节点选择算法B -WSJ为最优.
证毕.
2) 算法时间复杂度的分析
实际分布式存储系统中,链路带宽可以通过数据中心的主节点获取[17],带宽包括集合Vp中节点到集合Vn中节点的带宽,集合Vn中两两节点的带宽.相关研究测量得出获取带宽的时间很短[22],只需2~4个往返时延(round-trip time, RTT),因此获取带宽的时间对于再生修复时间来说可以忽略不计.
综上分析可知,B-WSJ算法加入各种机制降低了节点选择的时间复杂度.一方面,分布式存储系统中,单个文件的存储节点是有限的,例如Google文件系统编码方式为(6,3,3),此时,失效节点个数r满足条件:r≤3,r≪N;因此,失效节点的个数相对系统节点来说是一个很小的值.另一方面,算法中设计的预处理机制和剪枝策略,涉及了节点出入度和连接关系,删除了大量随机孤立或连接稀疏的节点,从而大批量地缩小了算法的选择范围.分布式存储系统中,等待节点失效个数达到r时进行修复.Garraghan等人在文献[25]中指出系统的节点修复时间以小时(h)为单位,大部分节点失效可以通过重启服务器或者其他方式来进行修复,因此其修复时间可以少于30 min;而有些不能通过重启服务器进行修复的失效则需要几天时间.基于此,算法的复杂度是可以接受的.
3) 编码性质的影响
当失效节点的个数达到阈值r时,这些失效的数据将被再生到新的空节点上.根据定义5可知多节点失效时的合作修复模型.我们将此修复过程建模成信息流图,即最大流等于最小割.使用B-WSJ算法选择新生节点集合vn和相应Hp之后,系统继续开始修复数据.修复过程中修复带宽最小割的大小至少为文件的大小,修复过程中的数据传输量可以保证源文件被恢复.因此B -WSJ算法选择出的节点与文件的MDS性质是独立的.
5 实验验证及分析

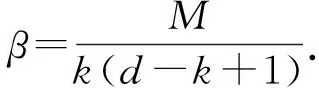
在实验1中,主要变化网络拓扑中带宽分布,以探索多节点失效场景下,B-WSJ算法与已有的算法的性能变化.设定节点的失效阈值为2,每个供应节点需要从4新生节点中下载数据,即d=4.实验分别在网络拓扑中带宽均匀分布范围为[0.3,120],[1,120],[10,120],[30,120],[50,120],[70,120],[90,120]的情况下进行.如图6所示:

Fig. 6 Performance of different node selection algorithm with different network topologies 图6 不同带宽分布情况下不同节点选择算法的性能
在带宽异构明显的情况下,已有的节点选择机制性能相差越来越大.当带宽分布为[90,120]时,即带宽变化不明显时,B -WSJ算法比SPSN算法性能提高了5.27%,比BHS算法性能提高了21.73%.当带宽分布为[0.3,120]时,B -WSJ算法比SPSN算法性能提高了45.93%,比BHS算法性能提高了78.95%.结果证明节点的选择机制对于数据的再生时间具有很大的影响.从图6中还可以看出,B -WSJ算法在带宽异构明显时的性能要好于带宽异构不明显时的性能,这是由B -WSJ算法的对带宽进行贪心择优的特征决定的.
为了验证环境参数对算法性能的影响,我们对不同供应节点个数进行变化.文献相关参考文献网络拓扑中带宽服从均匀分布U[0.3,120] .实验依次变换d的取值,即d分别取值为4,5,6,7,8,结果如图7所示:

Fig. 7 Performance of different node selectionalgorithm with different providers图7 不同供应节点个数时不同节点选择算法的性能
从图7中可以看出随着供应节点个数的增加,算法的再生时间均增加,这是由于算法不但选择新生节点而且同时选择供应节点的个数决定的;从图7中可以清晰看出,B-WSJ算法所选结果的再生时间比SPSN算法增长幅度较慢,这是符合算法的特征的;BHS算法的结果没有特别明显的增长趋势.

Fig. 8 Performance of different node selection algorithmwith different numbers of failure nodes图8 不同失效节点个数时不同节点选择算法的性能
为了继续验证环境参数中节点失效个数对B -WSJ算法性能的影响,我们在失效不同节点个数的场景进行了实验.设定d=4,带宽服从均匀分布U[0.3,120].由于单个文件需要能够被恢复出来,因此不能超过6个节点同时失效,故实验中阈值r分别取值为1,2,3,4,5,6.图8表明:随着节点失效个数的增加,已有节点选择算法的性能越来越差.从图8中可看出B-WSJ算法性能最优,而SPSN算法性能较差.当r=1时,SPSN算法和B-WSJ算法性能相同,这是由于SPSN算法为B-WSJ算法在失效一个节点情况下的特例.随着失效个数越多,由于SPSN算法为逐个失效节点的修复,其选择到的节点性能越来越差,因此其再生时间越来越长,而B-WSJ算法具有全局并行性的特征而性能相对较优.BHS算法为随机选择算法,性能不稳定,因此平均性能最差.
6 结 论
在大数据环境下,分布式存储系统通常引进冗余来提高可靠性.在多节点失效场景下,当失效节点个数达到一个阈值时,系统才进行修复.为了优化修复时间,相关研究验证了单节点失效场景中节点选择机制对修复时间的影响.然而已有的算法不适用于多节点失效的场景,其串行性特征会使得数据的修复性能不再最优.基于此问题,本文继续探索了多节点失效场景下,节点选择机制对数据修复性能的影响.在分析多节点失效的延迟修复模型之后,本文提出了B-WSJ算法,并对算法性能进行多维度的分析和最优性证明.最后通过在不同的参数环境下对比已有算法,结果证明节点选择机制对于数据的修复性能具有很大的影响;通过对不同的实际文件存储方式和失效模型进行实验,结果表明:算法在失效个数比较多或带宽异构明显的情况下,B-WSJ算法比已有算法的性能更优.本文的研究模型比较理想,后续我们将继续扩展环境,考虑传输不同数据量场景下的节点选择机制.
