基于注意机制的化学药物命名实体识别
2018-07-19杨志豪林鸿飞
杨 培 杨志豪 罗 凌 林鸿飞 王 健
(大连理工大学计算机科学与技术学院 辽宁大连 116024) (yangperasd@mail.dlut.edu.cn)
近年来伴随着生物医学领域的飞速发展,生物医学领域的相关文献也以指数级别快速增长.这也随之促进了生物医学文本挖掘技术的快速发展.而化学药物命名实体识别便是生物医学文本挖掘技术中非常重要的一步.
BioCreative评测是国际上关于生物医学文本挖掘的重要评测,而CHEMDNER(chemical compound and drug name recognition)是其中关于化学药物命名实体识别的一项子任务[1-2].在CHEMDNER这个任务上,很多研究者将该任务转化为序列标注问题,而条件随机场(conditional random fields, CRF)在处理这类问题上有着优秀的性能.因此,大多数研究者都采用CRF模型来处理该任务.Leaman等人[3]针对化学名实体识别提出了tmChem系统,该系统由2个使用了丰富特征的CRF模型组成,并运用了若干后处理,在CHEMDNER任务上该系统获得的最高F值为87.39%.Lu等人[4]同样利用2个CRF模型在CHEMDNER任务上获得了88.06%的F值.这2个CRF模型分别为单词级别的CRF和字符级别的CRF.在单词级别的CRF模型中,它们使用了词聚类的特征.基于传统的统计机器学习的方法在该任务上虽然取得了不错的成绩,但是大多数方法均需要领域专家来设计各种丰富的特征,而这些丰富特征的设计,需要大量的人力、物力,于此同时这些特征往往都与任务密切相关,无法扩展到其他任务.
目前,深度学习在各个领域受到了大量研究者的关注.深度学习主要是利用复杂的网络结构或由多重非线性变换构成的多个处理层对数据进行高层抽象的方法[5].最初,深度学习方法在图像和语音识别领域上获得较大成果,随后被运用到自然语言处理(natural language processing, NLP)领域.在命名实体识别任务上,Collobert等人[6]提出了一种有效的神经网络模型,该模型不再需要大量的人工特征,并且能够从海量的未标注文本中学习词向量,进而有助于模型的训练;Huang等人[7]提出BiLSTM-CRF模型,该模型是BiLSTM与CRF的结合,其中BiLSTM能有效利用当前词的上下文,而CRF层能利用句子级别的标签序列信息;Ma等人[8]提出BiLSTM-CNN-CRF模型,该模型首先利用CNN学习字符级别的表示,然后利用BiLSTM-CRF进行后续处理.与传统的机器学习方法相比,深度学习在表示学习上具有很大的优势,它不需要或只需要少量的特征便可以达到较好的性能.在当今的序列标注问题上,BiLSTM-CRF模型成为了主流的方法.该方法引入了句子级别的似然函数(sentence level log-likelihood),与原始的单词级别的似然函数(word level log-likelihood)——交叉熵相比,该函数考虑了句子中单词标签的相关性.虽然该方法利用了句子级别的信息,但是该方法并没有利用全文信息.目前的方法,无论是基于传统机器学习的方法,还是基于深度学习的方法,它们都没有很好地利用篇章信息,仅仅停留在句子信息.这就造成了实体标签的全文非一致性问题(一篇文章中的相同实体被赋予不同的类别标签)的产生.
针对目前方法的不足,本文提出一种基于Attention机制的BiLSTM-CRF模型(Attended-BiLSTM-CRF).该方法以篇章为基础,首先通过大量无标注数据来学习低维、稠密的词向量;然后利用BiLSTM对文档的词向量和单词字符向量进行处理,抽取每个词的上下文表示;随后利用Attention机制来获得当前词在全文范围内的上下文表示;然后将全文范围内的上下文表示和该词的邻近上下文表示经过融合后送往CRF层;最后利用CRF层来获得这篇文章所对应的全文标签序列.实验结果表明,该模型在CHEMDNER评测数据集上获得了更好的表现.
本文方法的创新点在于利用Attention机制引入了篇章级别的信息,在篇章级别信息的帮助下,单词的类别标签的一致性获得了提升;同时将Attention机制和BiLSTM-CRF结合,并在CHEMDNER评测数据集上取得更高的F值.
1 基于Attention的BiLSTM-CRF的化学药物命名实体识别方法
本节我们首先描述模型使用的词特征和字符特征,然后描述BiLSTM-CRF模型,最后阐述本文提出的Attended-BiLSTM-CRF模型.模型的整体结构如图1所示:

Fig. 1 The model architecture of Attended-BiLSTM-CRF图1 Attended-BiLSTM-CRF模型结构
1.1 表示学习
1.1.1 词向量
目前在利用深度学习处理NLP任务上,词向量的表示方法被广泛运用.词向量是一种分布式的词表示方法,它能够从大量的未标注数据中学习到词的语义和语法信息.与传统的词袋模型(bag of words, BOW)表示相比,词向量表示具有维度低和稠密的特点.目前已有很多工具可以用来学习词向量,如word2vec[9]和GolVe[10]等.
为了获得高质量的词向量,我们从PubMed利用“drug”关键字下载了1 918 662 篇MEDLINE摘要.随后利用word2vec工具使用这些无标注的数据进行训练,获得了50维的词向量表示.我们使用这50维的词向量来初始化模型的词向量,模型的词向量是可以训练的,伴随训练不断更新.
1.1.2 字符向量
字符向量与词向量存在显著不同.词向量主要关注词语本身的语义,而字符向量主要关注词语本身的拼写特点(如前缀、后缀等).利用字符向量和词向量能更好地刻画单词的属性.此外,化学药名与普通词在字符级别上存在较大的差异(药物命名存在一系列的标准规范,如IUPAC),因此字符向量可以进一步帮助模型来识别化学药名.
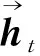
it=σ(Wxixt+Whiht-1+Wcict-1+bi),
(1)
ct=(1-it)⊙ct-1+it⊙tanh(Wxcxt+Whcht-1+bc),
(2)
ot=σ(Wxoxt+Whoht-1+Wcoct+bo),
(3)
ht=ot⊙tanh(ct).
(4)
其中,σ是非线性函数,本文使用hard sigmoid函数,{Wxi,Whi,Wci,Wxc,Whc,Wxo,Who,Wco}是LSTM的参数矩阵,{bi,bc,bo}是LSTM的偏置项.
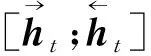
1.2 BiLSTM-CRF
对于一篇文章,经过上述处理后,便可以获得当前词的词向量和字符向量,随后将所有词的这2部分直接拼接后输入到另一个BiLSTM中,便可以得到每个词的上下文表示.
在序列标注任务上,BIO(begin,inside,outside)标签机制被广泛使用,因此本文也采用该标签机制.在实际文本中,化学药物命名实体通常不是由一个单词组成,而是由多个单词组成.这样,利用BIO标签机制后,一个实体的第1个词被赋予B标签,第2个词到最后一个词都被赋予I标签,同时实体之前和实体之后的词都被赋予O标签.由此可知,在实际的标注序列中,B,I,O标签并不是任意出现,它们之间存在紧密的逻辑联系,即一个单词的实体标签不仅受到该单词的上下文环境和该词本身含义的影响,而且还受到该单词的上下文标签的影响.但是在普通的序列标注模型中并没有考虑到这种约束,它们在对当前词的标签判断上,仅仅使用当前词的上下文,并没有使用当前词标签的上下文.因此,在某些情况下会产生不可能的标签序列.如I标签出现在O标签之后等.为了进一步提高实体识别的准确性,这里我们借鉴Collobert等人[6]和Huang等人[7]的工作,结合CRF模型考虑标签转移概率的优点,我们在原始的BiLSTM基础上加入整个句子的标签转移信息.
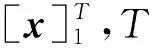
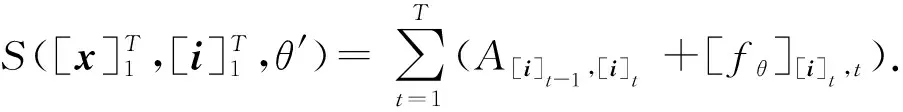
(5)
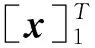
(6)
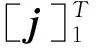
(7)
我们使用随机梯度下降法(stochastic gradient descent, SGD)来优化参数.
训练结束后,在预测标签时,我们需要寻找得分最高的标签序列作为预测标签序列,即:
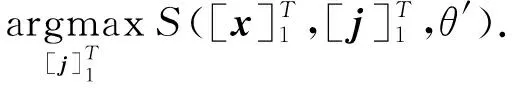
(8)
这里本文采用维特比算法[13]来找到最佳标签序列.
1.3 Attention机制
迄今基于深度学习和传统机器学习的方法中,无法避免的一个问题是单词标签的全文非一致性:在一篇文章中,相同的词、相同的实体却常常被模型赋予不同的实体标签.显然,这会降低模型的正确率,也不易于实际的工程使用.这种问题发生的主要原因在于现今的模型通常以句子作为单独的处理单元.在一个单独的处理单元中,模型根据该词的上下文来赋予标签,即这些模型仅仅利用了句子信息,是句子级别的方法.在同一篇文章中,如果同一实体在不同句子中的上下文不同,则句子级别模型所赋予的标签也会不同,这便是单词标签的全文不一致性产生的原因.同时,如果在同一篇文章中,对于同一个实体,在其众多的上下文中,如果只有唯一一处或几处的上下文对该实体的标签类别的判断起决定性的作用,则现今的句子级别的方法也不能很好地处理该问题.
句子级别方法在化学药名识别这一具体任务上,同样存在单词标签非一致性的问题.同时,单词标签非一致性在这一任务上的另一个体现便是缩写识别准确率的低下.在一篇文章中,作者通常只会在第一次提到缩写时给出该缩写的全称,通常普通模型能够根据此处的上下文对该缩写赋予正确的实体标签.在其后提到该实体时,作者通常不会给出全称,而仅仅给出该实体的缩写,而此处的上下文和该缩写的拼写与该缩写所代指的实体之间的关系较弱,普通模型无法仅根据这些信息作出正确的实体标签类别判断.模型要作出正确的判断,必须要从全文找到该缩写所对应的全称,并获得此处的上下文信息.因此,只有引入篇章信息才能很好地解决这类问题.
在解决单词标签非一致性问题上,研究者通常采用基于规则的后处理.但是规则的制定较为复杂,也无法根据任务学习、变化,而且很难制定出完善的规则.对于该问题本文提出利用Attention机制来引入篇章信息,在篇章信息的帮助下,通过模型的不断学习来缓解该问题.Attention机制最早被运用到图像领域,随后被运用到NLP领域,但目前并没有研究者将Attention机制运用到化学药物命名实体识别任务上.在图像领域,Attention机制主要是模拟人的注意机制[14]:人在观察一副图像时,并不会将自己的注意力平均地分散到整幅图像的每个部位,而大多是根据需求将注意力集中到图像的特定部分,例如看人物肖像时,通常会将注意力集中到脸部.在本文中,对于每一个词,拟使用Attention机制来获取篇章级信息,进而改善相同词的标签的全文非一致性问题.
energyi=f(attended,statei,W),
(9)
αι=softmax(energyi),
(10)
其中,f(·) 是用于衡量statei与attended之间相关性的函数,函数中的参数W随模型一同训练.本文使用曼哈顿距离作为衡量相关性的函数.由于a与自己的距离为0,同时不同词的词义相关性越弱,其曼哈顿距离也就越大,但我们需要词义越相近的词的能量越大,故在实现中我们利用max(energyi)-energyi来修正所需的能量.本文使用曼哈顿距离:
(11)
在实现中,我们对W全部初始化为1,并且在训练过程中保持为正数.
随后,我们利用得到的注意力权重αi对source中的信息进行重新筛选和融合,获得当前词在全文范围下的上下文,这里我们定义为glimpsei:
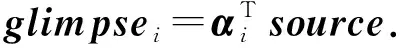
(12)
为了使Attention模型更容易训练,同时当前词的实体标签不仅取决于全文范围内的上下文信息,还应该取决于当前词邻近的上下文信息,因此,我们将glimpsei与sourcei相结合后,输入到后续的模型结构中:
contexti=g(glimpsei,sourcei,U).
(13)
其中,g(·)为非线性函数,本文使用tanh,U为随模型训练的参数.
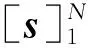
(14)
在预测阶段,与1.2节不同的是,对每个句子分别采用维特比解码.
(15)
2 实验分析
2.1 实验设置
本文在BioCreative IV命名实体识别子任务CHEMDNER的数据集上进行实验[1].表1展示了CHEMDNER原始数据集的构成:

Table 1 CHEMDNER Corpus Analysis表1 CHEMDNER语料的数据统计
实验中,我们将训练集(training set)和开发集(development set)合并,并从中随机抽取10%作为新的开发集,并利用新的开发集来调参,测试集(evaluation set)保持不变.在结果评估上,我们采用序列标注中常用的准确率(precision,P)、召回率(recall,R)、F值(F-score,F)作为实验数据的评价指标.表2展示了本文模型使用的超参数:
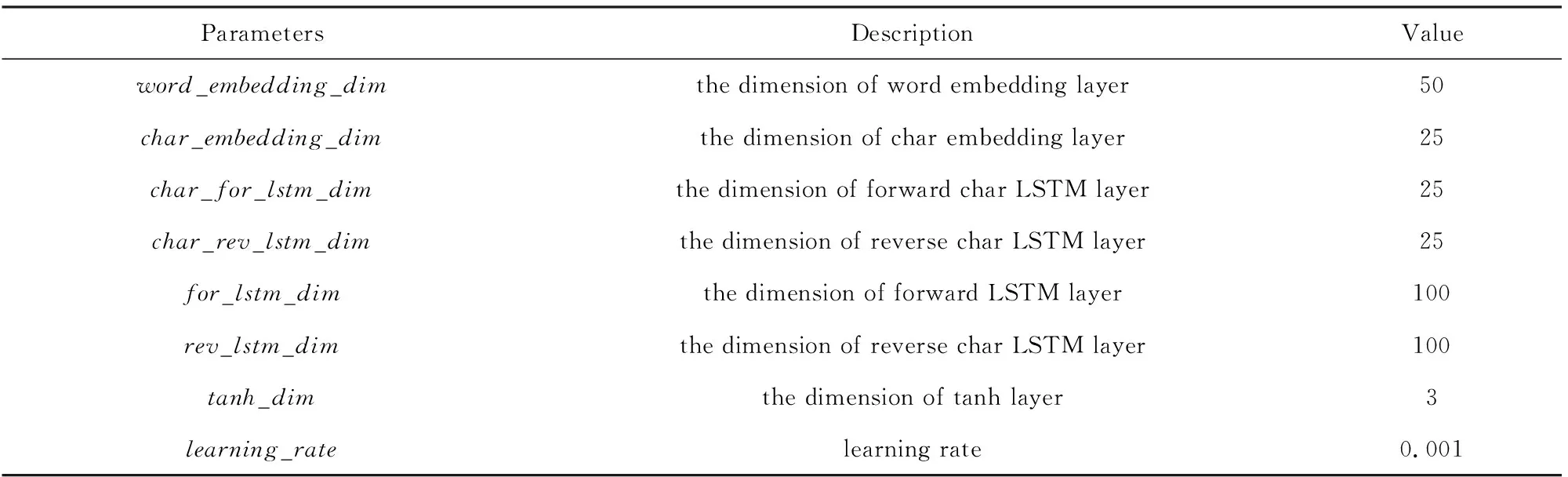
Table 2 The Hyper-Parameters of Model表2 实验中模型的超参数列表
2.2 实验结果
我们将目前的主流方法BiLSTM-CRF与加入Attention机制的BiLSTM-CRF进行对比.此外,为了探索词特征和字符特征对模型性能的影响,对于词特征和字符特征我们分别采用了2种形式的处理方式:1)词特征或字符特征是否经过Attention层处理,即Attention利用何种特征来决定在全文范围内的对齐;2)词特征和字符特征是否经过LSTM层,即是否将词特征或字符特征用于最后的分类.实验结果如表3所示:
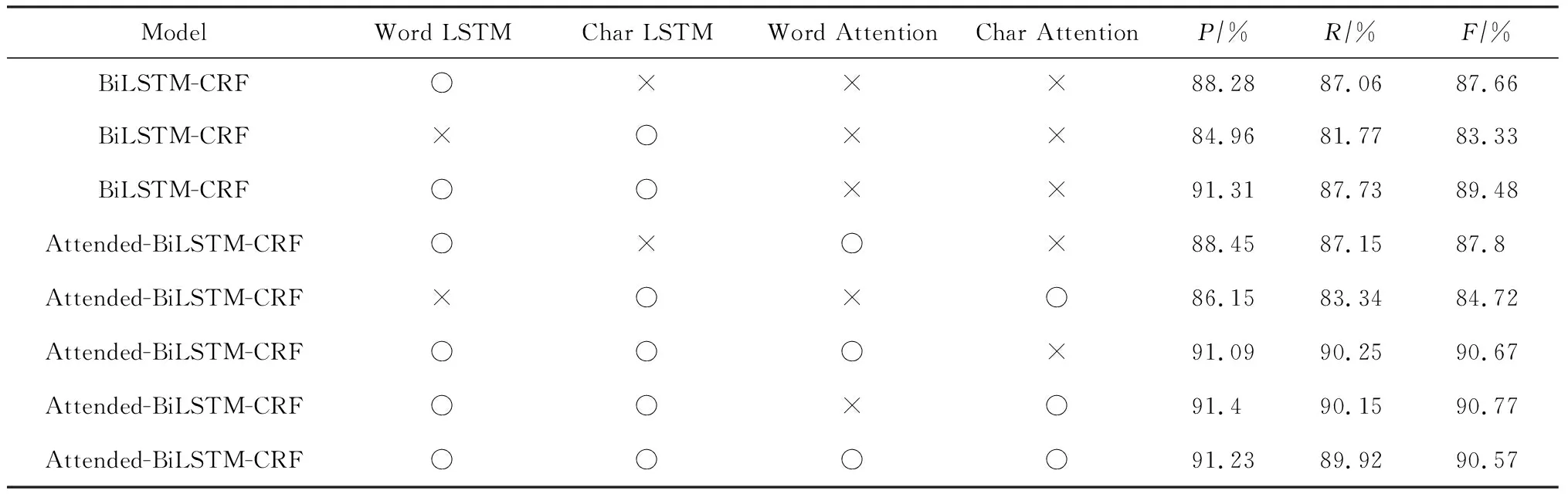
Table 3 Experment Results for the Feature of Attention表3 Attention特征的实验结果
Note: “○” indicates that our model uses this feature. “×” indicates that our model does not use this feature. Word LSTM or char LSTM indicates that our model whether use LSTM layer to process word feature or char feature. Word attention or char attention indicates that our model whether use attention layer to process word feature or char feature.
由表3我们可以获得:
1) 无论是词特征、字符特征或它们的组合,运用Attention机制均能提高性能.
2) 在LSTM层,单独的词特征要比单独的字符特征好,而同时运用词特征和字符特征能进一步提高性能.
3) 在Attention层,单独的词特征要比单独的字符特征差,而同时运用词特征和字符特征反而会降低性能.
对于以上结果,我们分析如下:
1) Attention机制能够学习到篇章级的信息,能够帮助模型提高全文一致性和缩写识别的准确率.在进行结果分析时,我们得到如表4的结果.表4中有背景颜色的单词是模型识别出的实体.由于篇幅限制,我们省略了文中的部分句子和除ANIT以外的标注.从表4中可以看到,本文提出的模型在缩写识别上优于BiLSTM-CRF模型.
2) 在做标签类别判断时,主要依靠词义,而不是字符含义,同时词义与字符含义并不是相互对斥,而是可以相互互补.所以在LSTM层,单独词特征好于单独的字符特征,而同时使用也能提高性能.
3) 由于在词级别存在未登录词,而化学名中也存在大量的未登录词,所以在使用词来做Attention时,未登录词会影响Attention权重αi的生成,造成权重分配不恰当;而字符却不存在这种问题.所以在Attention层单独的字符特征要好于词特征.而这两者同时使用时,模型无法完全消除词特征的缺点,所以造成联合使用时性能有所下降.
为了展示Attention权重的学习效果,我们可视化了Attention权重,如图2所示.该表是当前词为Retinoic时,全文每个单词所获得的权重.由于全文单词过多,无法一一显示,故做相应的省略.
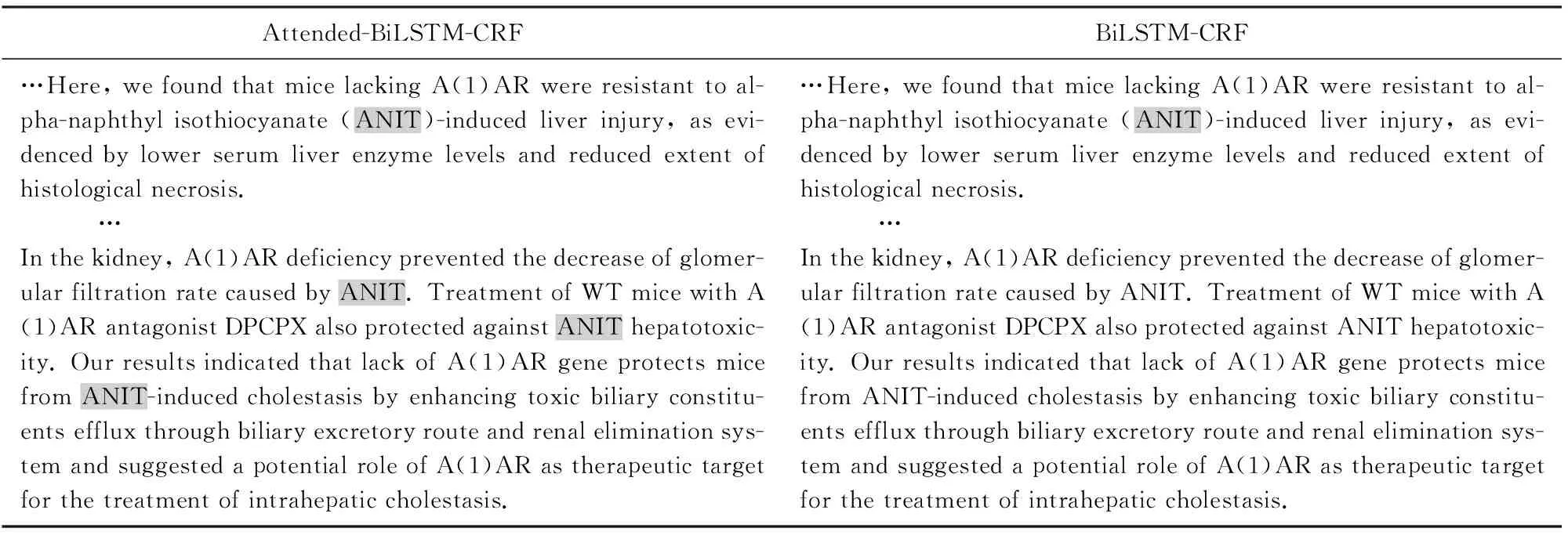
Table 4 An Sample of Tagging Consistency表4 标签一致性展示
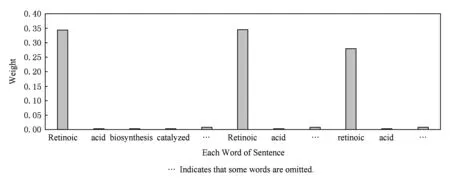
Fig. 2 A sample’s attention weight from CHEMDNER dataset图2 CHEMDNER数据集中某一样本的Attention权重展示
2.3 方法性能对比实验
为了验证Attended-BiLSTM-CRF的性能,我们和其他现存的一些方法进行了对比,实验结果如表5所示:
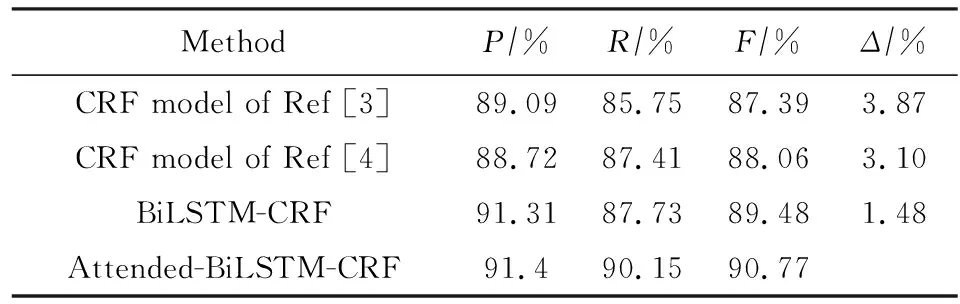
Table 5 The Results of Different Method表5 各种方法对比实验结果
Δindicates the percentage of promotion inF-value.
对比方法简介:
1) CRF 模型[3].利用多个CRF组成的tmChem系统,并作相应的后处理,如缩写识别等,该模型在BioCreative CHEMDNER测评任务上排名第1.
2) CRF模型[4].同样利用多个CRF组成的系统,并运用了词聚类特征和使用了相应后处理,如括号匹配等,该模型在BioCreative CHEMDNER测评任务上排名第2,但测评结束后利用多粒度的词聚类进一步提高模型性能达到88.06%.
3) BiLSTM-CRF.利用BiLSTM-CRF构成的模型,仅仅使用词和字符向量特征,未做后处理.
4) Attended-BiLSTM-CRF.本文提出的基于Attention的BiLSTM-CRF的模型,未做后处理.
以上模型可以分为:传统机器学习方法(前2种方法)和深度学习方法(后2种方法).从实验结果来看,深度学习方法好于传统机器学习方法,而且在特征构造上也无需大量的人工特征,同时也无需复杂的后处理.本文提出的Attended-BiLSTM-CRF模型相比其他方法在F值上均有提高,相比传统的机器学习方法F值提高超过3%,同样相比目前主流的BiLSTM-CRF模型F值提高1.48%.在表5中,可以得到:本文提出的方法与BiLSTM-CRF方法最大的不同在于保持P值基本不变的情况下,大幅度提高R值,这从侧面显示本文提出的方法提高了标签的一致性.同时,在对Attended-BiLSTM-CRF模型的结果分析中,我们发现单词标签的一致性的确得到提高,缩写识别的正确率也得到提高.
3 总结与展望
本文提出了一种用于化学药物命名实体识别的Attended-BiLSTM-CRF方法.实验结果表明Attended-BiLSTM-CRF相比现存的方法均能获得更好的结果,这主要有3个原因:
1) 低维、稠密的词向量和字符向量比传统的机器学习有更好的表现能力,同时深度模型如LSTM能更好地学习到高层的抽象信息;
2) CRF层的引入,降低了不可能出现的类别序列,利用了句子级别的标签之间的依赖信息;
3) Attention机制利用了篇章级别的信息,有效降低了单词标签的全文的非一致性,同时,也带来了缩写识别的准确率的提高.
但是深度学习和Attention机制在生物医学文本挖掘中仍然有很大的提升空间.从本文的实验结果可以看出Attention机制对利用篇章级别的信息很有帮助.将来我们会进一步探索Attention机制在生物医学文本挖掘中的应用.
