基于卷积神经网络的缅甸语分词方法
2018-07-18林颂凯毛存礼余正涛郭剑毅王红斌张家富
林颂凯,毛存礼,余正涛,郭剑毅,王红斌,张家富
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引言
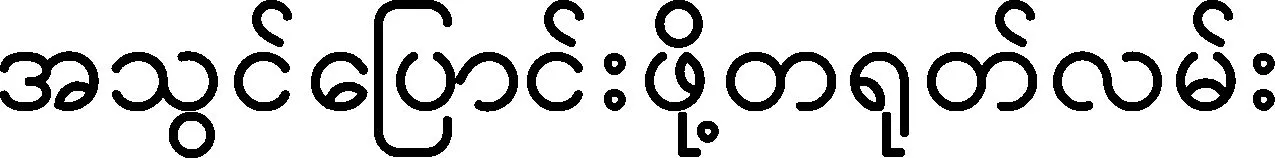
近年来,深度学习在语音、图像方面取得显著的成效[13-14],在自然语言处理任务中也得到了很好的应用[15-23],如Collobert等人[15]提出一种基于神经元语言模型的深度网络模型,用于词性标注、语块分析、实体识别的任务时能取到较好的效果。刘等人[16]使用字、词级别词向量作为初始特征,使用卷积神经网络抽取微博句子特征进行情感分析。吴等人[17]使用深度表示学习和高斯过程知识迁移学习的方法来进行情感分析,克服样本偏置与领域依赖的问题。来等人[18]使用神经网络解决在中文分词时人工构建特征繁琐,特征还需要长时间验证的问题。Chen等人[19]提出一种带有自适应门结构的递归神经网络(gated recursive neural network,GRNN)来抽取n-gram特征。Xu等人[20]将Chen等人提出的GRNN融合到长短期记忆网络(long short term memory neural networks,LSTM)中,利用LSTM提取上下文信息,将提取到的上下文信息用GRNN网络融合起来,利用融合后的上下文信息,作为分类依据。Zhang等人[21]提出将传统提取特征和神经网络自动提取特征过程结合起来,通过融合两种特征,分词效果得到提升。Cai等人[22]提出在分词过程中,不使用窗口滑动取得上下文信息的方式,而是采用直接对分词句子建模,消除了滑动窗口带来的局限性,直接获得该句子的全部信息。随后,Cai等人[23]对文献[22]的模型进行简化,调整神经网络中的更新策略,提出了一种基于词的贪心算法,使中文分词效果进一步提高。
由于深度学习模型能通过多个层次的逐层训练将原始特征进行多次非线性变换,自动获取最稳定的特征用于模型训练。针对缅甸语构词特点及音节组合特点,本文提出一种基于卷积神经网络的缅甸语分词方法,首先将缅语音节结构特征应用于缅语音节词向量特征分布式表示,然后基于卷积神经网络将音节及其上下文的特征进行融合,得到有效的特征表示,并通过深层网络的逐层特征优化自动学习到缅语分词的有效特征向量,最后利用softmax分类器来对构成缅语词汇的音节序列标记进行预测。实验结果表明,本文方法在训练样本稀缺的情况下,效果明显优于基于规则的缅语分词方法和基于统计的缅语分词方法。
1 缅甸语音节结构
在缅语构词上,音节是缅语词语的最小单位,音节则由辅音和元音字符构成。缅语有33个辅音字母、8个元音字母(包括独立元音和依附元音)、2个音调标记、11个中间辅音、1个Asat、10个数字、5个缩写音节和2个标点符号。缅甸语文本字符分为12类,每一类定义了一个类名,表1给出了类名的解释和对应的缅语字符集Unicode编码。
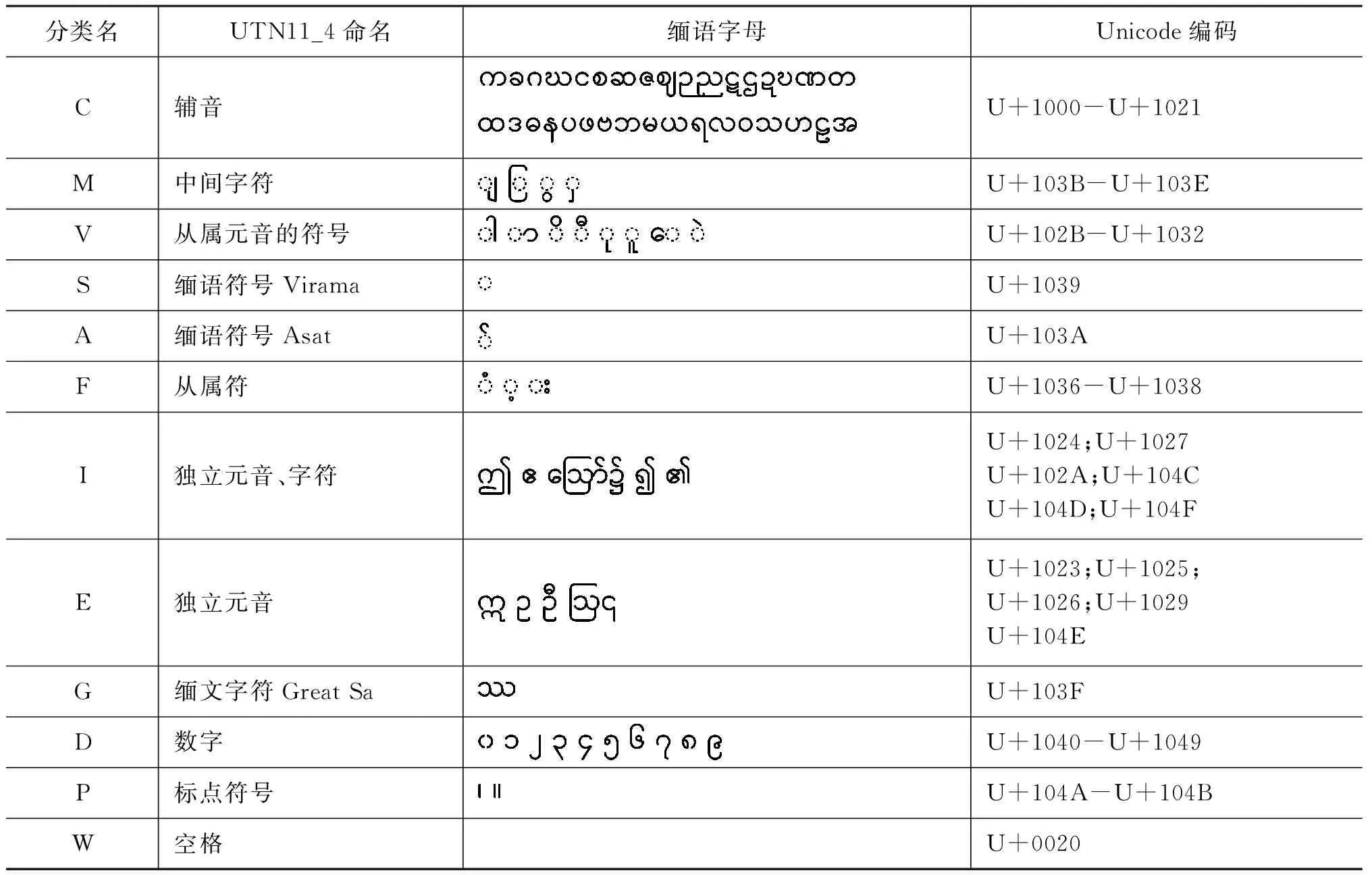
表1 缅语字符分类及编码
Syllble::=C{M}{V}{F}|C{M}V+A|C{M}{V}CA[F]|E[CA][F]|I|D
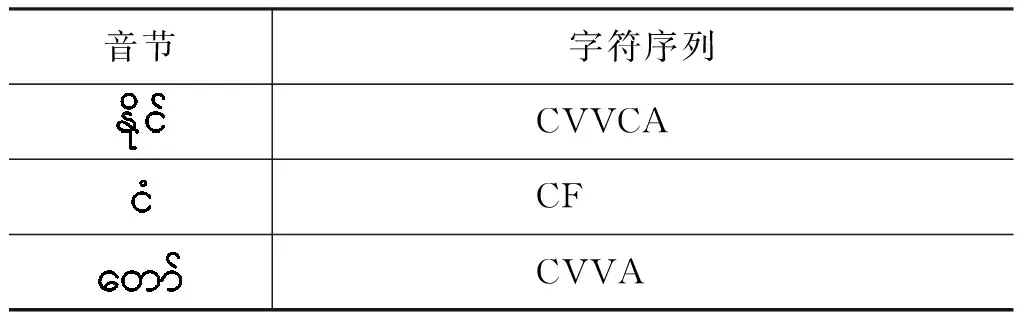
表2 缅语音节结构序列
2 基于卷积神经网络的缅语分词模型
2.1 模型架构
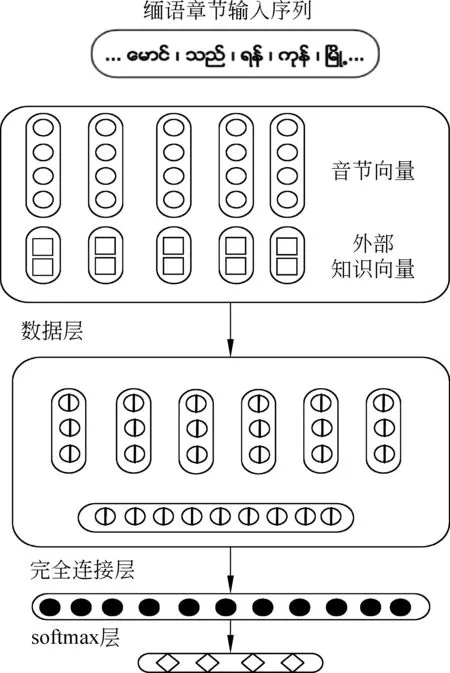
图1 缅语分词架构
本文架构模型的基本思路是,首先将缅语音节结构特征应用于缅语音节词向量特征分布式表示,然后基于卷积神经网络将音节及其上下文的特征进行融合得到有效的特征表示,并通过深层网络的逐层特征优化自动学习到缅语分词的有效特征向量,最后利用softmax分类器来对构成缅语词汇的音节序列标记进行预测,模型架构如图1所示。因此,在网络输入层要以缅语音节序列作为初始输入,在音节特征表示层分别将缅语音节序列及音节结构特征对应的巴克斯范式表征为相应的word embedding向量后再进行融合,得到具有语言知识的缅语音节word embedding向量,然后通过卷积层提取输入序列中音节上下文特征后,通过非线性变换对获取到的特征向量进行进一步优化,得到更有效的特征向量表示,最后在网络的输出层对一个缅语音节出现在缅语词汇中的位置概率进行预测。
2.2 缅语音节特征分布式表征
2.2.1音节特征向量
传统的词向量表示方法,通常将词汇表示为one-hot向量形式,该方法是将每个词表征成长度为N(语料中词典大小)的向量,其中只有一个维度的值为1,其他维度都为0,这个维度就代表当前的词。然而,这种词向量表征方法存在的问题是出现严重的数据稀疏,并且丢失了词语间的语义关系。深度学习在自然语言处理方面的优势还在于能够对词汇进行更深层次抽象,将词汇表征成一个高密度的低维实数向量,能有效避免传统的one-hot形式的向量表示方法出现的数据稀疏问题,并且能很好地表征词语之间的词法、句法和语义信息。如Collobert等人[15]提出的基于神经元语言模型自动学习词汇的Word Embedding向量化表示方法,其核心思想是一个词包含的语义应该由该词周围的词决定。该方法能够将适合出现在窗口中间位置的词聚合在一起,而将不适合出现在这个位置的词分离开来,从而将语法或词性相似的词映射到向量空间中相近的位置。Mikolov等人[24]提出了一种使用周围词来预测中间词的连续词袋模型(CBOW),该模型的核心思想是将输入层相邻的词向量直接相加得到隐层,并用隐层预测中间词的概率,这种方法的优点是周围词的位置不会影响预测的结果。Mikolov等人[24]还提出了一种连续skip-gram模型来表征词向量,该模型与CBOW的预测方式正好相反,是通过中间词来预测周围词的概率。本文采用Collobert[15]提出的词向量表示方法将每一个缅甸语音节进行向量化表示作为模型初始化输入,通过执行矩阵查找操作将文本窗口中输入的每个缅语音节转换成对应的音节embedding向量。
2.2.2缅语音节结构特征向量
2.2.3融合音节结构知识的特征向量
由于缅甸语属于资源稀缺性语言,为了回避缅语音节训练语料规模小导致影响深层模型训练效果,我们提出将表征缅语音节结构知识的向量表征与表征缅语音节本身的向量进行融合,以便得到具有语言知识的音节特征分布表示。为此,我们将输入序列的窗口大小设为5,缅甸语的分词可以定义为: 在一个句子中挑选一个音节,选取该音节的音节向量s3,该音节的前两个音节的音节向量s1、s2及该音节的后两个音节的音节向量s4、s5。将s1、s2、s3、s4、s5首尾连接组成一个长向量S;同时将这五个词的知识向量收尾相连,组成另一个长向量F;将这两个向量融合,使具有外部知识的音节向量作为卷积神经网络的输入进行学习特征。如果该音节的音节向量s3为句子的第一个音节,则s1、s2需要添加0向量作为补充;如果该音节的音节向量s3为句子的最后一个音节,则s3、s4需要添加1向量作为补充,使输入向量完整。将训练好的音节向量和音节结构知识直接融合,记为SF向量,使用音节向量和音节结构知识向量一同表示目标音节,使音节具有音节结构知识,使输入序列具有更多的缅甸语信息,提高分词正确率。
2.3 卷积
由于卷积神经网络能够有效地获取词汇的上下文特征,进而得到更有效的词汇特征表示。但对于自然语言处理的任务来说,输入不是一个图像的像素,而是用矩阵表示的句子或文档。对目标矩阵进行卷积操作,可以获得每个局部的特征向量,再将特征向量进一步组合,可以得到目标矩阵的特征向量。在本文缅语文本分词任务的网络中,目标矩阵每一行表示或一个SF向量。向量的表示方法可以通过在一个窗口中的组合来获得音节的上下文信息,组合成新的X矩阵[SF1⨁SF2⨁SF3⨁SF4⨁SF5],其中⨁是级联运算符,可以获得音节的前后音节组合信息,还可以获得音节结构知识的前后组合信息。为了预测目标SF3的分类,在计算机视觉使用卷积网络时,滤波器每次只对图像的一小块区域进行运算,但应用于自然语言处理中滤波器通常覆盖文本的上下几行网络结构,如图2所示。借鉴Zeng等人[25]的方法,我们的卷积操作包括一个滤波器W,滤波器使n个SF向量产生一个新的特征Z,如式(1)所示。
Z=WjXi
(1)
其中Xi为第i个输入矩阵,也就是第i个实例。Wj为卷积操作的第j个滤波器,是一个线性变换矩阵,1≤j≤30。我们可以看到,在提取缅语特征的过程中,仅使用一个滤波器Wj提取特征,大大减少了在学习过程中参数过多的问题,这也是用卷积神经网络作为特征提取的一大优势。在经过滤波器W之后,就会得到一个相应的特征输出Z。为了获取特征向量Z中最有用的信息,我们对Z进行max-pooling操作[25],如式(2)所示。
ms=max(Zs),0≤s≤j
(2)

图2 卷积层获取缅语音节上下文特征
2.4 融合语言知识的缅语音节特征
上述音节特征向量m自动合成线性向量T={m1,m2,…,mj}。为了学习更复杂的特征,我们设计了一个非线性层并选择修正线性函数(rectified linear function,ReL)作为激活函数。在缅语音节训练过程中发现,在随机初始的网络权重过大的情况下使用sigmoid函数会导致网络训练不稳定,但使用ReL激活函数可以有效避免权值过大或过小对网络训练的影响。激活函数可以写为式(3)。
g=max(0,WyT)
(3)
Wy为线性转换方程,将向量T映射到隐层layer1上,使用ReL激活函数得到g,这里g表示更高层次的缅语音节特征。
2.5 输出层
为了推算每个输入缅语音节向量矩阵X在词汇中的位置信息,将得到的特征g输入到softmax中来预测其位置信息[25],softmax的预测输出,如式(4)所示。
o=Wpg
(4)
Wp为线性转换方程,将向量g映射到输出层,每一个输出o为输入缅语音节向量矩阵X的位置的“得分”,o的预测种类有四种,分别为: B,该音节位于词汇的开始位置;M,该音节位于词汇的中间位置;E,该音节位于词汇的结尾位置;S,该音节可以单独形成词汇。每个得分可以通过softmax操作解释为该音节属于某位置的概率。例如,在实验中,该缅语音节“”,在标记语料中为缅语词汇开始部分,则对应B的值为1,其他位置为0。在经过神经网络预测时,该音节属于标签B的概率约为83%,属于标签M的概率约为9%,属于标签E的概率约为5%,属于标签S的概率约为3%,所以就可以判断该音节缅语“”为标签B,也就是属于词汇的开始部分。
2.6 反向传播
缅语音节序列标记识别任务目标是预测输入向量X在缅语词汇中的位置,位置信息取决于参数θ=(X,Wj,Wy,Wp)。本文将每个输入的向量矩阵看作是相互独立的,对于一个输入向量x,x通过网络预测得到输出向量o,在向量o中,第i个值oi为输入x在第i个位置的“得分”,这个“得分”可以写成一个带标记的条件概率ρ(i|x,θ),通过softmax操作[25]来计算概率如式(5)所示。
(5)
在整个训练过程中,通过最大化likelyhood[15,25]来训练本文卷积神经网络,进而实现预测缅语音节在缅语词汇中的位置信息,可以将log-likelyhood记为:
(6)
式(6)中,T表示训练实例,x为输入向量,y为该输入向量x的对应标记。使用随机梯度下降算法来使J(θ)最大化,来估计θ的值,也就是网络中所有的参数信息。本文中Wj,Wy,Wp为随机生成,X由具有音节结构知识的音节向量初始化得到。由于这些参数位于网络的不同层中,因此,我们使用反向传播算法并通过如下规则来更新所有参数信息θ,如式(7)所示。
(7)
3 实验及结果
为验证本文提出的(CNN_ES)缅语分词方法的效果,分别设置了三个对比实验。
实验1对比了本文提出的缅甸语分词方法与基于音节最大匹配(S_Max)、将字典融入无监督生成模型(I_D_Model)传统缅语分词方法。
实验2本文方法与其他深度神经网络(BP神经网络,卷积神经网络CNN,RNN语言模型)进行对比。
实验3验证不同因子对深度神经网络的影响,用缅甸语字符替换音节向量进行输入,和本文方法(CNN_ES)进行对比。
实验4验证不同窗口大小对实验结果的影响。
实验5对比不同规模的训练语料对实验结果的影响。
其中,_ES表示以融合音节结构特征的缅语音节Embedding向量作为CNN模型的输入。
实验中我们严格按照标准评价指标,统计了各种方法的准确率P和召回率R,在这两个指标的基础上,把F1值作为衡量所提方法的最终评测指标。准确率、召回率以及F1值的公式如式(8)~(10)所示。
(8)
(9)
(10)
3.1 实验数据集
缅甸语属于稀缺资源,目前还没有公开的缅甸语分词语料数据集。为验证所提方法的有效性,我们从新华社缅文版新闻网站上爬取缅语新闻文本数据,对网页预处理得到不含网页标签和图片的文本后,利用缅甸阳光计算机学院(UCSY)的在线缅语文本分词工具*http://www.nlpresearch-ucsy.edu.mm/NLP_UCSY/wsandpos.html对爬取的缅语文本数据进行切分,然后通过人工校对后得到40万规模的缅语分词语料数据集,以下实验都是以此数据集作为训练语料进行训练。我们从中随机挑选39.95万分词语料构成分词训练集,剩下的500个词构成测试语料集,如表3所示。在构建的分词语料库的基础上,我们进一步对词汇进行音节切分。

表3 语料规模
3.2 实验结果分析
我们的实验使用开源Python工具Gensim训练向量,训练神经网络的参数如表4所示。
(1) 现有的缅语分词方法与本文方法实验结果比较
对比了本文提出的缅甸语分词方法CNN_ES与缅甸语分词方法: 基于音节最大匹配(S_Max)[8]、语言生成模型(L_M)[26]、将字典融入无监督生成模型(I_D_Model)[26]、基于字典匹配模型(Dictionary)[27]、SVM[12]和CRF++[12]模型实验结果如表5所示。
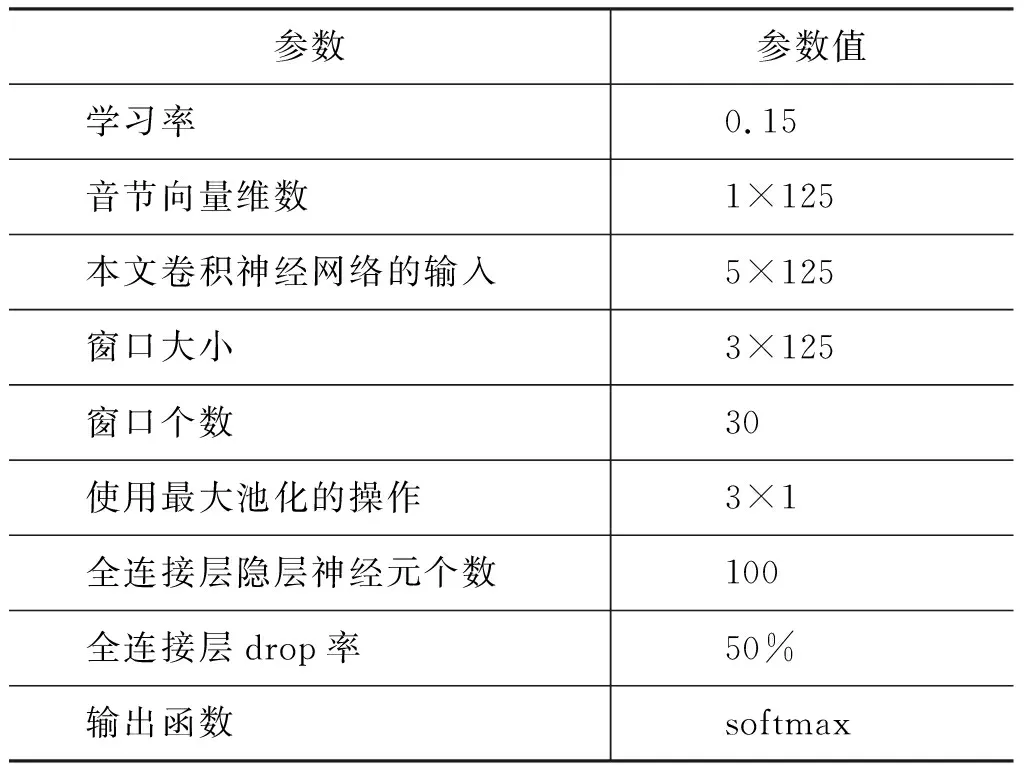
表4 参数设置

表5 不同分词方法的实验结果
从表5可以看出,通过查找准备的字典并匹配最长的子字符串来获得最大匹配的方法(S_Max)正确率较低,主要由于缅甸语训练语料的稀缺,在训练过程中无法人工穷尽所有的语言特点,和在与字典匹配过程中出现歧义的问题无法解决。语言生成模型(L_M)分词质量严重依赖于语料的质量,实验结果说明对于语料中出现次数较低的词效果不好。将字典融入无监督生成模型(I_D_Model),模型的生成过程与多个字典进行竞争生成,该方法在字典匹配的基础上,使用无监督的生成数据模型,提高了正确率,但还是无法保证在语料稀缺情况下字典生成的质量,而字典的质量会影响分词的结果。SVM、CRF++模型分词效果高于基于字典匹配的方法,SVM模型在训练过程中并未考虑音节的前后文信息,正确率较CRF++模型低。卷积神经网络(CNN)由于能够很好地利用音节的上下文特征,在训练语料规模不够大的情况下效果优于其他机器学习的方法。本文方法(CNN_ES)在CNN深层网络中训练缅语音节Word Embedding向量融合了缅语音节结构特征,分词效果明显提高,可见在深层网络中有效利用缅语的语言知识及音节的上下文特征能有效提高缅语的分词效果。对比传统基于字典匹配的缅甸语分词方法,本文方法(CNN_ES)删去人工构造特征字典的这一过程,让CNN_ES自动提取输入特征向量的规则不仅可以大大减少工作量,同时也可以避免在语料稀缺情况下总结出的特征字典质量不高而使分词质量下降的问题。机器学习、深度学习的缅甸语分词方法都依赖于语料库的大小,对于未覆盖的缅语不能很好地处理,本文方法(CNN_ES)将音节结构知识向量融合到音节向量中,当音节向量失效时(见到未覆盖词,将音节向量标记为全0向量),本文方法(CNN_ES)还可以通过音节结构知识向量对该音节进行进一步判断。
(2) 不同神经网络模型用于缅语分词的效果比较
从表6可以看出,在相同数据量的情况下BP神经网络学习速度较慢,主要是由于相邻层神经元进行两两连接,数据传递和更新需要大量的时间。BP网络每层的神经元并没有直接相连,对于预测音节的前后音节没有很好的关联,导致预测的正确率偏低,而且训练速度也快于其他深度神经网络。递归神经网络(RNN)语言生成模型,在训练语料规模不够大的情况下,可以模拟出缅甸语音节的组合的大部分规则,但对于出现次数不高的音节组合样本,其规则会被出现频率高的组合所覆盖;训练递归神经网络(RNN)语言时,会随着训练样本的输入反向传播出现梯度消失等问题,对于缅语分词训练,RNN模型构建相对复杂,训练时间也相对较长,对于语料资源稀缺的缅甸语,RNN模型并不适用。本文方法(CNN_ES)继承了CNN网络训练参数少、速度快及模型构建简单的优势,由于网络输入的为音节特征向量和音节结构知识向量的融合向量,丰富了缅语音节的特征,使网络提取到更多的特征,提高了缅语分词的正确率。
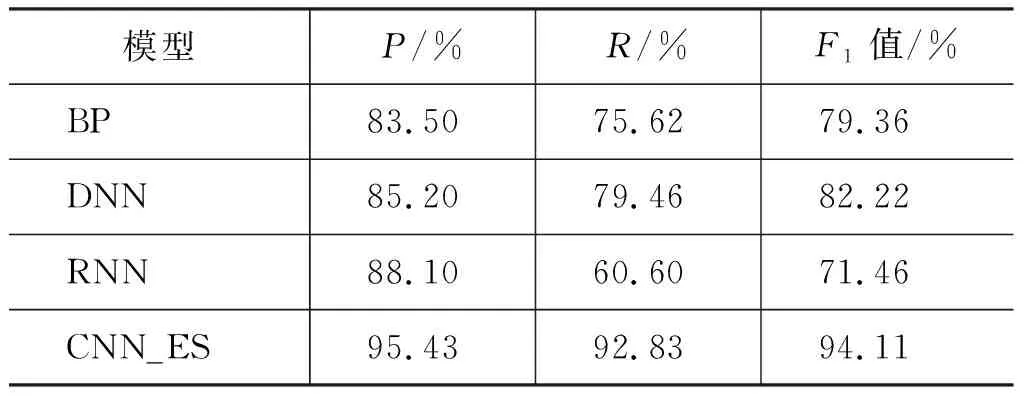
表6 不同神经网络类型的实验结果
(3) CNN网络中分别以缅语字符和音节作为初始输入对缅语分词结果的影响
缅语的最小构词粒度是音节,不是字符。为验证缅语不同构词粒度对分词结果的影响,我们在CNN网络的输入层分别训练基于缅语字符的Character Embedding向量和基于音节的word embedding向量作为初始输入,实验结果如表7所示。从表7可以看出,基于字符的方法效果远低于基于音节的方法,这主要是由于缅语基本字符只有160个,不能表现出像缅语音节一样丰富的特征,训练出的字符向量并不能很好地区分每个字符,并且由于降低了输入的粒子级别,使低质量的语料剧增,网络训练所需时间增加一倍,网络也不容易收敛。可见,对于缅语这种字符较少的语言,使用其丰富的音节组合信息可以获得更多的有效特征。
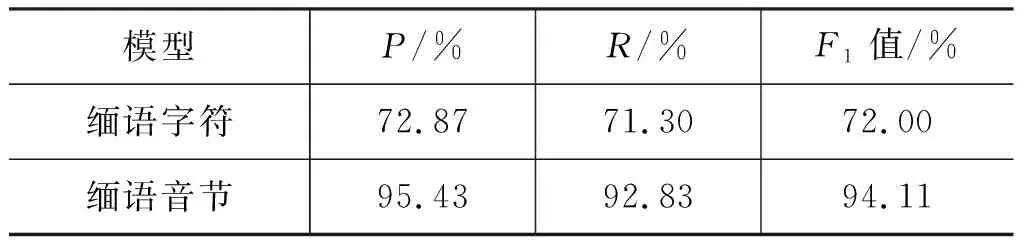
表7 网络输入层不同切分粒度对分词结果的影响
(4) 不同窗口大小对实验结果的影响
本实验对比了输入序列窗口分别为3、5、7、9三种情况下分词效果,如表8所示。
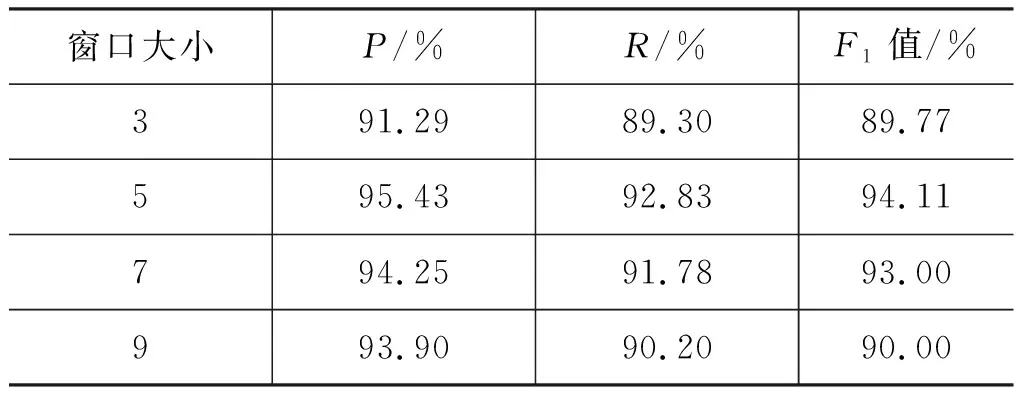
表8 不同窗口大小对实验效果的影响
从表8可以看出,窗口大小的选择也会影响分词的效果,在缅语常用语中,缅语词所包含的音节大多为2~5个,当窗口为5时实验效果最好,不仅可以避免当前音节对上下音节依赖的不足,还可以规避过长的窗口造成音节特征冗余。因此本文实验中音节窗口设置为5。
(5) 不同规模的训练语料对实验结果的影响
为了验证缅语音节结构知识特征对音节Word Embedding向量表征效果的影响,我们通过不同规模的训练语料进行了对比试验,P_CNN表示在不同语料规模下卷积神经网络CNN分词的正确率,P_CNN_ES表示在不同语料规模下本文方法(CNN_ES)分词的正确率,结果如表9所示。

表9 不同规模的训练语料对实验结果的影响
从表9可以看出,语料较少时,本文方法(CNN ES)融合了音节结构知识,可以在神经网络训练时提供更多的特征。与卷积神经网络CNN相比,该方法使分词的正确率有一定提高。当语料从10万增加到20万时,缅语分词的准确率有明显提高,主要原因是补充了小规模语料情况下特征覆盖不全的问题,导致深层网络无法学习到更多特征,同时本文方法在正确率提升速度方面高于CNN网络,融合了音节结构知识向量的表征方法,在相同语料的情况下,能提供更多的特殊的用于神经网络的学习。将语料大小从30万提升到40万时,CNN_ES分词准确率仅提升了近1个百分点。可见,在缅语音节词向量表示中融合语言知识特征,能有效弥补资源稀缺对缅语分词性能的影响。
4 结束语
针对缅甸语分词面临训练语料资源稀缺的问题,本文提出一种基于卷积神经网络的缅甸语分词方法,将缅语音节结构特征融合到缅语音节的深层特征表示中,并利用卷积神经网络学习到音节的上下文特征,通过深层网络的逐层特征优化自动学习到缅语分词的有效特征向量表示。实验结果表明,该文提出的方法在训练样本稀缺的情况下,效果明显优于基于规则的缅语分词方法和基于统计的缅语分词方法。下一步将研究如何在缅语音节的Word Embedding向量预训练中加入正则项约束,以便得到更有效的特征表示来提高缅语分词的性能。
