面向高考语文阅读理解的篇章标题选择研究
2018-07-18吕国英郭少茹谭红叶
关 勇,吕国英,李 茹,2,3,郭少茹,谭红叶
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2.山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006;3. 山西省大数据挖掘与智能技术协同创新中心,山西 太原 030006)
0 引言
阅读理解(reading comprehension,RC)作为问答任务的一个重要分支,受到越来越多的关注[1-2]。阅读理解式问答系统是从一篇给定的背景材料中查找答案,要求系统在“阅读”完一篇材料后,根据对材料的“理解”给出问题的答案[3]。
高考语文阅读理解中,背景材料相对较短且极具隐藏性,答案可能无法在背景材料中直接找到,因此,更注重考查机器对文章理解和概括的能力。高考语文阅读理解科技文分为选择题和问答题两大题型。选择题题型划分为五种,分别为“文意理解”、“观点支持”、“拟写标题”、“指代消解”和“补写句子”[4]。目前,选择题主要针对“文意理解”、“观点支持”类题目展开研究,解答这两类题目需要通过对与选项相关句子或片段的理解选出答案。标题选择题目的解答则需要对整个篇章进行理解概括,分析标题与篇章的相关性,进而选出答案。
篇章标题选择类题目可形式化描述为: 篇章、题干和选项三元组
针对高考语文阅读理解科技文篇章标题选择类题目,本文提出基于标题与篇章要点相关性分析模型。该模型构建了基于标题与篇章要点的相关度矩阵(2.1节),并融入标题结构特征(2.2节)进一步优化模型。在全国近10年高考真题和测试题上进行实验,对实验结果进行分析,最后对本文工作进行总结。

表1 篇章标题选择题目示例
1 相关工作
针对阅读理解任务提出的相关技术可以分为两种: 基于特征的方法[5-7]和基于深度学习的方法[8-11]。
基于特征的方法通常使用特征工程、语言工具、外部资源等来解决这类问题。文献[3]针对高考语文阅读理解文意理解类题型,提出一种多维度投票算法。该算法将Word2Vec、HowNet、词袋模型、框架语义场景四个方面作为度量标准,运用投票算法的思想,选取最佳答案。文献[4]针对高考语文阅读理解题干支持类题目,通过对篇章、题干、选项三者的关系进行建模,制定联合打分函数,加入句子相似度特征、反义匹配特征、否定特征三个语义特征信息,提出基于题干与选项一致性判别模型。文献[12]提出一种答案蕴含策略,把问题、正确选项和文章之间的关系用一个答案蕴含结构表达,通过模型获得该答案蕴含结构,选出正确选项。
基于深度学习的方法主要是通过构建神经网络模型。在基于词向量表示基础上,利用深度神经网络模型学习句子的向量表示,然后把任务转换成分类或排序问题。文献[13]针对MCtest数据集机器理解任务,构建一个基于Attention机制的分层的卷积神经网络模型。通过对文章、问题、答案进行建模,发现与回答问题相关的关键短语、关键句和关键片段。文献[14]针对阅读理解任务提出一个循环神经网络模型,学习词和短语的向量表示进行实体推理,用逻辑回归分类器对篇章预测类别,类别标签就是问题的答案。文献[15]基于分布式表达的思想,将问题与候选答案都映射到一个分布式的语义表达中,然后,基于二者的表达来学习问题与候选答案的匹配程度。
基于特征的方法需要人工构建不同的特征,耗费大量的时间,而基于端到端的神经网络模型虽然可以自动学习特征,但是由于数据的稀疏性、问题的复杂性,效果提升不是很明显。因此,本文结合基于特征的方法和神经网络的方法,提出标题与篇章要点相关性分析模型。
2 标题与篇章要点相关性分析模型
2.1 标题与篇章要点相关度矩阵
篇章由不同的段落组成,篇章各段落涉及不同的要点内容,标题是对篇章中各要点内容的高度理解概括。恰当的标题覆盖篇章各个要点内容,如何判断标题对各要点的覆盖程度是解决标题选择题的关键问题。针对此问题,提出了标题与篇章要点相关度矩阵。矩阵由选项和篇章要点相似度组成,行表示选项与各篇章要点相似度值,列表示篇章要点与各选项相似度值。根据相关度矩阵选取覆盖篇章要点内容最全面的一项作为最恰当的标题。图1为2015年北京高考题(第三题)相关度矩阵示意图。矩阵维度为4*5,分别表示四个选项和五个段落,颜色的深浅代表相似度值的大小,颜色越深代表相似度值越大。可以看出选项B覆盖篇章要点内容最全面,为最恰当的标题。具体公式如式(1)、式(2)所示。
其中,Sim(Ak,Seni)表示选项Ak与篇章要点Seni的相似度值,Ak,k∈[1,n],Seni表示篇章要点,m表示篇章要点的个数,Answermatrix表示选项与篇章要点相关度最高的一项。

图1 标题与篇章要点相关度矩阵
2.1.1篇章要点抽取
篇章要点的获取是形成标题与篇章要点相关度矩阵的关键。篇章各段落涉及不同的要点内容,段落主旨句是段落的中心句或者主题句,具有概括段落的作用,是段落的中心所在,所以,选取段落主旨句作为篇章要点。针对篇章要点获取问题,提出了基于相关因素的段落主旨句抽取方法。该方法对同义、上下位概念进行归并,同时,综合语句所在位置、文章标题、语句中所含重要词汇等多种度量方式,综合评估句子反映主题的价值,从而更精确地抽取出段落的主旨句。在文献[16-17]方法基础上,针对高考科技文的特点进行了改进。
(1) 段首、段尾句权值优化。高考科技文的段落中,段首句或者段尾句一般是总结段落内容的句子,所以段落的段首、段尾句包含的主题信息量比重比较大。对语句权值的调整如式(3)、式(4)所示。
其中,W(Si)表示语句的位置权值,Lnum表示段落中句子数量,j表示当前句子在段落中的位置,W(SLnum)表示段落尾句的权值。
(2) 长句权值优化。主旨句大多包含说明文章主题或关键内容的主题概念字串,所以包含主题字串多的语句可作为主旨句。长句所包含的主题字串的数量一般要高于短句,因而长句计算出来的权值较高,因此需要减弱语句长度对权值的影响,对语句权值的调整如式(5)、式(6)所示。

选取段落中语句权值最大的语句作为段落的主旨句,语句的权值可由不同的度量方式组合得到,如式(7)所示。
(7)
其中,σ1+σ2+σ3=1,F(Pi,Sj)表示段落Pi的第Sj句话的语句权值,WTitle(Sj)表示第Sj句话的标题权值。
2.1.2基于LSTM的选项与篇章要点的相关性计算
2.1.1节中,抽取了段落主旨句作为篇章要点。如何计算标题与篇章要点的相关性是生成相关度矩阵的难点。针对该问题,提出了基于LSTM的选项与篇章要点相关性计算方法,模型如图2所示。
基于神经网络的方法大多是在基于词向量表示的基础上,利用深度神经网络模型学习句子的向量表示,把任务转换成分类或排序问题。模型结构与文献[18-19]类似。
输入层是由篇章要点(集合SK)和选项(集合A)组成的二元组
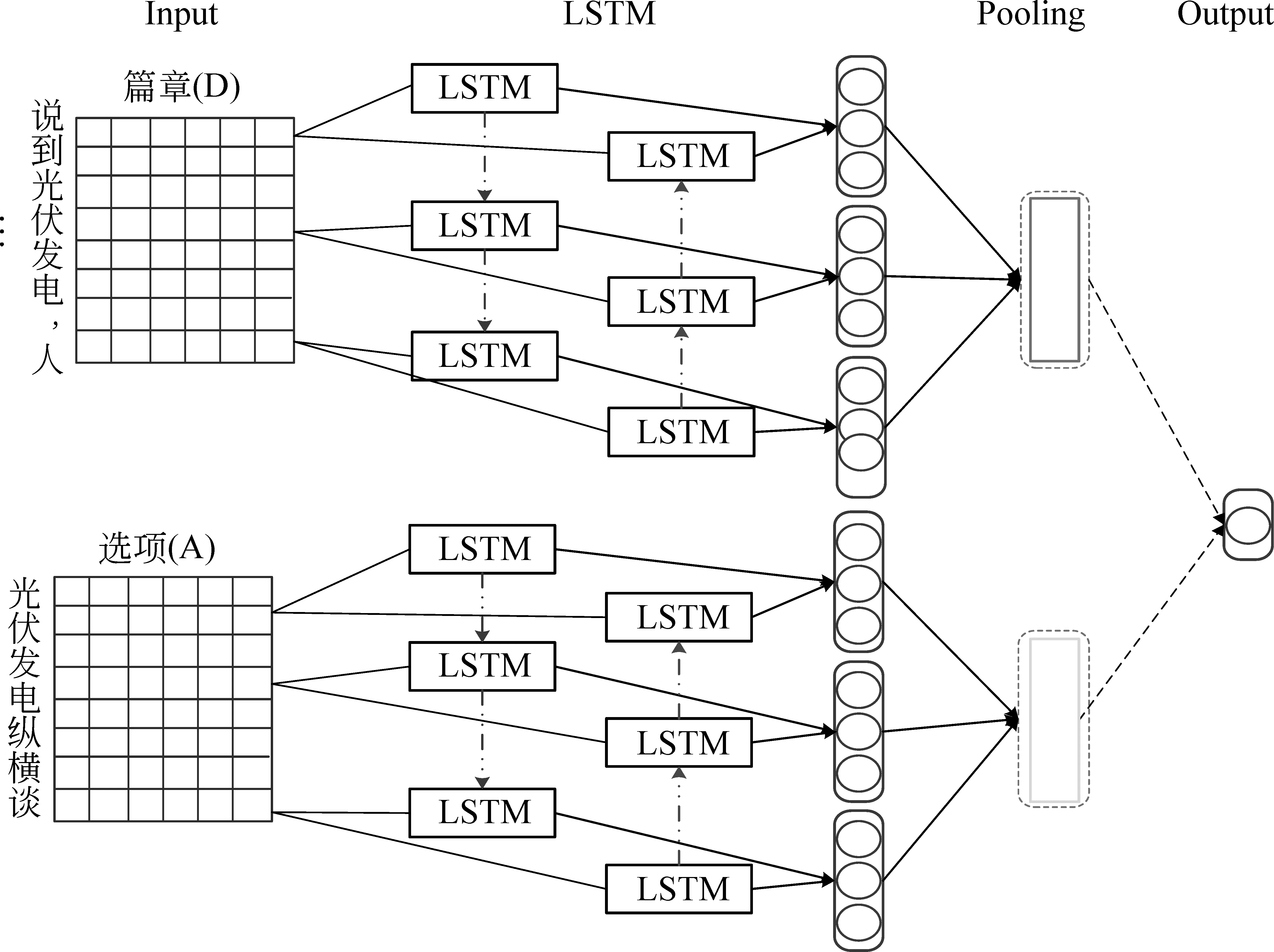
图2 基于LSTM的选项与篇章要点的相关性计算
LSTM层使用bi-LSTM获取选项和篇章要点的向量表示[21]。bi-LSTM会提供给输入序列每一个节点过去和未来的上下文信息,相对于单向LSTM来说能提供更多的特征信息。具体公式如下:
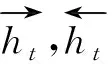
池化操作有最大池化、平均池化等,本文使用的是最大池化k-Maxpooling(k=1)方式。hsk和ha分别表示篇章要点和选项的向量表示,篇章要点和选项之间的相关性用篇章要点和选项的向量的余弦相似度表示。损失函数和文献[22]类似,如式(11)所示。
(11)
其中,cos(hsk,ha+)表示文章和正确选项的相似度,cos(hsk,ha-)表示文章和错误选项的相似度,hsk表示篇章要点,ha+表示正确选项,ha-表示错误选项,Q表示阈值。训练集中,每条数据中只有一个正例标题和一个负例标题。在测试集上,每条数据中有四个候选选项,分别输出每个选项和各个篇章要点的相似度值,形成标题和篇章的相关度矩阵。
2.2 篇章标题结构分析
标题作为读者阅读文章的第一项内容,对理解文章内容具有重要的作用。本文参考文献[23-25]的分类体系,分析了5 872篇高考科技文标题结构和语言特点。根据高考科技文标题的特点,制定了相应的结构体系,如(1)~(5)所示。具体类别比例如表2所示,其中以名词短语结构为主。
(1) 名词短语+名词短语标题(n+n): 由一个以上的名词短语构成。例如,“围棋与国家”。
(2) 动词短语+名词短语标题(v+n): 由动词和名词短语构成。例如,“拯救阅读”。
(3) 名词短语+动词短语标题(n+v): 由名词和动词短语构成。例如,“太空行走”。
(4) 完整句子结构标题(s): 指从语法角度讲符合句子构成的标题。例如,“企业家为什么越来越重视书画文化?”。
(5) 名词标题(n): 由单一名词短语或是专有名词构成。例如,“古琴”。

表2 标题类别比例
对标题结构进行分析统计,形成标题结构权值,如式(12)所示。
(12)
其中,FT(Ai)表示标题类别为i的权值,Ki表示标题类别为i所占的比例。
2.3 融合标题结构权值
标题具有高度归纳概括篇章内容、结构鲜明的特点。标题与篇章要点相关度矩阵方法主要考虑了对篇章内容的概括、标题与篇章内容的相关性分析。篇章标题结构分析方法主要研究了标题的结构特点,对标题进行分类。因此,将以上两种方法进行融合来获得更好的实验结果。具体如式(13)、式(14)所示。
其中,Answerfuse表示融合标题结构信息后最终的答案,FW(Ai)表示选项Ai融合标题结构信息后的答案。
标题与篇章要点相关性分析模型具体思路为: 先抽取段落Pi的主旨句作为段落的要点,计算每个选项Ak与各个要点的相关性,形成相关度矩阵。再根据标题结构的特点对标题进行分类,形成标题结构权值,融合相关度矩阵和标题结构权值选出最佳选项A*。如算法1所示。
算法1标题与篇章要点相关性分析
输入: 篇章D={P1,P2,…,Pi,…,Pm};选项A={A1,A2,…,Ak,…,An};
输出: 最佳选项A*
初始化 集合Dyd中存储篇章各要点,集合Fstruct存储标题结构权值,集合Fbd存储选项与篇章要点的相似度,S*临时存储段落要点,F*临时存储选项与篇章要点的相似度,T*临时存储标题结构权值
FORPiIND
S*=MAX{F(Pi,Sj)}
//获取段落要点S*,将S*添加到Dyd中;
ENDFOR
FORAkINA
ENDFOR
//获取选项与篇章要点的相似度F*,将F*添加到Fbd中;
T*=FT(Ak)
//获取标题结构权值T*,将T*添加到Fstruct中;
ENDFOR
FORAkINA
//融合标题结构权值
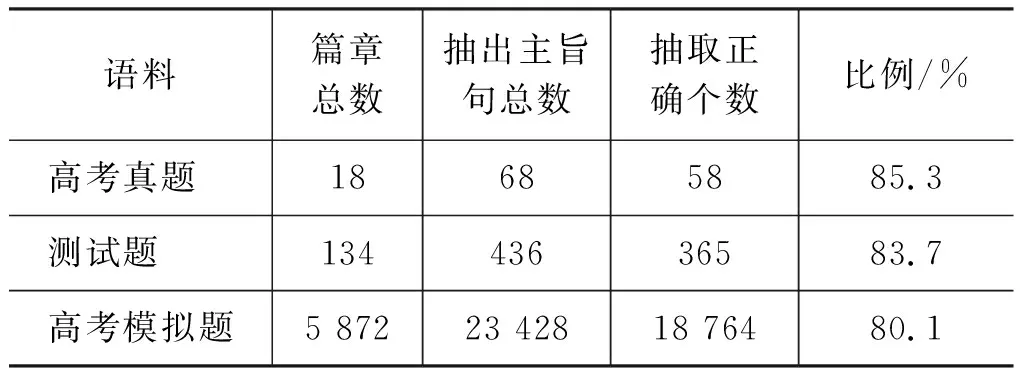
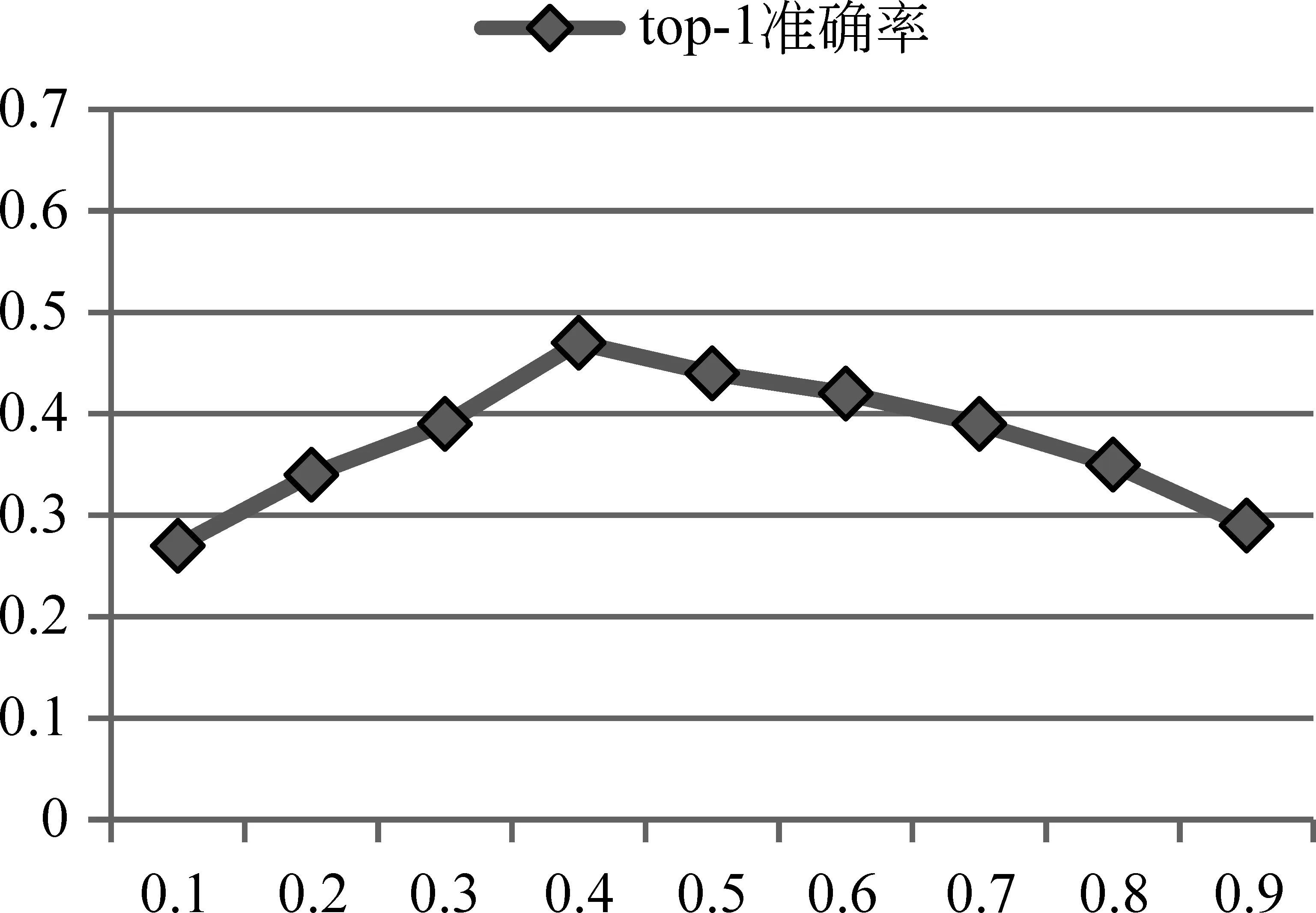
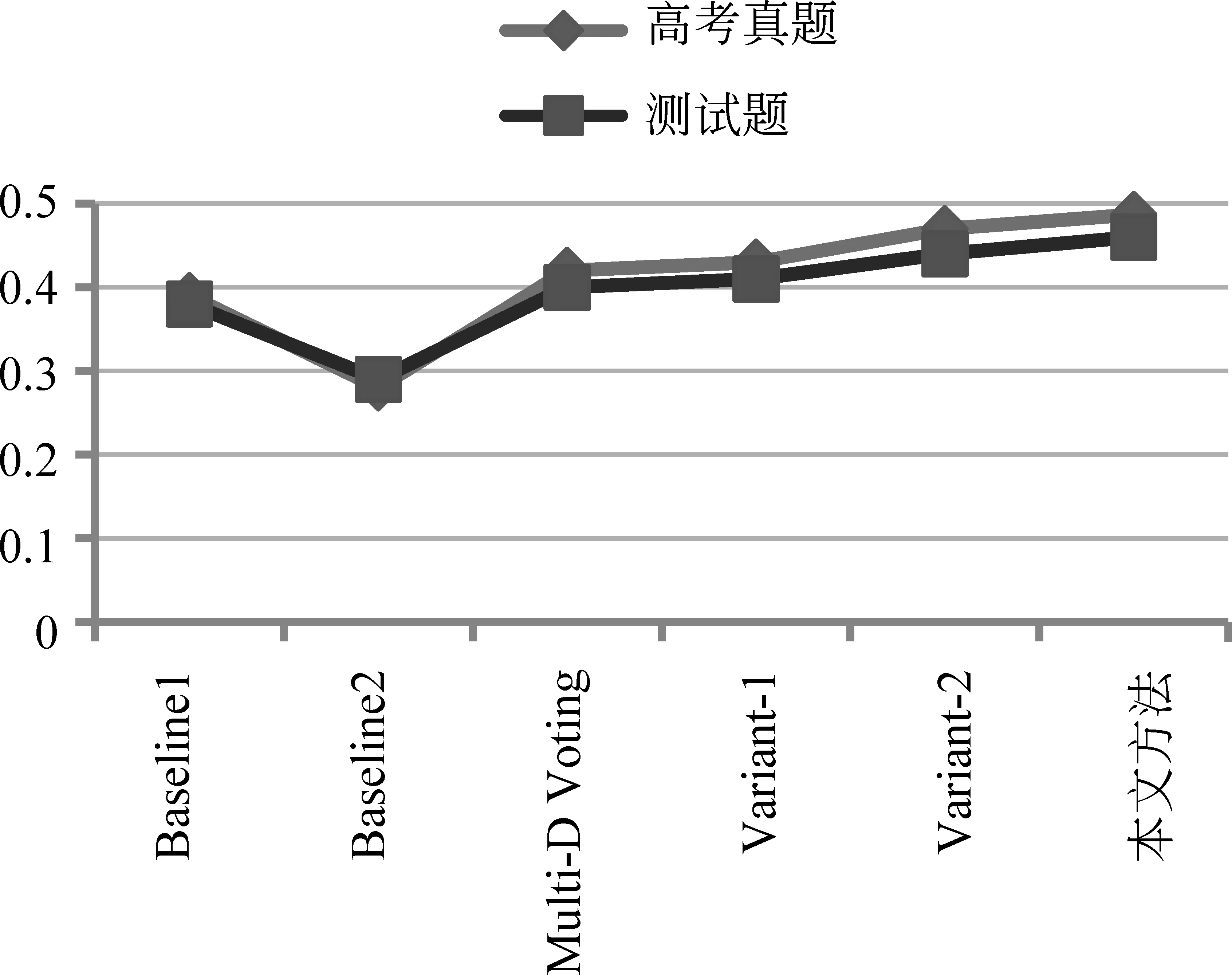
IFA* A*=A ENDIF ENDFOR 返回A* 实验所使用的语料包括5 872套高考模拟题(包含23 428个段落)和216套高考题(包含864个段落)。其中,训练语料为5 872套高考模拟题,测试集包括18道高考真题和134道测试题。测试题语料的篇章为有标题的高考科技文,选项正例为文章标题,负例由三名同学分别为文章拟写一个标题构成。测试题样例如表3所示。实验所用的高考题及高考模拟题语料均由山西大学中文信息处理课题组收集。本文使用哈尔滨工业大学社会计算与信息检索研究中心的语言处理集成平台LTP[26]对篇章文本进行分词、词性标注。 为了验证标题与篇章要点相关性模型的有效性,实验设置了较为常用的比较方法,包括: a) 基于词匹配的方法(Baseline1): 针对阅读理解问题,该方法通过计算每个选项和候选句的相似度来实现答案选取的功能。首先抽取文章中每段的首句作为候选句,并且对每个选项提取关键词,利用预先训练好的词向量计算每个选项和候选句的相似度,最后选取相似度值最高的一项作为正确答案。 表3 测试题样例 b) 卷积神经网络框架[21](Baseline2): 针对非事实类的问答任务,作者基于CNN提出了六种框架。使用第二个框架做对比实验,该框架使用CNN来学习问题和答案的向量表示,然后用余弦相似度对答案进行排序。 c) 基于多维度投票的算法(Multi-Dimension Voting): 针对高考语文阅读理解文意理解类题型进行分析,提出一种多维度投票算法。该算法将Word2Vec、HowNet、词袋模型、框架语义场景四个方面作为度量标准,运用投票算法的思想,计算相关句子与选项之间的语义相关性。 主旨句的抽取分别在高考真题、测试题和高考模拟题上进行了实验。通过实验对比分析式(7)中参数σ1、σ2、σ3分别设置为{0.52,0.32,0.16},实验结果如表4所示。抽取段落主旨句的评价标准,使用抽取精度表示,如式(15)所示。 (15) 其中,Ptopic表示准确率,s表示抽取正确的主旨句个数,t表示总主旨句个数。 表4 主旨句抽取结果 从表4可以看出,主旨句抽取准确率最高的是高考真题,准确率达到了85.3%,最低的是高考模拟题。追踪实验数据,发现影响抽取准确率的一个因素。本文对每个段落都抽取了主旨句,实际上有些段落的主旨句不明显,其主旨句是由两句话组成,或者该段落的主旨句需要总结概括,不能直接抽取句子作为主旨句。 参数选择。为了确定式(13)中φ的取值,本文在134道测试题上用不同的φ取值做实验,选取最优的参数取值,实验结果如图3所示。 图3 不同权重φ下融合方法的准确率 其中,横坐标为权重φ的取值,纵坐标为实验结果。可看出在φ值为 0.4 时,准确率最高,后续实验中φ取值均为0.4。 为了更好地对比本文的方法,对本文方法做了两个变式。 Variant-1: LSTM拥有记忆功能,能够捕捉文章上下文信息,可以解决序列问题,该方法把文章每个段落整段作为基于LSTM的选项与篇章要点相关性计算方法的输入,而不是先抽取段落主旨句作为输入(图2)。 Variant-2: 该方法在本文方法的基础上去除标题结构分析部分,来验证篇章标题结构分析对实验结果的影响。 为了统计准确答案处于候选项中第一或是第二位置的结果,使用Top-k的准确率P来评价答题结果[27],如式(16)所示。 (16) CorrectAnswer(k)表示针对测试语料题目中前k个结果中正确的答案个数。 表5为18道高考真题测试的准确率,表6为134道测试题测试的准确率。其中,Top-1的准确率表示解题正确的概率,Top-2表示在四个选项中正确答案排在前两位的概率。 表5 测试语料为高考真题的准确率 从表5可以看出,在Top-1、Top-2准确率上,本文方法准确率都是最好的。其中,Top-1准确率达到了0.487。从Top-2准确率可以看出正确选项位于前二位的概率达到了0.76。 表6 测试语料为测试题的准确率 从表6可以看出,在Top-1、Top-2准确率上,本文方法准确率都是最高的。其中,高考题Top-1准确率达到了0.487,测试题Top-1准确率达到了0.46。 从表5、表6可以看出,本文方法Top-1准确率在不同的数据集上均比其他方法高。但高考真题的准确率比测试题的准确率高了2.7%。研究实验结果后发现,主旨句的抽取准确率会对实验结果产生影响。测试题中主旨句的抽取准确率为83.7%,由于测试题选项为人工出的,故没有高考真题规范。 从表5、表6可以看出,在不同的数据集上本文方法准确率都是最高的。通过Variant-1和本文方法对比,可以发现本文抽取段落主旨句作为篇章要点输入比整个段落输入实验效果好。通过Variant-2和本文方法的对比,可以发现当加入了标题结构权值信息之后,模型的准确率有了提升。这说明本文提出的抽取段落主旨句作为篇章要点和融合标题结构信息的方法是有效的。 从表5 、表6还可以看出,Multi-Dimension Voting方法结果与Variant-1结果相近,没有本文方法结果好。研究实验数据后发现一个最主要的原因是,Multi-Dimension Voting方法针对的是高考语文阅读理解文意理解类题型。该类题目的题干中包含文章内容信息量大,且解题需要的信息只与文章中某个片段信息相关。而标题选择类题目的解答需要对整个篇章内容进行理解概括,分析标题与篇章内容的相关性。 从表5 、表6以可以看出,在不同的数据集不同方法中Top-2的准确率均大于Top-1的准确率。Top-2的准确率在高考题上最高,达到了0.76,在测试题上本文方法的Top-2准确率也达到了0.71,这说明在四个候选项中本文方法可以很好地去除两个干扰项的影响。 从图4可以看出,在不同方法上高考真题的准确率都高于测试题的准确率(除了Baseline高考真题的准确率比测试题的低了1%)。这是由于本文方法主要是针对高考题,且高考真题比较规范。从图4中可以看出在不同数据集上本文方法的准确率都是最高的,从而验证了本文方法的有效性。 图4 不同方法Top-1准确率在两个测试集上的对比 本文针对高考语文阅读理解篇章标题选择题目,提出标题与篇章要点相关性分析模型。根据标题高度凝练且能准确表达文意的特点,构建了基于标题与篇章要点的相关度矩阵。并在此基础上,依据标题结构鲜明的特点,对标题进行梳理和分类,融入标题结构特征,实现篇章标题选择题目的解答。实验结果表明,本文的方法与对比实验方法相比,在两个测试集上实验准确率都有所提升。 本文方法在高考真题上Top-2的准确率达到了0.76,下一步将分析总结选项位于第一位和第二位的特点,进一步提升Top-1准确率。同时,进一步搜集相关的语料,扩大语料规模,进一步提升模型的准确率和普适性。3 实验结果及分析
3.1 实验数据
3.2 Baseline

3.3 实验结果


4 总结与展望
