结合短语结构句法的语义角色标注
2018-07-18杨凤玲周俏丽蔡东风
杨凤玲,周俏丽,蔡东风,季 铎
(沈阳航空航天大学 人机智能研究中心,辽宁 沈阳 110136)
0 引言
浅层语义分析是近年来自然语言处理领域研究的热点之一,而语义角色标注是目前浅层语义分析所采用的主要形式。语义角色标注(Semantic Role Labeling,SRL)的主要任务是分析句子的“谓词—论元”结构,即给定一个句子,找出句子中谓词的相应语义角色成分,包括核心语义角色(如施事、受事等)和附属语义角色(如地点、时间、方式、原因等)[1]。SRL标注的语义角色对回答5W问题(who、what、when、where、why)提供了强有力的支持。例如,“He bought a bunch of roses yesterday at the Florist”,对谓词“bought”进行语义角色分析,其中,“He”是动作的发出者,即施事A0。“a bunch of roses”是动作的承受者,即受事A1。“yesterday”是动作发生的时间,即AM-TMP。“at the Florist”是动作发生的地点,即AM-LOC。SRL综合利用了底层的分词、词性标注、句法分析、命名实体识别等信息,作为自然语言理解的底层研究,在信息抽取、问答系统、指代消解、机器翻译等方面有着广泛的应用。
有关语义角色标注的研究最早由Daniel Gildea和Daniel Jurafsky[1]在2002年提出。他们在识别谓词和论元之间关系时利用了基于句法树的特征。迄今为止,大多数的语义角色标注方法很大程度上依赖于词汇和句法分析特征,Pradhan[2]等人的工作证实了句法分析功能的重要性。Johansson和Nugues[3]等人发现依存句法树能够为识别谓词的论元提供更好的表示形式。Palmer[4]等人利用人工标注的资源,如PropBank,提出基于特征的统计模型获得了比较高的准确率。目前语义角色标记方法都是在寻找合适的特征,而对于比较复杂的句子(含有并列结构、子句、从句等)仅仅依靠一些特征进行语义角色标注依然存在问题。
针对句子结构比较复杂的问题,本文提出结合短语结构句法树对句子进行处理,包括剪枝、子句抽取、论元边界修正。当句子中含有并列结构时,用并列结构中的第一个并列成分代替整个并列结构,将第二个并列成分剪枝。在对句子进行子句抽取时,引入了相容与不相容的概念。可以将语义角色之间的关系分为两类: ①论元相容: 两个语义角色同属于一个谓词; ②论元不相容: 两个语义角色分别属于不同的谓词[5]。对句子中的子句进行抽取时,子句中的论元与子句外的论元相对子句中的谓词是不相容的,因此,可以将子句作为一个语义角色分析的单元。通过剪枝和子句抽取简化了句子的复杂程度、缩短了句子的长度。当语义角色分析结束之后再结合短语树中短语的边界对论元的边界进行修正。
1 相关工作
目前,在英文中短语句法分析技术相对成熟,已经取得了较好的结果,因此很多研究者在短语句法树的基础上研究语义角色标注也取得了比较好的结果。
在语义角色标注中,最早进行研究的Gildea和Jurafsky等人[5]提出利用机器学习的方法对语义角色进行自动标注,使用了语义角色标注系统最常使用的七个特征。其中,在识别谓词和论元之间关系时用到了句法树的特征。在此基础之上,Gildea和Palmer等人[4]进一步在PropBank语料库上做了同样的实验,基于手工标注的短语句法树,使F值有了进一步的提升。随后,有很多人尝试使用不同的标注单元、特征、分类器、机器学习等方法加以改进。Xue和Palmer等人[5]提出在单一短语结构句法树的基础上,验证了Gildea的七个基本特征在SRL各个阶段的贡献,提出了新的特征,并基于手工标注的短语结构句法树,使F值又进一步提升。刘挺和车万翔等人[6]选取了较多的特征,先使用最大熵分类器将识别和分类做进一步训练。然后再做相关的后处理。该方法虽然在单一自动短语结构句法分析上取得了比较好的结果,但并未详细给出性能提升的具体原因。Moschitti等人[7]引入不同类型的树核捕捉句法树的结构相似度,该方法在自动特征学习方面很有吸引力,但也会带来较高的计算成本。Boxwell 等人[8]提出了一种基于丰富特征的SRL方法,结合了组合范畴、短语结构和依存三种句法分析的特征。但多种句法分析特征在带来了丰富信息的同时,也带来了较大的噪声。李世奇等人[9]提出基于短语结构句法分析的语义角色标注,即以句法为语义角色标注的单元,分为两个子任务: 一是语义角色识别,目标是从句子中抽取所有可以充当语义角色的句法成分;二是语义角色分类,判断语义角色识别阶段所得的语义角色的类型。可是,对于比较复杂的句子处理并未得到好的效果。以上的分析方法结合短语结构树进行语义角色标注时,并未对句子进行简化,而是仅仅将短语结构树作为一种特征。
以句法成分为标注单元的论元标注需要一种简单的剪枝预处理方法,来过滤句法分析树中一些不可能成为论元的句法成分,保留尽量少的候选句法成分,以提高准确性。刘挺和车万翔等人[6]采用识别分类一步到位的方法对与谓词相关的全部句法成分进行训练和预测。虽去除了句法类型为词性的句法成分,但使得AM-MOD和AM-NEG等角色对句法树上的句法成分匹配率很低,还要进行后处理。Dan Roth和Wen-tau Yih等人[10]将语义角色标注分为四个阶段: 剪枝、论元识别、论元分类、推理。其中,剪枝阶段是根据短语结构句法树将不太可能作为谓词论元的候选集合进行去除,这会出现将一些论元错误判断为非论元的问题,使候选论元个数减少。Wang等人[11]在Xue和Palmer等人[5]的基础之上,提出基于中心词的剪枝算法。该算法选取当前谓词节点和其祖先节点的兄弟节点,以及这些兄弟节点的孩子节点作为候选论元角色,进一步扩大了候选论元集合。不过论元减少的问题依然存在。Lei Sha等人[12]利用二次优化的方法将论元之间的关系分为两类: 相容与不相容。若当两个论元属于同一个谓词时,则认为两个论元相容;若不属于同一个谓词,则认为两个论元是不相容的。这样做就可以对不是同一个谓词范围内的论元进行剪枝操作。Jiang Guo和Wanxiang Che等人[13]将SRL任务拆分成两个任务,即SRL用来描述论元与谓词之间的关系,另一类是判断两个实体之间的关系。文献[5-6,10-13]结合短语结构句法树对句子进行剪枝操作实现句子简化,但并未对句子的类型进行总结归类,对句子的简化程度并不充分。
与先前的工作相比,本文提出结合短语结构树对句子进行剪枝、子句抽取、论元边界修正的方法。当句子中含有并列结构时,将并列中的第一个并列成分代替整个并列结构,即将第二个并列成分进行剪枝。当句子中含有子句时针对不同的子句采取不同的处理方式,这样做的结果简化了句子的复杂程度、缩短了句子的长度。将处理过后的句子进行语义角色的分析,对最终的分析结果结合短语树的结果进行论元边界修正。本文提出的方法对复杂句子结构的语义角色识别会有更好的效果。
2 结合短语结构句法的语义角色标注
本文结合短语结构句法对句子进行语义角色标注,对给定的句子先进行短语结构分析,基于短语树对句子进行剪枝、子句抽取,从而缩短句子的长度、简化句子的复杂程度。再将处理过后的句子进行语义角色的分析,再用最终的分析结果再结合短语树的结果进行论元边界修正。
2.1 短语结构句法树
短语结构句法树指将句子的短语结构句法分析的结果以树形结构输出,即对每一个输入的句子通过构造短语树来完成对它的分析。短语树不仅可以表示出句子的语法关系,也可以表示出句子的层次,如图1所示。
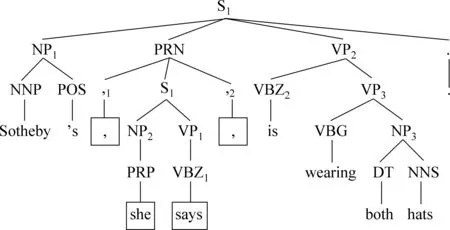
图1 短语结构句法树
从短语结构树中可以分析出一些短语结构,比如标记为NP[1]表示的是名词短语。在树中,当两个短语最近的父亲节点是同一个时,称两个短语为同一层的短语。如NP1与PRN最近的父亲节点都是S节点,二者则为同一层的短语结构。除此之外,短语结构树还可以分析出并列结构(CC)、从句(SBAR)、插入语(PRN)、子句(S)等信息。
基于短语结构句法树,可以对一些可以去除的部分进行剪枝操作。根据不同的子句形式、论元是否相容,从短语树中分析出语义角色分析单元,还可以针对某些论元在短语树中是否为一个完整的短语对论元边界进行修正等等。结合短语句法树,本文对句子进行以下处理: 剪枝、子句抽取,对论元的边界进行修正。
2.2 剪枝
对句子进行剪枝操作包括插入语以及并列结构剪枝两种情况。插入语在句子中属于独立语,将其去掉可以使句子得到简化。并列结构中的并列成分在句子中的重要性是一致的,可以将并列中的第一个并列成分保留,其他的并列成分剪枝,剪枝过后句子同样得到简化。
2.2.1插入语
在句子中间插入一个成分,它既不是句子的成分,也不和句子的其他成分发生结构关系,称之为插入语,其属于独立语。给定一个句子,先进行短语结构分析,在短语结构中标记为PRN的部分为插入语。但当句子中含有括号的时候,虽括号中的部分在短语结构树中标记的不是PRN,但属于插入语的范畴。
当句子含有插入语时,则将插入语剪枝,剪枝剩下的部分合并在一起作为语义角色分析单元。若插入语中含有谓词,对插入语未剪枝之前的句子进行语义角色的分析,此时对插入语中的谓词以及相关论元进行保留。
图1中,未对句子做任何处理之前,先对整个句子进行语义角色的分析,此时插入语“,she says,”中的谓词says的语义角色被分析出来。图1中方框部分为减枝去除的部分,将插入语剪枝剩下的Sotheby’s is wearing both hats.单独作为语义角色分析单元进行分析,分析出的谓词以及相关的论元与插入语中的谓词以及相关的论元合并在一起作为整句话的语义角色分析的结果。对于含括号的插入语同样处理。
2.2.2并列结构
如果相同的两个成分所传递的信息在重要性上基本相等,且一前一后排列起来,或者用并列连词连接起来,称之为并列结构。本文主要处理的并列结构有名词短语并列、介词短语并列、子句并列、从句并列。
结合短语结构树对并列结构进行判断分为有标记以及无标记两种识别方法,对于无标记的并列结构主要处理名词短语并列。在短语树中,若两个名词短语是兄弟的关系,则为并列结构。对于有标记的并列结构包括名词短语并列、介词短语并列、从句并列、子句并列。在短语树中,两个相同成分在树中是兄弟关系且两者之间标记为CC,则两个成分并列。对于并列结构的处理方式分为两种处理方式: ①子句并列: 对并列的各个子句分别进行语义角色分析; ②其他并列: 采取剪枝的方式进行语义角色的分析。
(1) 子句并列
当树中含有S CC S的结构,则称两个子句S并列。将两个子句分别进行语义角色分析,将分析结果合并在一起作为整句话的分析结果。
例1[S After the trading halt in the S&P 500 pit in Chicago,waves of selling continued to hit stocks themselves on the Big Board],[CC and] [S specialists continued to notch prices down ] .
例1中句子是由两个并列子句组成,CC为并列标记,两个子句中的谓词的论元是不相容的,所以可以分别进行语义角色的分析,则例1分成两个语义角色分析单元:
单元1After the trading halt in the S&P 500 pit in Chicago,waves of selling continued to hit stocks themselves on the Big Board
单元2specialists continued to notch pricesdown
(2) 其他并列
除子句并列,还有名词短语并列、介词短语并列、从句并列。对于名词短语并列的判断分为两类,一类含有并列标记,一类不含有并列标记。当判断两个名词短语是并列结构时,将第一个名词短语保留,其他的进行剪枝。
例2Benchmark grades sold for [NP [NP as much as 50 cents ] [NP a pound ]] last spring,have skidded to between [NP [NP 35 cents][CC and ] [NP 40 cents]] .
例2中,第一个并列的名词短语为[NP [NP as much as 50 cents ] [NP a pound ]],[NP as much as 50 cents ]与[NP a pound ]在树中为兄弟节点关系,为并列结构,将[NP as much as 50 cents ]保留,将 [NP a pound ]剪枝。第二个并列的名词短语为[NP [NP 35 cents][CC and ] [NP 40 cents]],含有并列标记CC,同理将[NP 35 cents]保留,将[NP 40 cents]剪枝。则语义角色分析单元为: Benchmark grades sold for as much as 50 cents last spring,have skidded to between 35 cents .
对于介词并列、从句并列与名词短语并列同样的处理方式。剪枝的部分不单独进行分析,在还原时,剪枝的部分与其并列结构属于同一个语义角色。
2.3 子句抽取
给定一个句子,先进行短语结构分析,当短语树中的成分标记为S时,则该成分称之为子句。结合短语树对子句抽取,不仅将抽取出的子句进行分析,而且将子句抽取之后剩下的部分同样进行分析。根据不同的子句采用不同的处理方式,如图2所示。
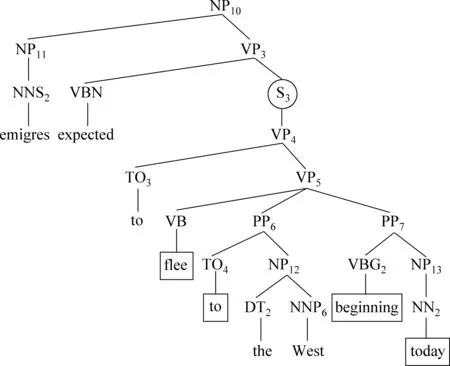
图2 短语结构句法部分树
在图2中子句S3的第一个词标记为TO,且子句包含在动词短语VP中。此时,S3为不定式结构,名词短语emigres是S3中谓词flee的一个论元。针对该类型的子句,从中抽取的语义角色分析单元为emigres flee to the West beginning today。图2方框中的部分是子句处理过后需要去除的部分,不含有方框的部分是保留的部分,则子句抽取过后的子句变成emigres expected to the West。
子句S开始的第一个词语为TO,且子句向上搜索的第一个短语为动词短语VP时,则语义角色分析单元为与S最相近的NP短语以及去掉TO的子句S。
本文关于子句类型从英文的句子结构出发总结如图3所示。
英语语法是英语语法系统地总结归纳出来的一系列语言规则,这些语法现象在英语语料中是普遍存在的。在图3(a)中称作为动词不定式,(b)(c)(d)(e)称作由关系词引导的不同形式的从句,(f)(g)为省略引导词的从句,不同的从句在句子中充当不同的成分。图3句子形式的语义角色的分析单元如表1所示。
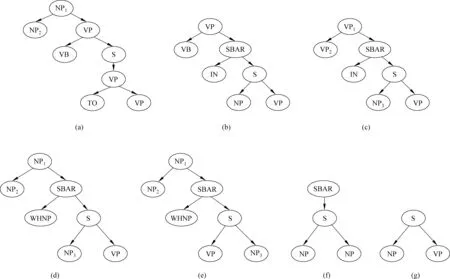
图3 子句结构形式

编号子句类型子句抽取规则aNP1-->NP2+(VP-->VB+(S-->(VP-->TO+VP)))NP2+S去掉TObVP-->VB+(SBAR-->IN+(S-->NP+VP))S-->NP+VPcNP1-->NP2+(SBAR-->IN+(S-->NP3+VP))NP1-->NP2+(SBAR-->IN+(S-->NP3+VP))dNP1-->NP2+(SBAR-->WHNP+(S-->NP3+VP))NP1-->NP2+(SBAR-->WHNP+(S-->NP3+VP)eNP1-->NP2+(SBAR-->WHNP+(S-->VP+NP3))NP1-->NP2+(SBAR-->WHNP+(S-->VP+NP3))fSBAR-->S-->NP+VPS-->NP+VPgS-->NP+VP,S不在SBAR中S-->NP+VP
其中“+”表示左右节点为兄弟节点,“-->”表示右边的节点是左边节点的孩子节点,“()”表示括号中第一个节点含有孩子节点。
对于表1中编号a、b、f、g句子结构,当子句抽取结束之后,用子句S中的NP短语替换子句语义角色分析单元放回到原句。对于表1中编号c、d、e
句子结构,用NP2替换子句语义角色分析单元放回到原句。当原始句子中所有的子句都用相对应的NP短语替换之后,对替换后的原句进行语义角色的分析,最后将子句分析的语义角色以及原句分析的语义角色合并在一起作为整句话的语义角色。
2.4 边界修正
从短语树中可以分析出名词短语NP、介词短语PP、子句S、从句SBAR等模块,这些模块可以单独作为语义角色。本文所使用的SRL工具[14]存在论元边界识别错误的现象,但结合短语树可以对论元边界进行修正。通过大量的错误实例分析发现A0、A1、AM-MOD以及谓词的边界最容易出现问题,本文主要针对这几个语义角色进行论元边界的修正。
短语树中的NP、S可以作为A0、A1,而现有的SRL工具在A0、A1末尾的标点符号是否是语义角色的一部分出现问题。结合短语树,若在短语结构树中,被识别成的A0、A1在树中是一个完整的NP或S,则论元不进行修正。若不是一个完整的NP或S,则对末尾的标点符号进行去除。
AM-MOD在短语树中对应的部分是MD,若识别出的结果在短语树对应的部分超出MD的范围,则对其进行修正。
现有的SRL工具,识别出的谓词都是单独的一个词语。而在实际的句子中,动词词组也可以作为一个谓词,如sits down。针对这种错误现象,结合短语结构树,判断谓词后面的第一个词是否标记为PRT。若是,则与动词合并在一起作为一个谓词。
图4中谓词sits后面的第一个词语down在短语树中标记为PRT,则将sits down词组作为谓词处理。

图4 短语结构句法树
3 实验结果及分析
3.1 实验数据
本文的实验数据来自于CoNLL-2005和CoNLL-2004 Share Task评测语料,其中CoNLL-2005选用test_wsj以及test_brown,CoNLL-2004选用测试集以及开发集。
对句子进行子句以及含有并列结构的句子数(名词短语并列、介词短语并列、从句并列)的统计,结果如表2所示。由统计结果可知各个语料中含有子句的句子数在各自的语料中占据一半以上,因此对子句进行分类处理可以有效提升论元识别准确率。

表2 各个语料子句数量情况
根据表1中子句主要的几种形式统计如表3所示。

表3 针对2005、2004年语料统计结果
3.2 实验流程
本文对句子进行短语结构分析采用伯克利短语结构工具*http://nlp.cs.berkeley.edu/software.shtml,F值为95.66%[22],对语义角色标注使用的是最新的基于神经网络的工具*http://homepages.inf.ed.ac.uk/mroth/demo.html。本文的系统结构图如图5所示。

图5 系统结构图
当系统输入一个句子时,对句子进行短语分析,将分析过后的结果进行剪枝、子句抽取等简化操作。将简化过后的句子的多个语义角色分析单元进行语义角色的分析,将语义角色的分析结果进行还原。将还原过后的语义角色结合短语树对句子进行论元边界修正,最终输出句子的语义角色分析结果。
3.3 实验结果及分析
3.3.1语义角色整体识别结果
本文总结如下规则进行实验,每类规则的具体内容如表4所示。

表4 规则表
给定一个句子,除了并列结构、子句、插入语之外,句子中还含有其他成分。所以rule9主要是针对其他规则处理之后句子剩下的部分进行语义角色分析。
针对各个规则分别在CoNLL2005wsj和brown以及CoNLL2004test以及dev上进行了实验,具体的实验结果如表5所示。由表中的实验结果可以看出每一个测试数据在加入九类规则之后,F值都有所提升。
表5中的baseline实验是用2016年Roth[14]基于神经网络训练的语义角色标注的模型,本文使用现有的语义角色模型测试出来的结果作为baseline实验。本文方法与baseline实验相比都有所提高,在CoNLL2005 Shared Task的wsj数据集F值提升了3.24%,brown数据集提升了2.86%,在CoNLL2004 Shared Task的test数据集提升了3.64%,dev数据集提升了2.87%。在四个语料中,加入rule9时,提升的效果最多。在wsj、brown、test、dev语料中,提升最少的规则分别是rule4-1、rule1、rule2-1、rule2-1。由表5同样可以得出,各个规则的准确率、召回率都有所提升。
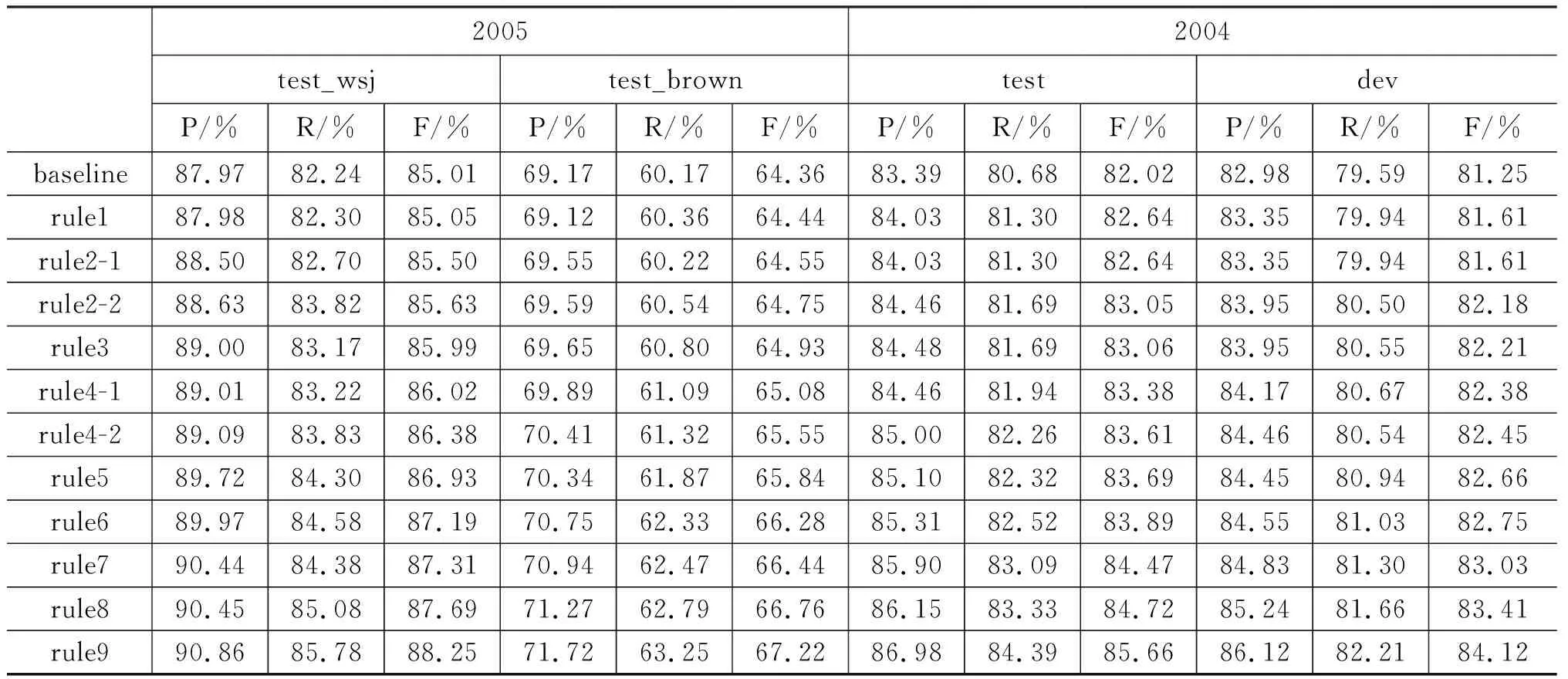
表5 各个规则的测试结果
各个系统对比实验如表6所示。
Zhou Jie[15]等人在2015年发表的论文采用端到端的神经网络模型,仅仅用到词、词性、当前词的上下文信息,并未用到句法、语义等信息,未能很好的挖掘句子的信息。Koomen[16]等人采用四阶段的方法识别语义角色: 剪枝、论元识别、论元分类、推理。四个阶段存在前后顺序关系,若剪枝出现错误会导致下一阶段论元识别的准确率下降,因此该方法存在不可避免的级联错误。Koomen所采用的剪枝策略是对论元边界的判断,对原始句子未做修改,而本文的剪枝是对短语结构中特定的结构进行去除操作,对原始句子进行了缩短处理、简化。Surdeanu[17]等人的方法与Koomen的方法类似,同样会出现错误级联问题。Toutanova[18]等人用到了句法信息来提高语义角色识别效果,但是句法本身识别的效果有待提高,论文中也提到了可以通过提高句法分析的效果来提升语义角色识别的效果。因此语义角色识别的效果受到句法分析的效果的制约,同理Pradhan[2]等人的方法出现同样的问题。
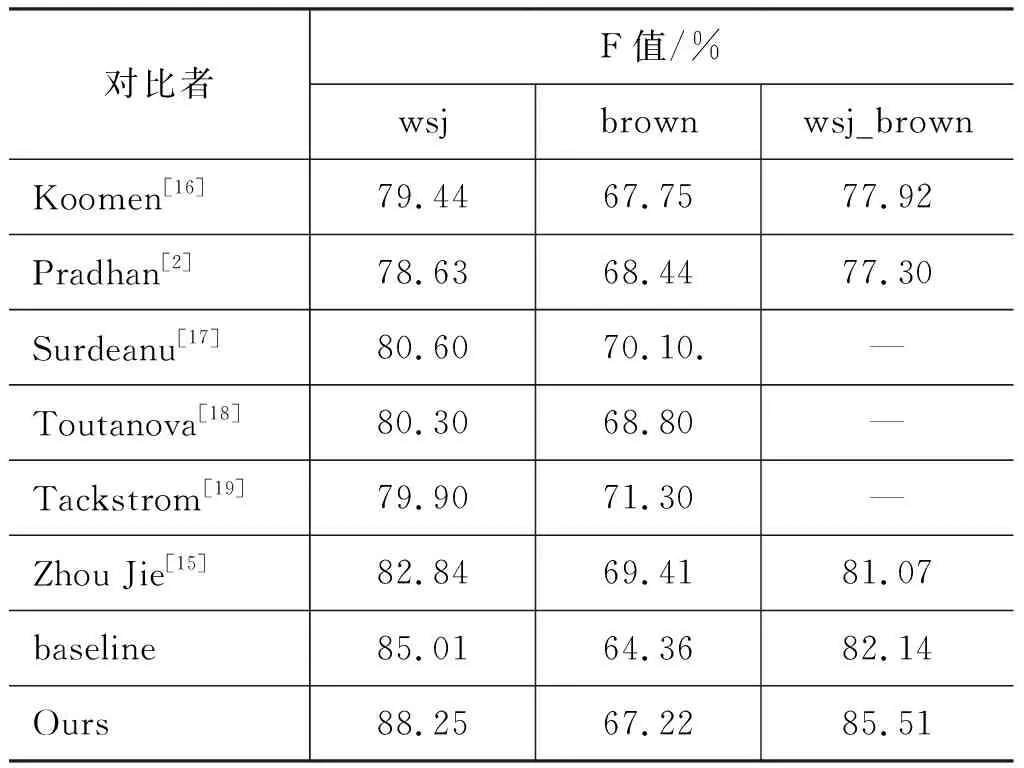
表6 各个系统对比实验
从表6中可以看出在wsj数据集上,本文的方法达到最好,但在brown并未达到最好。主要原因在于baseline结果相对较低,而baseline实验是用2016年Roth[14]基于神经网络训练的语义角色标注的模型,使用现有的语义角色模型测试出来的结果作为本文的baseline实验。与baseline实验相比,wsj的F值提升3.24%,brown的F值提升2.86%。本文的方法主要是针对比较长且复杂的句子进行了简化,据统计知wsj句子的平均长度为23.462,而brown数据集句子的平均长度为16.815,两个数据集平均句子长度相差6.647,所以在wsj上提升的效果相对brown较好。除此之外,从本文的表2可以看出,在brown语料中,含有子句以及并列结构的句子占68.08%左右,而在wsj语料中达到79.88%左右,也是brown语料F值偏低的原因之一。当两个数据集合并在一起时,本文的F值达到了最好。
为了说明本文的方法与所选用的语义角色标注模型无关,本文采用了另外一个语义角色标注模型(LTH*http://barbar.cs.lth.se:8081/parse)在CONLL-2005 test_brown语料上做对比实验,实验结果如表7所示。

表7 本文方法在不同模型上的实验
从表7中知本文的方法在LTH语义角色标注模型上F值有所提高,从而说明本文的方法在其它语义角色标注模型中同样有效,不仅仅针对本文所选取的模型有效。
在CoNLL-2005官网当年的评测F值排名前10的结果如表8*http://www.cs.upc.edu/~srlconll/st05/st05.html所示。

表8 CoNLL-2005评测结果
从表8中可以看出,在CoNLL-2005当年的评测结果当中,语料wsj的F值都要比brown的F值高出10%左右,结合表6可以得出各个系统在brown上的F值普遍低于wsj上的F值。从另一个方面可以说明本文在brown的实验结果F值偏低与语料brown有关,而与所选用的模型没有必然的联系,更与本文的方法没有关系。
本文方法主要目的是将较复杂的句子进行简化。其中,子句抽取部分是依据英语本身的语法特点进行处理的。通过不同形式的子句处理,可以将句子以动词为单位进行简化。例如: The decision,reported by the official Xinhua News Agency,indicated that the crackdown prompted by student-led pro-democracy protests in June is intensifying.
在图6中,子句S2中动词prompted的施事A0为the crackdown。若将整句话直接进行语义角色的分析,则错误的将The decision分析成该动词的施事A0。根据本文的子句抽取规则,将子句S2直接作为语义角色分析单元,将动词prompted的语义角色分析单元进行了简化,则可以正确识别。

图6 含有子句的短语结构部分树
3.3.2单个语义角色识别结果
各个语义角色对比实验如表9所示。
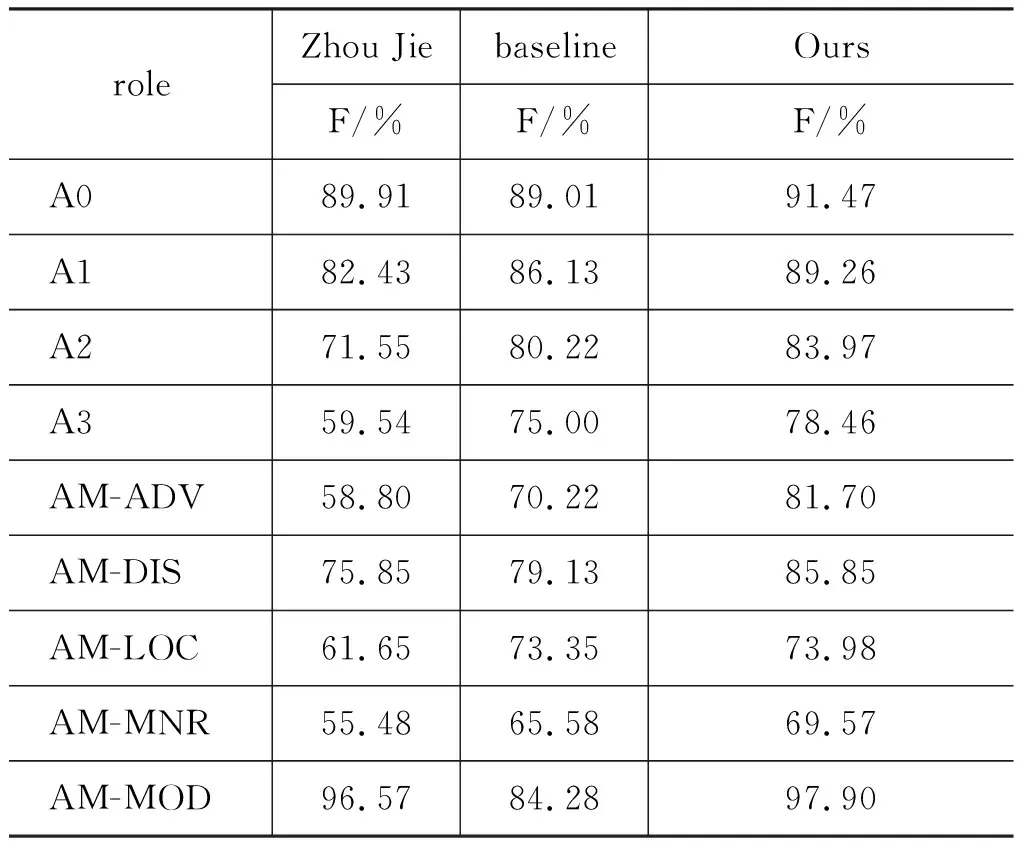
表9 各个语义角色识别结果对比

续表
表9中各个语义角色识别的正确率、召回率、F值与本文的baseline实验以及Zhou Jie等人[15]的结果对比表明,只有R-A0的F值比Zhou Jie等人的实验结果差。但与baseline实验相比,本文的方法在所有的语义角色中都有所提升。其中AM-MOD的F值提升最多,本文针对该语义角色进行了单独的修正,所以提升比较多。表格中还可以得知论元AM-TMP的F值提升的最少。
3.3.3谓词识别结果
关于谓词识别结果如表10所示。

表10 CoNLL2005、CoNLL2004动词识别结果对比
表10是在baseline实验的基础之上,针对rule1进行验证该规则的有效性。在wsj、brown、test、dev四个数据集上谓词的F值分别提升了1.68%、0.50%、0.30%、0.17%,由此可见,rule1对于谓词的识别可以取得有效的结果。
4 结论
本文提出了一种基于短语结构树的语义角色识别方法。该方法能有效的对句子结构进行简化,简化方法有剪枝、子句抽取。其中,剪枝包括并列结构以及插入语的剪枝,子句抽取针对不同形式的子句有不同的处理方式。结合短语结构树还进行了论元边界修正。本文分别在CoNLL2004与CoNLL2005评测语料中做了实验,F值与baseline实验相比都有所提高。在CoNLL2004的test数据集F值提升了3.64%,dev数据集F值提升了2.87%,在CoNLL2005的test_wsj数据集F值提升了3.24%,test_brown数据集F值提升了2.86%。实验结果表明,引入短语结构句法树能有效的提升语义角色的识别效果。但本文对于子句的抽取处理还不是太充分,如以介词短语开头的子句S未做处理。对并列结构的处理仅仅处理类似名词短语这样的并列结构,对于动词短语的并列未做处理。今后,将进一步研究如何结合短语树处理这些未处理的部分,从而提高语义角色标注的准确率。另外,本文是针对英文语料进行做的实验。其中,短语结构是自动识别的。而英文的短语结构识别准确率比中文效果好很多。因此,本文的方法若在中文语料中做实验,需要做进一步的处理工作。
