GA-BP与BP神经网络在医学研究中的应用与比较
2018-07-16张怡君左颖婷刘近春姜丽君张岩波郭东星
张怡君 左颖婷 刘近春 姜丽君 李 金 张岩波 郭东星△
【提 要】 目的 将BP神经网络和GA-BP神经网络模型引入到肝硬化病例资料中,对肝硬化分期诊断的分类进行预测分析,比较两种分类方法的预测性能。方法 根据肝硬化患者病例资料,进行BP神经网络和GA-BP神经网络模型的建模和预测。结果 BP神经网络的ACC为67.50%,GA-BP神经网络的ACC为92.50%,GA-BP神经网络的TPR、TNR、PV+、PV-、AUC四个指标均高于BP神经网络,且建模时间大大缩短。结论 GA-BP神经网络可以提高分类预测效果,具有对肝硬化分期分类预测的可行性。
人工神经网络(artificial neural network)是一种类似人类神经系统的信息处理技术,模仿生物神经网络用于处理数据的数学模型[1-3]。BP(back propagation)神经网络是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一[4]。BP神经网络模型对自变量类型的要求不高,可以是连续的,也可以是离散的,对自变量是否满足正态性及相互独立等条件不需要考虑,对变量间复杂的非线性关系有较好的识别能力[5]。但存在收敛时间过长、稳健性差、易陷入局部极小值等不足[6]。
遗传算法(genetic algorithm,GA) 起源于对生物系统进行的计算机模拟研究,是一种基于生物遗传和进化机制的适合于复杂系统优化的自适应概率优化技术。遗传算法具有优化模型参数或结构、采用全局搜索、强大的可扩展性和包容性等优点,可以同许多技术联合使用。
将遗传算法与神经网络相结合,可以避免神经网络易陷入局部极小、易出现过拟合现象、泛化能力差等问题。遗传算法不仅能发挥神经网络的泛化的映射能力,而且能使神经网络具有很快的收敛性和较强的学习能力[7]。GA-BP神经网络模型是近年来常用的预测模型,集中了遗传算法以及神经网络模型的优点,较单一神经网络模型的预测结果更佳。
对象和方法
1.研究对象
本研究采用回顾性流行病学调查方法,调查对象为2006年1月到2015年12月间山西医科大学第一附属医院消化内科的肝硬化患者。通过对患者病历的查阅,筛选出符合标准的病历。入选标准:病历资料完整,有详细的基本信息、临床表现和实验室检查记录,必须有计算Child分级[8]的指标:是否腹水、白蛋白含量、总胆红素含量、是否并发肝性脑病和凝血酶原时间(区分肝硬化代偿期或失代偿期)。
调查开始前,对调查人员进行统一培训,学习了解病历资料的结构和内容。数据录入时采用双重录入的方式,确保录入数据的准确性。
2.方法
(1)神经网络
神经网络模型主要包括前馈神经网络和反馈神经网络两类。前馈神经网络,是指数据从输入层通过隐含层到达输出层,信号只向前传播,如图1所示。反馈神经网络,则是数据是从输入层通过隐含层到达输出层,输出值又反向传播回输入层,直到网络稳定,如图2所示。
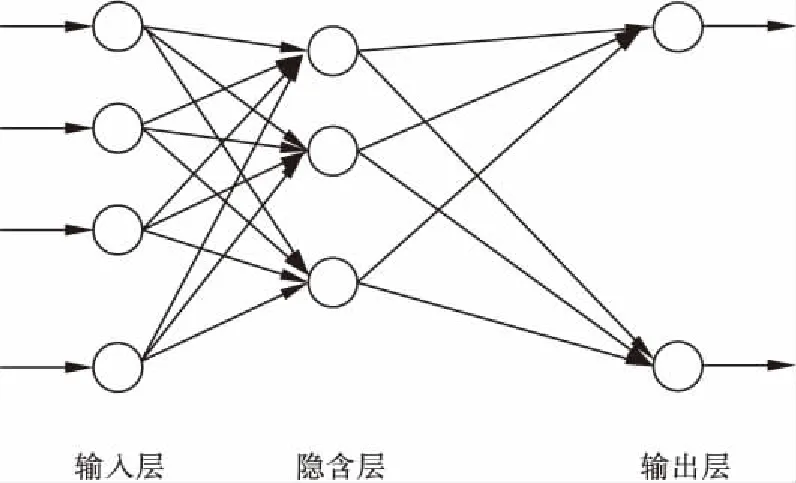
图1 前馈神经网络结构
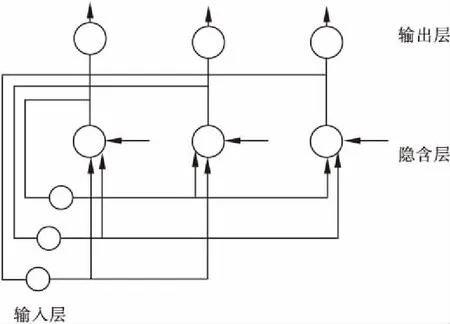
图2 反馈神经网络结构
①BP神经网络
BP神经网络是一种多层前馈神经网络,采用最速下降法的学习规则,其主要特点是信号前向传递,误差反向传播。在前向传递中,输入信号从输入层经隐含层逐层处理,直至输出层,每一层的神经元状态只影响下一层神经元状态。如果输出层得不到期望输出,则转入反向传播,根据预测误差调整网络权值和阈值,从而使BP神经网络预测输出不断逼近期望输出。
②BP神经网络的构建
BP神经网络为三层神经网络,输入层、隐含层、输出层。隐含层可以为一个也可以为多个,已有许多研究证明一个隐含层就可以满足对输入数据的非线性映射。
输入层节点数取决于自变量的个数。
隐含层节点数过多过少都会对网络的预测效果产生很大的影响,但目前对于网络的隐含层节点数没有一个确定的公式,只能通过经验公式做为初步估计,然后采用试凑法确定隐含层的节点数。公式如下:
H≤n-1;
H=log2n
其中,H是隐含层节点数目,n是输入层节点数目,m是输出层节点数目,a是[1,10]之间的数目。
输出层节点数一般通过实际问题得出,如分类预测时,分类为n个类别,则输出层节点数就为n个神经元。
(2)遗传算法
遗传算法模拟自然界遗传机制和生物进化论而成的一种并行随机搜索最优方法,按照选择的适应度函数并通过遗传中的选择、交叉和变异对个体进行筛选,使适应度好的个体被保留,适应度差的个体被淘汰,新的群体既继承了上一代的信息,又优于上一代。这样反复循环,直至满足条件。
遗传算法的基本操作:①选择,从群体中选出优良的个体,使他们有机会作为父代为下一代繁衍子孙;②交叉,将群体中的各个个体随机搭配成对,对每一个个体,以交叉概率交换它们之间的部分染色体;③变异,对种群的每一个个体,以变异概率改变某一个或多个基因座上的基因值为其他的等位基因。
遗传算法的基本计算流程如图3所示。
(3)GA-BP神经网络
GA-BP神经网络包括确定BP神经网络结构、遗传算法优化和BP神经网络预测三部分。根据输入输出参数个数确定BP神经网络结构,进而确定遗传算法个体的长度。遗传算法优化BP神经网络的权值和阈值时,种群中的每个个体都包含了一个网络的权值和阈值,个体通过适应度函数计算个体适应度值,并通过选择、交叉和变异操作找到最优适应度对应的个体。BP神经网络预测用最优个体对网络初始权值和阈值赋值,网络训练后输出分类预测结果。GA-BP神经网络算法流程如图4所示。
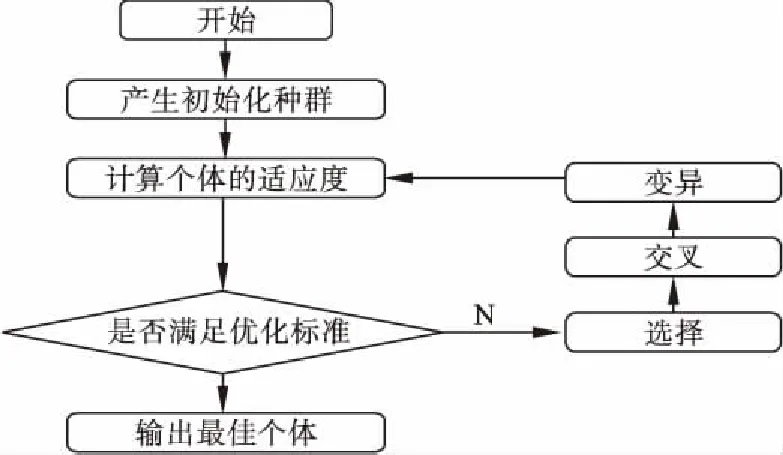
图3 遗传算法基本计算流程图
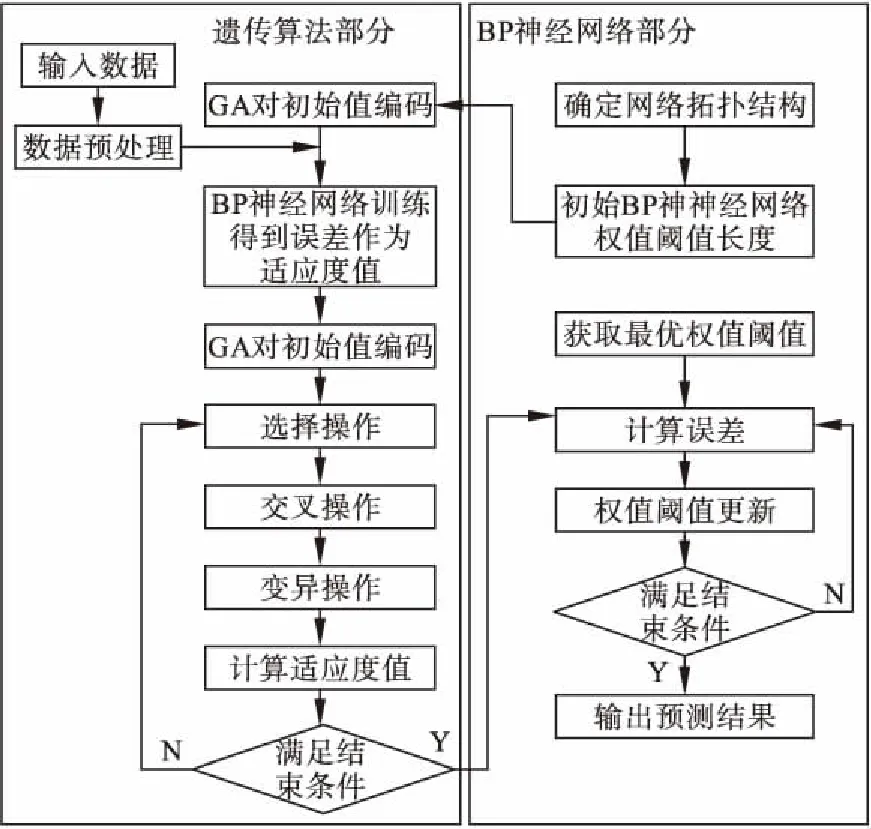
图4 GA-BP神经网络算法流程图
为了比较遗传算法优化BP神经网络前后的预测效果,先将全部自变量输入,建立BP神经网络模型;再将遗传优化提取的自变量作为输入,利用遗传算法对BP神经网络优化后重新建立模型进行测试。利用相同的测试集和训练集,对比分析预测效果。随机选取训练集和测试集,其比例为9:1,重复选择100次。
(4)分类预测的评价
常用的分类预测评价指标有准确率(accuracy,ACC)、真阳性率(true positive rate,TPR)、真阴性率(true negative rate,TNR)、阳性预测值(positive predictIve value,PV+)、阴性预测值(negative predictIve value,PV-)、ROC曲线下面积(the area under the curves,AUC)等。
结 果
1.调查对象基本情况
从1099份原始记录中选出符合标准的422份病例作为本研究的调查对象,具体筛选过程如图5所示。
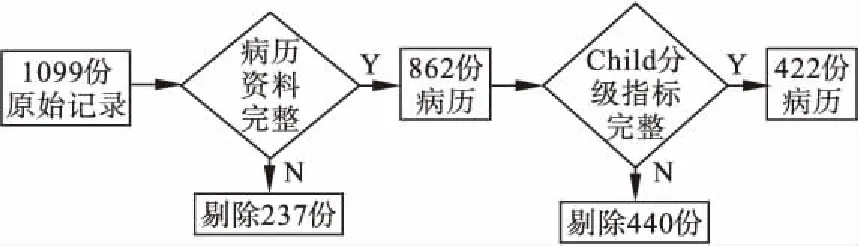
图5 样本筛选流程图
通过Child-Pugh分级[9]计算,其中82例代偿期患者,340例失代偿期患者。
(1)人口学特征分析
调查对象中男性223例,占52.8%,女性199例,占47.2%;调查对象的平均年龄(56.63±13.624)岁,最大年龄107岁,最小年龄17岁。
(2)综合因素描述
初步进行单因素χ2分析,将并发症、临床表现和既往史中P值在0.05附近的变量分别纳入到综合变量中,综合变量的取值为单个变量取值之和。见表1。

表1 综合变量描述
(3)实验室检查描述
实验室检查的统计描述见表2。

表2 实验室检查描述
2.BP神经网络和GA-BP神经网络模型结果
(1)隐含层节点数
BP神经网络的隐含层节点数对于BP神经网络预测效果有很大的影响:隐含层节点数过少,网络不能充分学习,网络的预测误差会加大;隐含层节点数太多,会使网络的训练时间延长,容易发生过拟合。所以本研究首先应该确定合适的隐含层节点数,采用的是试凑法,分别将BP神经网络和GA-BP神经网络在隐含层节点数[20,60]中取点,重复50次,分别记录BP神经网络的误差率和GA-BP神经网络的误差率,比较50次预测结果中位数,如图6所示。故本研究的隐含层节点数定为35。
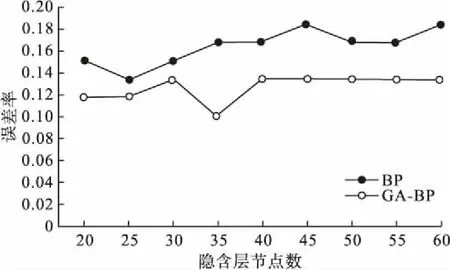
图6 隐含层节点数的确定
(2)BP、GA-BP神经网络模型结果
根据肝硬化数据输入输出特点确定BP神经网络的结构,输入变量38个,输出变量1个,所以BP神经网络的结构为38-35-1。BP神经网络参数配置:学习率为0.1,训练目标最小误差0.1。
GA-BP神经网络参数配置:染色体长度为38,种群大小设置为30。
随机选取测试集和训练集,重复选择100次,记录两个模型每次测试集的ACC、TPR、TNR、PV+、PV-、AUC,用中位数描述集中趋势,上、下四分位数(QL~QU)描述离散趋势,具体见表4。

表4 模型预测效果
从分类预测评价指标可以看出,GA-BP神经网络的分类效果较BP神经网络更优。
讨 论
肝硬化是肝脏疾病中常见的病变,肝硬化发展到失代偿期就到了比较严重的阶段,出现多种并发症,预后差,而且肝硬化发展到失代偿期病情不可逆,所以将病情控制在肝硬化失代偿期前对肝硬化的治疗、预后都有很重要的意义。本研究尝试通过统计方法,对肝硬化代偿期和失代偿期进行预测分类。
GA-BP神经网络利用了遗传算法的全局搜索且不易陷入局部极小值的优势,不仅对自变量进行优化,还对BP神经网络的权值和阈值进行优化,计算全局最优,弥补了BP神经网络易陷入局部极小、易出现过拟合现象、泛化能力差等缺陷。比较遗传算法优化前后的预测效果,结果显示优化后预测性能得到了改善和提升,且建模时间大大缩短,说明GA-BP神经网络模型的分类预测效果优于BP神经网络。
本文只研究了肝硬化分期,范围太小,研究的问题过于局限。由于肝硬化失代偿期和代偿期的分期诊断不是很明确,本文采用Child分级的方法,可能对预测结果有一定的影响。同时符合纳入标准的病例较少,抽样误差可能较大。对此,本研究拟继续收集病例,以增加研究样本量,下一步计划将肝硬化前期、肝硬化、肝癌做为分类结局,对其进行分类预测分析。
