Real-Time Visual Tracking with Compact Shape and Color Feature
2018-07-12ZhenguoGaoShixiongXiaYikunZhangRuiYaoJiaqiZhaoQiangNiuandHaifengJiang
Zhenguo Gao Shixiong Xia¹ Yikun Zhang¹ Rui Yao¹ Jiaqi Zhao¹ Qiang Niu¹and Haifeng Jiang
Abstract:The colour feature is often used in the object tracking. The tracking methods extract the colour features of the object and the background, and distinguish them by a classifier. However, these existing methods simply use the colour information of the target pixels and do not consider the shape feature of the target, so that the description capability of the feature is weak. Moreover, incorporating shape information often leads to large feature dimension, which is not conducive to real-time object tracking. Recently,the emergence of visual tracking methods based on deep learning has also greatly increased the demand for computing resources of the algorithm. In this paper, we propose a real-time visual tracking method with compact shape and colour feature, which forms low dimensional compact shape and colour feature by fusing the shape and colour characteristics of the candidate object region, and reduces the dimensionality of the combined feature through the Hash function. The structural classification function is trained and updated online with dynamic data flow for adapting to the new frames.Further, the classification and prediction of the object are carried out with structured classification function. The experimental results demonstrate that the proposed tracker performs superiorly against several state-of-the-art algorithms on the challenging benchmark dataset OTB-100 and OTB-13.
Keywords:Visual tracking, compact feature, colour feature, structural learning.
1 Introduction
As one of the basic topics in the field of computer vision, visual tracking aims to find and mark the position of the tracked object in each frame of video sequences. Visual tracking has important applications and very promising prospects in military guidance, video surveillance, medical diagnosis, product testing, virtual reality and many other fields[Ross, Lim, Lin et al. (2008); Mei and Ling (2010); Kwon and Lee (2010)]. Recently,great progress has been made in the research of visual tracking, and some achievements have been put into practical application. However, under the influence of factors such as deformation, light, fast motion, occlusion and complicated background, it is still achallenge to track the target efficiently in real-time.
A lot of work has been done on the task of visual tracking. Existing methods of tracking can be divided into three categories, namely, generating, discriminative and deep learning based methods. The generation method treats the tracking task as a template matching problem. The generate tracker searches for potential target locations that most closely resemble the appearance of the generated model. An object is usually represented as a set of base vectors in a series of templates or subspaces. In recent years, there are many generation-based visual tracking algorithms, frameworks and solutions proposed [Ross,Lim, Lin et al. (2008); Mei and Ling (2010); Kwon and Lee (2010); Li, Hu, Zhang et al.(2008); Liu, Huang, Yang et al. (2011); Xing, Gao, Li et al. (2013); Zhang, Zhang, Yang et al. (2012)]. A tracking algorithm using a local sparse appearance model and K-selection was proposed in Liu et al. [Liu, Huang, Yang et al. (2011)], which was robust to changes in appearance and drift. Ross et al. [Ross, Lim, Lin et al. (2008)] presented an appearance-based tracker that incrementally learn a low dimensional eigenbasis representation for robust object tracking. Xing et al. [Xing, Gao, Li et al. (2013)]developed the template update problem as online dictionary learning and proposed a robust object tracking method with online multi-lifespan dictionary learning. While the discriminative method model visual tracking task as a classification problem, this method is also commonly known as tracking-by-detection methods. What differs from the generative model is that tracking the maximum classification score between object and background is the goal of the discriminative model. Hare et al. [Hare, Golodetz, Saffari et al. (2016); Zhang, Zhang, Liu et al. (2014); Kala, Matas and Mikolajczyk (2010);Babenko, Yang and Belongie (2011); Grabner, Leistner and Bischof (2008); Avidan(2004); Avidan (2007); Yao, Shi, Shen et al. (2012, 2013); Yao (2015); Yao, Xia, Zhang et al. (2017); Collins, Liu and Leordeanu (2005)] are some attempts and achievements in recent years to solve the visual tracking task with the discriminative method.Convolutional neural networks (CNNs) perform well in many areas of computer vision by means of their powerful feature representation capabilities, such as medical image processing, biometric identification and visual tracking. Hong et al. [Hong, You, Kwak et al. (2015); Ma, Yang, Zhang et al. (2015); Qi, Zhang, Qin et al. (2016); Wang, Ouyang,Wang et al. (2015, 2016)] show the state-of-the-art results of deep-learning-based visual tracking methods. A novel visual tracking algorithm based on pre-trained CNN was proposed in Hong et al. [Hong, You, Kwak et al. (2015)]. With the CNN features and the learning recognition model, Hong et al. calculated the target-specific saliency map by back-projection, highlighting the differentiating target regions in the spatial domain.Wang et al. [Wang, Ouyang, Wang et al. (2016)] proposed a tracking algorithm using a full convolutional network that is pre-trained on image classification tasks after studying some important properties of CNN features in the perspective of visual tracking. And then, they regarded the online training process for CNNs as sequentially learning an optimal ensemble of base learners and proposed a sequential training method for CNNs to effectively transfer pre-trained deep features for online applications in Wang et al. [Wang,Ouyang, Wang et al. (2016)]. Although these methods have achieved considerable performance, they usually come at the cost of time and computational resources.
Tracking-by-detection is currently the most popular and effective framework for visual tracking tasks, and it obtains information about the target from each detection online.
Collins (DLSSVM) algorithm which approximates non-linear kernels with explicit feature maps. Avidan [Avidan (2004)] proposes a tracker based on offline Support Vector Machine (SVM). Then, Avidan [Avidan (2007)] uses an online boosting method to classify object and background. Babenko et al. [Babenko, Yang and Belongie (2011)]propose a tracker based on Multiple Instance Learning (MIL). The MIL is used to handle ambiguously labeled positive and negative data obtained online to alleviate visual drift.Hare et al. [Hare, Golodetz, Saffari et al. (2016)] propose a structural learning based tracking algorithm. Motivated by the successful of Struck and learned some tricks form[Atluri (2004)], Yao et al. [Yao, Shi, Shen et al. (2012)] propose weighted online structural learning for visual tracking to deal with the unbalanced weight problem of samples during tracking.
Recently, a group of correlation-filter (CF) based tracker [Bolme, Beveridge, Draper et al.(2010); Bertinetto, Valmadre, Golodetz et al. (2015); Danelljan, Khan, Felsberg et al.(2014); Zhang, Ma and Sclaroff (2014) (2014); Henriques, Rui, Martins et al. (2014)(2014)] has drawn much attention due to its significant computational efficiency. CF achieves real-time training and detection of densely sampled instances and highdimensional features by using Fast Fourier Transform (FFT). Bolme et al. [Bolme,Beveridge, Draper et al. (2010)] describe their pioneering work and, adopt CF to visual tracking for the first time. Later, in order to improve the tracking performance,researchers also propose some extensions. Henriques et al. [Henriques, Rui, Martins et al.(2014)] propose a CSK method based on illumination characteristics. In addition, Ma et al. [Ma, Yang, Zhang et al. (2015)] propose a long-term tracker to learn the discriminantdependent filters used to estimate the object’s translation and scale variations. Danelljan et al. [Danelljan, Häger, Khan et al. (2014)] calculate the fast scale estimation problem by learning the discriminant CF based on the scale pyramid representation. Subsequently, in order to solve the unwanted boundary effect introduced by the periodic hypothesis of all cyclic shifts, Danelljan et al. [Danelljan, Häger, Khan et al. (2015)] introduce spatial regularization components into learning, and punish the CF coefficients according to spatial locations to achieve excellent tracking accuracy.
The colour feature is often used in the visual tracking [Rez, Hue, Vermaak et al. (2002);Possegger, Mauthner and Bischof (2015)]. The method [Danelljan, Khan, Felsberg et al.(2014)] extracts the colour features of the object and the background area, and distinguishes them by correlation filter based on the kernel function; then the object tracking of the video sequence is achieved. However, this method simply uses the colour information of the object pixel and does not consider the shape feature of the object, so that the description capability is limited. Moreover, incorporating shape information often leads to large feature dimension, which is not conducive to real-time object tracking. In addition, the construction of least squares classifier based on correlation filter can only be used for binary classification tasks and cannot accurately describe occlusion information of the object. The above problems will cause drift of visual tracking in complicated actual scenarios.
To handle the aforementioned problem, this paper presents a real-time visual tracking method with the compact shape and colour feature. In this paper, compact shape and colour features are formed by fusing shape and colour features of candidate objectregions, which reduced the dimension through the Hash function. Then, a structural classification function is presented for object classification and prediction. The proposed method is able to enhance the description ability of object appearance model, while the structural classification can improve the accuracy of the object classification, which can effectively avoid the visual tracking drift and improve the tracking performance.
2 The proposed method
In this section, we first introduce the structural classifier for visual tracking. Next, we present the shape and colour feature. Thirdly, we describe how to learn the compact representation of features. Finally, we use the proposed online learning method to build our tracking approach. The overall framework of the proposed tracker is presented in Fig. 1.

Figure 1: Overview of real-time visual tracking with compact shape and colour feature
2.1 Structural classifier for visual tracking
At the first frame of the sequence, the bounding boxof the object is given manually, whereis the position of the object,are the column coordinates, row coordinates, width and height of the upper left corner. The bounding boxBtrepresents the position of the object at framet, and then we describe the displacement of the target using offset. The tracking procedure starts from the second frame, the accurate bounding box is estimated for the object location. The boundary boxBtof the object in frametcan be obtained by:where

denotes a structured classification function, andxtrepresents the frametin the video sequence.is a vector ofkdimension,which represents the compact shape and colour feature of the candidate object region and will be constructed by Step 3 in the Fig. 1. The parameterwis ak-dimensional vector which initialized withkrandom real numbers between 0 and 1, and it will be updated online at Step 4 by learning samples of each frame.
2.2 Shape and color feature
An intensive sampling method is used to get samples close to the real object bounding box, and the corresponding image regions are cropped as training sample to extract the shape and colour features of these samples.
The dense sampling method is designed as follows: The real object bounding box of the current frametisBt, therefore, the true object offset isyt= (0 ,0,Δwt,Δht), in this paper, the fixed object size is set as Δwt=0,Δht=0. Taking the current object offset in a circle which (0 ,0)as the centre andSas the radius (S=30in this paper), we sampleMoffsets in this circle, which isY= {y=(Δc, Δr, 0,0):Δc2+Δr2<s2}. According to the definition of Eq. 1, the object bounding box can be obtained by addingMoffsetsyof the samples to theBt, and we takeMimage regions obtained by cropping these object bounding boxes in frametof imagextas training samples.
Next, we will extract the shape features for each training samples. In this paper, we use Haar-like features to describe the shape information of the object. The Haar-like feature is a commonly used feature description operator in the field of visual tracking. This paper uses three basic types of features, which are divided into two rectangular features, three rectangular features and diagonal features. The result of the sum of all the pixel values of a class of rectangular part in the three types of matrix image regions is subtracted from the sum of all the pixel values of the other type of rectangular part is a single eigenvalue.In this paper, the integral graph is used to speed up the calculation of this eigenvalue.Finally, we combine the eigenvalues of all three types of features into a vector, and build the Haar-like feature of the image region.
The colour information of each training sample is extracted and merged with the shape feature into a new feature vector. The colour information is extracted as follows: The colours are divided into 11 categories (black, blue, brown, grey, green, orange, pink,violet, red, white and yellow). For the three types of rectangular of Haar-like feature obtained from the previous step, we count the probability of the RGB values of all pixels in each rectangle, and then we put the 11 probability values into a colour vector. Finally,we put this colour vector after the Haar-like feature, thus we can get the new features containing the shape and colour information. The colour vectorCNand all theprobabilities of mapping to the 11 colours from the RGB values of all the pixels in a rectangleis defined by:
wherecniis thei-th colour of the 11 categories,cis the coordinates of the pixels in the rectangleI,Nis the total number of pixels in the rectangleI, andg(c)is the Lab colour space value of the pixelc, and we can getp(cni|g(c))from the common colour name mapping.
2.3 Compact representation of feature
The feature vector extracted from the second step, which contains the shape and colour information of the sample, has a high dimension. Using this feature directly will increase the computational complexity of the object tracking, which is not conducive to real-time tracking. In this paper, the local sensitive hash is used to map the high-dimensional features obtained in step two to generate compact colour-coded feature vectorsThe is described as follows: Suppose the dimension of the eigenvector obtained in Step 2 of Fig. 1 isd, that is, the characteristic of each sample is ad-dimension vector. In order to map high-dimensionald-dimension vectors intom-dimensioncompact binary coding features. We define a hash function familyHcomposed ofmHash functionsha(.). More specifically, a random vectorυ∈dis generated as a hyperplane from thed-dimension Gaussian distribution, then the hash functionhaυ(.)is defined as:

whereq∈dis the eigenvector of the single sample obtained in Step 2 of Fig. 1.Constructing m hash functions by the above method and substitutingqinto these Hash functions, a binary coded string of m dimensions can be obtained. That is, a compact coded feature vector is constructed. Note that the abovemHash functions are generated only in the first frame of the video sequence, and will continue to be used in the following frames.
2.4 Online learning
In this step, we will learn and update structural classification functions. Object tracking is an online update process for dynamic data flow. The object tracking method needs to learn and update the parameters from the training samples to adapt to the new frame. This step updates the parameterswof the structured classification functionin Eq. 1 using the compact colour-coded features of the samples generated in Step 3, and then we use the updatedwto estimate the optimal object position in the new video frame.
The method of updating the parameterwis described in detail below. SubstitutingMsamples represented by a compact coding feature into Eq. (4), new parameterwis obtained by optimizing Eq. (4):
whereλis the regularization coefficient, in this case, theis the relaxation of variables,marking cost Δis used to measure the coverage of the bounding box, defined as:

The sub-gradient descent method is used to iteratively optimize the Eq. (4) to determine the final value of the new parameterw. Assuming that the current frame is the framet,the sub-gradient of the Eq. (4) with respect to the parameterwtis:
The eigenvector ofMsamples calculatedin Step 3 are respectively substituted into the formula (7), and the recalculated one is the updated structural classification parameter. The stochastic sub-gradient method [Shwartz, Singer and Pegasos (2011)] is guaranteed to converge to the optimal SVM solution.
2.5 Real-time visual tracking
In this section, we will generate the candidate object region, and use structural classification function to estimate the optimal object region, and finally determine the object location. When the framet+1image arrives, the tracking method requires sampling close to the object location of the last frame, and estimates the highest classification scores in the samples by using the structured classification function which has been updated parameters , and then the region that corresponding to this sample is the optimal target location. After getting the new object position, we turn to Step 2 until the video sequence ends. The detailed processing is described as follows:
First of all, we assume thatis the object boundary box of the last frame in the sequence, offsetis sampled in a circle withas the centre andas the radiusbounding boxes of candidate objectobtained by addingto the sampledoffsets. Then wetake the correspondingimage region cropped from the current framet+1image
as the candidate object region.Second, the compact shape and the colour feature vector ofcandidate target regionsis calculated by using the feature generation method described in Steps 2 and 3.Eq. 8 is used to calculate the optimal offset:
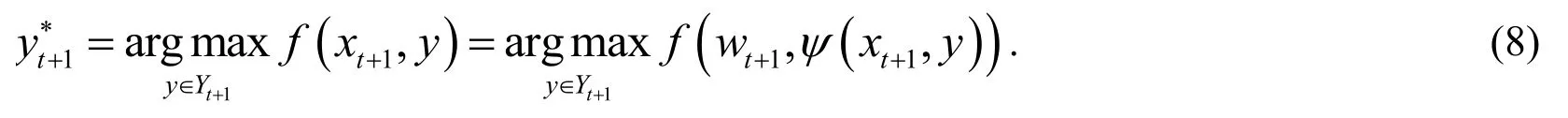
The position of the current frame targetaccording to the target boundary boxand the calculated optimal migration of Eq. (8).
3 Experiments
We conducted our experiments with the most extensive and authoritative datasets OTB-13 [Wu, Lim and Yang (2013)] and OTB-100 [Wu, Lim and Yang (2015)]. All these sequences are annotated with 11 attributes which cover various challenging factors: Such as scale variation (SV), occlusion (OCC), illumination variation (IV), motion blur (MB),deformation (DEF), fast motion (FM), out-of-plane rotation (OPR), background clutters(BC), out-of-view (OV), in-plane rotation (IPR) and low resolution (LR). We follow the evaluation protocol provided by the benchmark [Wu, Lim and Yang (2015)].
Four metrics with one-pass evaluation (OPE) are used to evaluate all the compared trackers: 1) bounding box overlap, which is measured by VOC overlap ratio (VOR); 2)centre location error (CLE), which is computed as the average Euclidean distance between the ground truth and the estimated centre location of the target; 3) distance precision (DP), which indicates the relative number of frames in the sequences where the centre location error is within a given threshold; and 4) overlap precision (OP), which is defined as the percentage of frames where VOR is larger than a certain threshold.
In order to evaluate the proposed method, we use the two evaluation indicators mentioned in Wu et al. [Wu, Lim and Yang (2013)]. We use the precision plot to measure the overall tracking performance, which shows the percentage of frames whose position is within a given true threshold distance. As a representative precision score for each tracker, we use a score of threshold=20 pixels. The success plot is defined as the area under the curve(AUC) for each success graph, which is the average of the success rates corresponding to the overlap threshold of the samples. Our visual tracking method is implemented in MATLAB (R2017a) on a PC with a 3.60 GHz CPU and 12 GB of RAM. The average running speed of our tracker is 0.15 second per frame.
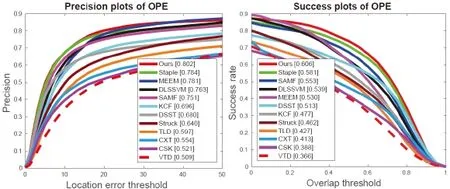
Figure 2: Overall distance precision plot (left) and overlap success plot (right) with onepass evaluation (OPE) over 100 sequences (OTB-100). The legends show the precision scores and AUC scores for each tracker. The top performer in each measure is shown in red, and the second and third best are shown in blue and green, respectively
We evaluate our tracker with 11 state-of-the-art trackers designed with conventional handcrafted features including DLSSVM [Ning, Yang, Jiang et al. (2016)], DSST[Danelljan, Häger, Khan et al. (2014)], STAPLE [Bertinetto, Valmadre, Golodetz et al.(2015)], SAMF SAMF [Li and Zhu (2014)], KCF [Henriques, Rui, Martins et al. (2014)],MEEM [Zhang, Ma and Sclaroff (2014)], STRUCK [Hare, Golodetz, Saffari et al.(2016)], TLD [Kalal, Matas and Krystian (2010)], VTD [Kwon and Lee (2010)], CXT[Dinh, Vo and Medioni (2011)], CSK [Rui, Martins and Batista (2012)]. Among them,Struck and DLSSVM are structured SVM based methods, Staple, KCF, DSST, CSK and SAMF are CF based tracers, MEEM is developed based on regression and multiple trackers. Fig. 2 shows the overall precision and success plots on OTB-100.

Table 1: Comparison with 11 state-of-the-art trackers on 100 sequences in terms of DP,OP, CLE, and VOR
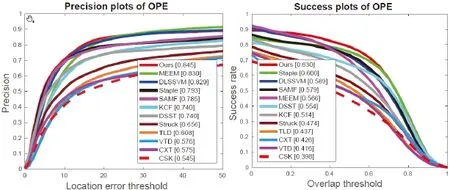
Figure 3: Overall distance precision plot (left) and overlap success plot (right) with onepass evaluation (OPE) over 51 sequences (OTB-13). The top performer in each measure is shown in red, and the second and third best are shown in blue and green, respectively
Due to the lack of benchmark datasets and evaluation methods, the results of algorithms such as TLD, VTD, CXT, and CSK are not satisfactory with the highest DP indicator is 0.60. With the solution to the key issues of the benchmark and the presentation of some advanced methods (correlation filtering and deep learning), the performance of the algorithm has been greatly improved and the lowest index of DP has reached 0.64.Without comparing to our method, DLSSVM, STAPLE, MEEM, and SAMF have relatively competitive performance among the 11 methods. What is worth noting is the performance of MEEM in CLE, which is mainly owing to the multi-expert restoration program to solve the problem of model drift in online tracking. Through comparison, we can find that the tracker we proposed performs better than all the methods. As shown in Tab. 1,our algorithm consistently performs better than 11 recently proposed methods in DP, OP,CLE, and VOR on OTB-100. In addition, we also report our results on the OTB-13 dataset,as shown in Fig. 3. The proposed method performs better than the competing methods.
4 Conclusion
This paper proposed a structured object tracking method with compact shape and colour feature. In order to enhance the descriptive ability of the features, we added the shape features of the tracking object and fused them with the colour features to form new features. However, the direct use of such high-dimensional features will increase the computational complexity of object tracking. To alleviate computational cost, we used hashing method to reduce the dimensions of the new features and generate a compact representation for shape and colour feature of the object. Then we used the structured classification function to learn and update online to estimate the optimal object region.Through experimental verification, we can find that the proposed method achieves promising performance compared with the state-of-the-art visual tracking methods.
Acknowledgement:This work was supported by the National Key Research and Development Plan (No. 2016YFC0600908), the National Natural Science Foundation of China (No. 61772530, U1610124), Natural Science Foundation of Jiangsu Province of China (No. BK20171192), and China Postdoctoral Science Foundation (No. 2016T90524,No. 2014M551696).
杂志排行

Computers Materials&Continua的其它文章
- Biodegradation of Medicinal Plants Waste in an Anaerobic Digestion Reactor for Biogas Production
- Molecular Structure and Electronic Spectra of CoS under the Radiation Fields
- Feature Selection Method Based on Class Discriminative Degree for Intelligent Medical Diagnosis
- A Spark Scheduling Strategy for Heterogeneous Cluster
- Rare Bird Sparse Recognition via Part-Based Gist Feature Fusion and Regularized Intraclass Dictionary Learning
- Event-Based Anomaly Detection for Non-Public Industrial Communication Protocols in SDN-Based Control Systems