用于盲人视觉辅助的多目标快速识别并同步测距方法
2018-07-11吴晓烽吴丽君吴振辉陈志聪林培杰文吉成
吴晓烽, 吴丽君, 吴振辉, 陈志聪, 林培杰, 文吉成
(1.福州大学物理与信息工程学院, 微纳器件与太阳能电池研究所, 福建 福州 350116;2.国家电网福州供电公司, 福建 福州 350003)
0 引言
目前, 我国约有7 500万视障人群, 他们的生活和出行都因其视力的障碍而受到极大困扰.盲杖等传统辅盲工具只能通过物体接触来检测障碍物, 对空间中较高物体(如树枝等)难以检测.近年来, 电子行走辅助[1](electronic travel aids, ETA)系统相继被提出, 为视障人士带来了极大便利, 其中障碍物识别与测距是ETA系统中的关键技术.文[2]对近年的ETA系统进行了实用性综合对比, 其中评分最高的Ecole Polytechnique Fédérale de Lausanne(EPFL)系统[3], 采用成对声呐进行测距, 有着测距精确度高、 易穿戴等特点.评分其次的tactile vision system(TVS)[4]通过成对摄像头生成视差图来检测障碍物的远近, 其便于穿戴, 检测范围广.现有ETA系统, 虽能较为精确地检测障碍物离使用者的距离, 却无法识别障碍物.在实际使用中, 与高精度地对障碍物测距相比, 视障人士更迫切地需要对周围多障碍物的识别及相应位置的估计.近年提出的wearable mobility aid(WMA)[5]系统是一种采用RGBD摄像头测距, 并利用LeNet[6]网络实现障碍物识别, 最后整合信息反馈给盲人的异步实现方式.这种异步识别及测距方式为目前大多能够识别障碍物的ETA系统采用, 但受限于所采用的测距方式, 只能对离使用者最近的障碍物识别测距, 而对实际应用中多障碍物同时出现的场景, 就会出现难以匹配等问题, 因而难以适用.
随着深度学习技术的发展, 目标检测领域出现了RCNN(regions with convolutional neural network)[7]、 Faster-RCNN[8]、 SSD(single shot multibox detector)[9]、 YOLO(you only look once)[10]等算法, 其能够以较高精度、 鲁棒地同时识别多类物体.其中, SSD是一个基于卷积神经网络目标检测识别模型, 相比于Faster R-CNN等目标检测算法, SSD去除了产生候选区域(proposals generation)及像素或特征降采样(pixel or feature resampling)等阶段, 因而可以实时地检测识别目标.且SSD通过不同层次的特征图(feature map)进行多段识别, 从而能够达到较高的目标识别精度.因此, 本研究针对现有ETA系统的不足, 探索基于深度学习算法的多目标快速识别及同步测距方法, 以期实现盲人视觉辅助.提出将各类类别标定框(ground truth box)的高度与距离进行回归拟合从而训练出测距模型, 并结合目标检测算法SSD所识别障碍物类别及检测框(bounding box)高度, 最终实现对多目标快速识别并同步测距.
1 基于SSD的目标检测识别算法
提出的目标检测识别及测距方法的原理如图1所示.在人工采集的目标图像和实际距离数据集的基础上, 整个目标识别及测距方法框架主要分为两个部分: 其一, 在多段距离下, 人工采集目标图像并提取每一类标注框(ground truth box)的高度, 根据物体近大远小的原理, 将所提取的物体高度与实际距离值回归拟合, 以训练获得测距模型; 其二, 首先利用基于VOC2007数据集训练的SSD模型检测识别物体, 并提取出物体检测框(bounding box)的高度, 输入测距模型从而获得测距结果.将从不同层级特征图检测及目标函数模型两方面来介绍SSD的原理.
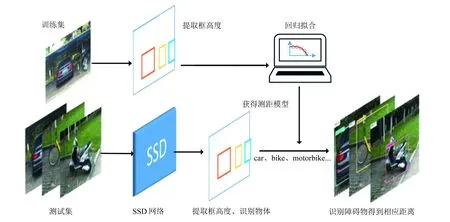
图1 测距方法整体流程框图Fig.1 Flow diagram of distance measuring method
1.1 不同层级特征图检测
SSD利用回归来识别物体, 如图2所示.对于每个特征图, 采用3 px×3 px卷积核(filter)生成若干默认检测框(default bounding boxes)以及每个检测框相对标注框的偏移量与置信度, 最后共同识别物体.具体地, 如图2(b)中, 每个特征图块(feature map cell)生成3个默认检测框.在训练阶段时, 将已标注好的图片中的标注框与特征图中的默认检测框(default bounding boxes)进行匹配.对于图2(a)中的两个标注框, 按照尺寸分别与8 cell×8 cell及4 cell×4 cell特征图中蓝色虚线框与红色虚线框(猫与狗)吻合, 因此将其作为模型训练的正样本, 而其他虚线框为负样本, 采用3 px×3 px的卷积核(filter)生成相对于默认框的4个偏移量: 高度(h)、 宽度(w)以及中心位置(cx,cy)和21个类别置信度(c1,c2, …,cp,p=21)(以VOC2007数据为例, 一共21类).
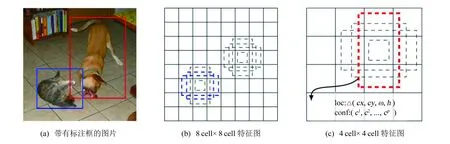
图2 不同比例的默认检测框[9]Fig.2 Different ratio of default boxes
因为较低层特征图具有较良好的局部特性, 而高层的特征图具有较好的全局特性, 而好的全局特效能获取更平滑的结果, 所以SSD在分类网络(VGG)后额外添加了逐层递减的卷积层进行预测, 如图3所示, 由逐层递减的卷积层来实现多尺度预测以及共享权重.
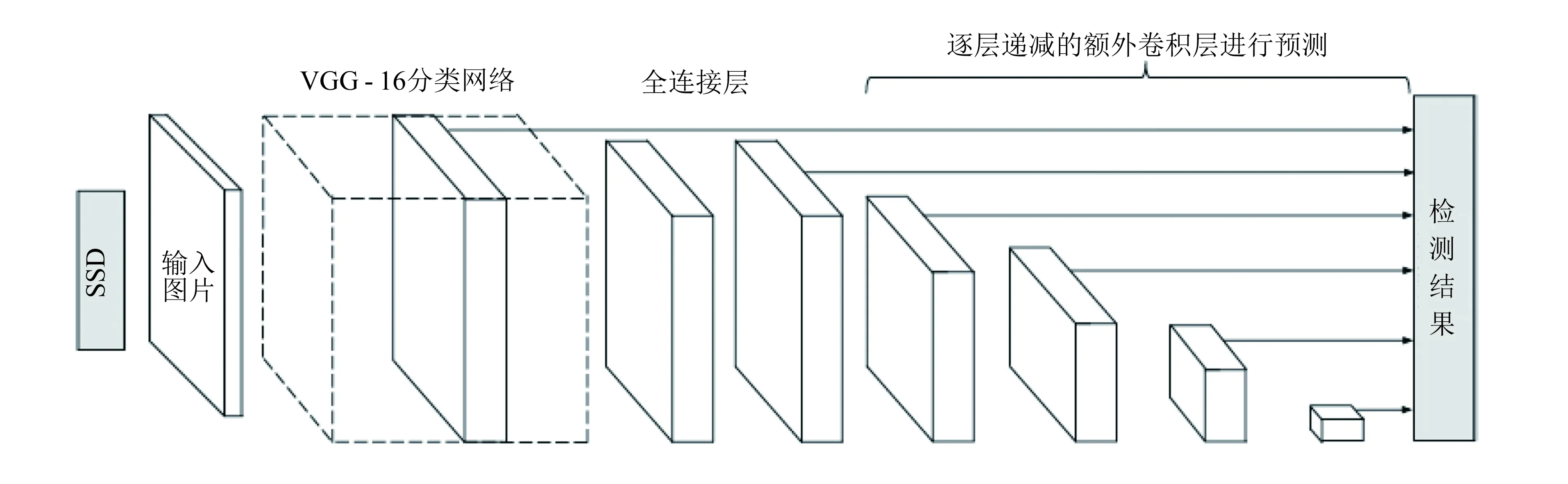
图3 SSD网络模型[9]Fig.3 Network model of SSD[9]
通过在不同层的特征图上应用默认检测框机制, 可使SSD有效地离散化输出框形状从而大幅度减少检测框数量, 加快检测速度.而通过应用从多个特征图进行预测的方法, 能够对输入图像进行多尺度检测.
1.2 目标函数
目标函数用来衡量真实值和预测值(默认检测框以及对应4个预测值和21类置信度)的差距, 通过最小化目标函数来获取最佳神经网络权重.如上节所述, SSD目标函数[9]为定位损失(loc)与置信度损失(conf)的加权和:
(1)
其中:Lconf为定位损失, 其衡量检测框定位与标注框的差距;Lloc(x,l,g)为置信度损失, 表示分类的错误率;α为权重;N代表匹配的默认检测框, 如果N=0, 则设L=0.若设α>1, 则更偏重定位精度, 若设α<1, 则更注重识别精度, 可按需求设置.本实验视定位损失和识别精度同等重要, 故设α为1.定位损失smoothL1Loss计算如下:
(2)
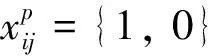
(3)
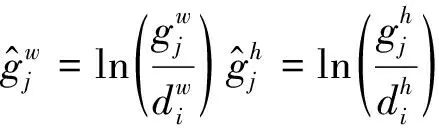
(4)
置信度损失计算如下:
(5)
2 回归拟合测距模型及其训练
2.1 图像采集与特征选取
针对对盲人出行影响较大的三类目标(汽车、 自行车、 摩托车)进行图像采集, 并将其分为三份: 训练集、 测试集和侧面测试集.其中侧面测试集用来验证测距模型对不同角度拍摄图像的性能.此处, 采用普通手机拍摄(Iphone 6, 3 264 px×2 448 px), 因盲人对过远物体检测需求不大, 而过近则摄像头无法拍全整个物体.因此, 本实验从4.0 m开始, 以0.5 m的间隔对三类物体的正面进行同时拍摄, 并记录相应的物距, 共拍摄38组(4.0~22.5 m)作为训练数据; 然后, 随机选取不同距离, 以及侧面角度对三类物体进行拍摄22组, 作为测试数据; 部分训练图片如图4所示, 其距离分别为6.5、 12.0、 22.0 m.

图4 训练数据示例Fig.4 Examples of training data
为选取合适的特征实现测距, 首先对正面采集及侧面采集的图片数据进行一定的分析.分别对每一类的正面及侧面图像进行人工标注, 并记录标注框的宽与高(单位为像素), 如图5所示, 其距离都为6 m.
从图中可以看出, 在相同距离时候, 不同视角会使得目标宽度影响较为严重.以汽车为例, 如图5(a)与图5(b)所示, 汽车变化影响较为巨大(1 331 px变化为3 074 px), 而高度则变化范围相对较小(1 038 px变化为1 262 px), 所导致的误差在视觉可接受范围之类.其他类别如自行车及摩托车的情况亦是如此.因此, 本实验采取较为不受视角影响的高度进行测距, 以提高测距算法的鲁棒性.

图5 正面与侧面角度图片的标注示例(拍摄距离: 6 m)Fig.5 Example of side angle image with ground truth boxes (shoot distance: 6 m)
2.2 测距模型
将训练集中各类别的标定框的高度与距离进行回归拟合, 从而实现多目标同时测距, 采用的回归模型为:
y=f(x,β)+ε
(6)
其中:y为距离;x为标定框高度,x=(x1,x2, …,xm)T;m=1;β=(β0,β1, …,βp)T是未知数参数向量;ε为随机误差.现对模型做n次观测, 得到观测数据为(xi1,xi2, …,xim,yi)T, 即:
yi=f(x(i),β)+εi
x(i)=(xi1,xi2, …,xim)T(i=1, 2, …,n)
(7)
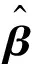
(8)
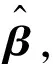
(9)
步骤1给出β的初值β0;
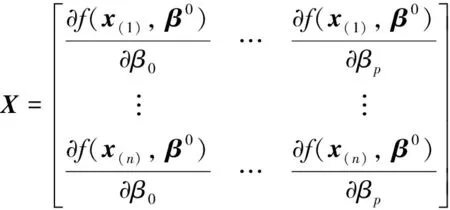
步骤3计算β*:β*=β0+(xTX)-1xTY*;
步骤4迭代: 以β*代替β0重复步骤2, 3, 直至|β*-β0|或|Q(β*)-Q(β0)|结果达到预先精度为止.
2.3 模型训练
提取2.1节中已标记好的训练集中标注框的高度, 记为xtrain/px, 距离记为ytrain/m, 显著值α=0.05, 训练拟合出测距模型.以下以汽车为例, 旨在利用训练集拟合出回归方程, 并用测试集数据(xtext,ytext)对模型进行验证.训练集与测试集部分数据列于表1中.

表1 标注框高度与实测距离数据(汽车)
受图像成像原理的影响, 图像拍摄距离(x)与物体高度(y)之间的关系并非完全线性的.画出x,y的散点图, 如图6所示.根据其趋势, 采用指数模型对其进行回归拟合:y=β0eβ1x.
考虑到高度与距离量纲区别较大, 为了消除其影响, 首先对数据进行预处理, 采用min-max归一化到0~1范围.
(10)
其中:xmax、xmin和ymax、ymin分别为样本中最大值与最小值.
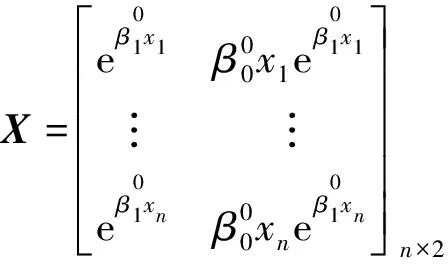
y=0.969 5e-3.666x
(11)
做出回归曲线, 如图7所示, 回归结果如表2所示.
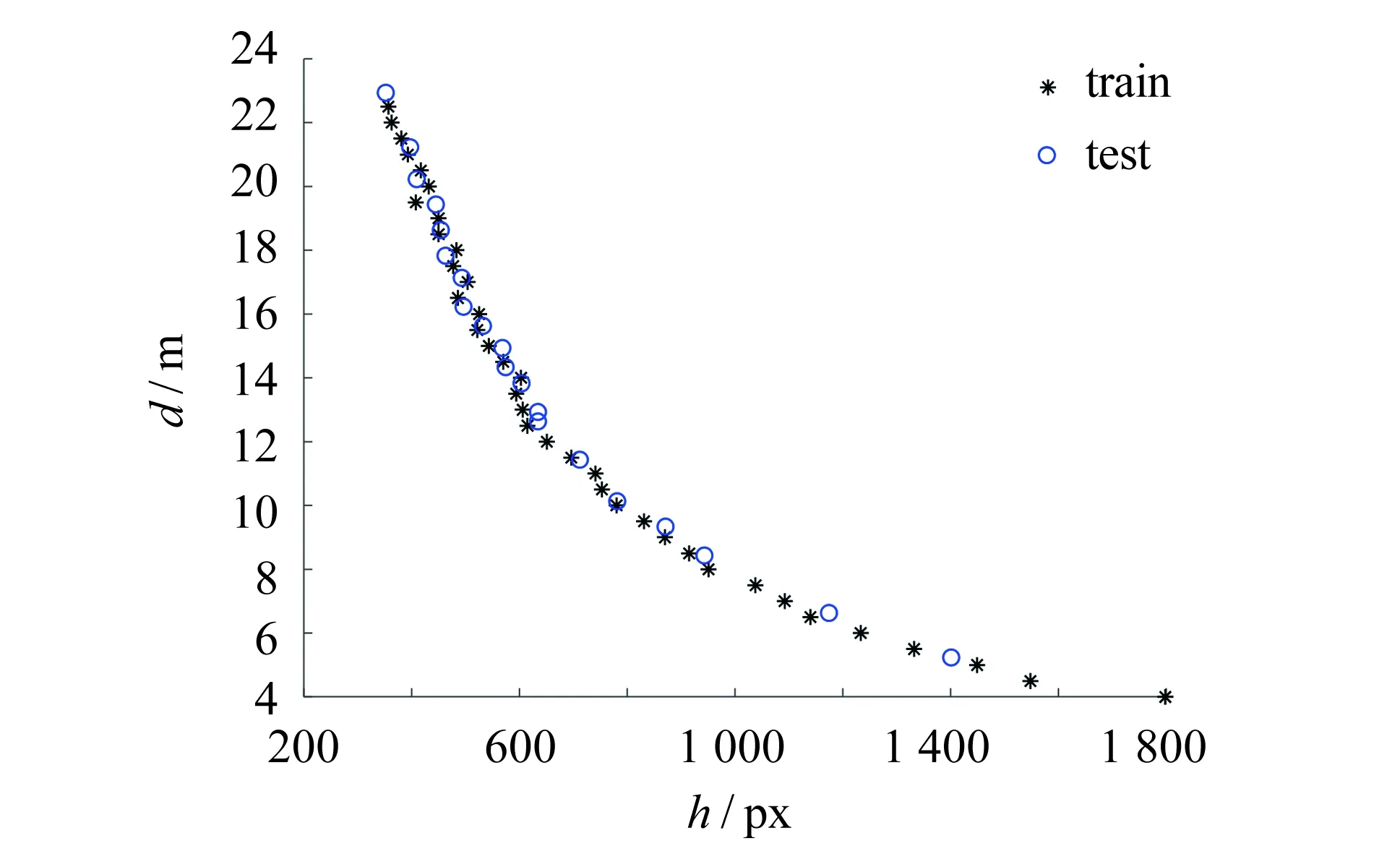
图6 训练集与测试集散点图Fig.6 Scatter plot of training data and testing data
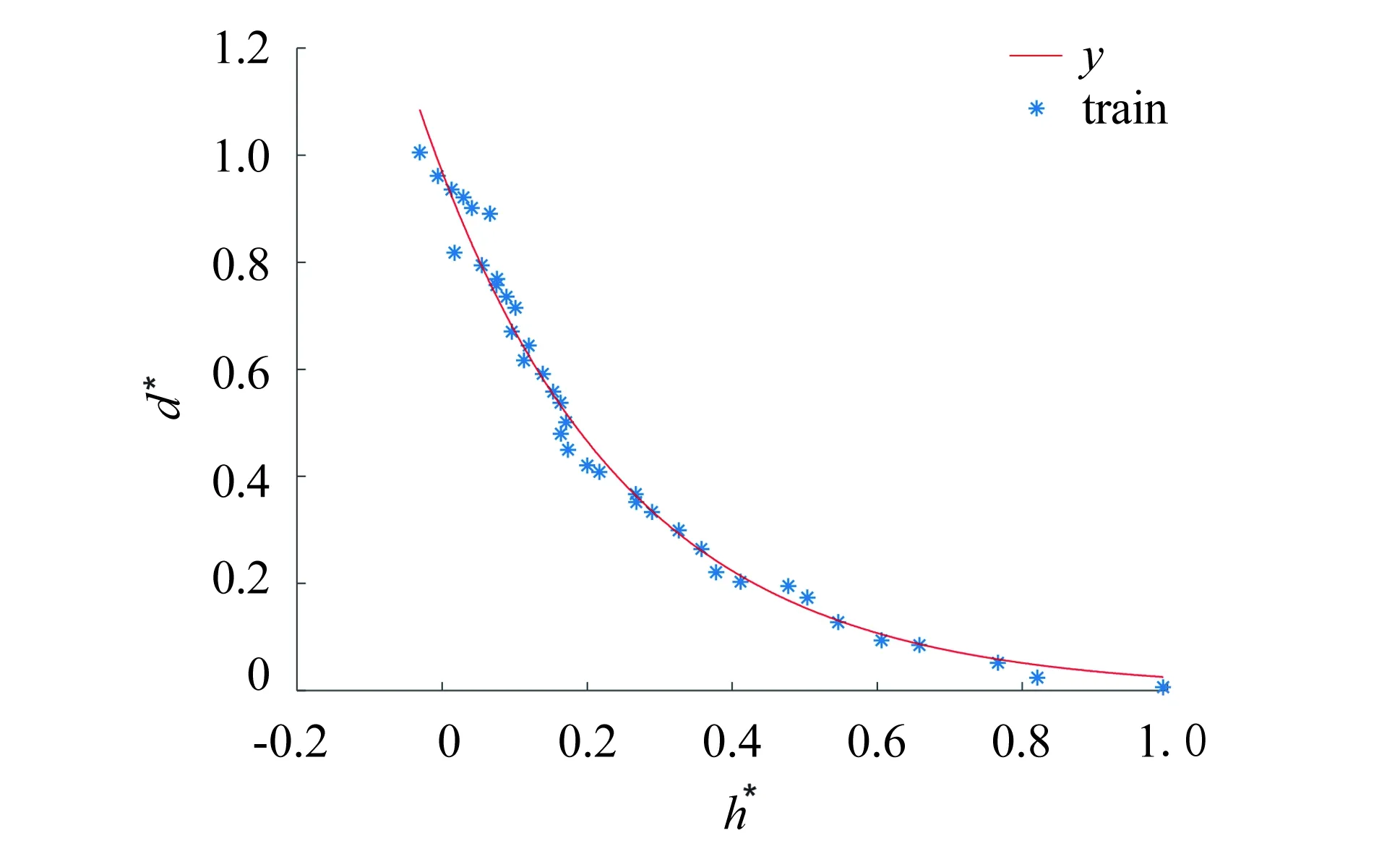
图7 回归方程拟合回带图Fig.7 Diagram of fitting curve of regression equation

回归方程指数类型y=0.9695e-3.666x统计量n=38, 自变量数m=1, SE=2.6089, SR=31.6045, ST=34.2134, 统计量F=437.600769∗∗, F0.05=4.121方程检验结论因为统计量F>F0.05, 所以认为方程线性相关性显著
由表3可知, 训练好的模型能够较好地拟合测试集, 并且对于侧边角度也能够较好地反应高度和距离的关系, 距离测量结果基本符合盲人视觉辅助需求.
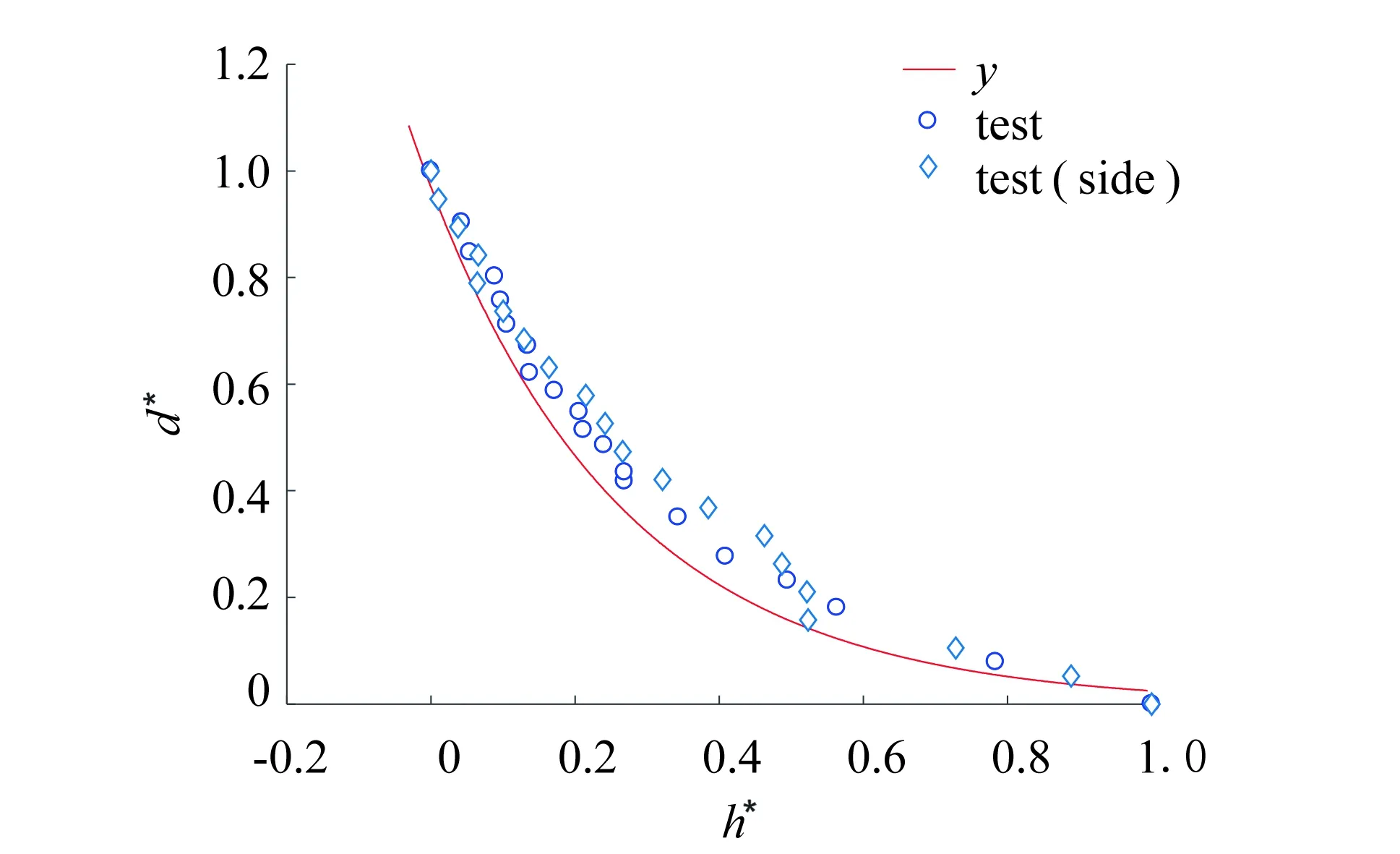
图8 回归方程测试数据拟合回带图Fig.8 Diagram of fitting curve of regression equation for testing data
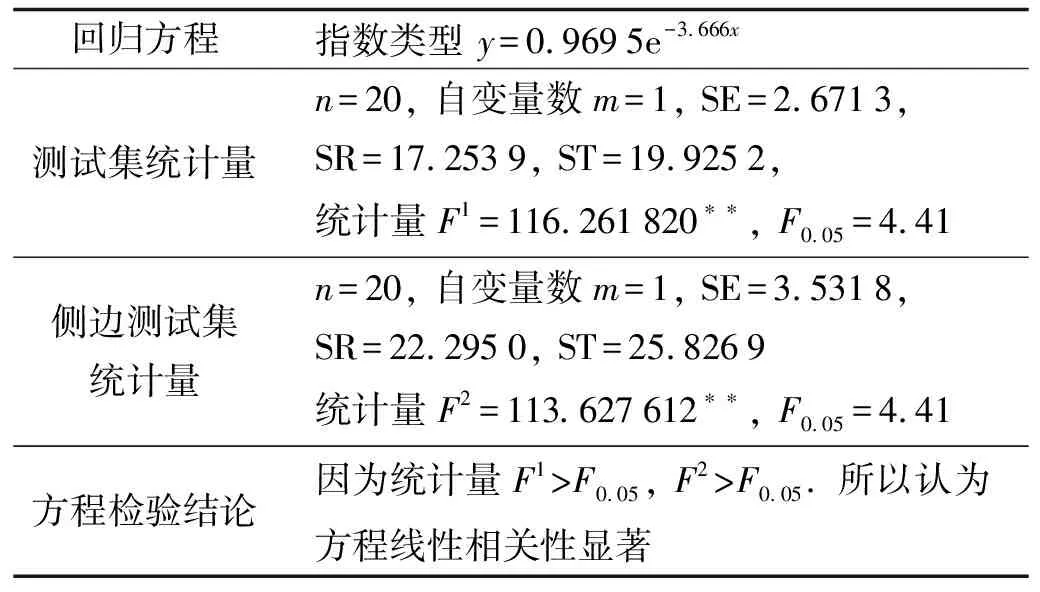
回归方程指数类型 y=0.9695e-3.666x测试集统计量n=20, 自变量数m=1, SE=2.6713, SR=17.2539, ST=19.9252, 统计量F1=116.261820∗∗, F0.05=4.41侧边测试集统计量n=20, 自变量数m=1, SE=3.5318, SR=22.2950, ST=25.8269统计量F2=113.627612∗∗, F0.05=4.41方程检验结论因为统计量F1>F0.05, F2>F0.05. 所以认为方程线性相关性显著
3 实验结果实例与对比分析
针对盲人现实使用需求场景, 本实验通过对不同剖面的物体、 复杂背景及多目标情况下的识别检出效果及距离估算精度进行验证, 并对识别测量速率进行验证.实验平台环境配置为: CPU为i7-6700k、 RAM为16 GB、 显卡为GTX1070, 显存为8 GB, 运行环境为Ubuntu16.04, PyCharm2016.3.3集成开发环境, 搭载Keras、 TensorFlow框架.
3.1 多目标正面, 不同距离的检出率及测距结果
测距结果如图9所示.其中括号中数值为距离估计值(汽车估计值, 自行车/电动车估计值), 括号前为真实值.

图9 测距结果(单位: m)Fig.9 Result of measured distance(unit: m)
在图9不同距离的测试环境中, 汽车相对于其他两类有着较好的距离测量精确度, 但总体而言, 测量的距离精度基本可以满足盲人的视觉辅助需求, 且在距离较远时由于目标较小, 自行车可能存在漏检情况, 如图9(b)当距离为7.5 m时自行车被漏检, 图9(c)中当距离为9.3 m时摩托车及自行车都被漏检.出现上述情况有如下3种原因: 1) 尺度变化导致物体特征减弱.为了保证实时性, SSD输入图片尺寸为300 px × 300 px, 则原图(3 264 px×2 448 px)经过尺寸变化(双线性插值法[11])导致物体尺寸变小, 从而使得较小的目标(自行车、 摩托车)的特征减弱, 产生精度降低甚至漏检情况.2) 背景干扰.图9(a)中自行车把手与背景相似, 在物体尺寸较小时, 只能检测出特征较为明显的轮子.因此出现“半截”的检测框, 从而导致测距误差较大.3) 人工标注框与SSD检测框具有一定的区别.如图5(c)所示, 在人工标注摩托车标注框时, 为精确定义车的大小, 摩托车上边框被标注为右侧倒视镜的一半, 而图9(b)中SSD检测框明显未包含镜子, 从而导致精度下降, 这将在下一步的工作中进行改进.通常情况下汽车、 摩托车和自行车的行驶速度依次递减, 因此在可检出距离上有一定的递减是符合实际应用需求的.
3.2 多目标侧面, 不同距离的检出率及测距结果
将基于SSD及回归拟合的物体识别测距模型应用于侧面测试集, 测试结果如图10所示.

图10 侧面测距结果(实际距离为4 m)Fig.10 Result of measured distance(actual distance is 4 m)
从图10可以看出, 侧面测量结果与正面测量结果基本一致, 摄像头从不同角度拍摄对物体检测框高度影响较小, 因而本算法对不同角度有较好的适应能力.对自行车进行测距时, 由于侧面的物体特征更加明显, 距离测量也较为精确, 但在检测摩托车时出现检测框未包括整个摩托车从而造成测距误差明显的情况, 这有待进一步研究改进.通过上述分析可得出, 对于较大的物体, 由于特征较为明显, 测距结果较好; 而对于较小物体, 或者物体未被检测框正确框注, 会导致精度差距较大, 甚至存在漏检情况.
3.3 对其他类别的检测结果及识别速率
本方法有较好的迁移性, 且在本实验平台环境下能够进行实时测距.利用普通智能手机录制的视频(Iphone6, 分辨率为3 264 px × 2 448 px)进行识别测距, 如图11所示.图11(a)为将本方法应用于行人检测与测距, 其能够保持大约25 帧 ·s-1的实时多类物体识别测距, 并且测距精度符合盲人实际使用需求.图11(b)为在复杂马路识别与测距, 从图中可以看出, 大多数行人以及车辆都被检出, 虽有一些物体被遮挡而未被检出, 但盲人所最关心的, 最接近盲人的几个目标都被检出, 因此本方法是符合实际使用需求的.

图11 复杂环境测距结果Fig.11 Result of complex environment ranging
最后以ETA系统中的障碍物检测模块与本方法进行比较, 如表4所示.本方法相对于上述三种方法, 主要优势在于: 其一, 能够识别障碍物.“前方有车”和“前方有人”更加值得警惕, 能够让盲人知道自己周边环境, 在一定程度上增加了安全性, 并且相比于WMA识别数量更多.其二, 多个物体同时测距.上述几个方法仅仅能够对最靠近盲人的障碍物进行测距, 但盲人往往眼前景物是不断变化的, 多目标测距可以一定程度上对即将靠近盲人的物体做到实时监测作用.其三, 将识别与测距同步进行, 本方法将上述几个系统原本独立的两个模块合并在一起, 从而能够实现多物体同时测距, 并避免了可能造成的不同步问题, 并使多类物体同时测距成为可能.受限于深度学习算法的复杂度, 本算法所需功耗较高, 但鉴于深度学习算法处在飞速发展中, 关于深度学习算法的优化及其权重二值化的研究获得了越来越多的关注[12], 因此我们相信本方法具有较大发展潜力与实用性.

表4 与经典ETA系统的性能比较
4 结语
针对盲人视觉辅助需求提出一种基于深度学习的多运动目标快速识别并同时测距方法.该方法使用摄像头, 利用SSD目标检测算法识别障碍物, 并利用SSD所生成的检测框高度输入测距模型, 从而能够对多目标快速识别并同步测距.本方法相比于其他ETA系统的障碍物检测模块而言, 能够识别多类物体且识别类别数量可供拓展, 并能够将测距模块和障碍物识别模块同步执行, 从而实现对多个物体实时地同步识别测距.以车辆为例, 通过采集数据、 人工标注、 拟合等步骤, 并以实验证明: 本方法对于本实验的车辆类别测距达到盲人现实可供使用的精度, 且未出现识别错误情况, 并且检测速度在本实验条件下(GTX1070)达到20~25 帧·s-1, 满足现实使用需求.虽在其他较小物体上检测效果不理想, 但其主要误差是由目标检测算法SSD导致的, 随着目标检测算法的发展[12], 本方法将越来越适用.
