决策树算法在实践教学中的应用研究∗
2018-07-10阴亚芳孙朝阳
阴亚芳 孙朝阳
1 引言
近年来,数据挖掘技术是学术界关注的一个热点领域,决策树算法作为数据挖掘中一个经典算法,因为其输出结果易于解释和理解[1],已被广泛地应用到教学管理、科学实验、金融业和商业决策等各个领域。西安邮电大学为使毕业生能够适应信息化社会不断发展的要求,不断地探索提高实践课程教学效果的路径。本文采用数据挖掘技术,以西安邮电大学2015-2016-02学期数字逻辑电路实验课的调查数据为样本,借助weka数据挖掘工具,建立决策树模型,提取分类规则,挖掘出出重要的教学指导意见,为我校改善实践课程教学效果寻找更加科学的方法,使教学管理工作不再仅仅基于经验和直觉,而是基于数据和分析做出的决策。
2 决策树算法
2.1 决策树算法的介绍
发展到今天,决策树分类算法已经有很多,比较著名的有ID3算法、C4.5算法、CART算法、CHAID算法等,ID3是所有决策树算法的基础,由Quinlan于1986年提出[2],该算法采用信息增益作为属性度量的标准。Quinlan在ID3算法的基础上做了改进,于1993年又提出了C4.5算法[3],C4.5算法相对于ID3算法主要的优点有:采用信息增益率作为属性度量的标准,克服了ID3算法容易偏向于取值较多的候选属性的不足,并且可以对连续型的属性值进行分类处理等[4]。
2.2 构造决策树模型的理论
设样本数据集T有m个类别,T={t1,t2,…tm},训练样本中某个属性A有n种取值,A={a1,a2,…an},根据属性A把训练样本划分为T'={t2',…,tn'},可以求出训练样本的信息期望为[5]
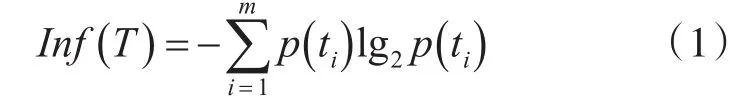
其中
属性A对训练样本划分的信息熵为
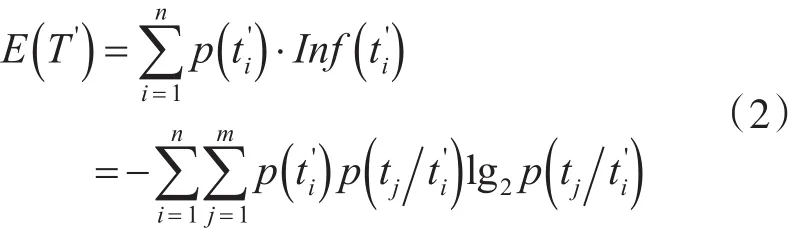
其中表示样本中包含类别tj的概率。
属性A对训练样本划分的信息增益为
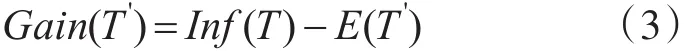
以上是ID3算法的核心理论,C4.5算法用信息增益率作为属性度量的标准,属性A信息增益率的表达方式为
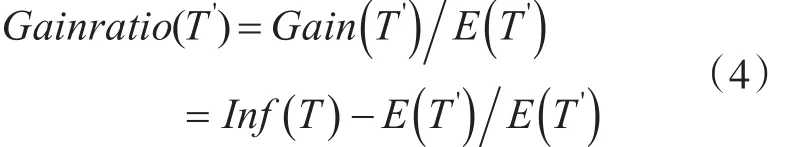
同理计算出其他属性的信息增益率,选择信息增益率最大的属性作为决策树根节点,用同样的方法递归下去,计算出各层的节点。
3 基于决策树算法建立模型并提取分类规则
weka是一个开源的数据挖掘软件,由怀卡托大学的weka小组用Java语言开发[6],它集合了大量能承担数据挖掘任务的机器学习算法,如分类分析、聚类分析、关联分析等,并且在新的交互式界面上可视化,是现今最完备的数据挖掘工具之一[7]。因为ID3和C4.5算法构造决策树的思路基本相同,所以我们仅以C4.5算法建立决策树模型为例,运用weka里的C4.5和ID3分类器对样本分类预测,并计算出分类预测的准确率,最后提取出“IF-THEN”分类规则[8]。
3.1 建立决策树模型
数据来源是西安邮电大学2015-2016-02学期实践课程的调查数据,因为全校的数据量很大,包括各个学院,各门课程,所以选择了电子工程学院具有代表性的必修实验课:数字逻辑电路实验课的调查数据,作为训练样本。实践课程调查表的数据结构如表1所示。

表1 学情问卷调查指标表
从表1中可以看出,“对该实验课”是教学效果评价的结果,即分类属性,包括三个属性值:A希望多开(简化为“甲”)、B保持现状(简化为“乙”)、C建议烧开或取消(简化为“丙”)。与教学效果相关的八个因素(属性)分别是:是否明确本实验目的(简化为“G1”)、是否预习本实验课(简化为“G2”)、完成本实验是否有困难(简化为“G3”)、对该课程是否有兴趣(简化为“G4”)、能否及时提交实验报告(简化为“G5”)、觉得该实验是否有收获(简化为“G6”)、是否满意老师的指导(简化为“G7”)、是否满意现有的实验(简化为“G8”),每个因素又对应具体的评价内容(属性值),共有23个属性值,这些评价内容几乎反映了教学工作中的各个细节,当然学生进行评价时,个别学生可能不想参与评价,或者随意乱评,这就使数据样本失去了客观性和准确性,造成了离群的数据。但这只是个别情况,绝大多数的学生还是会根据实际情况,给予客观的评价,所以,得到的调查数据是客观的、可靠的。
我们对数据进行噪声处理,再通过数据类型转换,使之符合我们数据挖掘的要求。100个样本数据中类“甲”38个样本数,类“乙”36个,类“丙”26个,根据式(1)计算出分类属性的信息期望
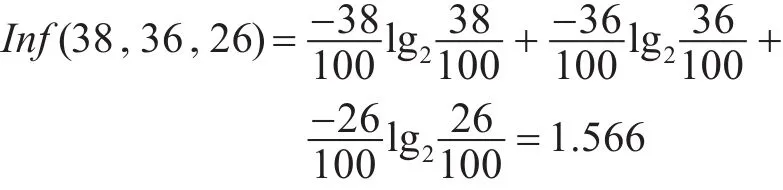
再依次计算样本集中各个测试属性的期望、熵、信息增益、信息增益率。
对于G1(是否明确本实验的目的)=“A”,共有44个样本,类“甲”有15个,类“乙”有16个,类“丙”有13个。由式(1),可以得出G1=“A”的期望如下
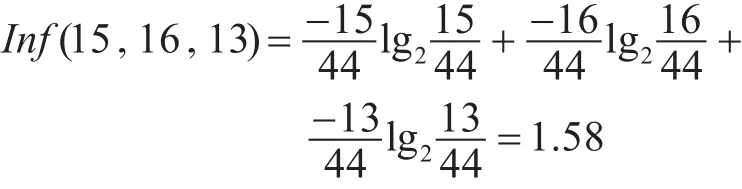
同样根据式(1),计算出G1=“B”、G1=“C”的期望为
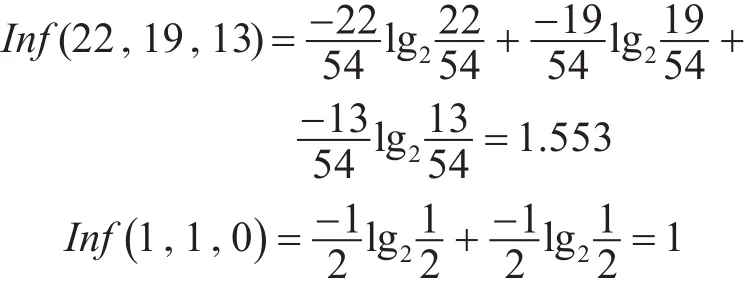
由式(2)可以得出由G1的属性值划分S的信息熵
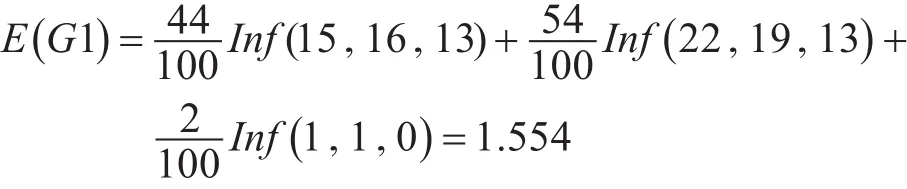
由式(3)可以得出由G1的属性值划分S的信息增益
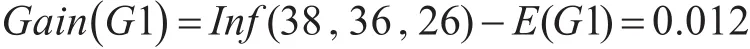
由式(4)可以得出由G1的属性值划分S的信息增益率
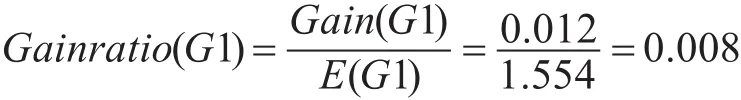
按照上面步骤可以得出其他测试属性的信息增益率分别为
Gainratio(G2)=0.037;Gainratio(G3)=0.004;
Gainratio(G4)=0.293;Gainratio(G5)=0.024;
Gainratio(G6)=0.032;Gainratio(G7)=0.005;
Gainratio(G8)=0.015。
比较上面8个测试属性的信息增益率的值,可知G4的最大,依据C4.5算法属性选择度量的标准,我们选择具有最大信息增益率的G4作为根节点,根据G4的3个属性值,再依据上面产生根节点的方法计算出各个分支的下一层节点,这样递归下去,直至每个分枝的节点都分裂完毕,停止树的生长[9]。为防止“过拟合”,对生成的树进行剪枝处理[10],最终的决策树模型如图1所示。
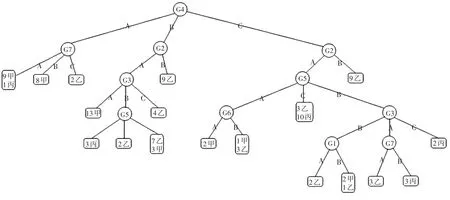
图1 基于C4.5建立的决策树模型
由图1可以看出位于最上面的根节点是“G4”属性,从根节点开始,顺着每个分支继续向下,直到每一个叶节点,形成一条路径,在路径中,节点越靠上的属性,其作用也就越重要。
3.2 模型评估
我们运用weka里的C4.5(J48)和ID3分类器构造决策树模型,由于两种算法的步骤一样,这里我们仅把weka-C4.5生成的可视化模型[11]给出,如图2所示。
与图1比较,借助weka所生成的模型与我们采用C4.5算法所建立的模型完全吻合。基于weka-C4.5输出页面中的Confusion Matrix矩阵如图3所示。
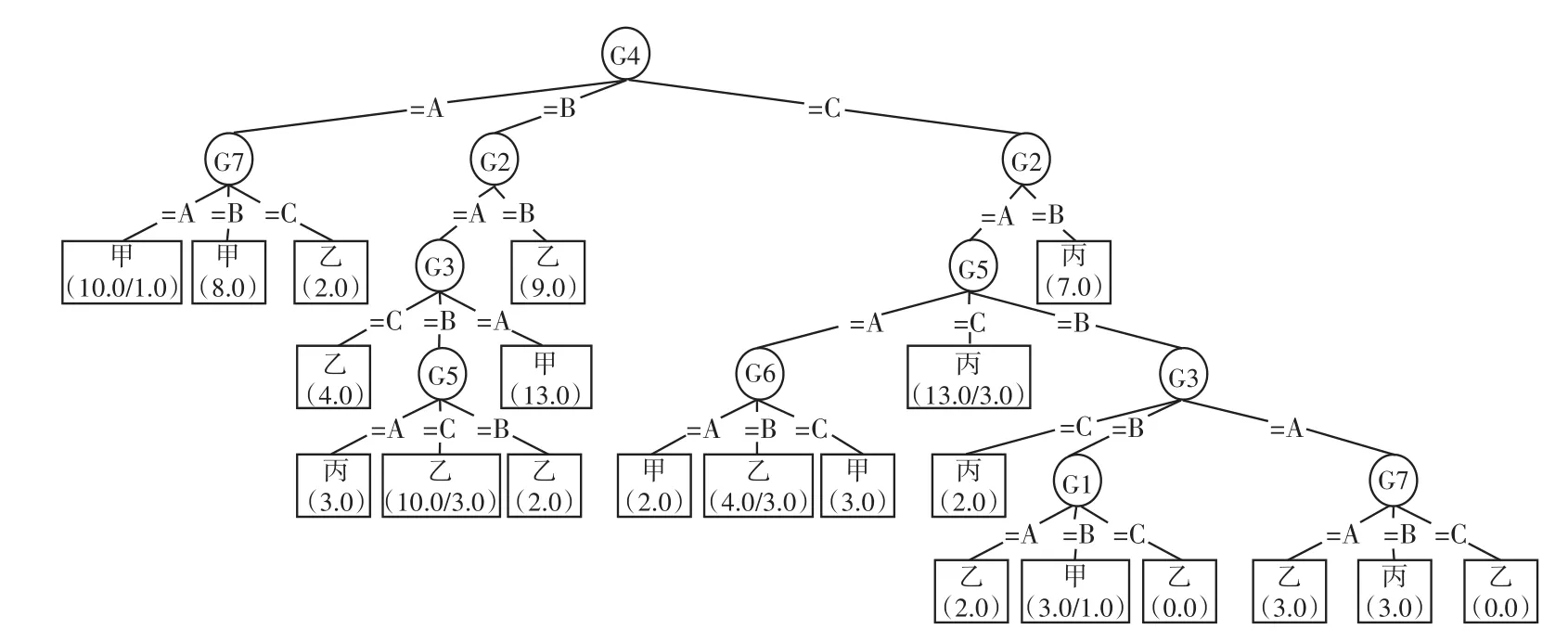
图2 基于weka-C4.5建立的决策树模型

图3 C4.5分类结果
矩阵第一行表示类别属性为甲的样本共有38个,被正确分类的有30个,8个被误判为乙;第二行表示类别属性为乙的样本共有36个,有27个被正确分类,6个被误判为甲,3个被误判为丙;第三行表示类别属性为丙的样本总共有26个,有23个被正确分类,1个被误判为甲,2个被误判为乙;样本被正确分类的比例为(30+27+23)/100=80%,对角线上的值越大,说明决策树模型分类预测得越好[12]。基于weka-ID3输出的Confusion Matrix矩阵如图4所示,准确率为(30+24+17)/100=71%。C4.5和ID3算法训练样本的准确率分别为80%和71%,所以采用C4.5算法能更好地为我们探索提高实践课程的教学效果的路径提供决策支持。

图4 ID3分类结果
3.3 提取分类规则
为了更好地解释和分析结果,结合图1和图2,我们可以提取出下面的分类规则:
规则一:IF G4=“A”AND G7=“A”THEN 类=“甲”。
规则二:IF G4=“A”AND G7=“B”THEN 类=“甲”。
规则三:IF G4=“A”AND G7=“C”THEN 类=“乙”。
规则四:IF G4=“B”AND G2=“A”AND G3=“A”THEN 类=“甲”。
规则五:IF G4=“B”AND G2=“A”AND G3=“B”ANDG5=“A”THEN 类=“丙”。
规则六:IF G4=“B”AND G2=“A”AND G3=“B”ANDG5=“A”THEN 类=“乙”。
规则七:IF G4=“B”AND G2=“A”AND G3=“B”ANDG5=“C”THEN 类=“乙”。
规则八:IF G4=“B”AND G2=“A”AND G3=“C”THEN 类=“乙”。
规则九:IF G4=“B”AND G2=“B”THEN 类=“乙”。
规则十:IF G4=“C”AND G2=“A”AND G5=“A”ANDG6=“A”THEN 类=“甲”。
规则十一:IF G4=“C”AND G2=“A”AND G5=“A”ANDG6=“B”THEN 类=“乙”。
规则十二:IF G4=“C”AND G2=“A”AND G5=“B”ANDG3=“A”ANDG7=“A”THEN 类=“乙”。
规则十三 IF G4=“C”AND G2=“A”AND G5=“B”ANDG3=“A”ANDG7=“B”THEN 类=“丙”。
规则十四:IF G4=“C”AND G2=“A”AND G5=“B”ANDG3=“B”ANDG1=“A”THEN 类=“乙”。
规则十五:IF G4=“C”AND G2=“A”AND G5=“B”ANDG3=“B”ANDG1=“B”THEN 类=“甲”。
规则十六:IF G4=“C”AND G2=“A”AND G5=“B”ANDG3=“C”THEN 类=“丙”。
规则十七:IF G4=“C”AND G2=“A”AND G5=“C”THEN 类=“丙”。
规则十八:IFG4=“C”AND G2=“B”THEN 类=“丙”。
4 结果分析
数据挖掘结果分析:在生成的决策树模型图中,节点越靠上,其作用也就越重要。最上面的根节点是G4,可见“对该实验课是否有兴趣”这一属性是学生对实践课程教学效果评价的关键因素,结合图1和表1我们可以得出如下结论:
1)对于G4=“A”这一分支,结合规则1~ 3可以看出,“是否满意老师的指导”所占的作用次之,这两个作用可以直接得出学生对课程的整体评价,所以,老师激发学生的学习兴趣很重要,其次,在教学过程中,老师多收集学生对该课程的建议,及时改善教学内容,这样才能取得较满意的教学效果。
2)对于G4=“B”这一分支,在图1中,从上到下节点的顺序是:G2、G3、G5,所以这三个因素的重要性依次为“预习实验”、“完成本实验是否有困难”,“能够按时提交实验报告”,结合规则4~9可以看出,老师可以采取措施监督学生完成实验预习,比如写预习报告,然后设置难度适中的课后作业,保证学生按时提交实验报告,可以取得良好的教学效果。
3)对于G4=“C”这一分支,即对实验课没有兴趣,却做课前预习的同学,结合图1和规则10、11可以看出,“能否按时提交实验报告”,“觉得该实验是否有收获”两个因素对课程评价的也有一定的影响,由规则12~16,可以看出因素重要性的顺序依次是:“能否及时提交实验报告”、“完成本实验是否有困难”,最后是“是否满意老师的指导”和“是否明确实验目的”。规则17表明:有13个学生做了预习,却不交实验报告。
5 结语
用C4.5分类算法针对数字逻辑电路实践课程调查数据建立决策树模型,预测的准确率为80%,得出的教学建议具有很大参考价值和可靠的理论依据,把决策树算法与我们具体的调查数据相结合,不仅可以进行分类预测,也可以发现新的问题,比如规则17表明,有13个学生做了预习却不交实验报告,这不是小数目,应该引起我们的注意,很可能是实验内容不够丰富,实验有难度,还可以通过和学生面对面的谈话,来了解具体原因,从而为我们的实践教学提供决策支持。但是我们对决策树的应用研究还是比较浅的,比如形成的分类规则中,哪些规则是比较重要的,遇到更复杂类型的数据怎么改进等等,需要我们做更深的研究。
[1]张棪,曹健.面向大数据分析的决策树算法[J].计算机科学,2016,43(z1):1.
ZHANGYan,CAOJian.Decision Tree Algorithms for Big Data Analysis[J].Computer Science,2016,43(z1):1.
[2]李丽芳.学生评教数据知识挖掘方法应用研究[D].广州:华南理工大学,2015.
LI Lifang.The Application Research of Knowledge Mining Algorithm Based on the Teaching Data of Student'Evaluation[D].Guangzhou:South China University Of Technology,2015.
[3]范明,孟小峰.数据挖掘概念与技术[M].第3版.北京:机械工业出版社,2012:76-77.
FAN Ming,MENG Xiaofeng.Data Mining Concepts and Techniques Third Edition[M].Beijing:Machine Press,2012:76-77.
[4]谭俊璐,武建华.基于决策树规则的分类算法研究[J].计算机工程与设计,2010,31(5):1-2.
TAN Junlu,WU Jianhua.Classification algorithm of rule based on decision-tree[J].Computer Engineering and Desing,2010,31(5):1-2.
[5]周剑锋,阳爱民,刘吉财.基于改进的C4.5算法的网络流量分类算法[J].计算机工程与应用,2012,48(5):71-74.
ZHOU Jianfeng,YANG Aimin,LIU Jicai.Traffic classification approach based on improved C4.5 algorithm[J].Computer Engineering and Applications,2012,48(5):71-74.
[6]Bramer M.Principles of Date Mining[M].London Springer,2013:121-136.
[7]姚亚夫,邢留涛.决策树C4.5连续属性分割阈值算法改进及应用[J].中南大学学报,2011,42(12):3772-3776.
YAO Yafu,XING Liutao.Improvement of C4.5 decision tree continuous attributes segmentation threshold algorithm and its application[J].Journal of Central South University of Technology,2011,42(12):3772-3776.
[8]李孝伟,陈福才,李绍梅.基于分类规则的C4.5决策树改进算法[J].计算机工程与设计,2013,34(12):4321-4325.
LIXiaowei,CHENFucai,LIShaomei.Improved C4.5 decision tree algorithm based on classification rules[J].Computer Engineering and Design,2013,34(12):4321-4325.
[9]刘鹏,姚正,尹俊杰.一种有效的C4.5改进模型[J].清华大学学报,2006,46(S1):996-1001.
LIU Peng,YAO Zheng,YIN Junjie.Improved decision tree of C4.5[J].Tsinghua Science and Technology,2006,46(S1):996-1001.
[10]Thakur D,Markandaiah N,Raj D S.Re optimization of ID3 and C4.5 decision tree[C]//International Conference on Computer and Communication Tecnology,2010:448-450.
[11]杨哲,李领治,纪其进,等.基于最短划分距离的网络流量决策树分类方法[J].通信学报,2012,33(3):90-102.
YANG Zhe,LI Lingzhi,JI Qijin,et al.Network traffic classification using decision tree based on minimum partition distance[J].Journal of Communication,2012,33(3):90-102.
[12]Aggarwal C C,Reddy C K.Data Classification:Algorithms and Application[C]//CRCPress,2014:43-44.
