关联规则挖掘方法在智能卷烟配方维护中的应用
2018-07-06雒兴刚王楠张忠良赵亮汤建国唐加福
雒兴刚,王楠,张忠良,赵亮,汤建国,唐加福
1 杭州电子科技大学管理学院,杭州市杭州经济开发区白杨街道2号大街1158号 310018;
2 东北大学信息科学与工程学院,沈阳市和平区文化路3号巷11号 110819;
3 云南中烟工业有限责任公司技术中心,云南省昆明市五华区红锦路367号 650231
卷烟配方维护是烟草企业维持卷烟稳定生产的基础与核心[1]。通常情况下,成品卷烟配方是由20至30种不同的单料烟按照一定比例配伍而成。所谓卷烟配方维护是指在卷烟产品生产过程中,由于某种客观因素(库存结构,市场成本,进货时间,进货方式等)的变动, 导致某品牌卷烟中某一种或几种单料烟不能够继续使用,就需要从库存中选择其他的单料烟进行替换,同时使原品牌卷烟的成本、感官质量和烟气指标保持在可接受 的范围内。然而,选择合适的单料烟用于替换原有配方中的缺失的单料烟,并维护原卷烟品牌的成本及感官质量和烟气指标的稳定是一项非常困难的工作[2]。因此,烟叶的替换问题是卷烟配方维护的关键问题。
在实际生产中,为了维持卷烟产品质量的稳定,卷烟配方维护人员通过人工经验选择单料烟,通常按照以下四个基本原则来替换单料烟:同等级替换、同香型替换、同类型替换、同部位替换。具体替换步骤如下:(1)当某种烟叶受到库存或成本等因素的影响而不能满足配方时,首先考虑同种同级异地替换;(2)如果品种相同也不能满足,就要考虑同级同地异种替换;(3)如果还不能使香烟的吸味等感官指标维持在可接受的范围之内,则要考虑同种同地高等级替换;(4)如果不能满足有高等级烟叶时,为了维持香烟的吸味等感官指标的稳定,就不能进行同种同地低等级替换,而要考虑同种同级异地替换。传统配方维护方法需要配方人员具有丰富的经验,但是仅靠经验等主观判断方法来进行卷烟配方维护效率低,还会浪费大量的人力、物力和财力,增加成本,无法满足企业快速化、持续化生产的需求[3]。
一方面,随着机器学习、人工智能以及数据挖掘等领域的快速发展,使卷烟配方维护工作实现智能化成为可能[4-5]。另一方面,多年来,烟草企业在卷烟生产和工艺实验的过程中积累了大量的基础数据,为智能卷烟配方维护提供了前提条件。近年来,学者们开始将数据挖掘等智能方法引入到卷烟配方领域中。田临卿等[6]介绍了数据挖掘在烟草农业生产中和烟草工业管理中的应用,并对其应用前景进行了展望。曹鹏云等[7]提出了一种基于核变换和测地距离线的局部线性嵌入的相似性度量计算方法,并以复烤片烟样品质量分布特征为材料进行特征分析与相似性度量。高月兰等[8]选择化学成分、感官特征和烟气指标作为属性,对烟草样品的不同等级烟叶进行了聚类分析,发现了样本特征的相似性以及差异性大小。在智能感官和烟气指标评估方面,Feng等[9]提出了一种结合遗传算法、神经网络、支持向量机、模糊集与专家知识的智能卷烟配方感官评吸系统,以满足卷烟设计要求。王涛[10]针对实际的烟草数据提出基于支持向量机的感官质量评估模型,并取得了理想的结果。邵惠芳等[11]根据烟叶化学成分与评吸质量的关系,建立了BP神经网络模型,可以较好的对烟叶的常规化学成分进行感官质量预测。石子健等[12]集成了五种不同的分类算法,提出了一种基于异质分类器集成系统的成品烟感官质量预测方法。然而,这些研究都是从大量烟草数据中提取出物理化学指标与感官质量及烟气指标之间的映射规则,没有考虑到烟叶的配伍性,无法满足智能卷烟配方维护的要求。
针对上述问题,本文试图通过烟叶的配伍性建立模型从而进行卷烟配方维护,而不用挖掘物理化学指标与感官质量及烟气指标之间的映射规则。关 联规则挖掘(Associate Rule Mining, ARM)是数据挖掘研究领域的热点,可以有效地 挖掘数据间隐含的相互关系,在各个领域得到了广泛的应用[13,14]。在医药领域中,多数研究利用关联规则发现中医方药配伍规律,获得广义药对,建立关联药对与病症间的关系[15,16]以及中药间的关联关系[17,18];在书目管理领域中,通过关联规则挖掘构建书目推荐系统[19,20];在故障诊断领域中,谢龙君等[20]将融合集对分析与关联规则相结合进行故障诊断;在商品销售领域中,利用关联规则方法可以将商品与用户以及商品与商品之间的内在联系进行挖掘,从而指导企业进行市场定位、个性化商品推荐以及营销战略制定等[21,22]。此外,针对关联规则挖掘的规则数目多且不易理解的问题,相关研究[23,24]对所得规则进行了简化,提高了规则利用效率。
本文基于H烟草公司的卷烟配方历史数据,应用关联规则挖掘进行卷烟配方维护。与传统根据人工经验进行配方维护相比,该方法可以有效挖掘出某品牌对应的主要配方、主干成分及单料烟间替代关系。经过规则简化后规则数量控制在101-102数量级,从而获得可理解的规则集,对卷烟配方维护工作具有一定的指导意义。
1 材料与方法
1.1 卷烟配方数据
从H烟草公司获得某品牌成品烟的配方数据。为清晰观察单料烟的变动及搭配情况,保证挖掘结果的有效性,选择3年(即2010年1月到2012年12月)某品牌共104组配方数据进行研究。
叶组配方根据库存量进行多次微调,104组配方中的任意配方基本保持由17至24份单料烟经过一定的比例配制而成。 单料烟共155份,包括6份法国薄片,149份烤片,涉及K326,KRK26,NC297等5个品种,79个不同等级。其中烤片包括19种国外烤片及130种国内烤片,国内烤片来自5个省份的18个市区。
1.2 方法
1.2.1 指标与特性介绍
基于关联规则挖掘方法的理论基础[25],进行了如下的定义。
单料烟项集:单料烟的集合I={I1,I2,…,Ik},其中I(i1 ≤i≤k)代表一个单料烟,k为项集的长度,长度为k的单料烟项集称为k-单料烟项集。
事务T:一些单料烟Ii所组成的配方。
事务数据库D:某品牌烟所有事务T的集合。
关联规则:形如AB的蕴含式,其中AI,BI,并且AB=。其中A和B为 该关联规则的前项集和后项集。
支持度:D中即包含A又包含有B的百分比,即Support(AB)=P(AB)。
置信度:D中在已经包含A的情况下,包含有B的百分比,即Confidence(AB)=P(B|A)=Support(AB)/Support(A)。
单料烟频繁项集F: 满足预定义的最小支持度阈值α的单料烟项集。
频繁项集的反单调性:如果长度为k的单料烟项集I的子集,即(k-1)-单料烟项集,不是频繁的,则I也一定不是频繁的。
1.2.2 基于Apriori的单料烟关联规则挖掘算法
本文基于Apriori 算法挖掘单料烟间的关联规则,具体步骤如下:
输入:单料烟数据库D、支持度阈值α、置信度阈值β。
输出:单料烟关联规则集合。
第一步:根据给定的支持度阈 值α,挖掘所有单料烟频繁项集。
(1)统计数据库D中所有1- 单料烟频繁项集(仅包 含一个单料烟)加入到L1中。
(2)利用L1中的1-单料烟 频繁项集,通过交叉组合生成候选2-单料烟频繁项集,加入C'2。然后在C'2中筛选2-单料 烟频繁项集加入到L2中。例1:如果L1中的1-单料烟频繁项集为a,b,c,d,e,交叉组合后C'2为 {ab,ac,ad,ae,bc,bd,be,cd,ce,de},如果只有ab,ac,ad,de的支持度大于阈值α,则L2为 {ab,ac,ad,de}。
(3)生成k-单料烟频繁项集(k>2)。
连接步:将两个具有前(k-2)个相同项的(k-1)-单料烟频 繁项集进行连接。即将相同的前(k-2)项与两个项集的第(k-1)项连接 成候选k-单料烟频繁项集,加入到C k'中。例2:L2中的2-单料烟频繁项集ab,ac,ad,de,通过连接步生成的候选3-单料烟项集的集 合C3'仅为{abc, abd,acd}。
剪枝步:根据频繁项集的反单调性,从C k'中将不是频繁的候选单料烟项集删除。例3:如果C3'中候选项集abc的一个子集bc不是频繁的,则项集abc也不是频繁的,故将其从C3'中删除,此时C3'为{abd,acd}。
扫描数据库D,筛选C k'中的k-单料烟频繁项集,加入Lk中。
(4)重复第(3)步,当单料烟频繁项集的集合Lk=时停止,得到所有频繁项集L。
第二步:由频繁项集L和置信度阈值β生成关联规则。
(1)产生Lk中每个k-频繁项集(F)的所有非空子集。
(2)扫描数据库D,计算F的每个子集的置信度,若子集A满足置信Confidence(AF-A)≥β,则产生规则AF-A。
1.2.3 关联规则约简
基于Apriori算法挖掘单料烟关联规则,可以很容易被发现卷烟配方数 据间的隐含关系。但是,原始的Apriori算法挖掘单料烟间的关联规则具有很大的局限性。(1)需要计算任意规则AF-A的置信度,并且A的长度可变。(2)上文得到规则包含大量的冗余规则。(3)得到的规则数量巨大,会使实际烟草配方维护的效率大大降低,因此需要进行规则约简。
对于规则约简问题,需要先来验证ABCD与ABC和ADBC之间存在的相互关系。假 设Support(ABCD)≥α, 且Confidence(ABCD)≥β,规则ABCD成立,那么Support(ABC)≥Support(ABCD)=Support(ADBC)。同时满足:

可以得出:规则ABC与规则ADBC同时满足要求成立。所以同理,当挖掘出规则ABCD时,同长度其它规则ABCD,ACBD,ADBC,ABCD,ABDC,ACDB都将成立。
对于烟草配方的规则挖掘,只需要将最基本的规则挖掘出来,由基本规则衍生出来的其它规则必然符合支持度与置信度要求,而且回避了冗余规则,使挖掘得到的规则有效地提高可理解性,约简规则步骤为:
(1)在L中获得长度最大的频繁项集(m-频繁项集)。
(2)由m-频繁项集生成前项个数小于m/2的关联规则,放入候选规则集合ψ中。在ψ中对于长度相同,且包含项集完全相同的规则,仅将前项包含指定个数项集的规则放入最简规则集合Ω中,直至把ψ中所有规则检验完停止。
2 实验测试及分析
2.1 数据预处理
2.1.1 数据预处理
三年的烟草配方数据共涉及到某品牌不同时期104个配方信息,155种单料烟。不同时期的配方事务集中包含多种单料烟,各单料烟“是否”出现看成典型的布尔类型。故在进行实验前需要将不同时段的配方数据表转换为0-1的二进制表。
2.1.2 数据结构
通过对原始烟草数据的整理,得到某品牌原始叶组配方数据矩阵,共104行,155列,对原始叶组配方数据矩阵做0-1规范化处理,每一行代表一个叶组配方,每一列代表一种单料烟。若对应行的配方中含有对应列的单料烟,则为1,反之为0,如表1所示。
2.2 实验结果
假设对104个配方调整是合理的,且感官品质,烟气成分和成本的变化都在可接受范围之内。根据表1所得叶组配方0-1矩阵作为算法的输入条件属性。针对国内烟草企业的卷烟配方特点,这里考虑的是由最长频繁项集所产生的关联规则集合。
如表2所示,为了检测支持度 与置信度对规则数的影响,分别将支持度阈值设置为0.13,0.14,0.15,0.16,置信度阈值设置为0.5,0.6,0.7,0.8。则根据不同支持度的变化,由最长频繁项集产生的平均规则数分别为127345.8,178065,109516.3,27522.75条。

表1 叶组配方0-1矩阵Tab.1 0-1 matrix of formula
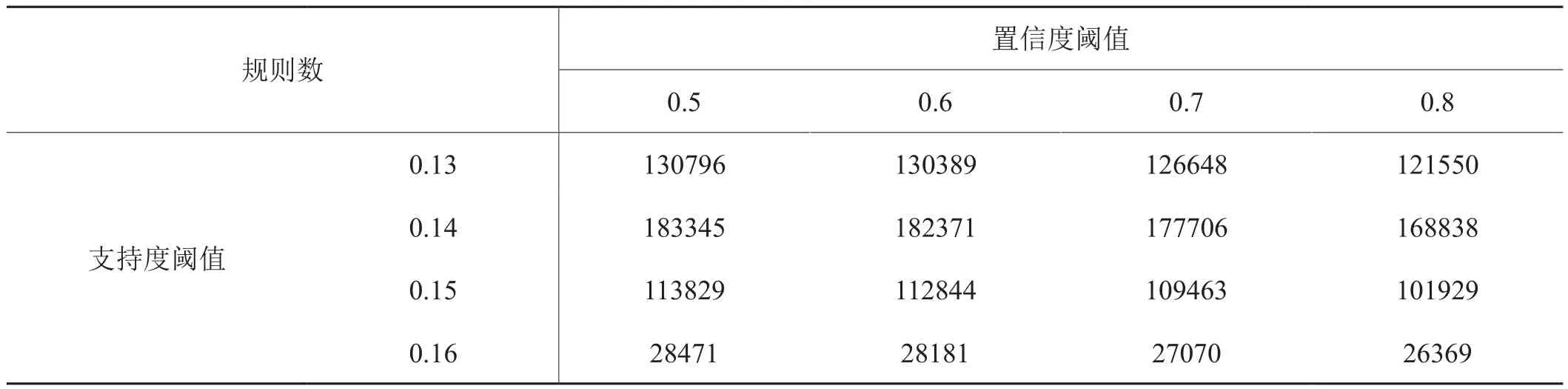
表2 不同置信度和支持度下的规则总数Tab.2 The total number of rules under different confidence and support
为了减少规则数,使挖掘的规则可以简单使用,利用前文所述方法进行规则约简。具体约简规则总数如图1所示。R1表示规则前项为单一项集的规则集合,R2表示规则前项为两个项集的规则集合。Rlɑ表示规则后项为单一项集的规则集合。
通过对全部规则和前项数为1和2的规则的比较,可以发现支 持度为0.14,置信度为0.6的规则较为符合要求。一方面,当未进行规则约简时,规则数处于可接受范围,较为全面,可靠性较好;另一方面,进行规则约简后,R1规则数减少为14条,R2规则数减少为149条,数目较少且配方规则信息保留相对完整,增强了可理解性,减少的规则数如表3所示。
表4内容是通过关联规则挖掘方法得到的结果,其中,表中每位数字对应一种特定单料烟。
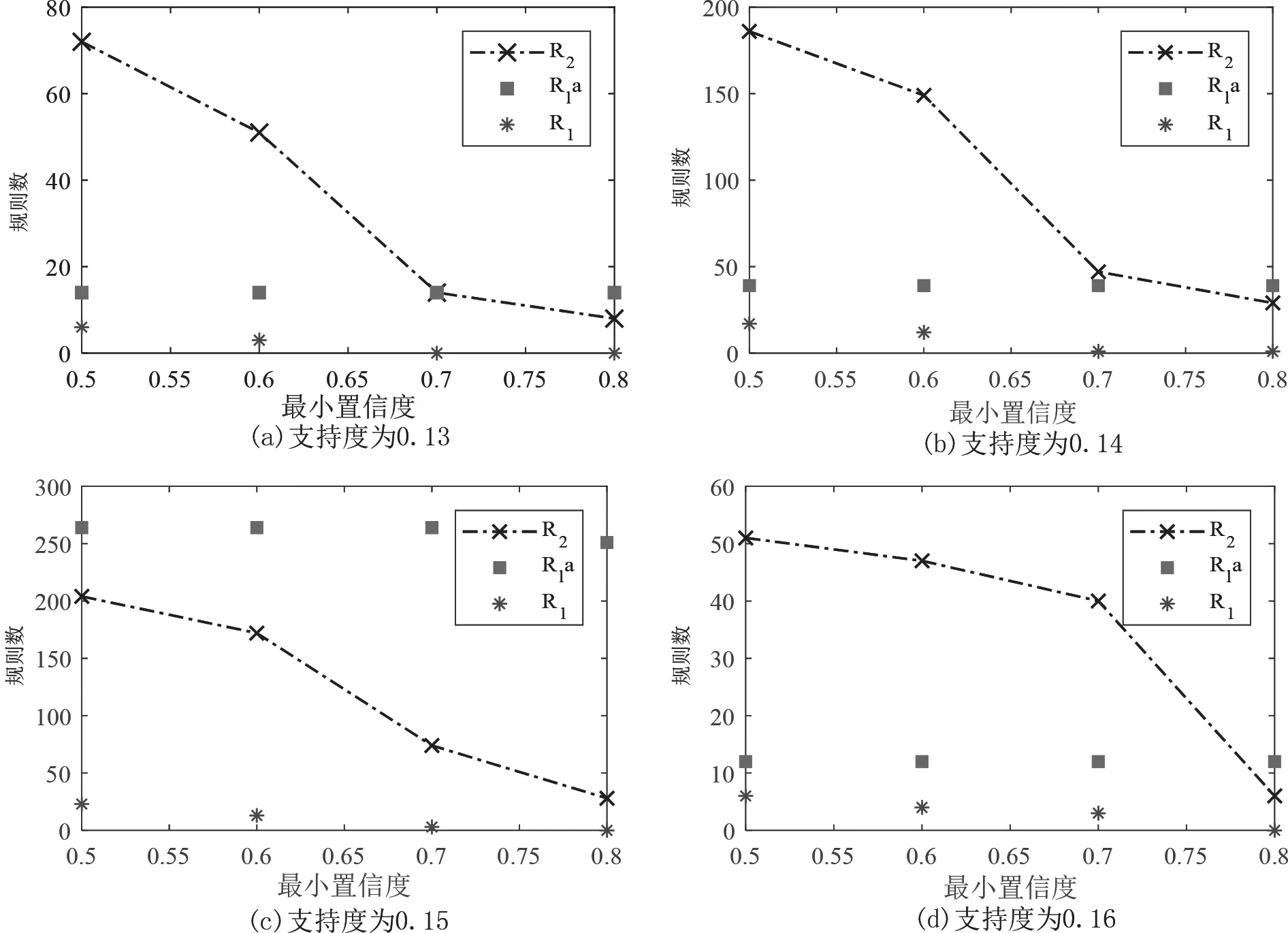
图1 约简后不同置信度和支持度下的规则数Fig.1 Number of reduction rules under different confidence and support after reduction
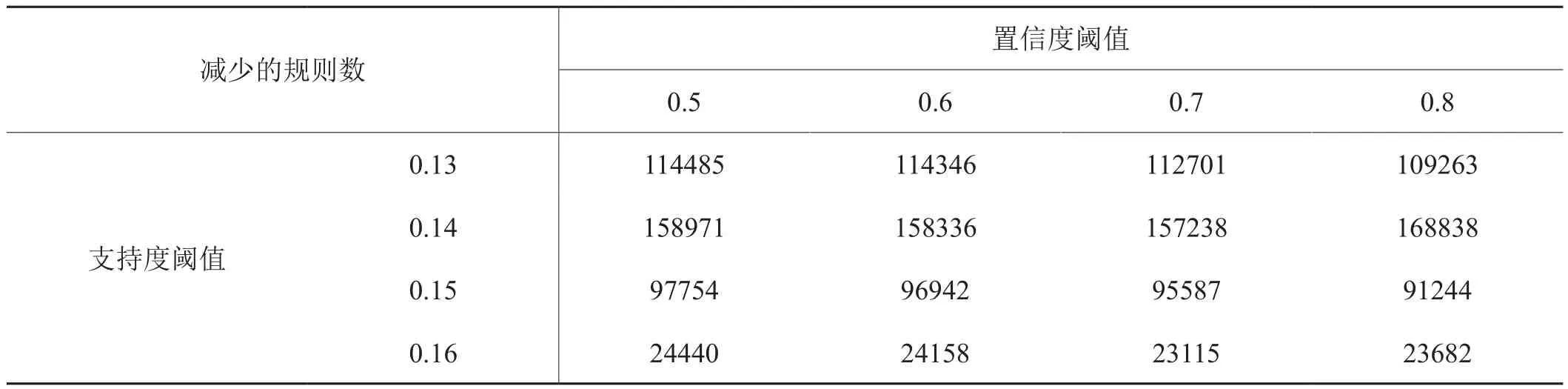
表3 约简后 不同置信度和支持度下减少的规则数Tab.3 Number of rules by different threshold after reduction
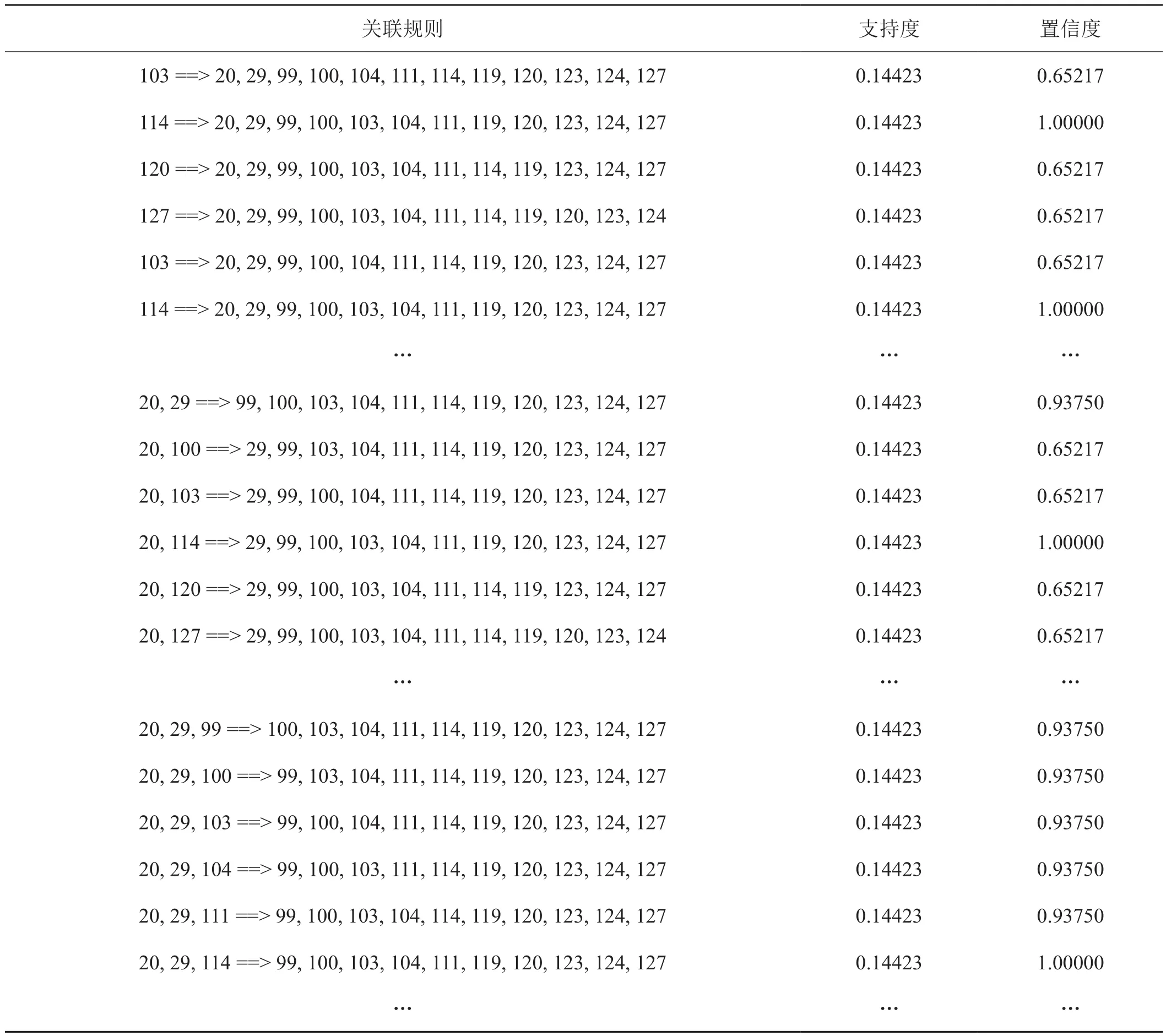
表4 关联规则算法对某品牌配方的实验结果统计Tab. 4 Association rules algorithm statistical experimental results
本研究采用关联规则方法进行挖掘后可以建立对应品牌成品烟的主干单料烟构成,得到配方中某些单料烟组合出现前提下其他单料烟出现的概率以及配方中主干单料烟间的替换关系。从表4关联规则的单料烟项集中得到该品牌的3个主要配方构成成分:
a. 20,29,99,100,103,104,111,114,119,120,123,124,127
b. 20,44,99,100,103,104,111,119,120,121,122,123,124
c. 20,99,100,103,104,111,119,120,121,122,123,124,127
通过对支持度与置信度的计算,可以得出“”左右两端单料烟组在配方数据库中出现的频率,及在“”左端某些单料烟组合存在的前提下,“”右端另一些组合存在的条件概率。置信度为1则反应后项在前项存在的条件下100%搭配存在,对于成品烟的配制具有参考价值。
对a,b,c三组主要配方构成成分进行求“交集”运算,获得其交集部分为20,99,100,103,104,111,119,120,123,124,即该品牌的配方主干成分。所以在该品牌的配制过程中,就可以在主干成分的基础上加入一些其它单料烟进行补充配制,这样有利于维持该品牌的感官评吸品指标的稳定。
同时,将a,b,c三种主要配方构成成分与交集求差,获得三组中的非公共部分的单料烟。具体结果如表5所示。

表5 某品牌配方的主干单料烟与单料烟替换Tab.5 Backbone of single cigarette and the replaced single cigarette
针对非公共部分单料烟的相互替换情况,表6给出了该部分单料烟的特征信息及感官指标值。通过观察表6的单料烟数据及三组非公共部分单料烟,根据人工替换经验并结合单料烟的产地、品种、等级和感官指标,可以在非公共单料烟组合中寻找可以替换的单料烟。根据以上实验结果,针对该品牌烟可进行如下内容的卷烟配方维护:
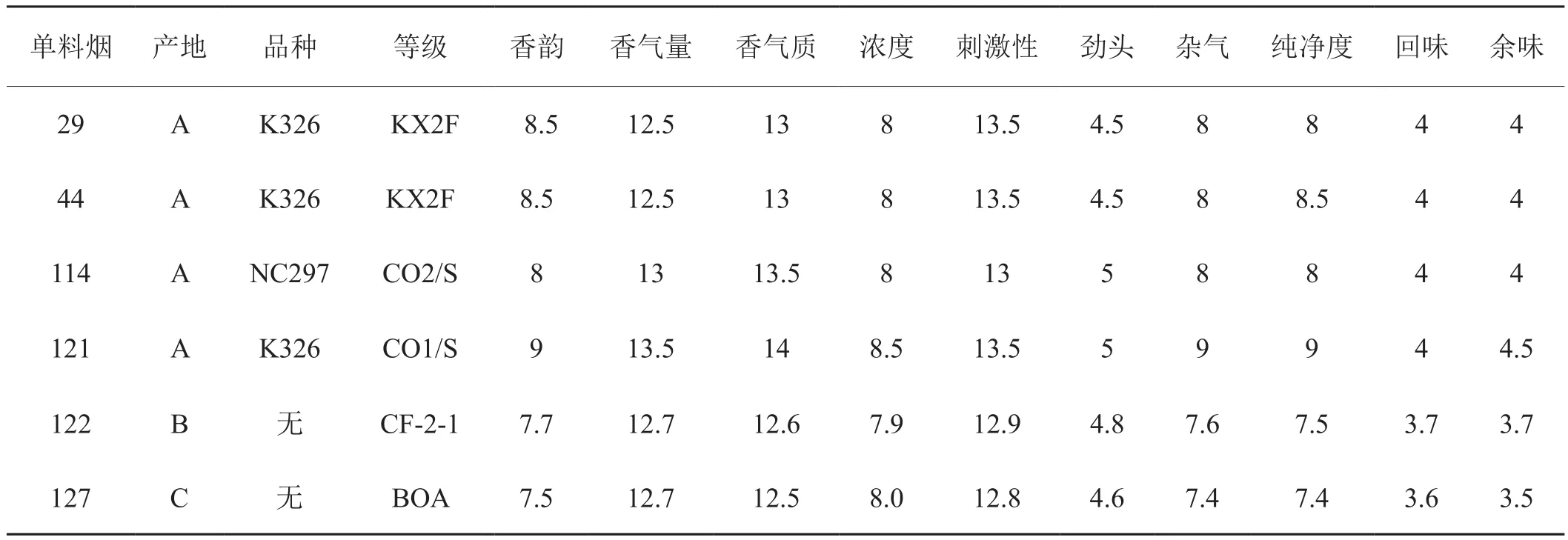
表6 单料烟特征属性及 感官指标数据表Tab.6 Characteristics of single cigarette and sensory index
(1)一对多替换。当29号单料烟缺失时,由表5可知单料烟组(29,114)和(121,122)都可与单料烟127进行搭配使用。其中29和121为产地、品种均相同,并且121等级比29高,而单料烟114和122为感官指标相近的单料烟,符合单料烟替换的人工经验。所以由于某种客观原因导致29号或者114号单料烟不能继续用于生产,为了避免生产停滞,可考虑用单料烟组(121,122)替换单料烟组(29,114)。
(2)多对多替换。当单料烟121或单料烟122缺失时,则不能按照(1)中的规则进行替换,这时可考虑用单料烟组(29,114,127)替换(44,121,122)或(121,122,127)。
(3)一对一替换。在表5中非公共部分的单料烟中,第二组(44,121,122)和第三组(121,122,127)包含公共部分(121,122),所以很可能44和127可以相互替换。观察表6可知单料烟44和单料烟127产地、品种均不同,但是感官指标相近,而且单料烟127比单料烟44的等级高,不同产地的单料烟127可以用于替换单料烟44。
3 结论
烟草企业一般根据配方专家的人为经验来配制成品烟配方,然后通过评吸专家重复评吸打分调整配方来保证成品烟感官指标的稳定性。然而,配方维护这一环节浪费较多人力物力,针对该问题,本文通过数据挖掘手段,根据H烟草集团多年来积累的配方历史数据以及各单料烟出现的频率与搭配组合,直接挖掘某品牌烟的主要配方、配方主干成分及单料烟替换规则,在一定程度上可以辅助卷烟配方的维护及卷烟生产。关联规则挖掘对于界定某品牌配方中单料烟共存问题具有一定积极意义,保证了卷烟配方中单料烟的配伍性。同时,关联规则挖掘在之前已有的卷烟配方数据基础上挖掘单料烟共存,保证后续配方的合理性。规则挖掘得到主干单料烟间的替换关系,则可有效避免因某种单料烟缺失造成的生产停滞,维持生产稳定,而且单料烟替换对于企业提升利润具有重要意义。
本文仅对于卷烟配方中单料烟组合进行研究,实际卷烟生产中还涉及到化学元素构成、各单料烟投放比例、辅料以及感官指标等考虑因素,运用本方法直接指导卷烟配方设计与维护还需要进一步进行研究。
[1]陈艳.基于数据挖掘的卷烟配方质量SPA研究[D].中国海洋大学,2010.CHEN Yan. Research on SPA of Cigarette Recipe Quality based on Data Mining [D]. Ocean University of Chin a, 2010.
[2]林华.数据挖掘技术在卷烟配方优化中的应用[D].中国海洋大学,2008.LIN Hua. Application of Data Mining Technology in Optimization of Cigarette Products Formula [D]. Ocean University of China,2008.
[3]丁香乾,曹均阔,贺英.Kohonen网络与BP网络的集成应用研究[J].中国海洋大学学报(自然科学版),2003,33(4):615-620.DING Xiangqian, CAO Junkuo, HE Ying. Research on the Integration of Kohonen and BP Network [J]. Journal of Ocean University of Qingdao, 2003, 33(4): 615-620.
[4]Venkatadri. M, Reddy LC. A Review on Data mining from Past to the Future [J]. International Journal of Computer Applications,2011, 15(7): 19-22.
[5]谢剑平.形势与未来:烟草科技发展展望[J].中国烟草学报,2017,23(3):1-6.XIE Jianping. On the Development Prospects of Tobacco Science and Technology in China [J]. Acta Tabacaria Sinica, 2017, 23(3):1-6.
[6]田临卿,许自成.数据挖掘技术在烟草行业中的应用[J].中国农业科技导报,2012(06):84-90.TIAN LinQing, XU Zicheng. Application of Data Mining Technology in Tobacco Industry [J]. Journal of Agricultural Science and Techology, 2012 (06):84-90.
[7]曹鹏云,付秋娟,宫会丽,等.高维空间下烟叶质量相似性度量方法研究[J].中国烟草科学,2013(3):84-88.CAO Pengyun, FU Qiujuan, Gong Huili, et al. Similarity Measurement Method of Tobacco Leaves in High Dimensional Space [J]. Chinese Tobacco Science, 2013(3): 84-88.
[8]高月兰,张延军,黄平俊,等.聚类分析在卷烟配方中的应用[J].中国农学通报,2006,22 (2): 103-106.GAO Yuelan, ZHANG Yanjun, HUANG Pingjun, et al. The Application of Cluster Anlysis on Cigarette Blending [J]. Chinese Agricultural Science Bulletin, 2006, 22(2): 103-106.
[9]Feng T J, Ma L T, Ding X Q, et al.. Intelligent Techniques for Cigarette Formula Design [J]. Mathematics & Computers in Simulation, 2008, 77(5/6): 476-486.
[10]王涛.SVM在配方感官评估中的应用[J].微计算机信息,2010,26(10):36-238.WANG Tao. Application on SVM in Formulating Sensory Evaluation [J]. Microcomputer Information, 2010,26(10):36-238.
[11]邵惠芳,许自成,李东亮,等.基于BP神经网络建立烤烟感官质量的预测模型[J].中国烟草学报,2011, 17(1):19-25.SHAO Huifang, XU Zicheng, Li Dongliang, et al. The Establishment of BP Neural Network based Models for Predicting Tobacco Leaf Sensory Quality [J]. Acta Tabacaria Sinica, 2011,17(1): 19-25.
[12]石子健,汤建国,张忠良,等.多分类器集成系统在卷烟感官评估中的应用[J].中国烟草学报,2016,22(1):24-31.SHI Zijian, TANG Jianguo, ZHANG Zhongliang, et al. Application of Multiple Classifier Systems in Cigarette Sensory Evaluation [J].ACTA TABACARIA SINICA, 2016, 22(1): 24-31.
[13]何月顺.关联规则挖掘技术的研究及应用[D].南京航空航天大学,2010.HE Yueshun. Research and Application on the Technologies in Mining Association rules [D]. Nanjing University of Aeronautics and Astronautics, 2010.
[14]Maragatham G, Lakshmi M. A Recent Review on Association Rule Mining [J]. Indian Journal of Computer Science & Engineering,2012, 2(6): 831-836.
[15]宫俊,董俊龙,梁茂新,等.基于关联规则的广义药对最适合病证的挖掘方法[J].东北大学学报,2011(8):1097-1100.GONG Jun, Dong Junlong, LIANG Maoxin, et al. An Association Rule-Based Method for Finding Generalized Herbs Suitable for Syndromes [J]. Journal of Northeastern University, 2011(8):1097-1100.
[16]Nahar J, Imam T, Tickle K S, et al. Association Rule Mining to Detect Factors which Contribute to Heart Disease in Males and Females [J]. Expert Systems with Applications, 2013, 40(4): 1086-1093.
[17]季涛,宿树兰,尚尔鑫,等.基于关联规则的中医药治疗消渴症的用药规律与特点探析[J].中华中医药杂志,2016(12):4982-4986.JI Tao, SU Shulan, SHANG Erxin, et al. Determining the rules of traditional Chinese medicine on treatment of consumptive thirst based on association rules mining [J]. China Journal of Traditional Chinese Medicine & Pharmacy, 2016 (12): 4982-4986.
[18]宫兴伟.中药复方智能挖掘的关键技术研究及系统实现[D].西南交通大学,2017.GONG Xingwei. The Key Technical Reserch and System Implelent of Intelligent Mining for Traditional Chinese Medichine Compound[D]. Southwest Jiaotong University. 2017.
[19]刘静.数据挖掘算法在书目推荐系统中的应用研究[D].郑州大学,2011.LIU Jing. Application of Data Mining Algorithm in Bibliographic Recommendation System [D]. Zhengzhou University, 2011.
[20]谢龙君,李黎,程勇,等.融合集对分析和关联规则的变压器故障诊断方法[J].中国电机工程学报,2015(2): 277-286.XIE Longjun, LI Li, CHENG Yong, et al. A Fault Diagnosis Method of Power Transformers by Integrated Set Pair Analysis and Association Rules [J]. Proceedings of The Chinese Society for Electrical Engineering, 2015, 35(2): 277-286.
[21]侯雪波,田斌,葛少云,等.关联规则技术在电力市场营销分析中的应用[J].电力系统及其自动化学报,2005, 17(2): 67-72.HOU Xuebo, TIAN Bin, GE Shaoyun, et al. Application of Association Rules Techniques in Electric Marketing Analysis [J].Proceedings of the CSU-EPSA, 2015, 35(2): 277-286.
[22]寇宇.关联规则挖掘在电信产品交叉销售中的应用研究[D].哈尔滨工业大学,2010.KOU Yu. Research on the Application of Association Rules in Telecom Product Cross Selling [D]. Harbin Institute of Technology,2010.
[23]杨宇.个性化推荐的关联规则算法研究[D].东南大学,2016.YANG Yu. Research on Association Rules Algorithm for Personalized Recommendation [D]. Southeast University, 2016.
[24]Lin W, Alvarez S A, Ruiz C. Efficient Adaptive-Support Association Rule Mining for Recommender Systems [J]. Data Mining & Knowledge Discovery, 2002, 6(1): 83-105.
[25]Hipp J, Ntzer U, Nakhaeizadeh G. Algorithms for Association Rule Mining - A General Survey and Comparison[J]. Acm Sigkdd Explorations Newsletter, 2000, 2(1): 58-64.
[26]王爱平,王占凤,陶嗣干,等.数据挖掘中常用关联规则挖掘算法[J].计算机技术与发展,2010(4): 105-108.WANG Aiping, WANG Zhanfeng, TAO Sigan, et al. Common Algorithms of Association Rules Mining in Data Mining [J].Computer Technology & Development, 2010(4): 105-108.
[27]Han J, Kamber M, Pei J. Data Mining: Concepts and Techniques[M]. Morgan Kaufmann, 2011: 259-264.
