基于深度学习的室内场景识别的研究
2018-07-06张明桂凯
张明,桂凯
(上海海事大学信息工程学院,上海 201306)
0 引言
深度学习最早由Hinton[1]等人在2006年提出。近年来深度学习的快速发展,在各行各业都有广泛的应用,例如人脸识别领域,无人驾驶领域等。室内场景识别的难点在于场景图像元素很多而且还很复杂,传统的场景识别研究的比较多,然而利用深度学习来解决室内场景识别的研究还很少。
目标检测是室内场景识别的核心组成部分,在多年的发展过程中产生许多经典算法。N.Dalai和B.Triggs提出梯度分布直方图HOG[2]特征(Histogrames of Oriented Gradients),使用SVM分类器用于行人的目标检测,该方法的优点是提取的边缘特征可以较好地展示局部特征信息,缺点是需要图像中的人物保持直立状态才有较好的识别效果。Felzenszwalb等人在HOG特征的基础上提出多尺度形变模型(Deformable Parts Models,DPM)[3]。DPM检测方法大体与HOG一致,通过使用SVM(Support Vector Machine)训练得到待测物的梯度模型(Model),简单的说就是模型和目标匹配进行检测。DPM在模型上做了很多改进工作,DPM方法被认为是目标检测与识别领域的重要里程碑。
特征提取是室内场景识别中另一个重要部分,传统的人工特征设计虽然能解决一些问题,但是泛化能力较弱,需要人工深度参与,并且需要人工拥有丰富的专业知识。相较而言,深度学习中特征学习不需要人工过多的参与其中,因此逐渐取代了人工设计特征。研究表明,使用深度学习技术对场景进行识别的准确率要比传统方法要高很多[4-5]。
由于传统的室内场景识别中需要大量的专业人员参与特征设计,时间长、工作量大。因此本文提出使用深度学习技术来解决特征设计的难题。具体来说就是先通过原图得到高斯金字塔图片集,然后采取优化的区域选择算法得到待测图片的显著区域,接着使用CNN网络对显著区域的图像进行特征学习,最后根据多层感知机对特征进行场景类别判断。相比传统的室内场景识别方法,本文方法优势主要体现在不需要人工过多的参与特征设计,利用神经网络的学习特征相比人工特征设计效果提升明显。同时,使用多尺度提取特征比单一尺度的特征提取,特征信息更丰富,对场景识别准确度的增加有明显提升。室内场景识别的流程图如图1所示。
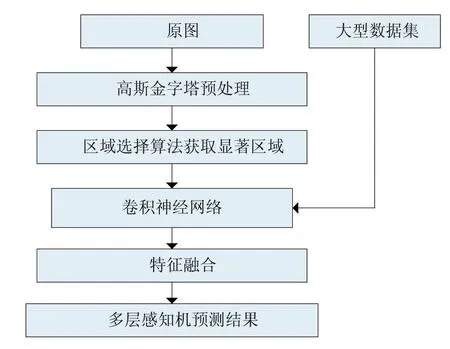
图1 室内场景识别流程图
1 显著区域提取
显著区域是图像中最能表现图像内容的区域,对应到室内场景中就是指能够代表场景内容特征的区域。通过获取图像显著区域的特征,可以增加场景识别的准确度。
1.1 多尺度预处理

其中G(n+1)(i,j)表示新图像,Gn表示原始图像。W(m,n)=W(m)*W(n)是长度为5的高斯卷积和,新图像Gn+1是通过对原图像Gn进行偶数行采样而得到。用MATLAB编程运行如图2所示。
根据人眼视距的特点,景物尺寸的大小和其所在位置的距离都会影响到目标物的判断与识别。在卷积神经网络的特征学习过程中,一般采用池化方法来解决由于景物尺寸大小带来的影响,不过这样就会使得卷积神经网络的规模变得非常大,影响网络的性能,同时还会降低学习模型对目标的定位与描述。
为了解决这个问题,本文提出利用高斯金字塔[6]对图像进行预处理。高斯金字塔过程是对原图像进行多尺度像素采样,生成一系列不同分辨率的图像。本文主要使用下采样,通过对一张图片选取高斯金字塔中三张图片输入到卷积神经网络中,由于图像视野窗口一定,而每张图片的像素点所包含的背景信息是不同的,可以得到更好的图像表示效果。高斯金字塔的图像可以采用如下公式来获取:

图2 高斯金字塔图片
1.2 区域选择
陈媛媛在文献[7]中介绍了通过阈值法提取图像显著矩形区域的方法。具体做法是通过相关算法得到二值化的图像。然后设定一个初始值为T的阈值,通过计算图像中所有小于阈值T的像素平均值A1以及大于阈值T的像素平均值A2,新的阈值T'取A1和A2的和的均值,反复计算直道两次阈值的差小于1,最后得到的阈值为最终阈值。对于大于阈值的点,用矩形框覆盖,最后形成的矩形区域即为显著区域。
受陈媛媛方法影响,本文中将待测场景图像的每一个点进行判断,分为显著类或非显著类。这个点可以是一个像素,一个区域,或一个目标。通过该方法估算每个点的显著度,显著度指的是该点属于显著类的概率。在知道场景图像的位置信息以及特征信息的前提下,显著度检测可以采用贝叶斯定理公式进行推导,本文在陈媛媛方法的基础上做了改进,待测场景图像中某一点的显著度公式如下:

上式中变量Sx是二值变量,表示该点属于显著类还是非显著类,变量F和变量L分别表示该点的特征信息与位置信息,fx和lx表示的是未知点x的特征信息和位置信息。因此,通过上式待测点x的显著度SDx的概率可以用公式表示为p(Sx=1|F=fx,L=lx)。
因为特征图表示的是图像的不同特征,每个特征之间是相互独立的,如果需要对不同的特征进行比较,需要将这些特征图的取值设定标准,而且取值区间应当在相同的范围内,对特征图进行标准化的操作如下:
(1)对于计算得到的图像中的点的显著度,需要转化成一个取值区间[0,N];
(2)将待测图划分成一个个小的区域,然后将每一个小区域得到的显著度最大值N以及周围的局部最大值n找出来;
(3)对于待测图中所有点,计算(N-n)2。
通过上述步骤,可以根据(N-n)2的取值变化对图像中点的显著度区域进行判断。如果取值变化不大,则表示该幅图中没有很显著的区域,因为跟周围的点区别不明显。如果取值变化很大,说明该幅图确实有很明显的显著度区域。
2 特征学习
室内场景识别研究中,传统的人工特征设计都是基于特殊的场景进行。随着深度学习的快速发展,可以采用深度学习技术对室内场景识别进行研究。
卷积神经网络
卷积神经网络[1](Convolutional Neural Networks,简称CNN)是一种多层神经网络,其隐藏层由卷积层和池化层以及全连接层组成。选用良好的卷积神经网络模型不仅可以取得较好的识别效果,同时可以提升识别效率,减少训练参数,加快训练时间等。LeNet-5是最经典的卷积神经网络,其结构如图3所示。
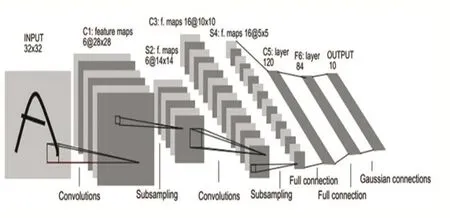
图3 LeNet-5卷积神经网络
上图中C1,C3,C5表示的是卷积层,S2,S4是池化层,F6是全连接层,最后一层是输出层。卷积神经网络通过卷积核提取图像的特征,每个卷积层中都有多个特征平面(Feature Map),同个特征平面的神经元共享权值。对待测图像进行卷积操作,利用局部感受野和共享参数等特性,使用池化层对图像进行局部下采样,可以有效减少处理的数据量,同时保留有效的数据信息。卷积神经网络的训练过程以图3为例,输入的图像大小为32×32,若卷积核大小为5×5,通过第一层卷积操作后,得到28×28的特征图。然后进入第二层池化层,输入是以卷基层的输出为基础,若池化采用2×2均值操作,则得到14×14的池化层数据。如此反复操作,最后通过损失函数计算误差,通过误差修正权值,从而达到训练目的。
3 室内场景识别方法
利用深度学习解决室内场景识别的研究主要从两个方向入手,一个是场景图像的显著区域提取,一个是利用卷积神经网络进行特征学习。本文的研究方法也是从这两方面展开。
3.1 多尺度显著区域的提取
为了解决视距原因造成的目标室内场景识别准确度的影响,本文提出多尺度显著区域提取的方法来优化该问题。具体做法如下,对于一幅室内场景图像A,将原图标记为(Q1=A),使用高斯金字塔对A预处理,提取两张不同分辨率图像,然后通过区域选择方法提取两张图像的显著度,标记为Q2和Q3。通过Q1,Q2和Q3组成的多尺度显著区域进行实验,结果表明相比单一尺度的特征提取,多尺度的显著区域特征提取可以更好地表示室内场景信息,同时识别准确率有明显的提升。
3.2 显著区域的特征学习
通过上述方法提取得到的显著区域Q1、Q2和Q3,利用卷积神经网络对其进行前向传导,提取对应的特征U1,U2和U3。

上式中,W表示权重,b表示偏置。Q(k)表示输入,g(G(k);(W,b))表示对输入Q(k)进行前向传导。通过卷积神经网络提取三个不同尺度下的显著区域特征,本文采取加权平均的方式对获取的特征进行融合,具体如下:

其中α+β+γ=1。
U表示融合后的显著区域特征,为了充分提现多尺度下特征提取的互补性,取α=β=γ=1/3,由于多层感知器在图像识别方面的广泛应用,预测场景类别时可以训练一个多层感知机(MLP),具体如下:

Z是MLP的输出,即为针对场景类别的一个概率分布。MLP的损失函数定义为:
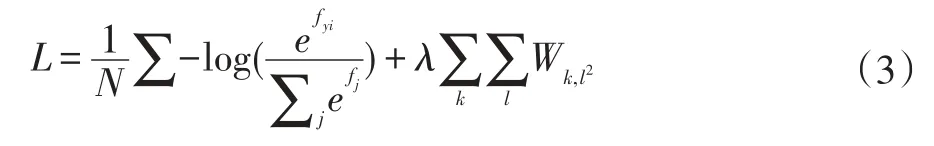
上式中,fj表示得分向量的第j个元素的得分,yi代表正确的类别。Softmax函数将一组向量的任意数值压缩到0和1之间,使其和为上式即模型的优化目标函数,其中第二项为二次正则项。我们的目标是通过训练,可以最小化损失。因此本文采用了Adam方法[8]对模型进行训练。Adam方法的优化公式为:

上式中,L表示损失函数,下标t代表迭代的次数,i代表训练样本的标号,W为权值,mt和vt是引入的力矩估计参数,α是学习率,β1和β2是自适应参数。室内场景的类别由多层感知机(MPL)中预测概率最大的那一类所确定。

4 实验分析
实验所用的卷积神经网络框架为Caff,该框架支持Python和MATLAB接口。实验所需图片数据库选用的是MIT-67[9],该数据库包含的室内场景图像比较丰富,在场景识别领域使用广泛,部分场景图片如图4。为了验证本文方法,做了如下说明。
(1)显著区域的选择,选择了原图Q1以及经过高斯金字塔预处理得到的Q2和Q3。相比只选用原图Q1,由Q1、Q2和Q3组成的多尺度显著区域可以更准确地表示场景信息。
(2)特征的提取,对三个不同尺度的显著区域特征提取,输入到卷积神经网络的图像大小均为32×32。同时将学习速率α和权值λ的值分别设置为1×10-5和5×10-4。对于α的取值,试验结果表明1×10-5是理想的学习速率。而λ则是基于经验值,并未进行特别的调试。
实验结果
本文所选取的MIT-67数据库包含了67个室内类别图像,共15620张图像。每种类别的图像数量上有差异,但是都不少于100张图像,所有的图像都是JPG格式。为了方便研究,本文选择的图像都是常见的如卧室、厨房等室内场景。每种场景图片各选择30张,共180张图片。选择30张图像进行室内场景识别模型测试,剩下150张进行场景识别模型的训练。表1展示的是预测准确度。
从图表可以看出,办公室和卧室的识别准确率最高,达到75%以上,原因可能是它们的室内特征相对单一明显。而客厅和厨房的准确率在60%-70%之间,要低于卧室和办公室,分析原因可能是显著度提取不够明显,导致特征学习出现偏差。总体而言,本文使用的基于深度学习的室内场景识别方法是有效的。
其次,与传统单一人工特征设计的场景识别的准确率的对比,将待测图片放入训练好的室内场景识别模型中进行测试,其中HOG,LBP,GIST[10]是传统的单一的人工特征设计在场景识别中的准确率。Q1-Q3是指多尺度下特征融合后的场景识别准确率。测试结果如图5所示。
从图5可以看出,Q1-Q3的识别准去率在50%左右,相比单一尺度的特征学习的准确度提升5%,即表中Q1、Q2、Q3所示。同时相比传统的人工特征设计的场景识别算法优势明显。从而可以得出本文提出的方法在室内场景识别的研究中是有效的,也说明未来使用深度学习技术进行场景识别将会成为主流的研究方向。
5 结语
室内场景识别由于室内环境的复杂性,一直是研究的热点与难点,随着深度学习的发展,采用不同的学习模型取得的效果也是不一样的。通过选择更好的学习模型,同时在优化神经网络的参数方面进行深入研究,可以进一步改善实验的结果。
[1]HINTONGE,OSINDEROS,TEHYW.A Fast Learning Algorithm for Deep Belief Nets[J].Neural Computation,2006,18(7):1527-1554.
[2]Dalal N,Triggs B.Histograms of Oriented Gradients for Human Detection[C].In 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition(CVPR'05)2005 jun 25(Vol.1,pp.886-893).
[3]Felzenszwalb PF,Girshick R B,McAllester D,et al.Object Detection with Discriminatively Trained Part-Based Models[J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,2010,32(9):1627-1645
[4]KRIZHEVSKY A,SUTSKEVER I,HINTON G E.ImageNet Classification with Deep Convolutional Neural Networks[C].Lake Tahoe,USA:MIT Press,2012:1106-1114.
[5]SZEGEDY C,LIU W,JIA Y,et al.Going Deeper with Convolutions[C].Boston,USA:IEEE,2015:1-9.
[6]刘晨羽,蒋云飞,李学明.基于卷积神经网的单幅图像超分辨率重建算法[J].计算机辅助设计与图形学学报,2017(09).
[7]陈媛媛.图像显著区域提取及其在图像检索中的应用[D].上海交通大学,2006
[8]D.kingma,J.Ba.Adam.A Method for Stochastic Optimization[C].International Conference for Learning Representations,2015.
[9]QUATTONI A,TORRALBA.A Recognizing Indoor Scenes[C].Miami,USA:IEEE,2009:413-420.
[10]ZUO Z,WANG G,SHUAI B,et al.Learning Discriminative and Shareable Features for Scene Classification[C].ECCV.Zurich,Switzerland:Springer,2014:552-568.
