基于流程挖掘的业务流程模块推荐方法研究
2018-07-05复旦大学软件学院上海200433
郑 光 键(复旦大学软件学院 上海 200433)
0 引 言
在市场竞争日益加剧的今天,如何建立合理的业务流程模型,如何提升业务流程的质量与效率已经成为企业发展的重要问题。而业务流程设计正是企业流程管理中的关键步骤,但设计业务流程是一件比较耗时耗力的工作。推荐合适的流程模型帮助用户设计流程,在最近几年中得到了学术界的充分关注,但目前的方法检索结果精度较低,粒度较粗,对用户的建模支持力度有限[1]。
流程挖掘技术在近几年来不断受到业界的关注,还为流程推荐研究提供了新的思路和方向。流程挖掘的基础是流程日志,流程日志准确地记录了业务流程具体活动与资源组合调度等信息,从中可以有效地挖掘出流程模式与业务流程绩效[2-4]。通过流程日志的挖掘能够最大程度地获得业务流程的特征信息,从而对流程模块化推荐提供必要的信息和帮助。
模块化分析是业务流程推荐的基础,复杂的业务流程由若干流程模块组合而成。合理的业务流程模块应当具有高内聚、低耦合、功能独特化等特点,且相互之间的依赖程度较小[5]。基于流程块的业务流程建模能够重用经过实践检验的流程块,经过适当调节后从而减少用户建模的时间,加大对用户建模的支持力度。Clara等[6]总结了业务流程中的数种变化模式,以及流程模型库中的可变性,在建模时只要在流程模块的基础上进行少量调整便能提高流程建模的效率。Shi-Chen等[7]以松散耦合为目标,提出了基于设计结构矩阵的流程分解方法。而基于Petri网的业务流程建模方法一般采取“任务细化”的方式来进行模块化分析,文献[8]则对基于Petri网的复杂工作流模型的简化提出了自己的策略。但是上述的流程模块化分析存在注重模型的逻辑结构,而对流程模型的语义重视不够等问题。Mending等[9]指出,过程模型的价值不仅仅取决于逻辑结构,还取决于模型的标签语义价值,文章尝试从认知科学的角度来验证说明:建模过程中的语义信息是保证建模质量的一个重要标准,通过合理的活动标签能够改善人们对建模模型的理解。
目前在基于推荐的流程建模研究中涉及的流程块是基本的逻辑组成单元或者是单个活动,文献[10]针对不确定的业务流程,为提高流程的柔性,综合针对单个用户以及用户群的推荐结果,推荐下一个需要执行的活动。这里的活动块粒度较小,不具备高内聚低耦合的特点,只适合在流程建模时推荐单个或者少数活动,效率不高且同样在活动的功能语义角度描述方面存在不足。除此之外,还有一些研究尝试从流程建模过程中角色的角度来入手,文献[11]提出了一种利用流程挖掘生成角色块的方法,基于角色块的流程模型突出角色之间的关系。除此之外,如何对推荐结果进行合理的评价还存有一定的限制,Koschmider等[12]提出了一个基于标签相似度匹配的流程活动推荐系统,给出相应的相似度评分。但是文章最后仅从认知负荷理论入手,通过问卷调研的方式对所推荐的流程活动进行证明其有效性,缺乏如流程绩效、活动质量等定量角度的证明。
合理的流程模型推荐方法能够帮助用户推荐合适的流程模块,从而帮助企业发挥资源价值,改善企业产品的质量,最大程度地提升企业业务流程的绩效。针对目前业务流程模块推荐的现状,本文提出了一种基于流程挖掘技术的业务流程模块推荐方法。实验表明,基于流程挖掘的业务流程模块推荐方法能够提高流程模块推荐的准确性,也更加符合流程模块推荐中的语义性需求与功能主题的特性。
1 基于流程挖掘的模块化分析
流程挖掘技术能够从工作流管理系统WfMS(Workflow Management System)的事件日志中挖掘出所需的流程信息,现在已经成为了企业改进流程质量的一种重要手段[13-14]。本文运用流程挖掘技术从日志中挖掘出流程模型等信息,用于模块化分析和绩效预测。
在获取到流程日志数据之后,在进行深入分析前还需要对数据进行数据集成、数据清洗等预处理操作。
1.1 活动特征挖掘
基于预处理后的流程日志,我们可以获得该流程的模型表示、数据流等信息。在实际业务场景中,一个完整的业务流程通常由一系列的活动组成,在流程中执行一次活动称为一个事件。流程活动特征是流程模块化分析的基础,因此,首先要做的是对活动特征进行挖掘。
流程活动具有许多属性和特征,除了从流程日志中可以直接获取的执行角色、起始时间、活动成本等,还包括了从流程日志中挖掘出来的活动业务特征及交互信息等[15]。在介绍活动建模特征之前,引入一些符号。A为流程活动集合,即A=(a1,a2,…,an),其中n代表流程中活动的总个数;R为流程资源集合,即R=(r1,r2,…,rk),其中k表示流程中资源的总个数;记流程日志为L;CapR(a)为能够处理活动a的资源集合。
从流程日志中可以直接定义的活动特征如下:
定义1角色 角色指一个流程活动的执行者,如销售人员、采购人员等。
定义2时间 时间指完成该活动的时间间隔,取流程日志中该活动所有执行时间的平均值。
定义3地点 指完成该流程活动的所需地点场景。
除此之外,通过流程挖掘技术还可以从流程日志中挖掘出流程的业务特征和交互属性:
定义4资源偏好度 不同流程活动对完成活动所需资源具有不同的偏好,流程日志中的历史记录可以反映这一偏好,具体体现在不同资源对该活动的执行次数上。对活动的资源偏好建模,令流程日志L中资源r执行活动a的次数记为Count(r,a),定义活动a对资源r的偏好度如下:
(1)
式中:AvgCount(a)为资源集CapR(a)中所有候选资源执行活动a的平均次数,σ为相应的标准差,起到了缩放因子的作用。那么活动a的偏好模式可以表示为:ActPrefer(a)=(Prefer(a,r1),Prefer(a,r2),…,Prefer(a,rn))。
定义5协作水平 不同活动在活动交接过程中的合作效率称为活动间的协作水平。
记活动a1与a2之间的协作水平如下:
(2)
式中:Htime(a1,a2)为活动a1与a2的平均交接时间,AvgT(a1,a2)表示在日志L中所有参与者的平均交接时间。那么活动a的协作水平可以表示为:ActCoop(a)=(coop(a,a1),coop(a,a2),…,coop(a,an)),其中coop(a,a)记为1,不存在协作关系的活动之间的协作水平记为0。
定义6活动质量 随着活动被执行次数的增加,处理该活动的经验和技能不断累积,活动质量也得到了不断提升,从流程日志L中调取了一些相关数据进行回归分析后发现,Sigmoid函数能够较好地拟合这一模式,因此定义活动质量如下:
(3)
式中:n为日志L中活动a被执行的次数,π为缩放系数且π>0。
1.2 流程模块化约束模型
复杂的业务流程可以由若干流程模块组成,流程模块可以看作是业务流程整体的子流程或者流程部件[16]。模块应当具有较明确的功能定义,模块内部结构应当结合紧密。不同模块之间的联系较弱,且可以通过标准化的接口结合。
因此在模块化业务流程时应当满足如下约束:
(1) 高内聚/低耦合。高内聚意味着流程模块内聚具有明确的功能特性,模块内活动应当具有紧密的关联;低耦合意味着模块之间的相互依赖性较小,模块之间应尽量保持独立性。
(2) 标准化接口。模块之间的输入输出应当按照既定的标准完成,这使得模块之间的替换能够更加容易。
(3) 时间/地点独立性。考虑到流程模块之间的任务转接,不同流程模块之间的时间和地点不应该存在混合的关系,应当存有清晰的分界线。
(4) 资源独立性。若流程模块之间对于某资源存在抢占冲突,或者同时调用某资源会导致资源超出负荷,则可能导致流程模块不可用。
在详细介绍流程模块化约束模型之前,除了上节符号外,再引入一些符号如下:
BP为从流程日志L中挖掘得到的业务流程,PMi表示其中第i个流程模块,PMi∈BP,D=(D1,D2,…,Dn)表示活动执行地点集合,P=(P1,P2,…,Pn)表示活动执行角色集合。
定义7流程模块化约束模型
BP=f(PM1,PM2,…,PMi,…,PMt)=ture
(4)
Resourceconflict(PMi,r)=turer∈R
(5)
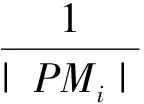
(6)
式中:f(·)函数表示模块之间的组合,t为流程模块总数目;Resourceconflict(PMi,r)表示在模块PMi执行时候对所需资源r的可用性;|PMi|表示模块PMi中活动总数,sign(·)函数为符号函数,当变量相等时取1,否则为0。v(X)表示所有活动集合中资源偏好度的方差,v(Y)表示所有活动集合中协作水平的方差,d(ActPrefer(an,an+1))表示活动an与an+1之间资源偏好度的欧氏距离,d(ActCoop(an,an+1))表示活动an与an+1之间协作水平的欧氏距离。α为归一化缩放系数,且α>0。φlim为模块化划分阈值,取自符合APQC(American productivity and quality center)标准的业务流程模块化数据进行随机抽样分析后的平均值。
2 流程模块功能主题提取
流程日志中包含活动的案例描述或者执行信息,这些信息往往是基于文本形式存在的。业务流程中的语义信息是反映模型质量的一个重要标准,语义信息还能够体现出流程模块的主题特征。从流程日志中经过流程挖掘技术进行模块化分析后,基于改进的隐狄克雷分布LDA主题模型提取操作,能够提取流程模块的多维主题表示,获得流程模块主题模型的同时,保证主题模型结构的稳定性。
2.1 面向模块功能主题的LDA主题模型
隐狄克雷分布LDA是一种基于概率的主题模型,同时也是一种无监督学习算法[17]。通过LDA主题模型提取算法能够提取出流程模块的功能主题,进一步揭示模块功能主题与案例描述等语义信息之间的关系,为流程绩效预测与模块组合推荐打下基础。该模型将流程日志中语义信息看作由模块语义信息层、功能主题层和特征词层组成的3层贝叶斯概率结构,其拓扑结构如图1所示。

图1 面向模块功能主题的 LDA主题模型的3层拓扑结构
面向模块功能主题的LDA主题模型结构如图2所示,其中透明圆圈代表隐藏变量,灰色圆圈代表可观测变量,矩形代表变量的重复。假设流程模块为D,其中包含了N个流程活动,潜在的功能主题数为K,定义字符含义如下:流程模块主题为φ1∶k,其中φk为第k个功能主题的词的分布;第d个活动中主题所占比例为θd,其中θd,k为第k个主题在第d个活动中的比例;第d个流程活动的主题全体为Zd,其中Zd,n是第d个流程活动中第个词的主题;第d个流程活动中所有词记为Wd,其中Wd,n是第d个流程活动中第n个词。
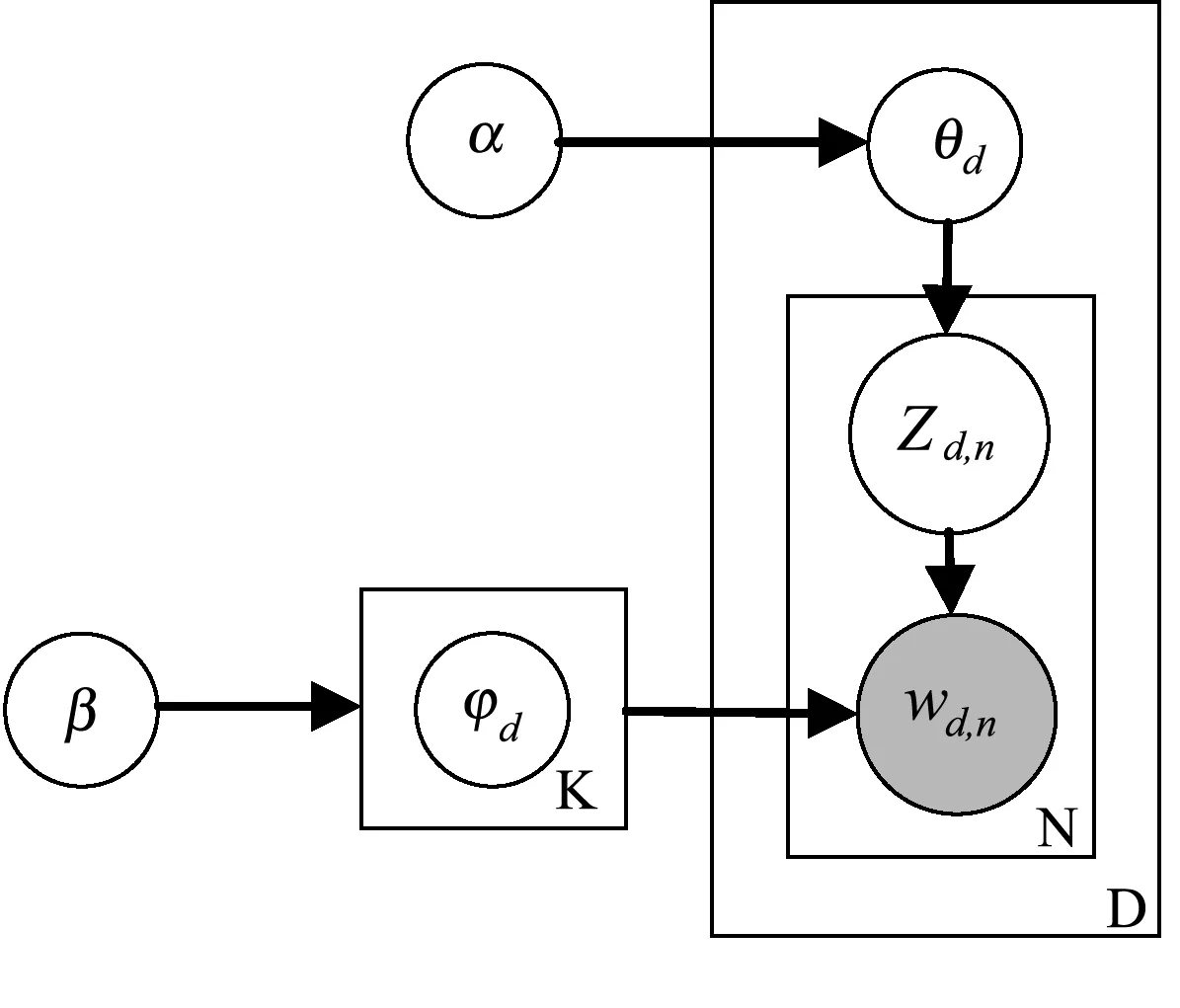
图2 面向模块功能主题的LDA主题模型结构
根据图2所示的结构下的联合分布以及LDA主题模型的后验概率分别为:
p(φ1∶k,θ1∶D,Z1∶D,W1∶D)=
(7)
(8)
在上述联合分布中Zd,n依赖于θd,Wd,n依赖于Zd,n与φ1∶k,θd与φd均服从以α与β为超参数的Dirichlet分布,对于上式中隐藏的参数采用吉布斯抽样算法(Gibbs Sampling)来进行估计。将获得的估计参数代入LDA主题模型进行计算,便可以获得每一个流程模块的功能主题模型,还可以获得每一个主题下的词汇分布及相应的占比。
2.2 基于最优主题结构的模块LDA主题模型提取算法
面向模块功能主题的LDA主题模型能够通过分析模块中的语义信息,提取出隐含的主题结构。一个模块可以用多维主题向量及其相应的分布表示,对于其中的每一个主题又可以用为多维特征词向量及特征词的分布表示。即M={(Z1,Z2,…,ZT)},Zi={(W1,W2,…,WN)},M表示某一流程模块的LDA主题模型。理想的模块主题模型应当使得各个主题之间关联度较低,即各主题之间独立性较高。
定义8主题向量相似度 主题在向量空间中的余弦距离可以表示主题向量之间的关联相似度:
(9)
式中:Zi、Zj表示模块PM主题模型中的两个主题向量,Wik、Wjk分别表示Zi、Zj在向量空间中第k个特征词及分布,1≤k≤N。则sim(Zi,Zj)越小,则主题之间越独立。基于此,我们给出模块主题模型的结构稳定程度的定义:
定义9模块主题模型的结构稳定程度 模块所有主题之间的平均相似度可以表示该模块主题模型的结构稳定程度:
(10)
而LDA主题模型的产生过程,就是在给定主题数目的情况下不断调节主题在向量空间中的词占比,从而达到各主题之间的关联度不断降低的过程。因此给定的主题数目直接影响到模块功能主题结构的稳定程度。引入主题密度的概念,提出基于最优主题结构的模块LDA主题模型提取算法。
定义10主题密度 主题密度为以向量空间中该点为中心,以α为半径区域内主题的个数称为主题密度,α为给定的半径距离:
Density(Zi,α)=|distance(Zi,Z)|≤α
(11)
定义11模型基数 给定一个LDA主题模型M和整数n,模型中密度小于等于n的主题数目成为该LDA主题模型的基数,记作Cardi(M,n)。
定义12参考样本 对于主题分布中的一个主题Z、给定半径α和阈值n,如果满足Density(Zi,α)≤n,则称主题Z为向量空间中一个参考样本。
给出基于最优主题结构下的模块LDA主题模型提取算法如下:
算法1基于最优主题结构的模块LDA主题模型提取算法:
Input:D,流程模块集合
K,初始主题数目
Output:M,各模块功能主题模型
Method:
1 根据给定K值以随机抽样方式得到初始模块主题模型M
2n=0
3 whiler、K未收敛 do
4 计算所有主题的平均相似度r=AvgSim(M)
5 计算所有主题的密度Density(Zi,r)
6 计算模型M的基数C=Cardi(M,n)
7Kn+1=Kn+gn(r)(Kn-Cn)
8 ifgn(r)=-1 then
9 将主题按密度从小到大排列,取前C个主题为参考样本,重新进行主题模型参数估计
10 else
11 重新采用抽样方式进行参数估计
12 利用Kn+1重新得到模块主题模型M
13n=n+1
14 end while
其中g(r)为r的变化方向的指示函数,当r的变化方向与前一次相反时,gn+1(r)=-1×gn(r),当r的变化方向与前一次相同时,gn+1(r)=gn(r),g0(r)=-1。
基于改进的LDA主题模型提取算法获得每一个模块的主题模型的同时,兼顾了主题模型结构的稳定性,保证各主题之间的独立性。
3 流程绩效预测与模块组合推荐
通过对流程日志的记录进行挖掘可以获取业务流程的整体特征,基于机器学习算法可以预测业务流程绩效,从而以最大化流程绩效为目标,对流程模块进行组合动态推荐。
3.1 业务流程特征提取
业务流程是流程活动的逻辑组合,基于活动特征可以进一步挖掘出业务流程特征。从流程日志L中挖掘流程特征的过程如下:
定义13流程时间 在业务流程中,随着活动长时间被多次执行,各流程步骤的熟练度逐渐上升,处理效率不断提高,因此时间是影响流程绩效的重要因素。定义业务流程BP的时间特征为:
(12)
式中:processi(a)表示活动a第i次的执行时间,h为活动a执行总次数,λn-i为对应的权重,λ为衰减因子且0<λ≤1,即距离现在越久则相应的权值越小。
定义14流程成本 定义业务流程成本为历史处理总成本的平均值,如下所示:
(13)
式中:costi(a)表示活动a第i次的执行成本。
定义15流程协作水平 业务流程整体协作水平由流程内部各活动之间的协作水平所构成,记流程的协作水平如下:
ProCoop(BP)= (ActCoop(a1),ActCoop(a2),
…,ActCoop(an))
(14)
式中:ActCoop(an)表示流程中活动an的协作水平。
定义16流程活动质量 业务流程活动质量由流程内部各活动质量所构成,记流程的活动质量如下:
ProQuality(BP)= (Quality(a1),Quality(a2),
…,Quality(an))
(15)
式中:Quality(an)其中表示流程中活动an的活动质量。
定义17流程资源熟练度 业务流程最终绩效与流程内执行活动的资源的熟练度密切相关,资源对活动执行次数越多,则对该活动的处理越熟练。若某业务流程内每个资源只执行了一次,则该流程资源熟练程度较低。记流程的资源熟练度如下:
(16)
3.2 基于BP神经网络的流程绩效预测
首先定义流程绩效的评价指标,流程绩效评价指标应该体现流程“输入- 过程- 产出”的整体框架,兼顾流程整体的性能以及产出质量。定义流程活动的流转率为其输出的质量得分与其消耗的时间及成本的比值,令AF(a)为活动a的流转率,则可给出如下公式:
(17)
式中:Output(a)为活动a的输出质量,通常由活动的输出经济效益表示。
基于活动的流转率,给出业务流程的绩效评价指标如下:
PF(BP)=(∑a∈BPηa×AF(a))/n
(18)
式中:ηa为活动a的权重调和因子。
神经网络算法能够自动学习多维输入与输出之间的复杂映射关系,并且无需事先知道输入与输出之间的数学方程联系,被广泛用于各行业的预测问题中。而BP神经网络发展至今已经得到了多重验证及训练,方法比较成熟且结果较为稳定,是迄今运用最为广泛的神经网络算法[18-19]。因此本文选取BP神经网络算法训练流程绩效预测模型。经过本文多次实践后发现,三层BP神经网络对流程特征向量与流程绩效的建模效果较好,且三层网络的参数量与业务流程特征数目及训练集数据大小较为匹配,综合考虑训练成本等因素后,本文选取三层BP神经网络用于模型训练。而经过多次实践后,发现Sigmoid激活函数对模型的训练效果较好,因此本文选用Sigmoid函数用作神经元激活函数:
(19)
(20)
那么该神经网络在业务流程训练集TD上的累积均方误差为:
(21)
为了使得累积均方误差最小化,对网络中的参数进行更新估计,则让累积均方误差MSETD对各个参数求偏导数,并基于梯度下降策略对各个参数进行调整。考虑到算法的收敛性及运算成本,采用小批量梯度下降法MBGD(Mini-batch Gradient Descent)更新流程绩效预测模型中的参数,经过多次迭代后,获得业务流程绩效预测模型。
3.3 流程模块组合动态推荐
基于训练好的业务流程绩效预测模型,我们可以得到业务流程模块组合后的流程绩效预测值,以最大化流程绩效为目标,构建流程模块组合动态推荐架构如图3所示,主要分为虚线所示三大板块。

图3 流程模块组合动态推荐架构图
(1) 主题模型提取板块。负责从流程日志数据库中通过流程挖掘技术挖掘活动特征,进而对流程活动进行模块化。对流程模块提取相应的主题模型,以方便为模块组合推荐做准备。
(2) 模块组合推荐板块。用户在进行建模工作之前,通常以需求文档、设计说明等文本形式的内容来描述流程任务或者建模需求。对用户业务流程需求文档集合进行分词、去停顿词、取词干等预处理操作后,同样对其进行用户所需功能主题提取,获取用户所需功能主题以及相应的特征词占比。通过文本信息在向量空间模型下的余弦相似度匹配,寻找用户所需功能主题相近的流程模块。为了使推荐结果更加多样化和可选择化,采用k近邻思想在向量空间中找到k个相似功能主题的流程模块组成功能主题模块集合FTMS。为用户的需求生成若干个FTMS后,系统会自动从各FTMS中选择模块进行动态组合推荐。
(3) 流程绩效预测板块。通过流程挖掘技术从流程日志数据库中获取业务流程特征,并且利用日志记录训练绩效预测模型,对模块组合推荐板块生成的业务流程进行绩效预测,给出Top-N的推荐列表。
对于无法组合的流程模块(如输入输出无法对应匹配),系统会动态给出各主题下k个相似功能主题的流程模块清单,附上该模块所包含的语义信息以供用户参考。
4 实验及结果分析
为了评估本文所提出的方法,选取了10家采用APQC标准的流程框架的企业流程日志数据进行实验分析。每家企业均含有业务部、生产计划部、财务部等10个以上的部门,每个部门内部含有日常业务流程线2条及以上。数据集总共包含了8 286条流程实例,每条流程实例均包含了起止时间、事件描述、执行成本等所需信息。下面从流程模块主题模型提取和模块组合推荐两个角度对数据集进行对比实验分析。
4.1 流程模块主题模型提取实验分析
4.1.1 主题模型评价标准
采用语言模型的困惑度(Perplexity)作为LDA主题模型的评价标准,通过对主题模型的困惑度的计算可以得出该模型的性能[20]。困惑度指标越小则说明该主题模型的性能越好。给出困惑度的计算公式如下:
(22)
式中:Nd为流程模块d中语义信息的总词数;Wd,i为其中的第i个单词。
同时继续采用本文2.2节中的平均相似度来表示该模块主题模型的结构稳定程度。
4.1.2 不同K值对模块主题模型的影响分析
随机选取实验数据集中4条流程实例用作实验分析,由于各流程活动总数、案例描述不同,流程日志中所包含的语义信息大小也不相同。将各流程日志进行活动特征提取、模块化等一系列操作后,利用LDA主题模型提取算法对各模块提取主题模型。随机选取每一条流程线中的1个模块的主题模型进行实验对比分析,分别将4个模块称为D1、D2、D3、D4。如图4所示。
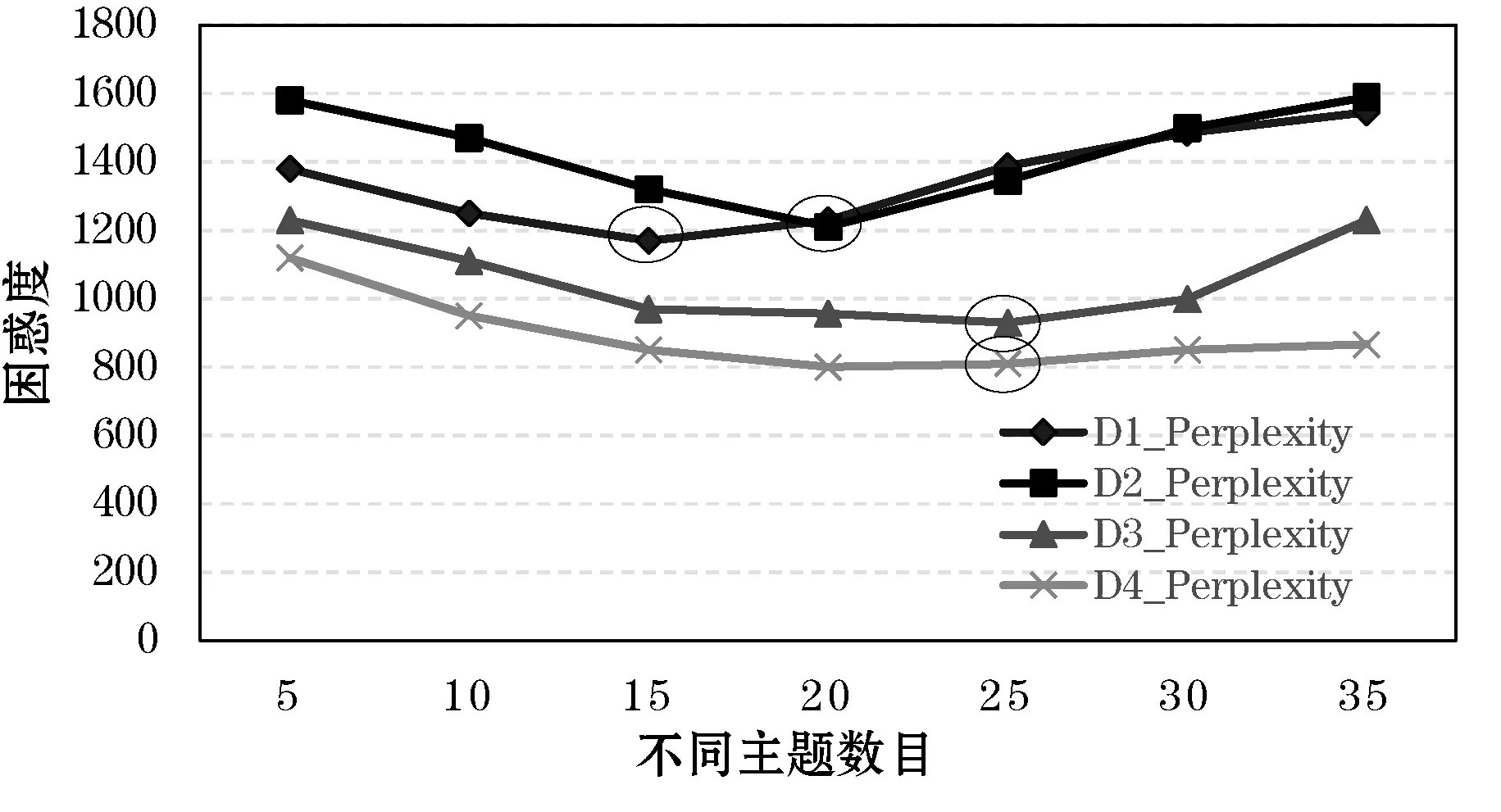
图4 数据在不同主题数目下困惑度对比
从图4中可以看出,指定不同的主题K值会对主题模型的性能产生影响,其中D1、D2、D3、D4均在圆圈处达到了困惑度最低值,说明在此处各模块的主题模型内部相关性较低,各主题独立性较高,主题模型更加稳定。每一个模块的最优K值受到模块内部语义信息的影响,因此各不相同。为了进一步说明主题模型困惑度与稳定性的关系,则对不同主题数目下模块主题模型的平均相似度进行实验分析。如图5所示。

图5 数据在不同主题数目下平均相似度与困惑度对比
通过比较Perplexity曲线与AvgSim曲线在不同主题数目K值下的走势发现,两个变量的变化趋势基本相同,且同样在圆圈处达到最优模块主题模型结构,说明此时的主题模型各主题之间的关联度最低,独立性最高,则此时的主题模型最能够表示模块的功能主题信息。
4.2 流程模块组合推荐实验分析
4.2.1 推荐效果评价标准
通过自助法(bootstrapping)以自助采样的方式将实验数据集合中的大部分数据作为训练集,将剩余数据作为测试集。对测试集中的业务流程日志进行流程挖掘、特征提取、流程模块化等一系列操作之后,移除最后一个流程模块,并将最后一个流程模块作为模块组合推荐的推荐目标。根据测试集中业务流程的原业务说明文档对最后一个功能模块进行预测推荐,将推荐模块代入原业务流程后判断流程绩效指标是否提升或者保持不变,通过计算测试集中业务流程的推荐模块中能够提升或者保持绩效不变的模块数与总推荐模块数目的比值来评估推荐的效果。即推荐效果RA可以表示为:
式中:RN为向业务流程推荐的功能模块数目,RNk为推荐模块中能够提升业务流程绩效或者保持不变的模块数目(绝大部分是原先的功能模块),testset表示测试集中的所有业务流程。
4.2.2 基于不同主题模型提取算法的流程模块组合推荐实验分析
图6给出了不同主题模型提取算法下的流程模块组合推荐效果实验对比。其中用于对比实验的分别是指定主题数(K=10)的LDA主题模型提取算法。以及基于开源自然语言处理工具StandfordNL[21]对模块提取主题的算法。StandfordNL能够对流程模块中包含的信息文本进行分词、去停顿词、取词干等预处理操作,再根据词频-反向文档频率TF-IDF(Term Frequency-Inverse Document Frequency)模型建模,从而获取模块的主题模型。
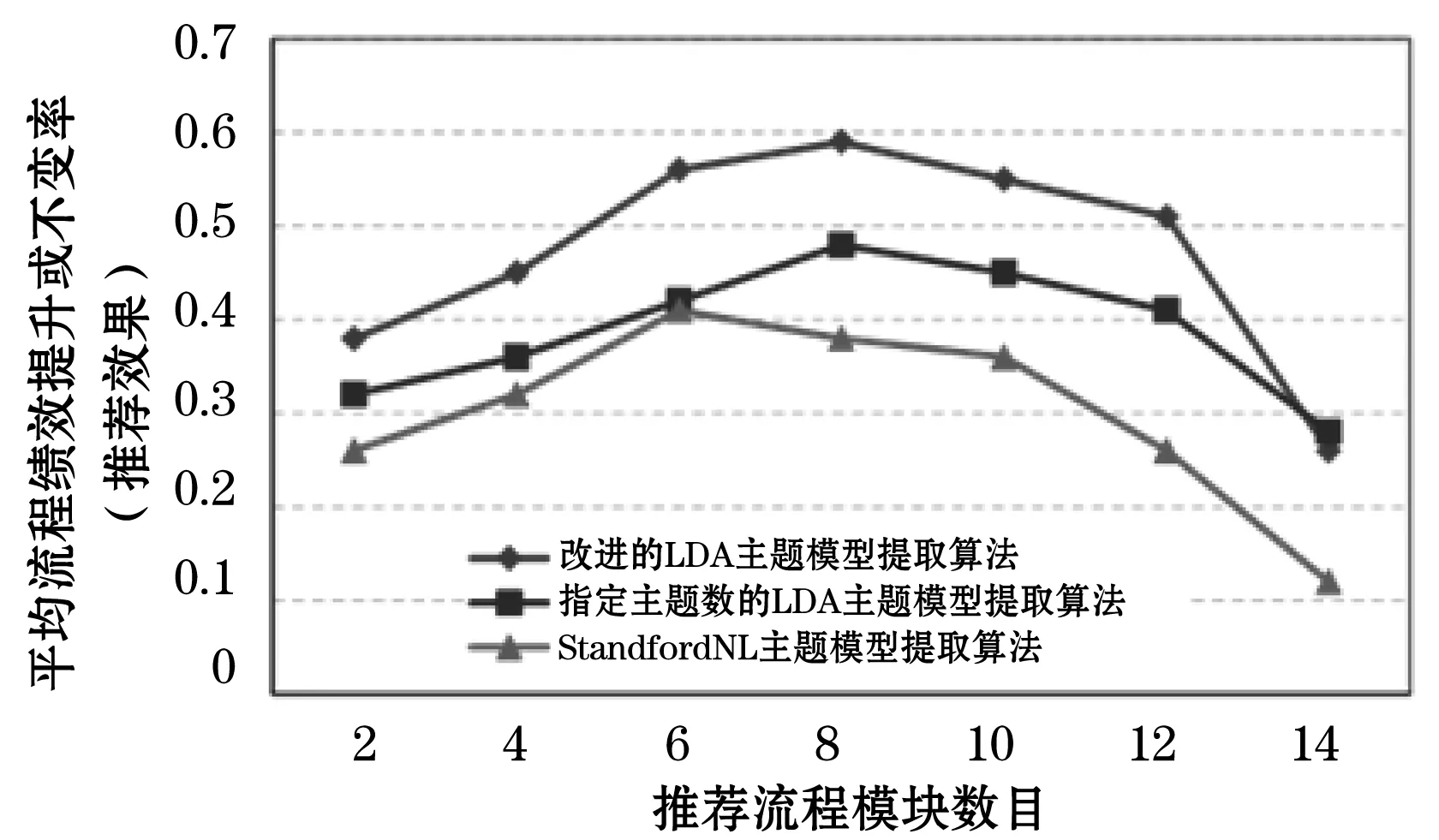
图6 基于不同主题模型提取算法的流程模块组合推荐实验对比
从图6中可以得出,三种模块主题模型提取算法的推荐效果都随着推荐模块数目的上升先逐步提高,但过了一定数目后开始逐步下降。其中两种基于LDA主题模型的提取算法的推荐效果在各种数目下均优于StandfordNL主题模型提取算法。可以看出LDA主题模型能够更好地从流程模块的语义信息中提取出代表该模块功能主题的语义模型。而本文提出的改进的LDA主题模型提取算法能够更好地提取结构稳定的LDA主题模型,因此在推荐效果上具有更优的性能。
4.2.3 基于不同绩效预测模型的流程模块组合推荐实验分析
图7给出了基于不同绩效预测模型下的流程模块组合推荐效果实验对比。其中用于对比实验的分别是Apriori关联规则推荐算法与线性神经网络。Apriori关联规则推荐算法能够挖掘模块组合与流程绩效之间的关联规则,然后根据关联规则为业务流程推荐流程模块。线性神经网络则是由多个线性神经元组成的另一常见神经网络算法,它能根据输出向量与期望输出向量之间的差距来调整网络内的神经元阈值和权值,从而获得预测模型。
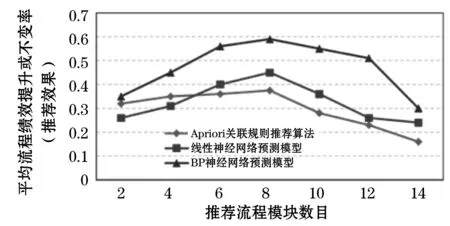
图7 基于不同绩效预测模型的流程模块组合推荐实验对比
从图7中可以得出,两类神经网络预测模型的推荐效果基本上均优于Apriori关联规则推荐算法。但在刚开始推荐模块数目较少时,Apriori关联规则推荐算法推荐效果要优于线性神经网络预测模型,这可能是因为推荐数目较少时,Apriori算法能够直接获取模块组合与高流程绩效之间的强关联规则。随着推荐模块数目的增加,神经网络预测模型的优势开始逐渐显现,但均过了一定峰值后开始下降,这与上节结论相同。其中BP神经网络的推荐效果均要显著优于另外两种算法的推荐效果,而线性神经网络缺乏反向传播误差等优势,因此推荐效果不如BP神经网络算法。
5 结 语
合理的业务流程模型能够为企业带来客观的经济收益及质量口碑,因此推荐合适的流程模块帮助企业设计流程已经在近年来得到学术界与工业界的不断关注。流程挖掘技术在近年来飞速发展为流程推荐研究提供了新的方向和思路。本文提出一种基于流程挖掘技术的业务流程模块推荐方法,能够基于流程日志使用流程挖掘技术获取特征信息,从而能对流程活动建模并模块化;再使用改进的基于最优主题结构的LDA主题模型提取算法提取流程模块的功能主题;同时构建业务流程整体特征后,基于小批量梯度下降法的BP神经网络算法训练流程绩效预测模型。将用户建模需求做所需功能主题提取后,采用K近邻思想生成功能主题模块集合,以最大化流程绩效为目标对流程模块进行动态组合推荐。实验表明,本文方法对流程模块推荐具有较好的推荐效果,证明其在流程建模过程中的可行性。
在现实企业流程中,流程信息包含的数据可能会更加复杂及多样化,未来计划在建模过程中考虑更多流程元素,进一步加强流程管理与流程建模的结合。未来的另一个研究方向是将流程推荐与业务流程资源分配相结合,提供基于资源分配与流程绩效结合的流程模块推荐。
[1] 赵卫东. 智能化的流程管理[M]. 上海:复旦大学出版社,2014.
[2] Liu Y, Wang J, Yang Y, et al. A semi-automatic approach for workflow staff assignment[J]. Computers in Industry, 2008, 59(5):463- 476.
[3] Nakatumba J, Aalst W M P V D. Analyzing Resource Behavior Using Process Mining[J]. Lecture Notes in Business Information Processing, 2009, 43:69- 80.
[4] Huang Z, Lu X, Duan H. Resource behavior measure and application in business process management[J]. Expert Systems with Applications, 2012, 39(7):6458- 6468.
[5] HornungT, KoschmiderA, Oberweis A. A Recommender System for Business Process Models[C]//17th Annual Workshop on Information Technologies & Systems (WITS),2009.
[6] Ayora C, Torres V, Vara J L D L, et al. Variability management in process families through change patterns[J]. Information & Software Technology, 2016, 74(C):86- 104.
[7] Chen S J, Lin L. Decomposition of interdependent task group for concurrent engineering[J]. Computers & Industrial Engineering, 2003, 44(3):435- 459.
[8] Clempner J. A hierarchical decomposition of decision process Petri nets for modeling complex systems[J]. International Journal of Applied Mathematics & Computer Science, 2010, 20(2):349- 366.
[9] Mendling J, Reijers H A, Recker J. Activity labeling in process modeling: Empirical insights and recommendations[J]. Information Systems, 2010, 35(4):467- 482.
[10] Dorn C, Burkhart T, Werth D, et al. Self-adjusting recommendations for people-driven ad-hoc processes[C]// Proceedings of the 8th International Conferenceon Business Process Management, Hoboken, NJ, USA, September 13- 16, 2010.DBLP, 2010:327- 342.
[11] 赵卫东, 戴伟辉. 基于角色块的工作流模型挖掘[J]. 系统工程与电子技术, 2008, 30(5):956- 959.
[12] Koschmider A, Hornung T, Oberweis A. Recommendation-based editor for business process modeling[J]. Data & Knowledge Engineering, 2011, 70(6):483- 503.
[13] Aalst W M P V D, Reijers H A, Weijters A J M M, et al. Business process mining: An industrial application[J]. Information Systems, 2007, 32(5):713- 732.
[14] Liu X, Fang X, Wang J, et al. Mining method of business process models based on configuration[J]. Boletin Tecnico/technical Bulletin, 2017, 55(1):77- 84.
[15] Zeng Q, Sun S X, Duan H, et al. Cross-organizational collaborative workflow mining from a multi-source log[J]. Decision Support Systems, 2013, 54(3):1280- 1301.
[16] Lacheheub M N, Maamri R. A formal model for business process decomposition based on resources consumption with security requirement[C]// International Conference on Advanced Aspects of Software Engineering. IEEE, 2017:1- 8.
[17] Limsettho N, Hata H, Matsumoto K. Comparing hierarchical dirichlet process with latent dirichlet allocation in bug report multiclass classification[C]// IEEE/acis International Conference on Software Engineering, Artificial Intelligence, NETWORKING and Parallel/distributed Computing. IEEE, 2014:1- 6.
[18] Armaghani D J, Hajihassani M, Mohamad E T, et al. Blasting-induced flyrock and ground vibration prediction through an expert artificial neural network based on particle swarm optimization[J]. Arabian Journal of Geosciences, 2014, 7(12):5383- 5396.
[19] Yu F, Xu X. A short-term load forecasting model of natural gas based on optimized genetic algorithm and improved BP neural network[J]. Applied Energy, 2014, 134(134):102- 113.
[20] Biggers L R, Bocovich C, Capshaw R, et al. Configuring latent Dirichlet allocation based feature location[J]. Empirical Software Engineering, 2014, 19(3):465- 500.
[21] Manning C D, Surdeanu M, Bauer J, et al. The Stanford CoreNLP Natural Language Processing Toolkit[C]// Meeting of the Association for Computational Linguistics: System Demonstrations. 2014:55- 60.
