基于用户行为模型的移动APP信息采集方法
2018-07-05杨海军梁汝峰蔡立志上海市互联网信息办公室上海0000上海蓝全网络科技有限公司上海上海市计算机软件评测重点实验室上海
杨海军 施 敏 梁汝峰 蔡立志(上海市互联网信息办公室 上海 0000)(上海蓝全网络科技有限公司 上海 0)(上海市计算机软件评测重点实验室 上海 0)
0 引 言
21世纪以来,计算机互联网飞速发展[1],据不完全统计,截至2016年底,中国的互联网用户已经达到7.31亿。随之而来的是爆发式增长的互联网信息,同时,随着智能手机的普及、移动互联网与各种APP的发展,移动客户端已经成为了人们获取以及发布信息的重要渠道。移动客户端APP已经成为互联网用户掌握各种新的主要途径之一,在事件传播和舆论导向过程中起着至关重要的作用,成为信息采集的主要对象。信息采集在信息实时性和全面性有较高的要求,若单纯以人力进行数据采集,无法高效、高质量完成如此庞大的工作量,基于计算机互联网技术的新闻移动APP客户端信息采集便应运而生。
1 移动APP客户端信息采集
在互联网大数据时代,从互联网中获取信息的方法随着技术的发展逐渐改变,传统的网页信息采集是指通过网络蜘蛛在互联网上采集网页信息的过程[2]。网络蜘蛛(Web Spider),又被称作网络爬虫或网络机器人,是专门用来搜索互联网上各种网页信息的软件,具有独立的工作和决策能力,能自动地在互联网上按照一定的规则进行搜索爬行,并将搜索的信息返回给服务器。不同的搜索引擎,网络蜘蛛会有所区别,通常包括通用网络蜘蛛和主题网络蜘蛛。通用网络蜘蛛通过通用搜索引擎进行信息采集,只考虑采集网页的数量,尽可能多地抓取网页信息,而不考虑网页和主题的相关度。主题网络蜘蛛通过垂直搜索引擎(主题搜索引擎)实现[3],只在特定领域范围内采集与主题相关的网页。
1.1 网络蜘蛛结构
为了使用移动APP客户端数据采集的需要,本文使用改进的网络蜘蛛模型,如图1所示。任务发送队列负责从移动APP信息采集任务库中遍历信息APP采集任务。然后将采集任务放入发送队列,并发送至任务请求发送模块;任务请求发送模块利用HTTP网络通信协议与待采集的APP服务器建立连接并发送请求;页面下载解析模块负责将返回的信息下载到本地,进行解析,按照预设的格式存储,最终发送至数据信息库。
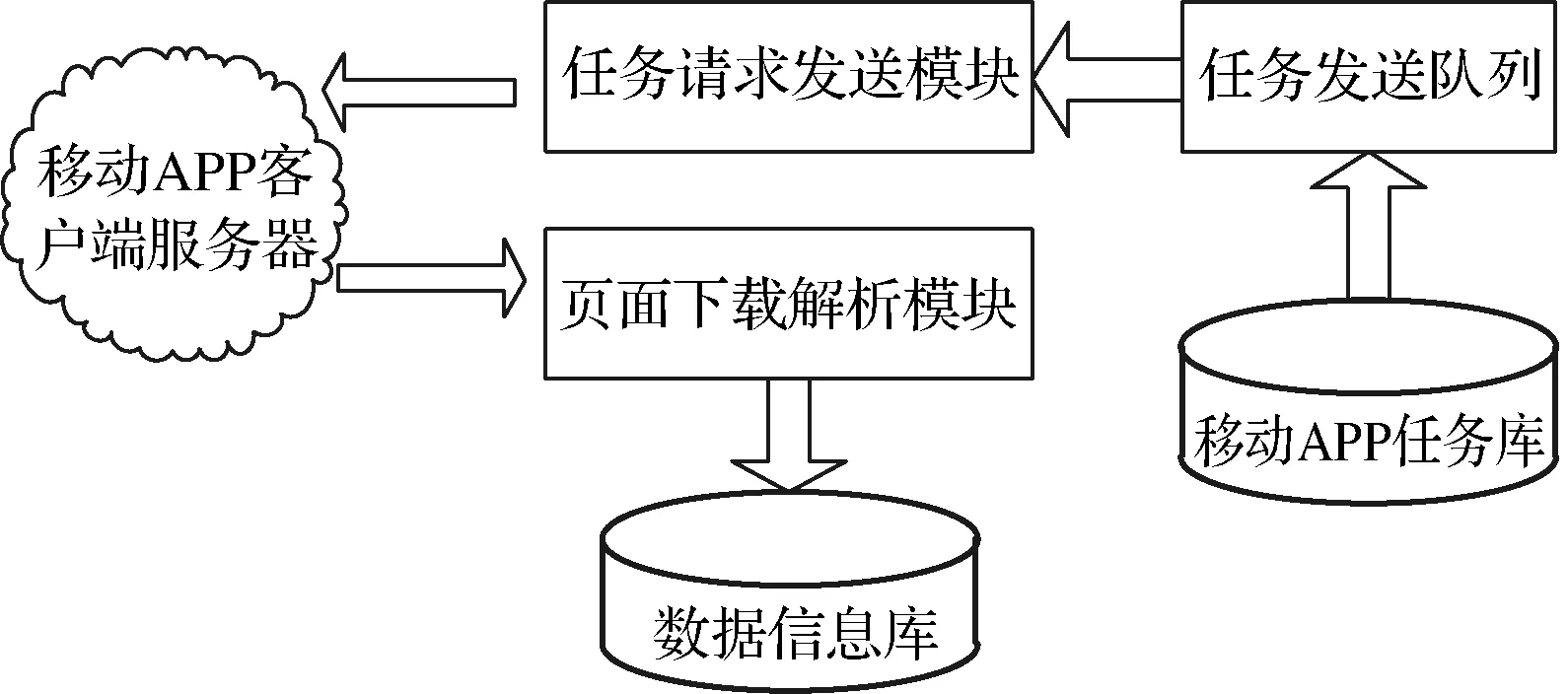
图1 改进的网络蜘蛛结构图
利用上述模型,可以实现移动APP客户端数据信息采集功能,具体流程如下:
(1) 从数据库中读取需要采集的移动APP任务,全部加载到任务队列中;
(2) 任务队列发送任务至任务发送模块;
(3) 任务发送模块获取任务相关Cookie、Client等信息,发送请求至移动APP服务器;
(4) 若移动APP服务器返回信息正常,执行(5);若移动APP服务器返回信息为空或无效数据,返回(2);
(5) 对移动APP服务器返回的信息数据进行相应的解析,过滤掉无用和隐藏的信息,将有价值的信息按照特定格式储存;
(6) 将储存的移动APP发布相关信息上传指定的服务器;
(7) 返回,继续执行(2)。
本文的改进网络蜘蛛模型可以直接利用PC端模拟手机发送相关请求至服务器,对获取的信息进行解析和存储,从而完成相关的数据采集工作。不仅可以节省硬件方面的投入,也可以提高采集和处理效率。
1.2 移动APP客户端信息采集协议基础
若想全面地采集如此庞大的移动APP客户端发布信息,保证移动APP客户端信息的采集效率是重中之重。目前大量移动客户端APP和服务器交互,都是通过HTTP协议实现。超文本传输协议HTTP(HyperText Transfer Protocol)是网络上广泛使用的一种从WWW服务器传输超文本到本地浏览器的传输协议。浏览器发起一个到服务器上指定端口(默认端口为80)的HTTP请求,应答的服务器将其上存储的资源,比如HTML文件和图像,传输给浏览器。HTTP是一个应用层通信协议,由请求和响应构成,并且是一个无状态的协议。其中HTTP 1.1版本由RFC 2616定义。HTTP协议通常承载于TCP协议之上,有时也承载于TLS或SSL协议层之上(即HTTPS)。一次HTTP请求和响应的过程为:客户机发送一个请求给服务器,请求内容包括统一资源标识符(URL)、协议版本号,MIME信息、客户机信息等内容。服务器接到请求后,给予相应的响应信息,内容包括响应状态码、协议版本号、MIME信息、服务器信息、实体信息等内容。
目前,可利用某些抓包软件抓取到相应的HTTP请求信息,代码1利用计算机软件模拟相关的请求,从服务器获取移动APP客户端的数据信息。

代码1 移动APP客户端发送请求信息

SNUID=0DB280DE2B0B940A0000000058A38888SUV=00F95AA53B6CDC44586F0C28B84A9082usid=xZmbGqOkeHYi1vjqvrposw2ewiX0iPDAt1nD/dVbT1Q==
从代码1可以看出,HTTP请求除了client信息外,还包含了cookies/login信息,在发送请求时,在请求中加入相应信息就可以顺利得到服务器返回的相应信息。解析返回的信息我们就可以获取信息数据,并根据我们的需求存取相应的数据信息。
2 采集效率问题建模分析与改进
由于网络蜘蛛的信息采集会消耗大量服务器资源,为了避免一些网络黑客等恶意访问服务器,造成服务压力过大、占用太多的资源、造成正常用户无法登录等,大部分的服务器都采取了适当的限制技术。即通过正常用户的行为模型来判断请求是否来自正常用户,即通过用户的请求频率、浏览器、IP等识别网络蜘蛛,从而对过度频繁的访问做出一定的限制。比如要求输入验证码,计算机软件暂时无法完成验证码的识别和自动输入,无法进行批量信息采集。为了不被站点拒绝访问请求,必须构建移动客户端APP的用户行为模型,模仿正常用户对网站的访问。
2.1 移动APP客户端信息采集用户行为模型
经过反复测试,发现某些较热门的移动APP移动客户端在单线程每次请求间隔1 s的情况下,30 s左右就会出现输入验证码提示,发送的请求也无法得到回复。服务器要求输入验证码会把一些正常的采集程序误认为恶意访问,从而进行限制,造成采集效率受到很大影响。
选择某个对用户访问限制较高的热点移动APP,经过反复建模验证[4],在一定范围内,采集的效率大致符合以下函数关系:
(1)
T(n)=ten+k
(2)
式中:T(n)为每轮采集总时间(不包括被限制时间):n为每次采集后暂停时间,t为常数近似为1/e,k为时间常数近似为20。F(n)为采集效率函数,表示单位时间采集发布文章数量,常数a表示每轮采集,除暂停时间外,每个任务平均消耗的采集时间,在不同模型中有所变化,常数b约为1 200(通常验证码20 min后解除限制)。
基于以上模型,本文提出基于多用户和多IP的移动APP客户端信息采集方法。
2.2 基于多用户模型的移动APP客户端信息采集
根据上节提出的模型,单个用户采集信息会受到服务器的限制,为避免正常的信息采集请求被服务器误认为恶意请求,这里提出使用不同浏览器模拟多个用户发送请求[5]。使用网络抓包工具抓取不同浏览器的请求信息,具体信息如代码2和代码3所示。

代码2 火狐浏览器发送请求信息

代码3 Chrome浏览器微发送请求信息

ABTEST=0|1475238878|v1ad=4yllllllll2g7s20lllllVKPDjUlllirTNL0wkllllylllllVqxlw@@@@@@@@@@@CXID=DEC0BB967BDACB3A0E0995B6A6546E6FIPLOC=CN1100jrtt_at=85c65a38f2dld91694594f6162bd3402LCLKINT=1221ld=c2llllllll2gor42lllllVKAgUllllirTojh0lllllylllllVylll5@@@@@@@@@@LSTMV=413%2C172pgv_pvi=4473533440pgv_si=s1933366272sct=478sgid=AVfHnoSFVgmYkAFPLiaCjDeoSNUID=SEC5752219IF2601FE6C5DDF1A088505sogou_player_alive=1473434672159sogou_player_isclosed=1ssuid=5063970967SUID=44DC6C386A28920A00000000579EE38FSUV=00274A10386CDC44579EE38FCDA67878usid=3QkIcbohvwvHMPuYweixinlndexVisited=1wuidAAEXTmGaEwAAAAqQUT++qQkAkwA=MiscellaneousReferer:http://weixin.sogou.com/Upgrade-Insecure-Requests:1TransportConnection:keep⁃aliveHost:weixin.sogou.com
由代码2和代码3可以看出,不同浏览器发送请求时发送的头信息有所不同,根据抓取的请求信息,可以模拟不同的浏览器发送请求[6]。为了模拟用户行为,采用多线程采集移动APP客户端数据信息,每隔一段随机时间更换一种浏览器发送请求,且每次发送请求后暂停一段随机时间,此随机时间满足正态分布,其生成函数为Box-Muller变换:
(3)
式中:σ为正态分布的标准差;μ为正态分布的平均值;U1和U2是(0,1)范围内服从均匀分布的两个独立随机变量。经测试,使用多浏览器可以明显提高采集效率,在单位时间内与一种浏览器相比,采集效率提高了一倍。但这仍然不能从根本上解决采集时间过长导致服务器要求输入验证码,从而导致采集效率不高的问题,只能一定程度缓解采集受限。
2.3 基于多IP模型的移动APP客户端信息采集
服务器处理请求除了验证浏览器信息外,还会验证IP,同一个IP多次发送请求会被大多数服务器限制功能[7]。为了有效避免采集程序被误认为恶意访问程序,尝试不断改变IP进行采集,具体方法为使用代理服务器[8]。现在互联网上有很多免费的代理可以使用,本文利用代理服务器进行移动APP客户端数据信息采集。
使用计算机单线程采集,设置的采集间隔时间为1 s,每当发送请求返回信息要求输入验证码时,更换代理服务器,继续发送采集请求,如此循环。当每个代理服务器遍历一次之后,重新使用第一个代理服务器,若此时服务器还要求输入验证码,降低采集频率并延长间隔时间。当代理服务器遍历一次之后,整个程序暂停一段时间,然后继续遍历使用代理服务器。从采集结果来看,使用代理服务器采集能够有效维持采集的连续性,减少了等待时间,从整体来讲,只要有足够多的代理服务器,理论上可以二十四小时不间断采集,大大提高了采集效率,有着更高的实用性[9-10]。
3 实验与验证
本次测试目的在与根据实际采集情况来分析改进的基于多用户和多IP模型的移动客户端数据信息采集相对于最初单浏览器固定IP信息采集的效率变化情况。本次测试使用的机器为 DELL品牌台式机,型号为ACPI x64-based PC,使用Java编程语言,版本为1.6.0_43,网络为方正宽带20 M。
首先使用固定IP,单线程搜索,每次搜索之后暂停1s,多次测试之后得到程序可以正常运行时间期望为29 s,搜索任务数量期望为22个,每次要求输入验证码之后程序停止运行,等待验证码输入要求解除,经验证,要求验证码输入持续时间期望为20 min。代入式(1)计算的效率值为0.017 9。
在相同的测试环境下,仍然使用单线程搜索,其他条件不变的情况下,每次搜索后更换浏览器发送请求信息,浏览器使用搜狗、火狐和Google Chrome三种浏览器。浏览器更换的间隔时间采用平均值为60 s,标准差为1 s的正态分布随机数,由式(3)得到。每次请求的间隔时间采用平均值为1 s,标准差为1 s的正态分布随机数。经过多次测试,计算得到程序正常运行期望为45 s,搜索任务数量期望为35个,当发送请求后,返回信息要求输入验证码也是在20 min后消失,根据式(1)计算得到采集效率为0.028 1。
最后在前面的测试平台和测试环境下,使用网络代理,仍然使用单线程采集,在第二次测试的条件下,每次出现验证码切换代理服务器继续进行采集,遍历使用网络代理,遍历一次之后重新遍历使用。若只使用单一浏览器,在现有代理数量的情况下,还达不到不间断持续采集,相对多浏览器采集,性能明显处于劣势,这里不做具体研究。经过多次测试,采集程序基本可以保证不间断采集,计算得到效率值期望为0.108 3。具体数据对比如表1所示。
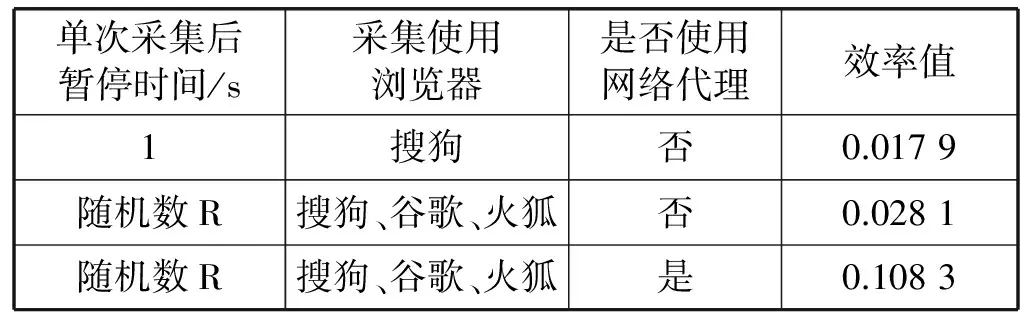
表1 多浏览器与代理对信息采集效率影响
从表1可以明显看出,通过增加浏览器数目和使用网络代理改进移动APP客户端采集程序取得了不错的效果,在采集的效率上有较大的提升。表2列出了运用3种采集方法时,验证码出现前正常运行时间和任务数的对比。
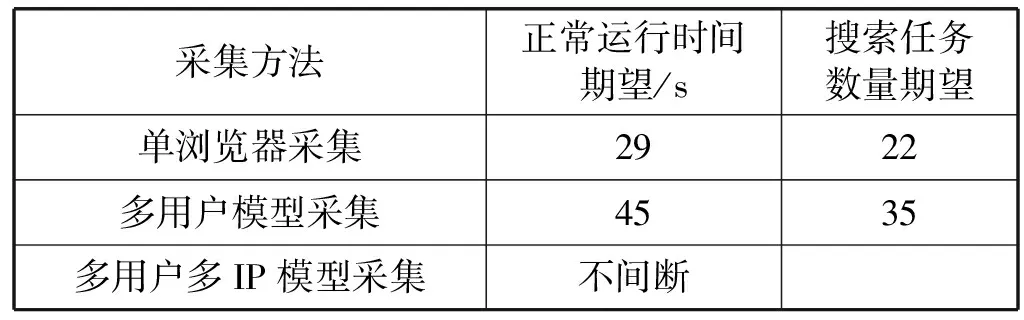
表2 三种采集方法运行时间和任务数对比
从表2可以明显看出,最终的采集方案可以做到不间断采集。不仅可以为科研仿真等提供数据,也可以为舆情监控传播分析提供大量的数据;采集移动APP客户端数据信息的实时性和全面性均达到工程应用的标准。
4 结 语
本文从传统的网络蜘蛛模型入手,对现有的类网络蜘蛛模型进行改造,以解决无法连续采集、采集效率低下的问题。结合用户行为模型提出了通过模拟多用户切换轮流向网络服务器发送请求,能够在一定范围内提高移动APP客户端采集效率;同时采用多IP模型,有效规避采集过程中对单一IP做出的诸多限制,从而在采集效率上有了较大幅度的提升。经过一系列优化已经投入使用,采集移动客户端信息的效率初步满足应用需求。
[1] Murray B H, Moore A. Sizing the Internet[R]. White Paper, Cyveillance, 2000:3.
[2] Aggarwal C C, Al-Garawi F, Yu P S. Intelligent crawling on the World Wide Web with arbitrary predicates[C]// Proceedings of the 10th International Conference on World Wide Web. ACM, 2001: 96- 105.
[3] Menczer F. Complementing search engines with online web mining agents[J]. Decision Support Systems, 2003, 35(2): 195- 212.
[4] 薛定宇, 陈阳泉. 高等应用数学问题的 MATLAB 求解[M]. 清华大学出版社有限公司, 2004.
[5] 丁婕. 管窥“网络蜘蛛”之网上爬行[J]. 技术与市场, 2008 (8): 49- 49.
[6] 刘玲. 一种基于人工策略的 WEB 信息精确提取系统[J]. 西南科技大学学报, 2009, 24(2): 49- 52.
[7] 陈志雄, 朱向庆. 基于内容评价与超链分析的主题爬虫策略[J]. 广西轻工业, 2011 (3): 66- 67.
[8] 张丽敏. 垂直搜索引擎的主题爬虫策略[J]. 电脑知识与技术, 2010(15): 3962- 3963.
[9] 张晶, 肖智斌, 容会, 等. 改进型遗传算法在网络蜘蛛上的应用[J].山东大学学报(理学版),2015,50(5):1- 6.
[10] 林晶, 彭小宁. 基于主题语义 URL 的信息搜索方法研究[J]. 计算机应用与软件, 2015,32(6): 42- 45.
