一种基于K均值的移动客户投诉数据处理算法研究
2018-07-04周慧珺龙涛陈景航
周慧珺,龙涛,陈景航
(1 中山火炬职业技术学院, 中山 528436;2 中国移动通信集团广东有限公司中山分公司,中山 528400)
1 引言
随着互联网、大数据、云计算等技术的发展,越来越多的软件利用TD-LTE等技术接入网络,采用Android手机、iPhone手机、平板电脑等访问移动设备软件,实现4G移动数据通信和语音通信,进一步实现了人类生活的信息化、智能化和便捷化。TD-LTE网络覆盖面积非常大,覆盖环境涉及崇山峻岭、丘陵沟壑、高楼大厦等,较多的障碍物非常容易遮挡信号,另外雷电、风雨、冰雪和断电等事故多发,也容易造成基站无法工作,信号传输中断,引起移动客户的投诉。
目前,中国移动客户数以亿计,因此产生的投诉量非常大,每一条投诉信息都需要客服人员进行处理,如果不对投诉信息进行分类,投诉处理进度就会非常慢,无法及时回复客户,造成客户转网或离网,不利于占有市场和提升企业利润[1]。因此,本文基于笔者多年的工作实践,提出采用数据挖掘算法针对海量投诉数据进行分类,将投诉信息自动化地归纳到每一个类别中,实现对投诉信息的分类处理,进一步改进客户服务水平。
2 移动客户投诉数据处理现状及存在问题
目前,移动客户投诉频发,投诉条数以千万计,但是处理投诉的客服人员少,从杂乱无章的海量投诉信息中随机地进行人工分类速度慢,因此对投诉信息进行分类,将其划分为网络类、业务类等分配到每一个客服组中,可以迅速地获取投诉处理口径,提高处理速度[2]。目前,移动客户投诉数据分类慢,客户信息处理时效性较低,客户服务水平低下,反馈速度慢[3]。具体描述如下:
(1)客户投诉数据分类慢。移动通信客户的投诉种类非常多,这些投诉信息涉及流量业务、语音业务、数据业务、基础业务、终端业务、集团业务、家庭业务、国际/港澳台业务、信息安全等,但是对这些业务进行人工对比分析的速度非常慢,无法从海量数据中实时地将投诉信息进行分类[4]。
(2)客户信息处理时效性较低。处理客户投诉时,由于不同的业务描述关键词不同,也有可能同样的投诉信息描述的关键词不同,因此容易造成信息处理混乱,因此人工匹配关键词很慢,客户投诉信息处理的时效性非常低,另外也非常容易产生反馈错误[5]。
(3)没有实现简单问题自动回复。由于投诉数据全靠人工、半人工进行比对,所以许多数据分析需要人工映射,没有实现简单的投诉问题自动化回复功能,因此大大地增加了客服人员的工作量,大大地降低了投诉处理水平,降低了客户的感知[6]。
因此,为了解决客户投诉处理速度慢、服务水平低、解决投诉不准确的问题,本文引入K均值算法,该算法可以将客户投诉划分为不同类型,分发给每一个处理人员。
3 基于K均值的移动客户投诉数据处理算法设计
为了能够更加准确的发现移动客户投诉数据信息,本文引入了基于K均值的大数据挖掘算法,该算法假设移动客户投诉数据集合可以使用X={x1,x2,…xn}进行描述,这些数据集中包含了K条投诉记录,其中mi可以描述第i个簇的中心,i=1,2,…k。另外,也可以使用uj(xi)描述使用K均值算法挖掘移动客户投诉记录中的而相关信息,比如第xi个样本对第j类的隶属度,这样引入模糊数学的K均值算法目标函数可以使用公式(1)描述。
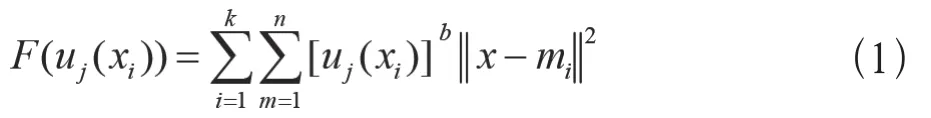
其中,常数b是一个模糊度控制因子,其可以根据实际需求调节模糊度。算法执行过程中可以针对目标函数求导,获取最优解,具体的最优解如公式(2)和公式(3)所示。
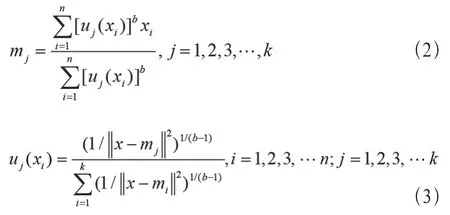
在程序实现过程中,基于模糊数学的K均值聚类算法可以使用以下伪代码描述。
算法输入参数包括四个,分别是移动客户投诉记录数据、包含N条投诉记录、用户期望得到的K个簇、模糊度控制因子b。
算法输出:用户期望得到的K个簇。
算法步骤:
(1)针对N条投诉记录进行初始化,将其随机的划分到K个簇中,并且可以指定每一个簇的中心为mi。
(2)使用公式(3)计算每一个投诉记录的隶属度,这样就可以得到投诉记录的隶属概率。
(3)然后针对步骤(2)处理的结果进行排序,选择最大隶属度值的数据划分到一个簇,使用公式(2)重新计算K个簇的中心值mi。
(4)然后重复性操作步骤(2)和步骤(3),遍历移动客户投诉记录数据集中的每一个数据对象,直到隶属度不再发生任何变化时,算法终止。
4 移动客户投诉处理改进后的优势
为了更好地验证移动客户投诉数据处理成效,本文采集了广东移动2017年6月和7月的投诉数据,预处理之后每个月选择183万条处理工单,详细数据如表1所示。
实验设计:2017年6月投诉工单量采用传统方法进行分类,7月份采用K均值进行分类。7月份60万条流量业务的处理时间是0.4 s,6月份耗费1.3 s,数据处理速度提高了70%;7月份183万条工单的平均处理时间为0.34 s,6月份平均处理时间为1.16 s,因此利用数据挖掘方法可以提高处理速度,缩短处理时效,分类时间如图1所示。
K均值算法不仅可以提高移动客户投诉数据处理时效,还可以更加准确地对其进行分类。为了验证本文数据处理的准确度,可以对7月份数据进行分类,采用的对比方法包括不使用K均值方法和使用K均值方法两类,详细数据描述如表2所示。
通过对实验进行分析,移动客户投诉处理采用K均值算法之后,投诉处理具有很多优势,这些优势包括以下几个方面。
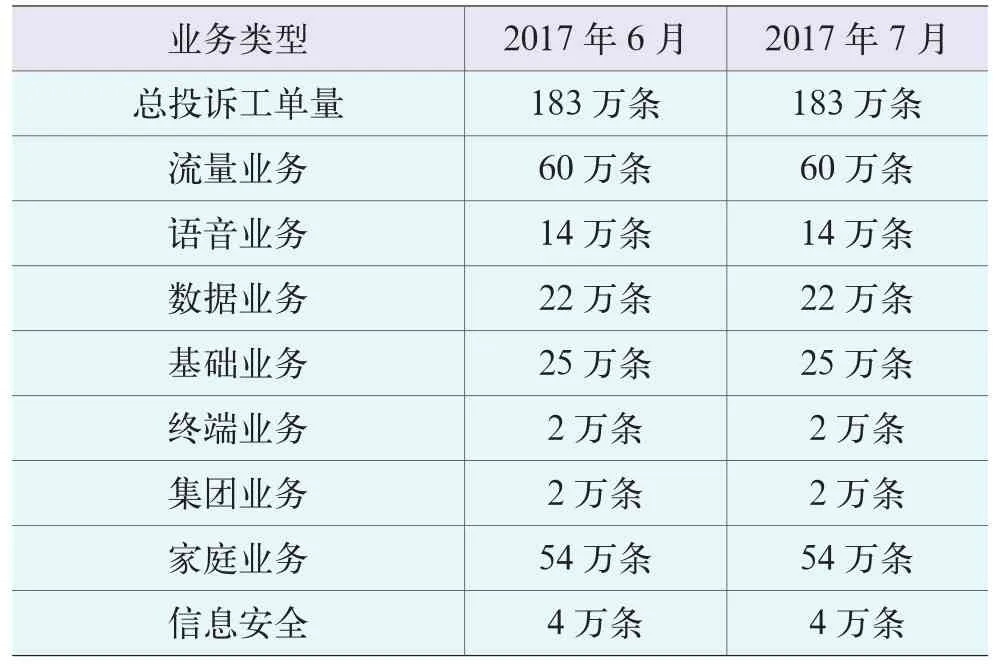
表1 广东移动客户投诉工单量
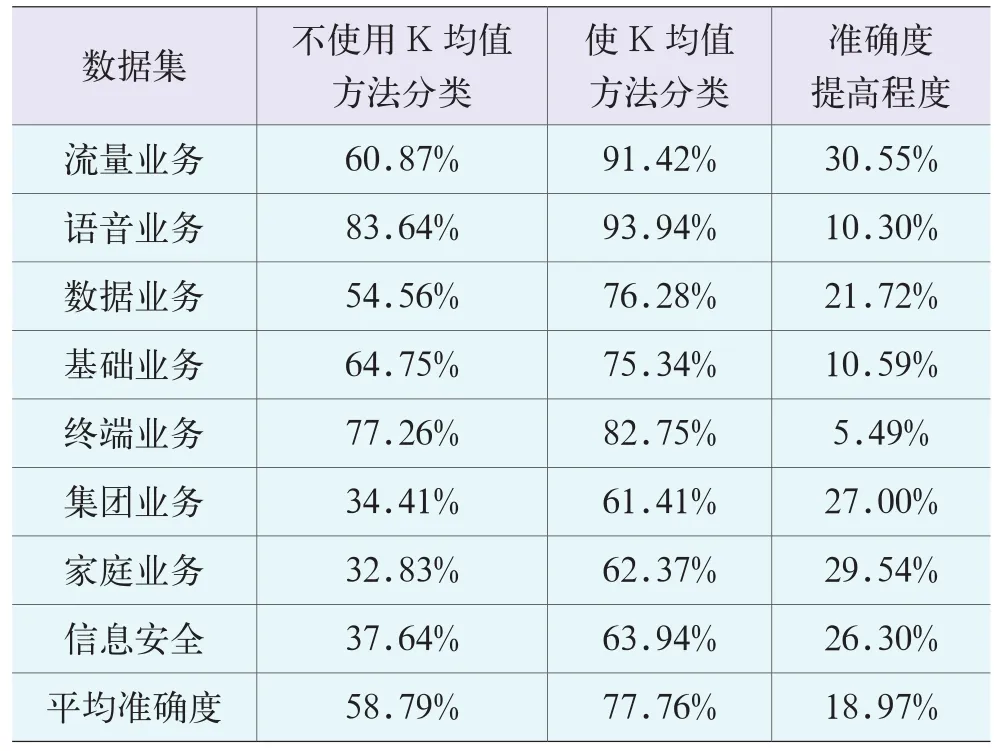
表2 两种算法的实验结果精确度对比
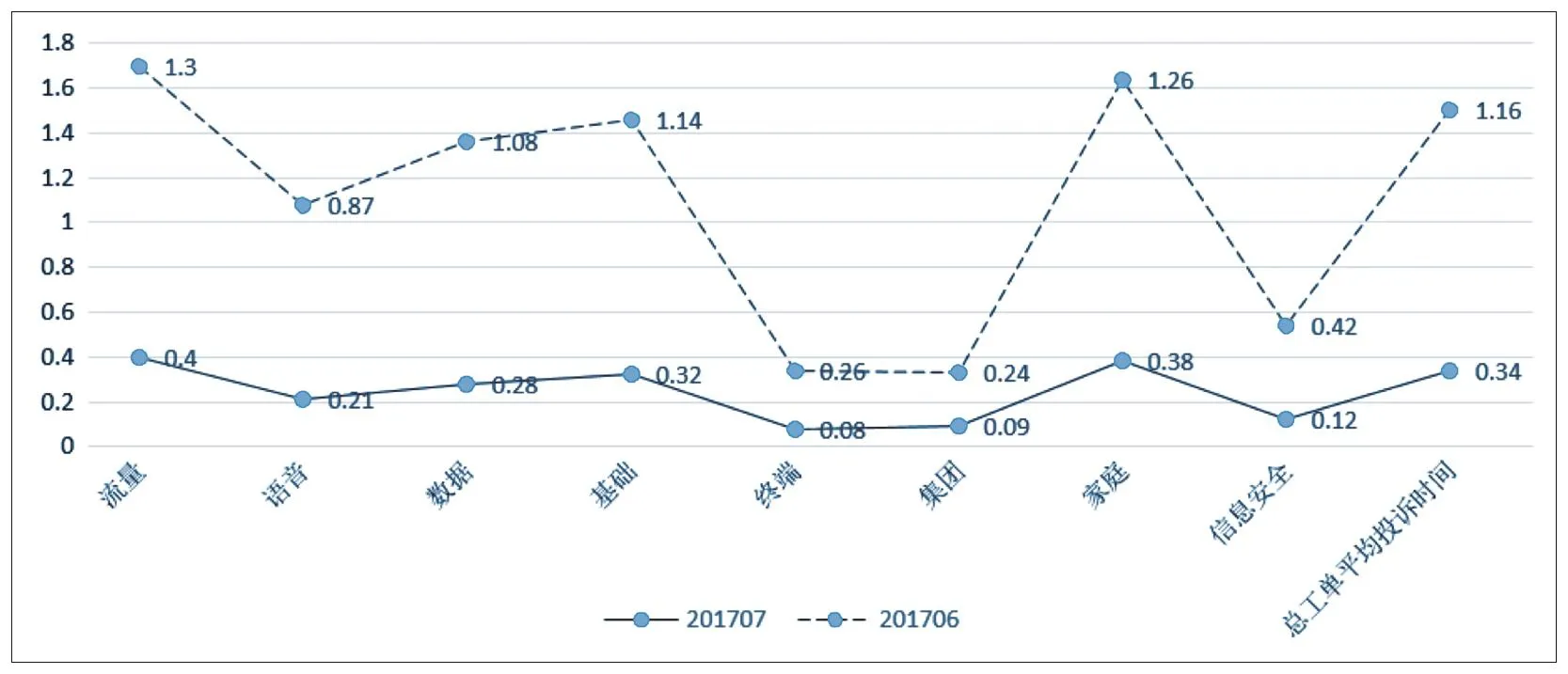
图1 投诉工单分类处理时间(s)
(1)大幅度缩短投诉数据处理时间。K均值是一种数据分类算法,其可以对海量的投诉工单数据按照既定的模式进行分类,将纷乱、无章的数据划分到一个个簇中,在这个过程中全部进行自动化处理,不需要人工进行任何操作,也不需要输入任何先验数据,因此数据处理时间就会大幅度缩短。
(2)进一步提升投诉数据处理准确度,方便客服人员反馈处理结果。客户投诉的内容非常多,这些内容包括流量扣费不合理、机卡分离不返费、信息泄露、家庭账户扣费不正常等,这些投诉既包括大众市场业务,又包括集团市场业务,投诉的内容有可能涉及多个类别,既包括流量又包括语音等,采用K均值算法之后,数据处理的分析程度比较全面,可以根据不同类别的归属将其归到某一类,然后由这一类客服人员进行处理,可以更快向客户反馈投诉结果。
5 结束语
随着“互联网+”时代的到来,移动4G通信也逐渐向5G时代迈进,广东移动服务的客户也越来越多。随着用户文化水平的提升,越来越多的客户开始重视自身权益,一旦出现信号不好、扣费不合理、流量用得快等情况,移动客户就会发出投诉信息。因此,处理数以亿计的客户投诉工单需要耗费大量的人力、物力和财力,因此移动公司一直在致力于提升客户服务水平,引入K均值等更加先进的数据处理技术,及时、准确地将投诉工单进行分类,然后将处理结果反馈给客户。
[1] 李睿颖, 柳炳祥, 万义成. 一种基于K-Means算法的移动客户聚类分析方法[J]. 数字技术与应用, 2016(8):157-158.
[2] 刘璐璐, 惠曾强. 一种基于K-均值聚类算法的站点结构优化研究[J]. 中国科技信息, 2016(20):68-69.
[3] 穆荣斌, 仲梁维. 基于K-均值算法的数据挖掘技术研究及应用[J]. 软件导刊, 2017,16(4):185-187.
[4] 饶喆, 唐双喜, 刘国平. 基于蚁群粒子群混合算法的K均值聚类优化算法研究[J]. 数字技术与应用, 2015(4):122-123.
[5] 李莺. 运营商投诉行为的大数据分析及应用[J]. 通信企业管理, 2016(10):67-69.
[6] 岳丹阳. 移动通信客户投诉的智能诊断方法研究[J]. 中国新通信, 2016(17):1-3.
