随机森林算法在空气质量评价中的应用
2018-07-04杨敬辉黄国荣
杭 琦,杨敬辉,黄国荣
(上海第二工业大学a.环境与材料工程学院;b.智能制造与控制工程学院,上海201209)
0 引 言
随着工业化进程加快,城市人口增多,空气污染的问题也日趋严重。近年来,虽然国家在大气污染防治的问题上取得了很大的成就,但是我国的大气污染问题仍然不容乐观,特别是以可吸入颗粒物、氮氧化物、臭氧等为主要污染物的空气污染问题也日趋严重。为了加强空气污染防治工作,减少由于空气污染造成对人体健康的危害和对环境造成的污染,采取有效的空气评价方法对海量的空气质量数据进行评价,并以此为基础进一步减少大气污染、优化空气质量,就显得尤为重要[1]。
目前国内外空气质量的算法有BP神经网络法[2]、支持向量机(support vector machine,SVM)[3]、决策树[4]和污染损害率法[5],文献[2]中提出的神经网络算法具有很强的自学习和自适应能力,但其在训练的过程中需要大量的原始数据,计算量较大;对于经典的SVM算法,它处理二分类算法的效率较高,但对于多分类模型来说,分类的准确性较低;文献[4]中提出的决策树算法中不能较好地处理连续值的属性、产生过拟合或欠拟合的情况;文献[5]中的污染损害率法的评价结果较客观,但是没有考虑PM2.5和O3的浓度问题对空气质量的影响。本文考虑并增加了PM2.5和O3两个属性,并创新性地采用随机森林算法进行空气质量评估。随机森林算法是在决策树理论基础上发展起来的一种新的分类算法,它解决了小样本、高维度和多分类等实际问题,并且无需做特征选择,对数据集的泛化能力强,既可以处理离散型数据,也可以处理连续型数据,既克服了神经网络收敛速度慢,需要大量样本等缺点,也很好地解决决策树过拟合或欠拟合以及经典SVM对多分类模型准确率较低等情况,具有较好的推广性。本文采取《环境空气质量标准》中给出的大气污染物的种类,利用2014—2016年统计年鉴的数据,将泛化能力强、训练速度快的随机森林算法引入空气质量评价模型,对我国113个重点城市的空气质量进行评价,将评价结果与其他分类算法进行比较,取得了满意的效果。
1 研究方法
1.1 随机森林的工作原理
随机森林(random forest)是一种基于分类树(classif i cation tree)的算法[6],它通过Bootstrap重采技术,以随机的方式来构建一个森林,利用Bagging算法有放回地从原始训练数据集中取样得到多个Bootstrap训练数据集,然后用每个训练集进行训练得到相应的决策树模型。随机森林可以生产几百个甚至几千个决策树,它的预测分类结果是通过模型中的所有决策树的投票结果来执行的,票数最多的一类即为随机森林模型选出来的最佳分类器。总的来说随机森林就是一个综合考虑多个决策树而形成的一种集成分类器的算法。
1.2 随机森林基分类器—-决策树
对分类问题或规则学习问题,决策树的生成是一个从上至下、分而治之的过程[7]。决策树从根节点开始,对每个非叶节点找出一个特征对训练集进行测试,根据不同的测试结果将训练集划分为若干个分支,每个分支构成一个新的非叶节点,再重复上述的划分过程,直到达到规定的终止条件或者自然终止而形成叶节点。故决策树需要比较不同的组合,选择划分结果最好的特征进行节点的划分。效果最佳的两种划分节点的方式为信息增益和Gini指数。根据信息论中熵值的定义,信息熵越大表示数据纯度越高[8]。对于信息增益来说,使用划分前后的熵的差值来划分效果的好坏。样本T的信息熵公式为:

式中,pi表示任意类别样本i占T的概率。H(T)越小,说明样本信息越有序。当用特征A进行分割时,T个样本将会被分割为k个部分,此时就可以计算用特征A分割节点的信息熵和信息增益分别用H(TA)、G(T,A)来表示。公式如下:

对于Gini指数来说,某节点的Gini指数越小,分类效果越好。公式如下:

由上述公式可以看出,信息增益和基尼系数大体一致,而随机森林算法在选择划分方法时,一般选择用Gini指数进行划分。但由于决策树在划分节点时采用的是单一分类器的决策模式,故经常存在由于分类器过于复杂而导致的过拟合或者欠拟合问题。
1.3 随机森林的构建
为了克服决策树过拟合或欠拟合问题,必需解决单分类器决策模式,此时基于多分类器的随机森林算法的出现很好地解决了这个问题。构建随机森林主要有以下几个步骤:
(1)从原始数据T里面通过Bootstrap抽样法抽取N个样本组成一个新的训练集TN,并且每个样本之间相互独立。
(2)对每个通过Bootstrap抽样法建立的分类树模型,产生m棵分类树从而形成“森林”,每棵决策树均不需要剪枝处理。而且在构建每棵树时,并不是选择全部k个属性都参与属性指标的计算,而是使用简单随机抽样,选择其中k(k∈K)个属性进行比较。
(3)生成的多个决策模型相当于多个领域的专家,统计m个决策树的分类结果,最后采用投票方式决定要样本的类别。
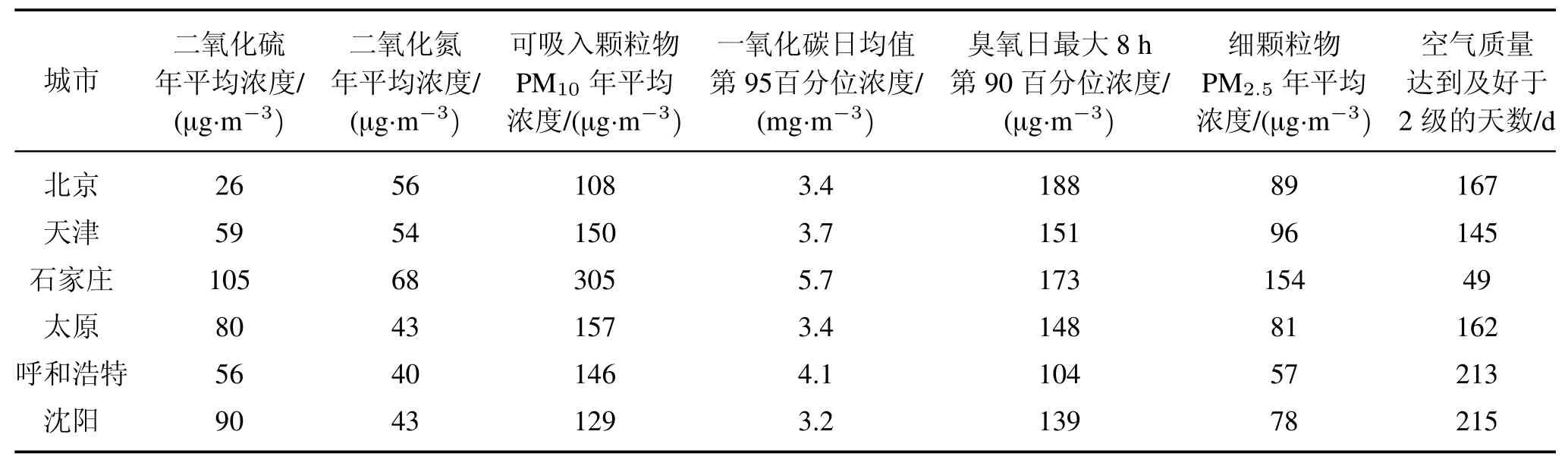
表1 部分重点环保城市空气质量情况Tab.1 Partial air conditions of major environmental protection cities
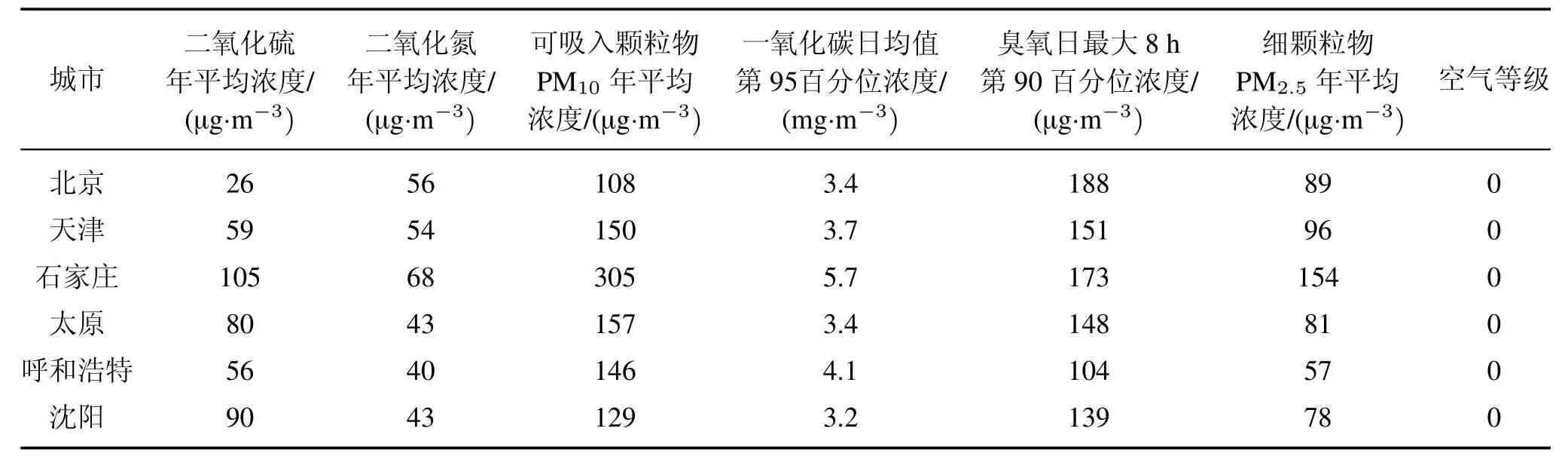
表2 二分类模型预处理部分数据Tab.2 Partial data preprocessing of binary classif i cation model
2 数据来源及预处理
要准确地建立空气质量的评价模型,首先要了解影响空气质量的因素[9]。本文选取2014—2016年我国113个环保重点城市的空气质量数据[10],空气质量标准取于《环境质量标准》(GB3095—2012),根据影响空气质量的几个重要因素作为属性变量,同时使用空气质量达到及优于2级的天数来表示空气质量好坏。本文所使用的部分原始数据如表1所示。
本文样本个数为277个,由于表中的6个属性的量纲级别差距不大,且随机森林有着较好的泛化能力,故此数据集无需做规范化处理,节约了大量时间。为了得到较好的分类精度,令响应变量Y为空气质量达到及优于2级的天数占全年天数的比重。本文同时考虑随机森林的二分类和多分类的能力,先对二分类中的响应变量Y处做如下处理:依据2015年2月2日环境部网站消息,我国重点环保城市的空气质量平均达标天数为298 d,约占全年的70%,故本文以70%作为阈值点。当空气质量达到及优于2级的天数占全年的比重大于等于70%时,归类为空气质量较好,用“1”来表示,当比重小于70%时,归类为空气质量较差,用“0”来表示,如表2所示;而对于多分类模型,当空气质量达到及优于2级的天数占全年的比重大于等于70%时,用“2”来表示,当空气质量达到及优于2级的天数占全年的比重大于等于30%且小于70%时,用“1”来表示,当空气质量达到及优于2级的天数占全年的比重小于30%时,用“0”来表示,如表3所示。

表3 多分类模型预处理部分数据Tab.3 Partial data preprocessing of multiclass classification model
3 随机森林算法的构建和结果分析
对预处理后的数据进行抽样,抽取70%的数据作为训练样本,其余作为测试样本。模型主要由输入、输出和算法处理3部分组成,其中模型的输入部分包括建模的样本输入和参数输入。本文所用到的原始样本为277个,从空气质量分布可以看出,在中国空气质量较好或较差的城市占比较少,而城市质量一般的城市占比相对较多。其中较好的占比30%~40%,较差的占比5%~15%,一般的占比50%~60%。考虑到数据的分布情况,本文在算法构建的过程中采用非平衡的方法进行取样。在利用spss modeler构建随机森林分类器时,首先设置要构建的决策树的个数为300,也就是要从原始样本中,利用Bootstrap抽样法进行300次采样,并用这300组数据集分别作为决策树根节点的训练样本。每棵决策M树随机选择的特征数目为系统默认参数,一般取其中M 为总特征数目。同时设置最大树深度为10,最小子节点大小为5,以信息增益的高低来确定每个分类节点的最佳分割阈值。最终训练完300棵树后,系统自动统计300个决策树的分类结果,最后采用投票方式决定此样本的类别。实验共重复100次,取其平均结果作为最终的分类结果。为了比较随机森林算法与其他算法的优劣,在相同的数据环境下,同时还建立了SVM模型、人工神经网络和决策树模型。
为了说明各个算法的分类精度,本文使用随机森林模型在测试集上的分类准确率来衡量二分类模型和多分类模型的分类效果,其指标的比较如图1所示。

图1 二分类模型性能指标的比较Fig.1 The comparison of different indicators of binary classif i cation model
准确率公式如下:

式中:nsample为样本总数;ˆy为测试样本类别;而yi为实际样本类别即

图2所示为多分类模型性能指标的比较。从图1、图2中可以直观地看出,无论是二分类还是多分类,对于分类的准确率来说,随机森林算法的分类准确性最高。从图中可得知随机森林、神经网络、决策树、SVM这4种算法的准确性值依次降低,说明与这些算法相比,随机森林具有更好的分类精度,综合性能最好。图3所示为基于随机森林算法计算得出的预测变量重要性的排序结果。由结果可看出,本文给出的6个属性变量在构建空气质量评价模型时,均产生了一定的影响,而可吸入颗粒物PM10,细颗粒物PM2.5和O3的浓度是影响各大城市空气质量好坏的主要因素。

图2 多分类模型性能指标的比较Fig.2 The comparison of different indicators of multiclass classif i cation model
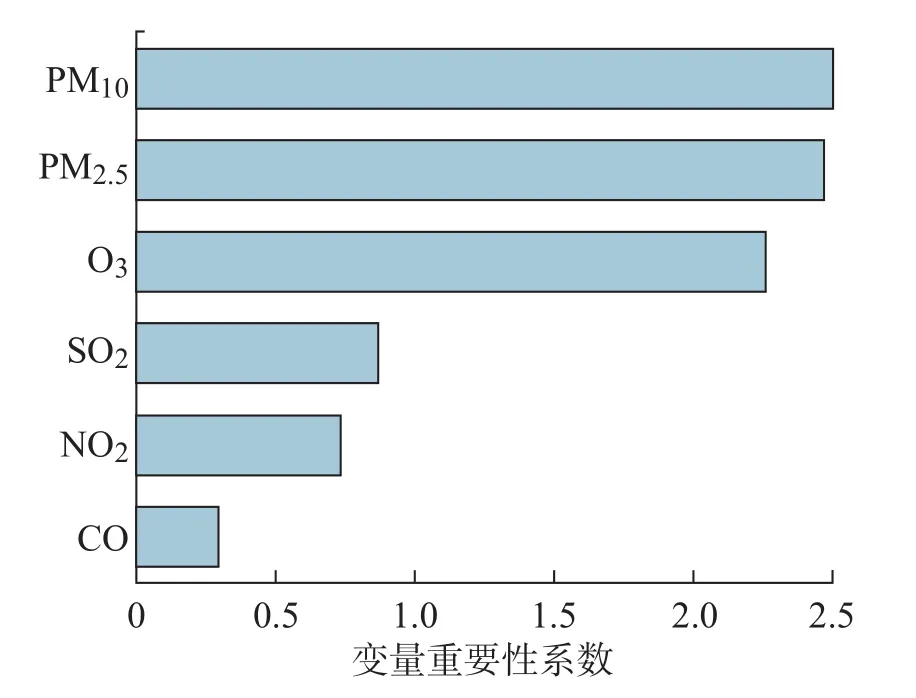
图3 预测变量重要性排序结果Fig.3 Results of predicting the importance of variables
4 结 论
随着国家对环境保护的重视,有关空气质量的评估方法也日趋完善。无论是在空气监测范围上还是在数据的处理速度或是准确率上都有了很大的进步。国家在2016年正式将PM2.5和O3列入全国空气监测范围内,本文收集到了3年的数据,并在现有研究的基础上,增加PM2.5和O3两个影响因子,针对影响空气质量的几个重要因素,得出了影响空气质量因素的重要性排序,并且在常用的准确率评价指标的基础上,将随机森林算法应用于空气质量评价模型的研究中,并与决策树、SVM和神经网络算法进行比较,发现无论在二分类还是多分类模型中,随机森林算法的分类效果均优于上述几类算法。同时随机森林算法在数据的处理方法上只需知道空气质量的分级标准就可以建立模型,只要样本属性选择恰当,无需对原始数据进行归约和标准化处理,收敛速度快,具有比较好的推广性,有利于空气质量的科学评估。
[1] 汪滢.基于决策树的数据挖掘算法在空气质量评估中的应用[D].南昌:南昌大学,2009.
[2] 陈祖云,金波,邬长福.支持向量机在环境空气质量评价中的应用[J].环境科学与技术,2012,35(6):395-397.
[3] 李璐,刘永红,蔡铭,等.基于气象相似准则的城市空气质量预报模型[J].环境科学与技术,2013,36(5):156-157.
[4] 汪滢,邱芬.基于决策树算法在空气质量评估中的应用[J].科技视界,2012(31):253-254
[5] 李祚泳,彭荔红.基于遗传算法优化的大气质量评价的污染危害指数公式[J].中国环境科学,2000,20(4):313-317.
[6] 李欣海.随机森林模型在分类与回归分析中的应用[J].应用昆虫学报,2013,50(4):1190-1197.
[7] 王峥琦.基于决策树算法的改进与应用[D].西安:西安科技大学,2005.
[8] 马骊.随机森林算法的优化改进研究[D].广州:暨南大学,2016.
[9] 沈劲,钟流举,何芳芳,等.基于聚类与多元回归的空气质量预报模型开发[J].环境科学与技术,2015,38(2):63-66.
[10]中华人民共和国国家统计局.环境统计数据[Z/OL].[2017-12-09].http://www.stats.gov.cn/ztjc/ztsj/hjtjzl/.
