基于实体对齐的知识图谱构建研究
2018-06-28,
,
( 1. 安徽科技学院信息与网络工程学院,安徽 滁州 233100; 2.北京邮电大学计算机学院,北京 100876 )
0 引 言
知识图谱自2012年由谷歌提出后,引起了人们的广泛关注。如Knowledge Graph[1],DBpedia[2]、百度知心,以及清华大学和上海交通大学建立的XLORE[3]和Zhishi.me[4]。这些知识图谱大都是利用群体智能在已有的结构化知识上建立的,对非结构化的文本信息覆盖比较少。由于大部分的实体都没有结构化的信息,在使用时仅覆盖少数领域。因此面向领域的知识图谱的研究逐渐引起人们的注意,清华大学的杨玉基[5]等人提出通过“四步法”,基于领域本体、语义标注和互联网数据准确高效的构建地理学科知识图谱,为构建领域知识图谱提供新的思路。杜亚军[6]等为了扩大微博搜索的效率,通过提取微博社区中的人物、事件、地点、话题和事件等概念及概念之间的组合关系构建微博社区知识图谱,并对图谱进行分析。熊晶[7]等为了提高甲骨文信息共享率,基于MKD知识图谱和甲骨文中隐含的语义关系,重点解决甲骨文知识图谱构建过程中的实体发现问题。唐诗是中国文学史上的灿烂明珠,作品量比较多,如果利用知识图谱技术建立唐诗、作者和地点等关系图谱,可以帮助学习者从多个方面研究唐诗文化,从而挖掘其中深层次的知识。但是,关于诗词知识图谱的研究还处于初期,由于现在可依赖的诗词书籍和网络资源比较丰富,百科类的数据如维基百科和互动百科中关于诗词和诗人介绍的也比较多,因此在分析各种数据源的基础上,探讨基于实体对齐的知识图谱构建方法,系统技术路线如图1所示,共分为三个部分。分别是数据来源、知识图谱构建的关键技术和知识图谱存储。其中,数据来源部分主要自动抓取百科和垂直网站中的诗人相关的数据;知识图谱构建的关键技术包含构建本体模型,抽取实体和属性相关数据并通过实体对齐技术对数据进行融合;最后把融合后的知识图谱存储到数据库中为查询和推理提供技术支持。
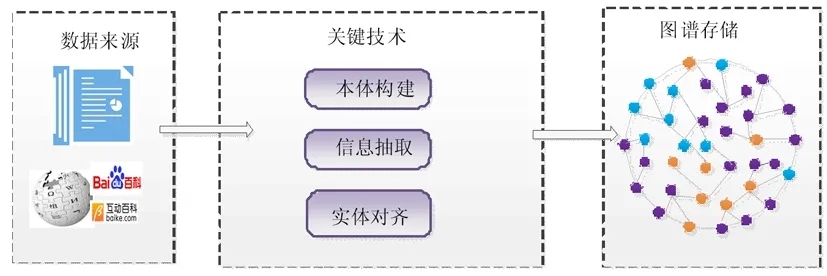
图1 系统技术路线图
1 数据来源
1.1 百科类数据
百科类网站以图的结构存储大量的用户生成数据,覆盖面比较广,各个领域的数据都会涉及,因此可做为面向领域的知识图谱的数据来源之一。在中文领域,比较知名的是维基百科、百度百科和互动百科,它们都含有诗人、古诗和地点的结构化数据,每个页面具体包括标题、类别标签、信息框和摘要等信息。标题一般对应实体的名字。类别标签表示实体所属的类别,比如,在百度百科中,实体“李白”的标签有“诗人”,“文学家”,“文化人物”和“历史人物”。信息框可以作为实体属性和实体关系的来源,摘要主要是描述实体的文本信息。
1.2 其他数据源
面向领域的网站上的数据是半结构化,描述的也是特定领域的知识,很多站点都是把保存在数据库中某些领域的知识展示出来。虽然范围比较窄,但是专业性比较强,是构建知识图谱中比较好的数据来源。目前关于诗词的网站比较多,古诗文网作为传承经典的网站,专注于古诗文的服务,包括各个朝代的作者简介,诗词和古籍信息等,数据比较集中和完备,所以从该网站爬取了42153条唐代所有作者的诗词信息来补充和扩充从百科中爬取的数据。
2 关键技术
2.1 本体构建
知识图谱的构建可采用自顶向下和自底向上的方法,自顶向下主要是先构建本体[8],为知识图谱提炼模式,定义领域内的概念、关系后,再把实体一个个添加进去。自底向上的方法则是从实体开始进行归纳底层的概念,然后逐步抽象上层的概念。这里采用自顶向下的方法构建知识图谱,统计在相关资料中出现频率相对较高的术语作为领域内的核心概念,如“地点”、“诗人”和“古诗”等,每个概念下都有若干实体,如“诗人”这个概念下就包含“李白”、“杜甫”、“白居易”等实体。另一方面,关系也是知识图谱的核心要素,他描述了领域内的概念、实体之间的相互作用,关系越多知识图谱越丰富。关系的类型参考百科的标签、实体的信息框及在文本中抽取的关系来确定,其中最主要的是上下位关系。
2.2 信息抽取
信息抽取主要是自动的从多数据源中抽取出实体、关系及属性等信息。抽取实体是指从文本集中抽取人命、地名或组织结构名等,它是信息抽取的基础,这里利用斯坦福的实体识别工具进行抽取。而实体之间的关系可分为上下位关系、属性关系及开放式关系。上下位关系是描述实体间包含与被包含的语义关系,上位词是指比较广泛的概念,下位词是指比较窄的概念。如上例中“李白”就是其标签“诗人”的下位词,可以通过百科中的描述信息获得。同样属性关系可以通过百科中的信息框得到,它包含大量的属性关系元组,比如“李白”的信息框中有属性“去世地”是“安徽马鞍山市当涂县”,通过这个关系就把诗人和地点信息建立了关联。利用Selenium爬取百科类的数据,并对同一实体的属性值进行整合。如图2所示,从百度百科、互动百科和维基百科中获取的“白居易”的信息框,对姓名属性,各百科中的描述是不一样的,在构建图谱前需要整合。但是百科中的信息毕竟有限,在非结构化的文本集中也存在大量的关系元组,因为该领域的关系类型比较稀少,因此这里采用人工定义关系类型,然后自动抽取“实体-关系-实体”元组来扩充知识图谱。
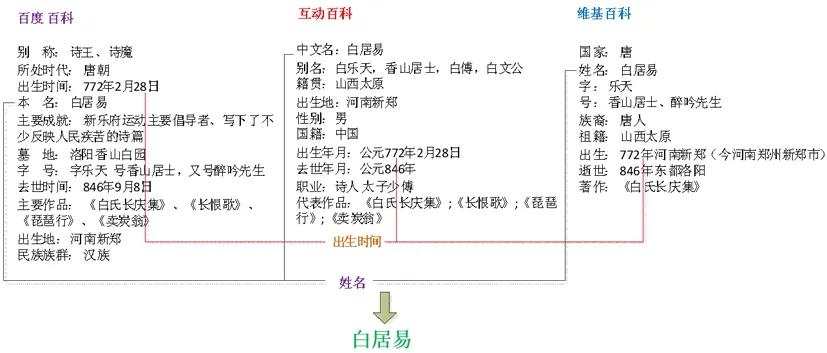
图2 实体属性整合
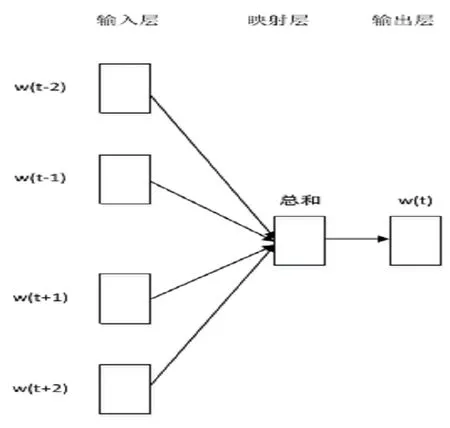
图3 CBOW模型结构图
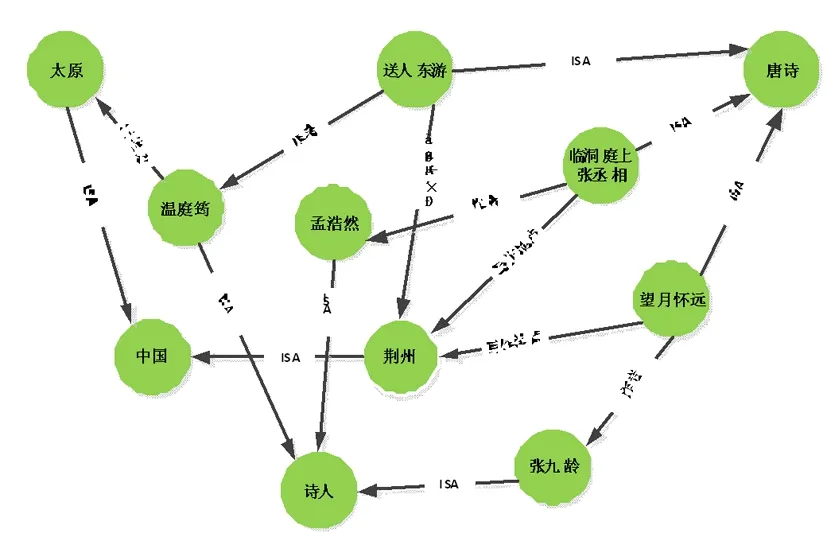
图4 诗人知识图谱展示
2.3 实体对齐
不同的网站可能包含对同一实体的描述数据,当基于多数据源来构建知识图谱时,需要对实体对齐,找出不同来源的实体是否描述的是现实世界中的同一实体,以便把开放领域抽取的三元组添加到知识图谱中,对知识图谱进行扩充。如 “王维”可能指唐朝诗人、画家,也可能指清华大学教授、博士生导师和北京儿童医院副主任医师等。因此,当我们扩充知识图谱时,首先要进行实体对齐。主要基于词向量来表示实体的上下文,通过文本相似性完成对齐。Mikolov提出的词向量主要是将字词转为计算机可以理解的稠密向量[9],包括CBOW和Skim-Gram两种模式,CBOW主要是根据上下文来预测目标字词,适用于小语料,而Skip-Gram则是根据目标字词预测上下文,在大型语料上表现比较好。由于主要是对唐代诗人数据,因此这里主要采用CBOW模型来训练数据。模型结构如图3所示,给定一个单词wt的上下文序列wt-2,wt-1,…,wt+1,wt+2,采用层次softmax算法,并结合Huffman编码,让要预测词的二进制编码概率最大。
训练好词向量后,实体所在的上下文就可以通过其含有的所有词的词向量相加并取平均值的方式表示,公式如下所示:
(1)
其中,wt表示特征词t的词向量,N(c)表示上下文c中的词数,v(c)是上下文c的向量表示。同样,知识图谱中的实体也可以用上述公式把它的描述信息k的向量表示为v(k),然后通过余弦相似度公式计算两个实体的相似性,当余弦值大于0.7时,认为它们是同一实体,把它添加到知识图谱中。
3 知识图谱存储
构建好知识图谱后,需要进行合理的存储,以便高效的查询和展示。在唐代诗人知识图谱中,概念、实体之间存在非常复杂的关联,所有的节点构成一张图,因此,可使用图数据库进行存储和展示。常用的图数据库Neo4j,FlockDB,InfoGrid等,其中Neo4j是一个高性能的图形数据库,它将结构化数据存储在网络上而不是表中。实现了图结构中的节点,边以及属性来进行图数据的存储,比较适合知识图谱的存储和展示。这个使用Neo4j来存储构建好的图谱,图4展示了唐代诗人知识图谱的一部分。这里单个节点表示实体,实体之间的连线表示存在一点的关系。比如“送人东游”、“临洞庭上张丞相”和“望月怀远”和“荆州”之间都存在写作地点这样的关系,这就可以为按地点的诗词查询和推荐提供服务。
4 结 语
知识图谱可以从海量的数据中提取结构化的知识,因此为多源数据的组织提供了一种更为有效的方式。目前,知识图谱已在智能搜索、深度问答、社交网络以及一些垂直行业中有所应用。但许多领域的应用也只是处于初级阶段,古诗词是中华民族的瑰宝,可以熏陶人的文学素养和言行举止。但是,现在古诗词的数据分布比较广,类型多样,基于实体对齐技术,以唐诗为例,获取大量的地点、诗人和古诗相关的信息,构建唐代诗人知识图谱,为有效的组织诗词数据以及探索知识图谱在行业领域的应用提供了新思路。
参考文献:
[1] Singhal A. Introducing the knowledge graph: things, not strings. Official Google Blog, 2012-5.
[2] Bizer C, Lehmann J, Kobilarov G, et al. DBpedia-A crystallization point for the Web of Data. Web Semantics: science, services and agents on the world wide web, 2009, 7(3): 154-165.
[3] Wang Z, Li J, Wang Z, et al. XLore: A Large-scale English-Chinese Bilingual Knowledge Graph[C]//International semantic web conference (Posters & Demos). 2013, 1035: 121-124.
[4] Niu X, Sun X, Wang H, et al. Zhishi. me-weaving chinese linking open data[C]//International Semantic Web Conference. Springer, Berlin, Heidelberg, 2011: 205-220.
[5] 杨玉基,许斌,胡家威,等.一种准确高效的领域知识图谱构建方法.软件学报,2018,29(10).
[6] 杜亚军,吴越.微博知识图谱构建方法研究[J].西华大学学报 (自然科学版), 2015,34(1): 27-35.
[7] 熊晶,钟珞,王爱民.甲骨文知识图谱构建中的实体关系发现研究[J].计算机工程与科学,2015, 37(11): 2188-2194.
[8] Studer R, Benjamins V R, Fensel D. Knowledge engineering: principles and methods[J]. Data & knowledge engineering,1998, 25(1-2): 161-197.
[9] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean.Efficient estimation of word representations in vector space. ICLR Workshop, 2013.
