基于混合策略的中文短文本相似度计算
2018-06-26宋冬云张祖平
宋冬云,郑 瑾,张祖平
中南大学 信息科学与工程学院,长沙 410083
1 引言
随着互联网信息技术的快速发展,人们可以方便地上传或下载共享的文档信息,这种以数字文档为媒介的共享模式导致了海量文档的存在。因此,如何在海量文档中,快速精准地计算文档相似度,从而进行有效的信息检索变得尤其重要。
句子相似度是衡量文档相似度的重要依据,广泛应用于自动文本摘要、信息检索、文本分类和机器翻译等领域[1-5]。然而,由于中文句子的语法结构复杂多变,语义语境的多异性等因素,增加了中文句子相似度计算的难度。为了有效地计算中文句子之间的相似度,专家学者提出了大量的方法,主要分为两类:基于向量空间模型的方法[6-10]和基于语法语义模型的方法[11-14]。
基于向量空间模型(Vector Space Model,VSM)的方法通过统计句子中词语出现的频率,将句子转化成空间向量,从而将文本的相似度简化为空间向量的距离。由于传统的VSM方法只考虑词语的频率,忽略词语在句子中的语义和语法结构,使得文本相似度计算不准确。因此,专家学者对传统的VSM进行大量的改进[7-10]。文献[7]在传统VSM的基础上,增加词语的句法和语义信息,提高了词语相似度计算的准确性。文献[8]将概念作为句子的基本语言单元,通过概念抽象和专业分类,使得构建的空间向量在文本语义表达方面更为准确。考虑到专业词汇在特定领域的重要性,文献[9]使用领域权重概念对VSM进行改进,提高了VSM在特定领域的准确性。
基于语法语义模型的方法通过现有预料构建词语知识库,并将词语在知识库中的关系距离,作为词语之间的相似度。文献[11]以HowNet为知识库,提取语义关联的词语,并结合词语出现的频率计算句子的相似度,取得了较好的效果。文献[12]将命名实体的信息内容加权,并结合句子的语法语义特征,综合评估相似度。文献[13]考虑到语句中不同词语对语句之间相似度的不同贡献程度,提出一种基于频率增强的语句语义相似度算法,使得计算的相似度更加接近人们的主观判断。
虽然,现有方法对传统的VSM和语法语义模型进行了一定程度的改进,但是仍存在一定的局限性。基于VSM的方法通过向量的形式,机械地考虑了句子的字面语义,针对于特定领域的文本能取到较好的效果,但由于缺乏句型结构的分析,对于一般的文本,效果不佳,泛化能力有待提高。而基于语法语义的方法综合考虑到了句子的成分组成和语法结构,计算的相似度更加符合人们的主观判断,但是,由于需要计算全部语法结构成分之间的相似度,因此,计算复杂度高,效率较低。因此,本文结合短文本的特点,分别使用基于层次聚类的关键词权重计算和句子成分主干分析过滤的方法对两者进行改进,并结合改进之后的方法,提出一种基于混合策略的文本相似度计算方法,完成中文短文本相似度计算任务。
2 基于混合策略的中文短文本相似度计算
文本相似度计算方法流程如图1所示。首先,借助现有的工具对中文短文本进行预处理,得到词语的词性。然后,根据词语的语义距离,使用层次聚类构建短文本聚类二叉树,将文本的关键词权重计算转化为二叉树中节点的深度问题,计算基于关键词权重的相似度,与此同时,使用句子主干分析方法提取句子主要成分,改进传统的语法语义模型,进而分别计算短文本的相似度。最后,综合计算两种相似度,得到文本最终的相似度。

图1 算法流程图
2.1 预处理
通常文本相似度计算是基于词语进行的,因此需要对中文短文本进行分词、词性标注和停用词过滤等预处理操作,得到有效的词语序列,及其相应的词性。其中预处理操作如下:
分词:通过斯坦福分词[15]工具对中文短文本进行分词操作,得到一系列有序的词语序列。
词性标注:将分词之后得到的词语序列使用斯坦福词性标注工具[16]进行词性标注操作,得到词语相应的词性。
无效词过滤:根据词语词性,将代表实际含义的实词定义为有效词,包括动词、名词、形容词以及副词,而将连词、介词、代词等虚词视为无效词,并进行过滤,不予考虑。
将预处理后的词语集合分别使用2.2节和2.3节中的方法,计算基于关键词权重的相似度和主干成分的语义相似度。
2.2 基于关键词权重的文本相似度计算
TF-IDF是信息检索领域常用的加权方法,广泛应用于多文档相似度计算领域[17-18]。该方法通过统计关键词的频率和逆文本频率综合计算关键词在文档中的权重,减低文档中高频低区分度词语对相似度计算的贡献程度。其中,逆文本频率的主要思想是包含某词条的文档越少,则该词条IDF的值越大,说明该词条具有很好的类别区分能力。然而,由于中文短文本的词语数量较少,无法构建大量的统计信息,得到的关键词的逆文本频率不准确,进而,无法构建TF-IDF权重向量。考虑到文本中,语义差异大的词语,区分文本相似度的能力越强,进而获得较高的权重。因此,针对于中文短文本的特性,本文提出了一种基于层次聚类构建词语权重向量的文本相似度计算方法,其主要步骤如下:
步骤1构建层次聚类单元。对句子Sen1和Sen2经过预处理之后,得到m和n词语,将每一个词语视为一个单独的集合,记为C={cij},作为层次聚类的基本单元,其中cij表示第i个句子中第 j个词语。将所有的集合C组合到一起,记为S={C1,C2,…,Cm+n}。
步骤2聚类单元合并与更新。根据公式(1)计算S中两两聚类单元之间的相似度,选取相似度最大的两个单元Ci和Cj进行合并,形成新的单元Ck=Ci⋃Cj,并更新Ck与S中其他单元之间的相似度距离。其中dis(cuv,cmn)表示计算两个词语之间的语义相似度,具体计算采用文献[19]中的方法,u≠m表示词语cuv和cmn分别来自于不同的句子。

步骤3构建层次聚类二叉树。重复步骤2,直到S中只含一个元素,构建层次聚类树。图2举例说明句子“党中央制定的路线方针政策得到落实”和“全党自觉服从党中央制定的方针政策”构建层次聚类树的过程,其中节点中的编号表示聚类单元合并的顺序。
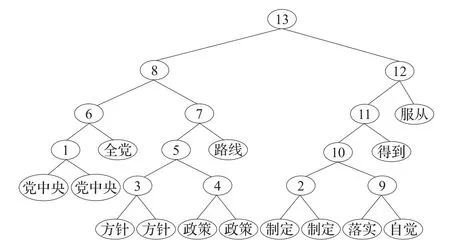
图2 层次聚类二叉树
步骤4计算层次聚类树的深度,构建权重向量W。计算步骤3中构建的层次聚类树深度,记为H。将根节点的层次记为0,从上往下,依次统计每一个词语所在的层次h。如果同一个词语出现在树的不同位置,则取均值,作为词语的深度。然后,使用公式(2)计算每一个词语的权重w,进而构建权重向量W。其中,对深度差加1的目的是为了避免词语权重为0的情况。

步骤5空间向量构建。统计Sen1和Sen2中词语的频率,构建频率向量P1和P2。然后,结合频率向量P和权重向量W,根据公式(3)构建句子的加权空间向量,记为V1和V2。

步骤6基于关键词权重的相似度计算。根据公式(4)计算向量V1和V2的余弦距离,并作为句子Sen1和Sen2之间的相似度。

2.3 基于主干成分的文本相似度计算
传统的语法语义模型需要计算每一个词语的相似度,效率较低,且实际中,通常句子的主要成分是决定句子语义的关键。因此,本文使用基于主干成分的方法对传统语法语义模型进行改进,提高传统语法语义模型的计算效率。
2.3.1 句法结构和依赖关系提取
斯坦福语法分析工具[20]是目前较为成熟的语法分析工具,并在自然语言处理领域得到了广泛的应用[12,14]。该工具主要使用递归神经网络(Recursive Neural Network,RNN),结合文本的词性(Part-of-Speech,POS)以及语料库中的依赖关系等特征,训练得到语法分析模型,具有速度快、性能好等优势。
本文借助斯坦福语法分析工具对2.1节预处理后的词语序列及其词性进行语法分析,得到中文短文本的句法结构和词语之间的依赖关系。以句子“绑匪被警察制服了”为例,进行语法分析,其可视化结果如图3所示。图左侧为可视化的句法结构树,其中IP表示简单从句;图右侧为词语与词语之间的依赖关系,例如nsubjpass表示被动名词主语关系。
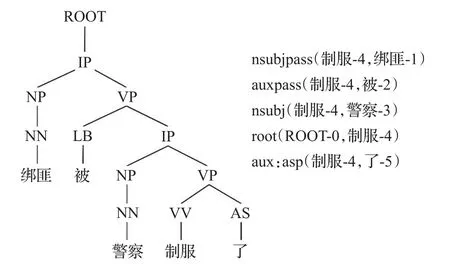
图3 语法分析可视化结果
2.3.2 中心词提取
中心词是贯穿整个句子结构的词语,且能高度概括句子内容,也是有效提取句子主干成分的关键。然而,中文文本句法结构较为复杂,不同的句法结构对应的中心词依赖关系构成也不相同,因此,需要针对不同的句型采取不同的策略进行中心词提取。考虑到中文文本的结构,将中文短文本分为名词性短语和简单从句两种类型,并根据句型决定中心词的提取。
首先,遍历2.3.1小节中的依赖关系集合,统计每一个词语对应的依赖关系的数量;然后,分别选取依赖数量最多的名词和动词作为候选中心词。最后,根据句子的语法结构,判断名词或者动词作为最终的中心词,记为Core。其中,由于名词性短语由名词和对应修饰成分组成,因此选择名词作为中心词;简单从句通常由主谓、谓宾和主谓宾结构构成,谓语是贯穿句子结构的核心,因此选取动词作为中心词。
2.3.3 主干成分提取
根据中心词,提取句子的主要成分,其包括主语成分集(Ss1,Ss2)、谓语成分集(Sv1,Sv2)、宾语成分集(So1,So2)和语态集(Sp1,Sp2)。对于只有主语成分的名词性短语,将中心词加入主语集合Ss中,并查找与Ss中有依赖关系的词语,将与中心词有并列依赖关系的名词加入到Ss中。对于简单从句主干成分,首先将中心词加入谓语集合Sv,然后,根据中心词与前后词语之间的依赖关系,确定句子语态Sp。最后,遍历语法树,找到与中心词存在依赖关系的词语,并根据句子语态Sp,将语法树中具有主语、名词性主语、被动宾语等依赖关系的词语存入主语集合Ss,将具有宾语、直接宾语、间接宾语、介词宾语,被动主语等依赖关系的词语存入宾语集合So。
2.3.4 集合相似度计算
假设集合S1和S2分别有m个词语(c11,c12,…,c1m)和n个词语(c21,c22,…,c2n),其中m 其中,dis(c1i,c2j)表示计算两个词语之间的语义相似度,ε为调节因子,具体的计算采用文献[19]中的方法,其文献中ε取值为0.2。 2.3.5 基于语法语义的相似度计算 综合2.3.3小节中得到的主要成分集合和2.3.4小节中的集合相似度,使用公式(6)计算句子相似度。其中,if(Sp1,Sp2)用于计算语态相似度,如果语态相同,取值为1,否则,取值为0。 对句子Sen1和Sen2经过2.2节和2.3节之后,分别得到句子相似度SimVSM(Sen1,Sen2)和SimMP(Sen1,Sen2),根据公式(7)对两者相似度加权计算最终的文本相似度。 其中,σ是权重调节因子,具体取值在实验中进行分析。 通常,相似度算法计算文本相似度得分属于[0,1]。为进行性能评估,设定相似度大于0.6的,则视为文本相似,否则视为不相似。 本文基于HowNet[21]词典,以Stanford工具进行句子的语法分析,在人工构建的测试集上,对算法的各个参数以及性能进行评价,并通过与其他的方法进行比较分析,以验证本文方法的有效性。 目前国际上还没有专门针对中文短文本相似度计算的公共测试集,文献[14]中采用人工构建的50对中文语句作为数据集。本文为了能更好地体现算法的有效性,分别在两个数据集上进行了实验。数据集I是通过知网、百度、Google搜索等平台,人工分析并组合,精心构建的200对句子,记为TEST-I,其中100对相似,100对不相似。数据集II是通过不同的翻译工具生成的2 000组相似句子对,再随机生成2 000组负类,共计4 000组句子对,记为TEST-II。 本文采用信息检索领域常用的召回率R、准确率P和F得分评估算法性能。其中F得分定义如下: 本文将基于关键词权重的相似度和主干成分的语义相似度进行加权,从而得到最终的文本相似度,因此对不同权重因子σ进行实验,确定最优的权重因子。本实验采用控制变量法,以0.1的步长对σ取不同的值,在TEST-II上进行实验,结果如图4所示。 图4 不同权重因子的实验结果比较 从图4可以发现,随着σ的变化,文本相似度的召回率R、准确率P和F得分大致呈现先增加后减少的趋势。当σ在0.5附近时,召回率R、准确率P和F得分均达到最优,分别为0.925、0.874和0.899。其他情况下,算法性能均有所下降。因此本文对σ取值为0.5,进行后续的性能评估。 为了验证本文方法的有效性,将本文方法与现有方法数据集I、数据集II数据集上进行实验,其中: 方法1传统的向量空间模型(VSM)的方法,具体细节详见参考文献[6]。 方法2基于语法语义的方法,具体细节详见参考文献[14]。 方法3本文基于关键词权重的方法。 方法4本文基于主干成分的方法。 方法5本文基于混合策略模型的方法。 表1展示了不同方法在数据集I上的文本相似度计算性能。从表中可以看出,传统的向量空间模型的召回率R、准确率P和F值分别为0.796、0.760和0.778,本文提出的基于关键词权重的方法文本相似度计算性能分别为0.852、0.813、0.832,相对于传统的向量空间模型,召回率R、准确率P和F值分别提高了0.056、0.053和0.054,这是因为本文基于关键词权重的方法采用词语语义距离和层次聚类相结合,从句子本身获得关键词权重,使得文本相似度计算更加准确,进而提高了文本相似度性能。此外,从表中还可以看出,本文基于主干成分的方法计算得到的文本相似度性能分别为0.836、0.821和0.828,相对于方法3在准确率相当的情况下,召回率也能有一定的提升。最后,将本文提出的基于关键词权重和基于语法语义方法相结合,形成混合策略模型的方法,其计算的文本相似度性能分别为0.866、0.856和0.861,相对于单一方法,具有明显的提高,这是因为本文提出的基于混合策略的模型,综合考虑了词语的频率,权重和语法语义,使得文本相似度计算更加准确。 表1 TEST-I的评测结果 为了进一步验证本文方法的有效性,将上述5种方法在更大的数据集TEST-II上进行实验,其评测结果如表2所示。 表2 TEST-II的评测结果 从表2中可以发现,本文基于混合策略的文本相似度计算方法的召回率R、准确率P和F值分别为0.925、0.874和0.899,在大数据集上,性能仍然高于其他文本相似度计算方法,进一步说明了本文方法的有效性。 文本相似度计算是自然语言处理中的重要课题。本文针对中文短文本,提出了一种基于混合策略的短文本相似度计算方法。该方法考虑到关键词权重对文本相似度计算的重要性,采用词语语义距离和层次聚类构建词语聚类二叉树,并根据词语在聚类树中的位置,构建权重向量,改进传统的基于VSM的方法。此外,根据中文的语义表达习惯,并从主干成分的重要性角度出发,提出一种基于句子主干成分的相似度计算方法,实现文本高效的语义相似度计算。最后,综合关键词加权相似度和主干成分相似度,得到最终的基于混合策略的文本相似度。将本文方法与现有方法在不同数据集上进行实验,结果表明本文方法在文本相似度计算的召回率R、准确率P和F值上高于其他方法,说明本文方法的有效性。 [1]Ferreira R,Cabral L D S,Lins R D,et al.Assessing sentence scoring techniques for extractive text summarization[J].Expert Systems with Applications,2013,40(14):5755-5764. [2]Yu L C,Wu C H,Jang F L.Psychiatric document retrieval using a discourse-aware model[J].Artificial Intelligence,2009,173(7/8):817-829. [3]Liu T,Guo J.Text similarity computing based on standard deviation[J].Lecture Notes in Computer Science,2005,3644:456-464. [4]Magnolini S,Vo N P A,Popescu O.Analysis of the Impact of machine translation evaluation metrics for semantic textual similarity[J].Lecture Notes in Computer Science,2016,10037:450-463. [5]Nguyen H T,Duong P H,Le T Q.A multifaceted approach to sentence similarity[M]//Integrated Uncertainty in Knowledge Modelling and Decision Making.[S.l.]:Springer International Publishing,2015. [6]Salton G.The SMART retrieval system—Experiments in automatic document processing[M].Upper Saddle River.NJ,USA:Prentice-hall,Inc,1971. [7]Zheng C,Qing L I,Liu F J.Improved VSM algorithm and itsapplication in FAQ[J].ComputerEngineering,2012,38(17):201-204. [8]Liang X,Wang D,Huang M.Improved sentence similarity algorithm based on VSM and its application in question answering system[C]//2010 IEEE International Conference on Intelligent Computing and Intelligent Systems(ICIS),2010:368-371. [9]苏小虎.基于改进VSM的句子相似度研究[J].计算机技术与发展,2009,19(8):113-116. [10]Yang S,Lou X Y.Research on sentence similarity based on VSM with semantic of word[J].Journal of Chengdu University of Information Technology,2012. [11]赵玉茗,徐志明,王晓龙,等.基于词汇集聚的文档相关性计算[J].电子与信息学报,2008,30(10):2512-2515. [12]Nguyen H T,Duong P H,Le T Q.A multifaceted approach to sentence similarity[M]//Integrated Uncertainty in Knowledge Modelling and Decision Making.[S.l.]:Springer International Publishing,2015. [13]廖志芳,邱丽霞,谢岳山,等.一种频率增强的语句语义相似度计算[J].湖南大学学报:自然科学版,2013,40(2):82-88. [14]廖志芳,周国恩,李俊锋,等.中文短文本语法语义相似度算法[J].湖南大学学报:自然科学版,2016,43(2):135-140. [15]Chang P C,Galley M,Manning C D.Optimizing Chinese word segmentation for machine translation performance[C]//The Workshop on Statistical Machine Translation,2008:224-232. [16]Toutanova K,Klein D,Manning C D,et al.Feature-rich part-of-speech tagging with a cyclic dependency network[C]//ConferenceoftheNorth AmericanChapter of the Association for Computational Linguistics on Human Language Technology,2003:173-180. [17]Erra U,Senatore S,Minnella F,et al.Approximate TFIDF based on topic extraction from massive message stream using the GPU[J].Information Sciences,2015,292:143-161. [18]Mikhaylov D V,Kozlov A P,Emelyanov G M.An approach based on TF-IDF metrics to extract the knowledge and relevant linguistic means on subject-oriented text sets[J].Computer Optics,2015,39(3):429-438. [19]刘群,李素建.基于《知网》的词汇语义相似度计算[D].北京:中国科学院计算技术研究所,2002. [20]Socher R,Bauer J,Manning C D,et al.Parsing with compositional vector grammars[C]//Meeting of the Association for Computational Linguistics,2013:455-465. [21]Dong Z,Dong Q.HowNet-a hybrid language and knowledge resource[C]//Proceedings International Conference on Natural Language Processing and Knowledge Engineering,2003:820-824.

2.4 混合策略相似度计算

3 实验及分析
3.1 数据集
3.2 评估标准

3.3 权重因子分析
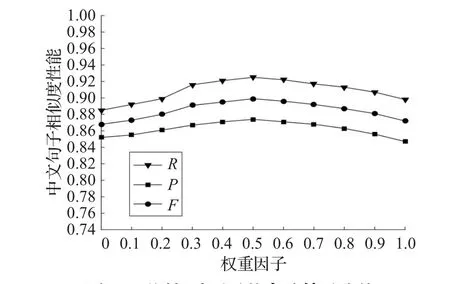
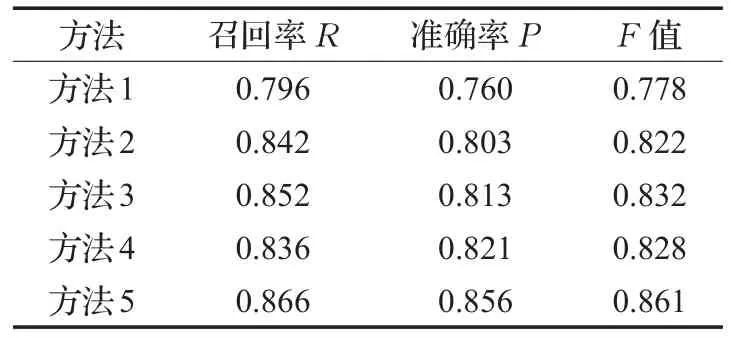
3.4 相似度算法性能评估

4 结束语
