视频阵列处理器多层次分布式存储结构设计
2018-06-26崔朋飞田汝佳
蒋 林,崔朋飞,山 蕊,武 鑫,田汝佳
西安邮电大学 电子工程学院,西安 710121
1 引言
阵列处理器,通过片上集成大量轻核处理元(Processor Element,PE),利用邻接短线互连而成,广泛地用于视频计算[1]。视频阵列处理器不仅具有强大的计算能力,而且适应后摩尔时代集成电路工艺的发展。但是,随着视频编解码标准的不断演进,计算量急剧飙升,数据访问量也随之增加[2]。虽然,通过片上集成更多的处理核,一定程度上可以提升视频阵列处理器计算能力,但是核数的增多进一步加剧了处理器访问存储的鸿沟,促使存储结构成为制约视频阵列处理器性能提升的主要瓶颈。
新一代视频编解码标准(High Efficiency Video Coding,HEVC)[3]在提升编码性能的同时,对系统带宽提出了更高的要求。特别是,面向帧间的运动估计与运动补偿算法由于其庞大的数据量,一方面处理元需要频繁访问主存读取参考像素值;另一方面,算法间的数据通信需要大量的数据共享,而在各算法内部,则会产生大量的不需要与外部进行交互的临时数据。因此,如何提供高效的数据交互机制同时满足临时数据的缓存要求便成为提升整个阵列处理器性能的关键。
为了解决这一问题,各种基于光互连和基于电互连的存储结构相继被提出。为了利用光信号在通信中速度快、稳定性高和功耗小的特点,文献[4]通过额外的光电转换器件,将电路由器引入到光互连网络中,使用光信号进行片上信号的传输。文献[5-6]中基于三维集成技术提出了一种多层的光电互连结构,通过光交换层实现处理器核心对多Bank存储器的并行访问。光片上通信虽然在带宽、延迟和功耗等方面具有显著优势,但物理实现较为复杂且成本高昂,同时光电转换带来的额外延迟、功耗等开销使得其不适合局部数据访问通信。
文献[7]中UltraSPARC T2处理器设计了多级Cache的存储结构,通过交叉开关,将L1级私有Cache与L2级Cache互连,但多级Cache间一致性复杂,硬件开销较大。文献[8]中基于簇的64核处理器结构中,每8个核构成一个处理元簇,每4个处理器核共享一个存储器,并通过路由器形成星型拓扑,进行核间通信,整个片上网络通过路由器形成mesh结构。但多个处理器共享一个存储器,增加了访问冲突概率,且星型拓扑需要8端口的路由器作为支持,无疑增加了设计的复杂度。文献[9]中的多核处理器结构,每个处理器核心拥有私有的L1级指令Cache和L1级数据Cache,4个处理器核心通过总线方式共享L2级Cache,通过全局的总线仲裁机制,维护Cache的一致性。虽然通过总线方式互连,设计简单,但当处理器核心增加时,总线压力急速增加,且可扩展性较差。文献[10]提出的CHMS结构中,通过共享的寄存器堆和共享的存储器实现处理器核心的通信,虽然能高效地进行数据共享,但由于所有存储资源共享,增加了并行化编程的难度,增加了访问冲突概率。
针对上述问题,同时为了满足视频编解码各算法间数据交互和各算法内部中间结果的缓存需求,结合视频阵列处理器多核阵列的结构特点,本文设计了由私有存储层和共享存储层构成的多层次分布式存储结构。考虑到视频编解码算法中,每个算法基于基本的编码宏块,针对4×4、8×8的编码单元进行处理,如运动估计、运动补偿以及变换量化算法,而所处理的编码单元通常由相邻的像素值构成,基于这一特点,本文利用视频算法编码单元的数据在时间和空间上的数据相关性,考虑结构设计的复杂度和可扩展性,结合阵列结构的拓扑特点,采用目录协议一致性策略,设计了由“逻辑集中,物理分布”的分布式存储器和多个Cache构成的共享存储层;考虑各个算法在数据处理期间,各算法内部数据的相对独立性,设计了由16个私有存储器构成的私有存储层。通过Xilinx公司FPGA板级验证,实验结果表明,该结构在保持简洁性和可扩展性的同时,最高能够提供9.73 GB/s的访存带宽,满足视频编解码算法数据访存的需求。
2 多层次分布式存储结构通信机制
多层次分布式存储结构由私有存储层和共享存储层两层结构组成,如图1所示。其中私有存储层由16个独立的存储器构成,该16个存储器组成4×4的存储器阵列,与4×4的处理器簇相对应,构成各处理器单元的的私有存储器;共享存储层由16个物理分布、逻辑统一的存储器块和16个Cache通过片上路由器互连构成。
当视频阵列处理器中的各计算单元处于数据准备阶段时,通过共享存储层,将所需数据加载到各私有存储器中;当计算单元处于算法的计算阶段时,对各私有存储器进行无冲突的读写操作,从而减小数据访问的冲突概率,提高算法的运算速度。
2.1 共享存储层Cache一致性

图1 多层次分布式存储结构示意图
传统的存储结构一般为片内私有的L1级Cache加私有或者共享的L2级Cache和集中式的外部存储器的分层次结构,采用基于总线结构的MSI、MESI、MOESI一致性协议[11],但随着处理器核数的增加,硬件资源的消耗以及设计的复杂度成倍提升,总线结构已经不能适应多核处理器系统的需求。基于NOC(Network on Chip,NOC)结构的分布式存储结构和基于目录协议[12]的Cache一致性策略由于其可扩展性和高效性,已经成为现代多核处理器存储体系的主流。
目录的组织形式一般分为全位向量映射目录、有限指针目录和链式目录[13]。在一个基于目录协议实现的多核系统中,目录由多个目录项组成,每个目录项对应一个Cache行大小的数据块,因此目录项的数目与存储器的总容量成正比关系。目录由两部分构成,一部分是状态信息,另一部分是共享信息。目录的状态信息表示当前Cache行所处的状态,如VALID,该状态信息位基本是固定的,不会随着系统规模的增长而变化,而目录的共享信息则表示当前系统中拥有该共享副本的节点信息,在全位向量映射目录中,每一位表示一个处理器核的共享状态,共享信息位会随着系统规模的增长而增长,有限指针目录和链式目录能够降低目录的存储开销,但也会大幅增加系统设计的复杂性,为了降低设计的复杂度,考虑到本文的簇内处理器核心数不多,本文采用全位向量映射目录的组织形式。
如图2,以3个存储器块为例,在系统初始阶段,存储器块对应目录中有效位为1,共享位为000。当PE00对存储块01读取数据时,首先访问目录存储器,当有效位为1时,将数据通过路由器返回PE00,同时更改目录信息为1001;当PE02对存储块01读取数据时,目录信息最高位为1,则直接读取存储器中数据,同时修改目录信息为1101;当PE00对该Cache行的数据修改过,且需要替换写回时,则目录信息修改为0001;随后当PE02读取存储块01时,目录信息有效位为0,则根据共享位向PE00发送写回请求,待数据写回后将数据返回PE02,同时修改目录信息为0101。

图2 共享存储层数据一致性过程
2.2 PE间的通信机制
对于PE来说,通过设置地址信息中的标志位,可以对私有存储器和共享存储器进行访问。当访问私有存储器时,则通过私有存储层直接访问,当访问共享存储器时,则需要通过片上网络的共享存储层进行通信。
当PE发出读请求时,本地Cache单元首先判断本地Cache是否命中,若命中,则直接读取所需数据,访问结束;若不命中,则向控制器发送读查找请求,控制器根据地址信息,判断向本地的存储器块或远程的存储器块发送读请求,若对应存储器块目录的对应行状态位有高,则读取对应数据,并修改目录信息,待数据写入本地Cache后,访问结束;若对应存储器块目录的行状态位为低,则根据目录中该数据的共享信息向拥有者发送写回请求,待数据写回后再读取数据并修改目录状态,待数据写入本地Cache后,访问结束。写访问过程与读访问过程类似,访问流程如图3所示。

图3 数据访问过程
3 多层次分布式存储结构的设计
多层次分布式存储结构中,共使用64个Xilinx定制双端口存储器IP(Intellectual Property,IP),其中,私有存储层16个,对应16个私有存储器,共享存储层48个,对应16个共享存储器、16个目录存储器以及16个高速缓存单元,通过互连网络构成层次化的分布式存储结构,如图4所示。

图4 多层次分布式存储结构框图
3.1 网络适配器的设计
网络适配器是本地PE与远程PE通信的网络接口,按照路由器格式对通信信息进行打包与解包操作,包格式如图5所示。
网络适配器由无效查找模块、无效发送模块、写回请求模块、替换写回模块和读查找模块5个模块构成,顶层结构如图6所示。
3.2 目录存储器设计
目录存储器是分布式Cache实现数据一致性的关键,主要由请求保持模块、目录控制模块、请求仲裁模块和目录存储IP模块以及数据存储器IP构成,顶层设计如图7所示。
请求仲裁模块对来自本地PE和远程PE的两路读写请求做出仲裁,采用本地优先的仲裁策略;请求保持模块对仲裁失败的请求暂存,等待下次仲裁;目录控制模块对仲裁成功的请求做出响应,分以下几种情况:
(1)读查找请求:目录控制器根据读查找地址,读取目录中的信息,如果有效位为高,则读取对应数据存储器Bank的数据,并根据读地址的高4位,记录读取数据的PE号,更新目录信息;如果有效位为低,则根据共享位信息,向对应PE发出写回请求,待数据返回,发回读查找数据,再对目录信息进行更新。
(2)通知无效请求:目录控制器根据无效查找的地址,读取目录中的信息,如果有效位高,则将有效位置零,并根据共享位,向对应PE发送无效请求;如果有效位为低,则根据共享位,向对应PE发送无效请求。
(3)替换写回请求:目录控制器根据替换写回地址,将替换写回的数据写入对应数据存储器Bank中,同时更新目录信息,将对应地址的有效位置1。
3.3 高速缓存单元的设计
高速缓存单元(Cache)采用4路组相联的地址映射策略,采用最近最少用[14]的写替换策略对本地PE的读写进行缓存。
高速缓存单元主要由状态寄存单元(State_reg)、命中判断单元(Hit_judge)、写策略选择单元(Wr_str)、读仲裁单元(Rd_arb)、读数据单元(Rd_data)和地址转换单元(Addr_trans)6个子模块构成,如图8所示。
(1)状态寄存单元:该模块用于记录高速缓存单元数据的实时状态,并采用最近最少用替换策略提供需替换的Cache行号。
(2)命中判断单元:当PE发出读写请求时,命中判断单元通过状态寄存单元的信息,判断本地Cache中是否命中。
(3)写策略选择单元:当PE读写不命中,需要向本地Cache调入数据时,写策略选择单元根据状态寄存单元的对应Cache行状态,做出替换写入或者直接写入的策略选择。
(4)读仲裁单元:该模块用于对PE发出的读请求、由写替换引起的读请求和控制单元发出的写回请求按照本地读有限的优先级做出仲裁选择。
(5)读数据单元:读仲裁单元送出的读请求信号进入读数据单元,读数据单元根据命中判断单元的判断结果,选择来自本地Cache的数据和来自控制单元的远程数据做出选择,在需要进行写替换时,向控制器发出写替换请求。

图5 路由器适配器包格式
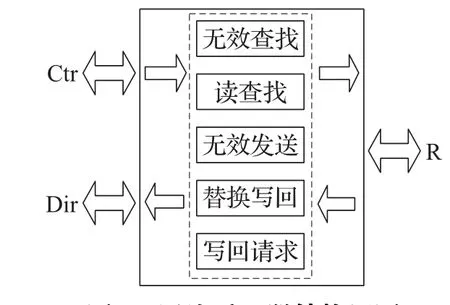
图6 网络适配器结构框图

图7 目录存储器结构框图

图8 高速缓存单元结构框图
(6)地址转换单元:在PE的读写过程中,存在命中与不命中两种可能,该模块对本地Cache缓存数据读写地址进行转换,在读写命中情况下,读写地址不做转换,直接送往本地存储器Bank;在读写不命中情况下,根据读写地址的高12位进行自增操作,完成读写地址的转换。
4 设计实现与性能分析
4.1 设计实现
在对网络适配器、目录存储器和高速缓存单元进行RTL级设计,通过编写几种典型访问情况下的测试激励,使用modelsim进行功能仿真后,与视频阵列处理器虚通道路由器、轻核处理器以及Xilinx定制存储器IP互连,通过Xilinx的Virtex-6系列xc6vlx550T开发板对设计进行硬件测试,具体参数如表1所示。

表1 多层次分布式存储结构参数
通过Xilinx ISE对设计进行综合,综合结果如表2所示。

表2 FPGA综合结果
由于访问延迟与片上Cache个数、地址映射策略、写替换策略、实时共享状态以及路由器的路由算法密切相关,图9和图10分别给出了采用最近最少用和写回的替换策略、4路组相联的地址映射策略以及采用XY维序路由算法在4×4的阵列结构中,几种典型情况下共享存储层数据访问的最小延迟周期数。
私有存储层中,可无冲突读写访问,读数据需要2个时钟周期,写数据只需1个时钟周期。共享存储层中,在读命中情况下,数据访问只需1个时钟周期,在写命中情况下,数据访问需要3个时钟周期。在读不命中和写不命中情况下,由于存在Cache一致性开销会导致访问延迟增大,但对本地存储器Bank的访问延迟要明显低于远程存储器Bank的访问延迟。
4.2 性能分析

图9 读数据访问延迟
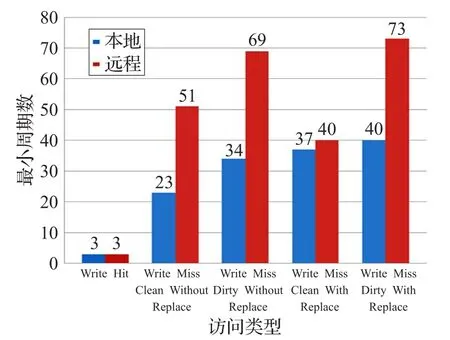
图10 写数据访问延迟
本文采用verilog硬件描述语言进行RTL级设计,设计并实现了一种多层次分布式存储结构。在文献[15]中使用SystemC硬件描述语言,设计并实现了一种Cache结构的仿真平台,并对两种Cache结构进行了仿真。本文结构与文献[15]访问延迟对比结果如表3所示。

表3 访问延迟对比结果
在读写不命中情况下,由于本文所设计的共享存储层中,16个L1级Cache与分布式存储器一一对应,本地Cache与PE距离较近,故与文献[15]相比,读写延迟较小;在读命中情况下,本文设计的结构与文献[15]的结构相同,故延迟相同;在写命中情况下,由于需要更新Cache中状态信息,延迟有所增加。
文献[16-17]针对视频和图像处理,设计了不同的存储结构,本文结构与文献[16-17]阵列处理器存储结构对比如表4所示。
在文献[16]的V-RCA结构中,采用寄存器文件对数据进行暂存,虽然有利于提升数据的访存速度,但面积消耗较大,数据交互时每次数据访存位宽为128位,通过集中式的数据分发与接收模块进行存储管理,无疑增加了数据访存的复杂度。文献[17]的PAAG模型中,由于没有寄存器文件,通过东西南北4个方向的邻接共享存储器进行数据交互和缓存,适用于流水化设计,但由于邻接共享存储器容量有限且冲突概率较大,无法满足HEVC算法对存储访存的要求。本文设计的多层次分布式存储结构中,对临时数据通过独立的私有存储器缓存,对需交互的数据通过多个Cache和分布式存储器构成的共享存储层进行PE间通信,满足了视频算法对访存的需求。

表4 阵列处理器存储结构对比结果
5 结束语
针对高清视频编解码算法需大量访存的要求,结合视频算法的访存特点,设计并实现了一种多层次分布式存储结构。通过Xilinx公司的FPGA开发板进行验证,实验结果表明,在无冲突情况下,16个PE同时发送读写访问,此时带宽达到峰值9.73 GB/s,在满足视频编码算法访存要求的同时,保证了结构的可扩展性。
[1]Schmitz J A,Gharzai M K,Balkir S,et al.A 1,000 frames/s vision chip using scalable pixel-neighborhood-level parallel processing[J].IEEE Journal of Solid-State Circuits,2017,52(2):556-568.
[2]Oh K,So J,Kim J.Low complexity implementation of slim HEVC encoder design[C]//International Conference on Systems,Signals and Image Processing,2016:1-4.
[3]Sullivan G J,Ohm J,Han W J,et al.Overview of the High Efficiency Video Coding(HEVC) standard[J].IEEE Transactions on Circuits&Systems for Video Technology,2012,22(12):1649-1668.
[4]Ohta M.Optical switching of many wavelength packets:A conservative approach for an energy efficient exascale interconnection network[C]//IEEE International Conference on High Performance Switching and Routing,2016:69-74.
[5]Wang K,Gu H,Yang Y,et al.Optical interconnection network for parallel access to multi-rank memory in future computing systems[J].Optics Express,2015,23(16):20480-20494.
[6]Wang Y,Gu H,Wang K,et al.Low-power low-latency optical network architecture for memory access communication[J].IEEE/OSA JournalofOpticalCommunications and Networking,2016,8(10):757-764.
[7]黄安文,高军,张民选.多核处理器片上存储系统研究[J].计算机工程,2010,36(4):4-6.
[8]于学球.可扩展64核处理器关键技术研究——片上网络、存储体系及LTE实现[D].上海:复旦大学,2014.
[9]相里博.基于VMM的多核处理器共享缓存的研究与验证[D].西安:西安电子科技大学,2016.
[10]Li J,Dai Z,Li W,et al.Study and implementation of cluster hierarchical memory system of multicore cryptographic processor[C]//IEEE International Conference on Asic,2015:1-4.
[11]Hwang K.Advanced computer architecture:parallelism,scalability,programmability=[M].[S.l.]:Mcgraw-Hill,1993.
[12]Girão G,Oliveira B C D,Soares R,et al.Cache coherency communication cost in a NoC-based MPSoC platform[C]//Symposium onIntegratedCircuitsandSystems Design,Copacabana,Rio De Janeiro,Brazil,September,2007:288-293.
[13]庞征斌.基于SMP的CC-NUMA类大规模系统中Cache一致性协议研究与实现[D].长沙:国防科学技术大学,2007.
[14]Patterson D A,Hennessy J L.Computer architecture:A quantitative approach[M]//Computer Architecture:A Quantitative Approach.[S.l.]:Morgan Kaufmann Publishers Inc,2007:93.
[15]Girão G,Oliveira B C D,Soares R,et al.Design and performance evaluation of a cache consistent noc-based mp-soc[C]//Iberchip Workshop,2007.
[16]王浩.基于视频压缩算法的硬件模板设计和可重构阵列架构研究[D].上海:上海交通大学,2011.
[17]Li T,Xiao L,Huang H,et al.PAAG:A polymorphic array architecture for graphics and image processing[C]//Fifth International Symposium on Parallel Architectures,Algorithms and Programming,2012:242-249.
