基于多特征的深度图像序列人体行为识别
2018-06-20宋相法
宋相法,姚 旭
(河南大学 计算机与信息工程学院,河南 开封 475004)
0 引 言
人体行为识别是计算机视觉领域中的重点研究问题之一,可广泛应用于视觉监控、人机交互、智能家居等领域,受到了研究人员的广泛关注[1-5]。在过去的数十年间,基于可见光摄像机获取的彩色图像序列人体行为识别研究取得了很大进展[1-2],但是它们对光照变化、纹理和颜色等因素比较敏感,当环境、光照条件发生变化时,识别精度会大幅度降低,因此,人体行为识别极具挑战性[2]。
最近,微软Kinect深度摄像机获取的深度图像在计算机视觉和机器人等领域取得了广泛应用[2]。相比可见光摄像机获取的彩色图像,深度摄相机获取的深度图像可以提供一个光照不变的具有深度几何结构的前景信息,同时具有纹理与颜色不变性等优势[2]。所以,研究人员开始对深度图像序列人体行为识别进行研究。例如,文献[6]采用行为图谱对行为进行建模,然后使用3维词袋提取姿态特征,最后利用隐马尔可夫模型识别人体行为;文献[7]提出了基于深度运动图和梯度方向直方图(histograms of oriented gradients,HOG)特征[8]的人体行为识别方法;文献[9]利用时空深度长方体相似性特征进行人体行为识别;文献[10]利用深度图像序列中的四维法向量特征进行人体行为识别;文献[11]提出了基于法向量描述子和超向量编码的深度图像序列人体行为识别方法;文献[12]提出了基于二值距离采样深度特征的人体行为识别方法;文献[13]提出了基于深度运动图和局部二值模式特征的人体行为识别方法;文献[14]提出了基于时空金字塔立方体匹配的人体行为识别方法;文献[15]提出了基于深度稠密时空兴趣点的人体动作识别方法。
对于深度图像序列,可以提取出各种不同类型的特征,所以在实际应用中,通过提取某种单一类型的特征很难全面地描述和刻画人体行为信息。采用多特征进行融合,可以增强信息互补性,提高人体行为识别结果。根据以上分析,文中提出了一种基于多特征的深度图像序列人体行为识别方法。该方法首先提取超法向量特征和基于深度运动图的梯度方向直方图特征,然后使用核极限学习机(kernel extreme learning machine,KEML)[16]作为分类器,采用对数意见汇集规则[17]融合方法得到人体行为识别结果。
1 特征提取
1.1 基于深度运动图的梯度方向直方图特征提取
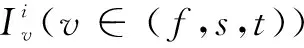
为了加快计算速度,没有设定阈值,而是直接将绝对值累加,如下:
(1)
其中,i代表帧索引。
通过式1分别在3个平面上得到深度运动图DMMf,DMMs和DMMt,然后去除深度运动图中处于边缘的全零行和全零列,最后得到人体行为的有效区域,如图1所示。
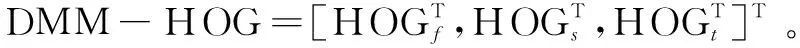
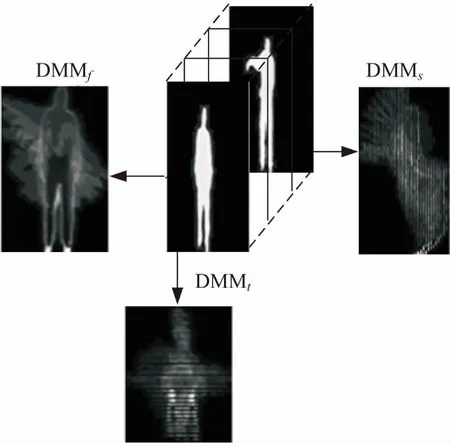
图1 DMM框架(golf swing行为)
1.2 超法向量特征提取
超法向量特征是由文献[11]提出的一种表示深度图像序列人体行为特征的方法,能够捕获局部运动信息。该方法首先计算出每一深度图像帧中每个像素点的法向量描述子,然后采用Fisher向量[18]一个简化的非概率方法对法向量描述子进行编码,从而获得超法向量特征。
深度图像序列可用下面的函数形式来表达:
R3→R1:z=Φ(x,y,t)
(2)
它构成了4维空间中的一个曲面F,该曲面上的点(x,y,t,z)满足式3:
F(x,y,t,z)=Φ(x,y,t)-z=0
(3)
其中,x,y,z为空间坐标;t为时间。
曲面F上的点F(x,y,t,z)处的法向量n表达为:
n=
(4)
点F(x,y,t,z)处的法向量描述子p由其时空邻域中的L个点的法向量级联而成,表达为:
(5)
令P={p1,p2,…,pN}∈RM是从深度图像序列中提取出的法向量描述子,D∈RM×K是视觉字典,则pi在D上的稀疏编码[19]的数学表达式为:
(6)
其中,dk为D中的视觉单词;αi∈RK为pi在D上的稀疏编码系数,α=[α1,α2,…,αN]∈RK×N;λ为正则参数,利用SPAMS工具箱[19]求解式6中的D和α。
对于每个单词dk,首先利用空间平均池化方法计算量化误差,如式7所示:
(7)
其中,uk(t)表示第k个单词在第t帧中的池化误差。
然后利用时间最大池化方法计算整卷中的量化误差[11],如式8所示:
(8)
其中,uk,i表示uk的第i个分量,uk是第k个单词在整卷中的表示。把K个向量uk级联起来得到最终向量U,如式9所示:
(9)
为了使所提取的特征能反映人体行为的时空属性,采用自适应时空金字塔方法[11]把图像序列划分成若干块,然后从每一块中提取特征向量Ui,最后把Ui级联起来得到深度图像序列的超法向量特征,如式10所示:
(10)
其中,V为图像序列被划分的块数。
2 多特征融合的核极限学习机行为识别
由于基于深度运动图的梯度方向直方图特征和超法向量特征分别从整体和局部两个角度来刻画和描述人体行为信息,具有良好的信息互补性;同时,核极限学习机有效地避免了极限学习机(extreme learning machine,EML)[20]固有的随机性和支持向量机模型求解的复杂性,而且具有更快的学习速度和更好的泛化性能[16],已初步用于人体行为识别[13,21]。因此,采用多特征融合的核极限学习机进行行为识别,可有效提高行为识别的性能。
2.1 核极限学习机
极限学习机是一种单隐层前馈神经网络模型,利用求解线性方程组的方法求出网络模型的输出权值,训练速度快,泛化能力强。核极限学习机通过引入核函数,解决了ELM算法随机初始化的问题,并且具有更强的鲁棒性。
(11)
其中,h(·)为一个非线性激励函数;wl∈Rn为连接第l个隐节点和输入节点之间的权重向量;βl为连接第l个隐节点到输出节点的输出权重;el为第l个隐节点的偏置。
式11共有n个方程,因此可以改写为:
Hβ=Y
(12)
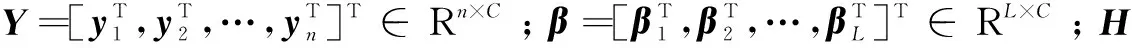
(13)
根据输入(x1,x2,…,xn)和H得出式12的最小平方解:
(14)
得到
(15)
其中,H†为矩阵H的Moore-Penrose逆矩阵,H†=HT(HHT)-1。
在HHT的对角线上的每个元素加一个正数1/ρ可以得到更好的稳定性,因此,ELM的输出表达式可直接表示为:
(16)
如果特征映射函数h(x)未知,则ELM的核矩阵可以定义为:
ΩELM=HHT:ΩELMj,k=h(xj)·h(xk)=K(xj,xk)
(17)
因此,KELM的输出表达式可表示为:
(18)
样本x的标记由具有最大值输出节点的索引值决定,即
(19)
这里f(x)c为f(x)=[f(x)1,f(x)2,…,f(x)C]。
2.2 融合策略
从深度图像序列中提取超法向量特征和深度运动图的梯度方向直方图特征分别作为核极限学习机分类器的输入,然后利用对数意见汇集规则融合两类特征的识别结果实现人体行为的识别。由于核极限学习机分类器的输出为输入所属类别的精度估计值,根据文献[22]可以将核极限学习机分类器的输出映射为类后验概率,用一个Sigmoid函数作为连接函数将核极限学习机分类器的输出f(x)映射到[0,1],以实现其后验概率输出。后验概率输出形式如下:
(20)
其中,参数A和B控制Sigmoid函数的形态,简单起见,令A=-1,B=0。
在对数意见汇集规则中,用于估计全体隶属度函数的后验概率pq(yc|x)形式如下:
(21)
或者
(22)
样本x所属类别标号y*如下式所示:
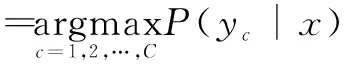
(23)
3 实验结果和分析
为了验证该方法的有效性,在深度图像序列人体行为数据集MSR Action3D (http://research.microsoft.com/en-us/um/people/zliu/ActionRecoRsrc/default.htm)上进行了实验。MSR Action3D数据集中共包含20种人体行为,例如horizontal arm wave、hammer、hand catch、forward punch等,每种行为由10个表演者重复表演3次,部分样例如图2所示。

图2 MSR Action3D数据库上的部分样例
为了保证比较的公平性,实验设置与文献[9-14]相同,数据集中的一半为训练集,另一半为测试集。采用文献[11]在提出超法向量特征时所建议的参数设置,其中字典D的大小k取值为100,正则参数λ的取值为0.15。
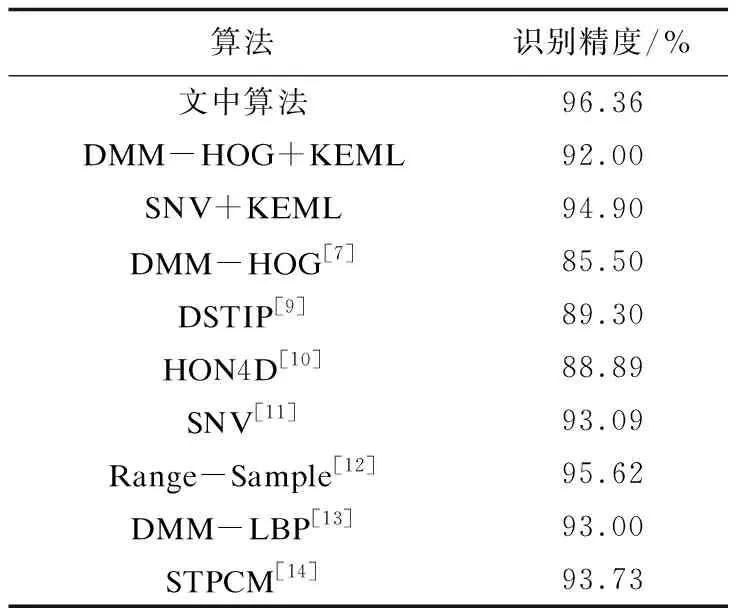
表1 实验结果对比
表1给出了文中算法的识别结果,同时也给出了单一DMM-HOG特征和单一SNV特征采用极限学习机分类器进行识别的结果,以及其他算法的识别结果。
由表1可知,识别精度由基于DMM-HOG特征的92.00%和基于SNV特征的94.90%提高到了文中算法的96.36%;文中算法的识别精度也高于其他7种算法,进一步证明了其有效性。
混淆矩阵可以揭示出数据的真实类别和预测类别之间的关系,常用来评价算法的性能。图3给出了文中算法在MSR Action3D数据集上的混淆矩阵。由图3可知,在20类行为中,识别精度达到100%的有16类;识别错误率主要发生在hand catch和high throw以及draw x 和hammer之间,是由于这些行为比较相似造成的。
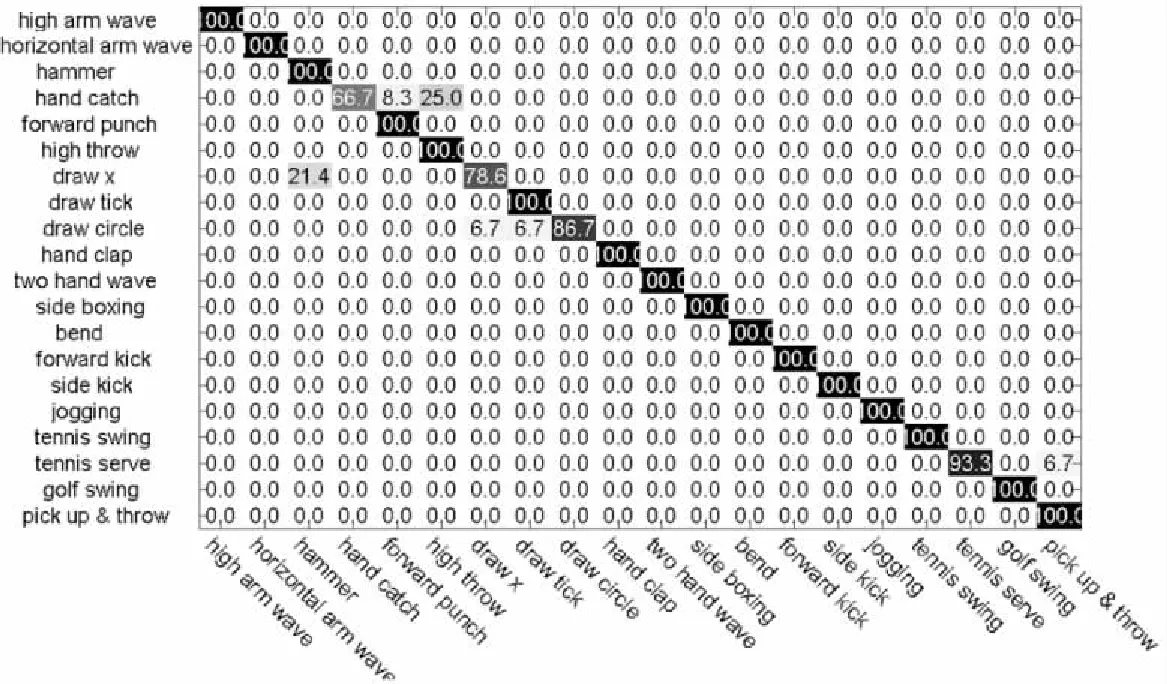
图3 文中算法在MSR Action3D数据库上的混淆矩阵
4 结束语
针对利用单特征对深度图像序列人体行为进行识别导致性能较低的问题,提出了基于超法向量特征和深度运动图HOG特征的深度图像序列人体行为识别方法。在MSR Action3D数据集上的实验结果证明了该方法的优越性。
参考文献:
[1] 胡 琼,秦 磊,黄庆明.基于视觉的人体动作识别综述[J].计算机学报,2013,36(12):2512-2524.
[2] HAN Jungong,SHAO Ling,XU Dong,et al.Enhanced computer vision with microsoft kinect sensor:a review[J].IEEE Transactions on Cybernetics,2013,43(5):1318-1334.
[3] 陈万军,张二虎.基于深度信息的人体动作识别研究综述[J].西安理工大学学报,2015,31(3):253-264.
[4] 黄菲菲,曹江涛,姬晓飞.基于多通道信息融合的双人交互动作识别算法[J].计算机技术与发展,2016,26(3):58-62.
[5] 单言虎,张 彰,黄凯奇.人的视觉行为识别研究回顾、现状及展望[J].计算机研究与发展,2016,53(1):93-112.
[6] LI Wanqing,ZHANG Zhengyou,LIU Zicheng.Action recognition based on a bag of 3D points[C]//IEEE computer society conference on computer vision and pattern recognition workshops.San Francisco,CA,USA:IEEE,2010:9-14.
[7] YANG Xiaodong,ZHANG Chenyang,TIAN Yingli.Recognizing actions using depth motion maps based histograms of oriented gradients[C]//Proceedings of ACM conference on multimedia.Nara,Japan:ACM,2012:1057-1060.
[8] DALAL N,TRIGGS B.Histograms of oriented gradients for human detection[C]//Proceedings of IEEE conference on computer vision and pattern recognition.Piscataway,NJ,USA:IEEE,2005:886-893.
[9] LU Xia,AGGARWAL J K.Spatio-temporal depth cuboid similarity feature for action recognition using depth camera[C]//Proceedings of IEEE conference on computer vision and pattern recognition.Piscataway,NJ,USA:IEEE,2013:2834-2841.
[10] OREIFEJ O, LIU Zicheng. HON4D:histogram of oriented 4D normals for action recognition from depth sequences[C]//Proceedings of IEEE conference on computer vision and pattern recognition.Piscataway,NJ,USA:IEEE,2013:716-723.
[11] YANG Xiaodong,TIAN Yingli.Super normal vector for action recognition using depth sequences[C]//Proceedings of IEEE conference on computer vision and pattern recognition.Columbus,OH,USA:IEEE,2014:804-811.
[12] LU Cewu, JIA Jiaya, TANG Chi-Keung.Range sample depth feature for action recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.Piscataway,NJ,USA:IEEE,2014:772-779.
[13] CHEN Chen,JAFARI R,KEHTARNAVAZ N.Action recognition from depth sequences using depth motion maps-based local binary patterns[C]//Proceedings of the IEEE winter conference on applications of computer vision.Waikoloa,HI,USA:IEEE,2015:1092-1099.
[14] LIANG Bin,ZHENG Lihong.Spatio-temporal pyramid cuboid matching for action recognition using depth maps[C]//Proceedings of the IEEE conference on image processing.Quebec City,QC,Canada:IEEE,2015:2070-2074.
[15] 宋健明,张 桦,高 赞,等.基于深度稠密时空兴趣点的人体动作描述算法[J].模式识别与人工智能,2015,28(10):939-945.
[16] HUANG Guangbin,ZHOU Hongming,DING Xiaojian,et al.Extreme learning machine for regression and multiclass classification[J].IEEE Transactions on Systems,Man and Cybernetics,Part B,2012,42(2):513-529.
[17] BENEDIKTSSON J A,SVEINSSON J R.Multisource remote sensing data classification based on consensus and pruning[J].IEEE Transactions on Geoscience and Remote Sensing,2003,41(4):932-936.
[19] MAIRAL J,BACH F,PONCE J,et al.Online learning for matrix factorization and sparse coding[J].Journal of Machine Learning Research,2010,11:19-60.
[20] HUANG Guangbin,ZHU Qinyu,SIEW C K.Extreme learning machine:theory and applications[J].Neurocomputing,2006,70(1-3):489-501.
[21] IOSIFIDIS A, TEFAS A, PITAS I. Regularized extreme learning machine for multi-view semi-supervised action recognition[J].Neurocomputing,2014,145:250-262.
[22] PLATT J C.Probabilistic outputs for support vector machines and comparison to regularized likelihood methods[C]//Proceedings of advances in large margin classifiers.Cambridge,MA,USA:MIT Press,1999:61-74.
