中亚语言自然语言处理综述
2018-06-14吐尔根依布拉音卡哈尔江阿比的热西提艾山吾买尔买合木提买买提
吐尔根·依布拉音,卡哈尔江·阿比的热西提,艾山·吾买尔,买合木提·买买提
(1. 新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046;2. 新疆大学 新疆多语种信息技术实验室, 新疆 乌鲁木齐 830046)
1 中亚语言概述
随着“丝绸之路经济带”战略构想的逐步实施,我国与沿线各国的经济贸易、互联互通、区域合作、金融合作、文化交流与合作等更加密切,如何利用信息技术和新媒体手段,通过“信息丝绸之路”的建设,进一步深化我国与“丝绸之路经济带”沿线国家的文化与信息交流,促进区域合作、实现共同发展显得十分必要。目前,我国对周边中亚国家和地区在多语种信息处理和网络内容安全方面都存在着重大需求。因此,在中亚语言自然语言处理方面展开研究,具有重要意义。
本文中的中亚语言是指“丝绸之路经济带”沿线的中亚国家和地区所操语言,属于阿尔泰语系突厥语族,其中包括我国维吾尔语、哈萨克语、柯尔克孜语和国外的哈萨克语(跨境)、吉尔吉斯语(跨境)、乌兹别克语、土耳其语、土库曼语、阿塞拜疆语、鞑靼语和巴什基尔语等,覆盖 1.82 亿人口,是我国“丝绸之路经济带”战略中具有重要地位的语言。其特点为语言现象互相接近,都属于黏着性语言。具体来说,在语音方面,元音和谐;在词法方面,词干可以加多种附加成分;在句法方面,主语和谓语人称词缀要保持一致,因此主语可以省略,句型结构为主语—宾语—谓语。
开展中亚语言自然语言处理工作,对“丝绸之路经济带”沿线国家及周边地区多语言智能信息处理的关键问题提供解决方案和技术支撑,以“一带一路,语言铺路”来解决“丝绸之路经济带”语言障碍问题,达到深化与沿线国家和周边地区的科技文化信息交流、促进区域合作及实现共同发展的目的。
2 中亚自然语言处理现状
目前,中亚语言中土耳其语在词法分析、句法分析、命名实体识别、机器翻译等方面均有较大进展。其中,维吾尔语、哈萨克语、鞑靼语在自然语言处理方面也进展较快,其他语种则尚处于初始研究阶段。下面我们分别描述中亚语言在词法分析、句法分析、命名实体识别、机器翻译等方面的进展,以及针对黏着语的通用语言处理技术的进展。
2.1 词法分析
2.1.1 土耳其语
土耳其语在词法分析方面的研究表现较为突出。Oflazer[1]在土耳其毕尔坎特大学(Bilkent University)时,介绍了土耳其语形态的两层描述。他对于黏着性词的结构,利用2.3万土耳其语词干及22个两层语音规则,分别针对动词,名词性词语的词形变化表构建了有限状态自动机。语音和形态方面的特殊情况都被考虑到该描述中,并通过PC-KIMMO 环境实现了基于两层描述的形态分析器。该工作为土耳其语自然语言处理基础研究做出了较大的贡献,此后的土耳其语词法分析基本上都是在该工作的基础上进行。但该方法存在一些缺点: ①为适合少数形态现象,需要修改规则,从而导致有限状态自动机的状态数剧增; ②该方法需要先确定词干,因此搜索词干过程提高了算法的时间复杂度。
随后Oflazer[2]进一步提出基于容错机制的有限状态自动机识别算法,并将该算法用到词法分析和校对任务上。该算法使得有限状态识别器能够识别轻度偏离基本正规集合的字符串。该算法的优点是它可以用给定的有限状态自动机,且适用于模式众多、匹配的字符串较短的场景。该算法与具体语言无关,且较适合于形态复杂语言。该方法只需给出待分析语言包含各种形态变化的单词表或描述该语言的整个形态现象的单个形态转换器,就可以将该方法用到该语言的形态分析和校对任务上。作者将该算法用到土耳其语及欧洲的芬兰语等10种语言的形态分析任务上,得到了较好的结果。但该算法本质上是基于规则的,即依赖于描述待分析语言的有限状态自动机或形态变化表。因此对不符合规则的未登录词,特别是对外来词无法进行处理。
伊斯坦布尔技术大学的Eryigit和Adali[3]针对之前文献[1]中存在的第二个问题,采用了词缀剥离方法。在该方法中他们利用土耳其语的词缀链接规则,将词缀按照功能进行分类,并对每一个类别构建了描述该类别中的词缀链接规则的有限状态自动机,并进一步将每一种词缀类的有限状态自动机进行结合,从而构建了全局有限状态自动机。该自动机从右到左对单词进行分析,不需要先确定词干,因此也不需要词干词典。与Oflazer的方法相比,Eryigit等提出的方法速度更快,速度相对快,未登录词处理能力更强,且不需词干库,只需要词缀链接规律,适合于对速度的要求高、对词法分析准确率要求不高的应用场景。该大学的Hakkani-Tür等人[4]为了解决基于规则的土耳其语词法歧义消除方法中需要人工方式编写规则、优化困难等问题,采用了三元模型的统计方法进行词法歧义消除。然而统计方法面临的困难是黏着语形态句法标记集比英语等其他非黏着语大很多,因而导致数据稀疏问题。因此,针对该问题他们将形态句法标记划分为多个屈折词素组(inflectional group),每一个屈折词素组包括每一个派生形式的屈折特征,从而降低了需要处理的标记集规模。利用该方法构建的四种统计模型都比基线方法好,其中忽略单词之内的局部形态句法特征的简单模型表现出最好的消歧效果。该方法在一定程度上缓解了数据稀疏问题。在词法分析任务上准确率为93.95%,在词法分析任务中仅考虑词性标注时,准确率为95.07%,有较大的提升空间。
美国俄亥俄州立大学的Kutlu和土耳其哈斯特帕大学(Hacettepe University)的Cicekli[9]进一步针对土耳其语数据稀疏问题,提出了混合模型,即他们将统计方法、基于规则方法进行结合,提高了土耳其语形态消歧系统的准确率。他们的混合方法由串联的五个模块组成;具体包括: ①根据单词标记概率表选择单词的最有可能的标记; ②通过有监督标记器进行消歧,该消歧器由人工构建的342条歧义消歧规则组成; ③根据后缀标记概率表选择后缀的最有可能的标记; ④通过他们训练的Brill标注器进一步进行消歧; ⑤后退启发式方式进一步进行消歧。他们最终实验结果表明当仅进行词性标注时准确率达到了96.9%,同时考虑词性标注和最终的形态分析结果时准确率为94.1%。
华为土耳其研究和发展中心(Huawei Turkey Research and Development Center)的Yildiz等人[10]提出了能够学习形态丰富语言词表示的深度学习框架。为了解决形态复杂语言的数据稀疏问题,他们通过Oflazer的方法进行词法分析,将单词表层形式分解为词根和形态特征集。在训练过程中先单独学习词根和形态特征的嵌入(embedding),单词表层形式的嵌入则通过词根和形态特征嵌入的连接得到,通过这种方式缓解了形态复杂语言面临的数据稀疏问题。换句话说,该框架第一层利用的是词根嵌入、形态特征嵌入构建词(表层形式)的嵌入。第二层将词表示作为输入合并上下文信息。最后一层是softmax层,该层将第二层的输出作为输入,输出待分类分数的结果。他们利用Viterbi算法从softmax出来的结果中找到了最优的序列。他们将该框架用到土耳其语、法语和英语的歧义消除任务上,并在土耳其语词法歧义消除任务上得到了最好的结果。为了提高消歧系统的准确率,他们收集并建立了土耳其语迄今为止最大的语料库,该语料库包括11亿的土耳其语单词。用该框架训练消歧系统以后,通过该系统对语料库进行消歧,并提取了词根。然后利用skip-gram模型得到了词根表示。并用该词根表示重新训练消歧系统。论文中没有描述利用该语料之前的消歧结果。因此不能确定大规模语料为提高歧义消歧的贡献程度。
2.1.2 哈萨克语
近年来,哈萨克斯坦哈萨克语词法分析方面也取得了一定的进展。土耳其法提赫大学(Fatih University)的Zafer,Tilki,Atakan Kurt以及伊斯坦布尔大学(Istanbul University)的Mehmet Kara等人围绕着Dilmaç机器翻译框架开发了哈萨克语两层形态分析器[11]。哈萨克斯坦列·尼·古米列夫欧亚国立大学(L.N. Gumilyov Eurasian National University)的Razakhova 、Yergesh等人在哈萨克语句法形式化*Formalization of syntactic rules of the Kazakh language, http://www.enu.kz/repository/repository2012/pdf/4.pdf(2017,1,10)、哈萨克语语义超图表示[12]、形容词的形式化模型构建[13]等方面做了一定研究。
哈萨克斯坦阿里-法拉比国立民族大学(al-Farabi Kazakh National University)的Tukeyev,Zhumanov以哈萨克语机器翻译[14]为目标做了哈萨克语链接语法方面的研究[15],并探索了适合俄语和哈萨克语基于规则的形态传感器[16]。为开发英语—哈萨克语机器翻译系统,该大学的Kuandykova等人研究如何构建100万词规模的英语—哈萨克语语料库[17]。该大学的D Rakhimova等人开始研究哈萨克语—俄语机器翻译[18]。该大学Bekbulatov等人研究形态分析对哈萨克语—英语机器翻译系统的影响[19]。该大学的Kairakbay等人研究哈萨克语形态分析[20],并将其应用到哈萨克文识别(OCR),研发了基于Web并行计算的哈萨克文识别系统[21-22]。
土耳其哈斯特帕大学的Kessikbayeva等人以Xerox自动状态机为工具开发了基于规则的哈萨克语词法分析器[23],并进一步研究了歧义消除方法[24]。
纳扎尔巴耶夫大学(Nazarbayev University)的Makhambetov,Makazhanov 等人对哈萨克语标注语料库的构建[25]、自动校对[26]、自动词性标注[27-28]、歧义消除[29]等方面进行研究。该大学的Yessenbayev等人对哈萨克语语音识别也进行了初步研究[30-32]。
新疆大学古丽拉等人通过有限状态自动机[33]、HMM 方法[34-35]对哈萨克语开展了较为深入的研究。
2.1.3 维吾尔语
自20世纪90年代中期开始,学者们开始研究维吾尔语语言信息处理技术[36]。新疆师范大学玉素甫等人对词类标记的确定[37]、网络用词的切分[38]等多方面进行研究。新疆大学吐尔根等人分别用基于有限自动状态机的算法[39],基于最大熵和有限状态自动机相结合的算法[40],基于CRF和有限状态自动机相结合的算法[41],基于有向图模型的算法[42-43],以及基于感知器算法[44]多种方法研究了维吾尔语词干提取和词性标注。新疆大学艾斯卡尔等人用基于词性和上下文的方法[45]、基于 CRF[46]的算法、无监督和规则相结合的方法[47]等多种方法研究了维吾尔语词干提取方法。中国科学院新疆理化所的Yung等人也用基于字符标注的CRF方法[48]对维吾尔语词语切分进行了初步研究。中央民族大学王海波等人也对维吾尔语词性标注等方面做了研究[49]。中国科学院计算所张海波提出了基于联合音变还原和形态切的方法对维吾尔语进行了词干提取[50]。
通过以上的代表性工作比较(表1)可以看出,土耳其语词法分析主要针对土耳其语的形态复杂性特点,提出基于规则、统计及融合方法。最近也通过深度学习方法来做词法分析和词法歧义消除。有些方法通用性比较强,不仅可以用到相似的中亚语言的词法分析任务上,还可以用到芬兰语等黏着语言的词法分析任务上。维吾尔语、哈萨克语等其他语言也参考土耳其语、汉语、英语取得了相对较好的进展。但是对于以上的词法分析和歧义消除研究,各研究机构都利用自己的训练和测试语料进行测试,测试结果准确率大致为85%~98%。由于没有统一的评价和测试标准,同时训练语料也由各研究机构各自收集和标注,因此难以客观地比较各种算法之间性能差距。

表1 词法分析工作比较
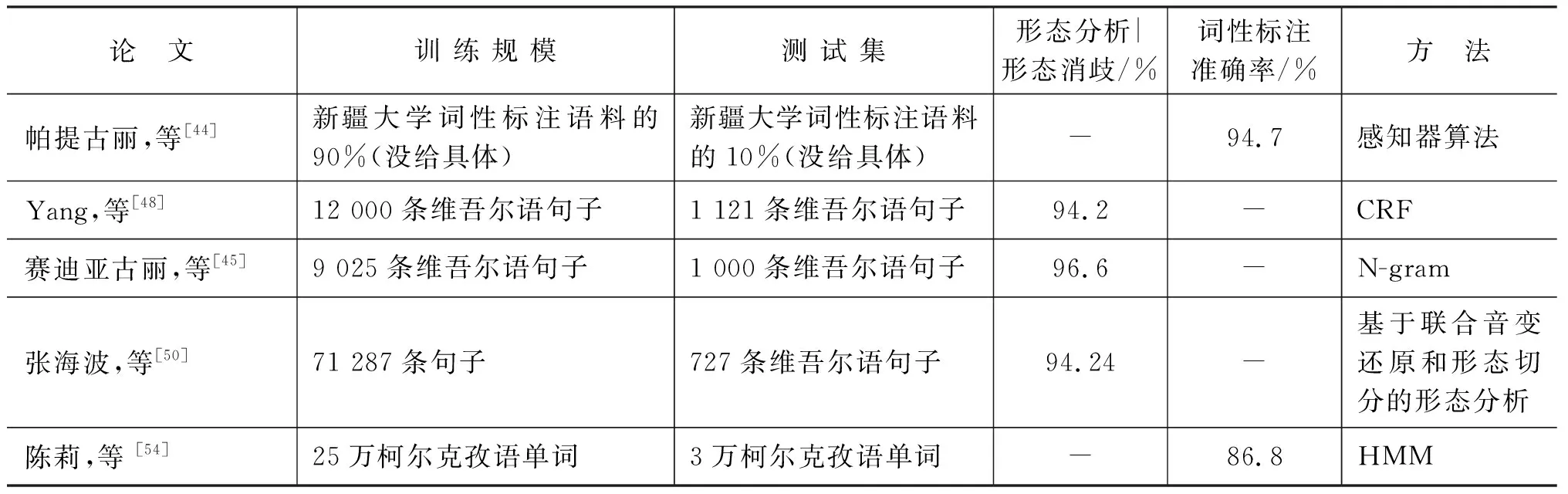
续表
2.2 句法分析

以上的句法分析工作与形态分析是串行进行,即先独立地进行形态分析,并通过自动或人工的方式进行歧义消除,各模块不能互相交互。鉴于以上工作的不足,德国斯图加特大学的Seeker[56]等人提出了基于图模型的联合形态切分和句法分析的格句法分析方法。该方法将词语切分、形态分析及依存句法分析等问题划分为几个小问题,并通过对偶分解方法找到共同解决方案。他们将该方法用到土耳其语和希伯来语树库,结果超出前人方法。
在句法分析方面,新疆大学探索了构建维吾尔语句法树库[57]、语法信息词典[58],制定了维吾尔语依存树库标注体系[59],并利用标注工具进行了依存树的标注[60]。目前部分标注句子[61]放到通用依存句法树库项目中*http://universaldependencies.org/#ug。
通过以上工作可以看出,虽然对于土耳其语的句法分析有一定的基础,但相比英语、汉语等语言还是比较滞后,维吾尔语和哈萨克语句法分析刚起步,处于语料库构建阶段。虽然CoNLL- X shared task在2006—2007年的依存树分析任务中增加土耳其语依存分析任务,但土耳其语句法分析还是被认为比较难。比如Buchholz等人提到[62]“ 最难的数据集显然是土耳其语。该数据集是相当小的,与小的数据集阿拉伯语和斯洛文尼亚语相比更小,它涵盖了八种类型,从而在测试集中导致高百分比的新的形态和词根。”
2.3 命名实体识别
土耳其中东技术大学(Middle East Technical University)的Yavuz等人提出了结合贝叶斯方法和基于规则的混合方法。他们在土耳其语树库语料上对50篇新闻进行标注、测试。由于以往的标注语料库没有公开因此无法与其他研究机构进行对比。他们在测试中对前人的工作用自己的测试集进行了比较,其测试结果表明混合策略比单独使用贝叶斯方法好,混合方法的F值为91.44%[65]。
土耳其科学技术研究理事会(TÜBiTAK ,Scientific and Technological Research Council of Turkey)能源研究所(TÜBiTAK Energy Institute)的Küçük等人[66]针对土耳其语命名实体资源匮乏问题,提出了自动资源编篆方法。他们以维基百科中的文章标题为原始语料,先随机抽取部分语料,进行命名实体人工标注,构建训练语料库。将该标注语料库及命名实体识别规则作为依赖数据和规则,用K邻近算法,对未标注语料进行自动编篆。通过该方法得到了为91.25%准确率的编篆语料库。他们将该语料库作为原先的基于规则的方法的依赖库,进行命名实体抽取,结果比原先的基于规则的方法好,从而说明了该方法的优越性。因为他们用维基百科的多领域数据,因此该方法在不同领域的效果比前人的方法好。但将自动编篆资源再进行人工修正以后,效果进一步提高,因此该方法还是在比较大的程度上依赖于人工标注。该理事会的信息学和信息安全研究中心(TÜBiTAK BiLGEM)的Demir 等人[67]针对形态复杂语言的语言处理技术主要依赖于与语言相关的特征,提出了基于半监督神经网络的命名实体识别方法。该方法与具体语言无关且利用词向量提高了土耳其语命名实体识别质量。
维吾尔语命名实体识别主要集中在人名上,其中有中科院与新疆大学共同合作研究基于词典等传统方法的基础上运用语言模型的维吾尔语中汉族人名识别方法[68]、新疆大学的基于CRF的维吾尔语人名识别方法[69]、基于统计和规则的维吾尔人名识别[70]、基于模糊匹配与音字转换的维吾尔语人名识别方法[71],也有基于规则的机构名[72]、地名[73]识别方面的研究。
2.4 机器翻译
卡耐基梅隆大学卡塔尔分校的Oflazer介绍了土耳其语在自然语言处理方面面临的挑战并进一步介绍了代表土耳其语自然语言处理方面的最好的词法分析、歧义消除、依存分析器等工具、以及树库、篇章语料库、土耳其语 WordNet和其他的语言资源[81]。荷兰格罗宁根大学的Cöltekin介绍了土耳其语形态切分、词干提取、未登录词识别、字—音转换、连字、形态歧义方面的开源工具[82]。
新疆大学吐尔根等人构建了面向政府文献的 20 万汉维句子对齐语料库,近 15 万条汉维语短语搭配的汉维语短语库[36];中国科学院新疆理化技术研究所周俊林等人开展汉语、维吾尔语之间机器翻译方法的研究[83],研究了机器翻译中维吾尔语形态的处理[84]、调序方法[85]、预处理方法[86],翻译中的未登录词处理[87]等方法。中国科学院计算所也在人名翻译[68]、以维吾尔语为例的黏着语机器翻译方法[88]等方面进行了深入探索。新疆大学在基于实例的机器翻译方法[89]、维汉机器语言模型构建[90]、词尾对翻译的影响[91]等方面进行了研究。
中文信息学会主办的全国机器翻译评测(CWMT)2011年增加从维吾尔语、哈萨克语、柯尔克孜语到汉语的机器翻译评测项目(CWMT2011)。CWMT2013、CWMT2015一直保留从维吾尔语到汉语的机器翻译评测项目,对我国少数民族语言机器翻译起了推动作用。
2.5 其他中亚语言
美国印第安纳大学的Washington等人对吉尔吉斯语形态传感器进行了研究[92],并利用语言的相似性和俄罗斯喀山联邦大学(Kazan Federal University)的Salimzyanov等人合作通过相同的方法对三种属于钦察语言(Kypchak)分支的鞑靼语、哈萨克语及库梅克语(Kumyk language)的形态传感器进行了研究(morphological transducer)[93]。他们先构造了鞑靼语—巴什基尔语(俄罗斯的巴什科尔托斯坦共和国官方语言)机器翻译原型系统[94],进一步研制了开源的基于规则的哈萨克语—鞑靼语机器翻译系统[95]。
日本名古屋大学的 Ogawa 等人利用日语—维吾尔语词典通过音译的方式扩展了日语—乌兹别克语词典[96]。京都大学的Wushouer等人以汉语作为中间语分别用启发式方法[97]、以语义距离为优化问题的约束方法[98]从汉语—哈萨克语、汉语—维吾尔语、汉语—柯尔克孜语词典中导出了维吾尔语—哈萨克语、维吾尔语—柯尔克孜语词典。
俄罗斯科学院语言学研究所(Institute of Lingustics Russian Academy of Science)的Sheymovich等人构建了形态标注的哈卡斯语(哈卡斯共和国官方语言)语料库、为哈卡斯语的形态分析器打下了基础[99]。俄罗斯鞑靼斯坦科学院(Tatarstan Academy of Sciences)的Galieva、Gatiatullin等人利用鞑靼语和俄语解释词典、鞑靼—俄语双语词典和俄语国家语料库等资源开始研究构建鞑靼语言语义标注语料库方法[100]。该科学院的Suleymanov等人研究鞑靼语和哈萨克语的共同模型[101]。
新疆大学木合亚提、古丽拉等人在柯尔克孜语语料库建设[54,102]和词性标注方面进行了初步研究。
2.6 形态复杂语言分析通用算法方面
国际上,2005-2010 年针对形态比较复杂语言举行了MorphoChallenge 评测*http://research.ics.aalto.fi/events/morphochallenge/。该评测由欧盟 PASCAL 项目组织。评测后期总共包括的语言分别为芬兰语、土耳其语、德语以及阿拉伯语。评测任务包括形态分析如何影响词语的切分、语音识别、信息抽取、机器翻译的性能。虽然通过该评测形态分析算法研究得到了一定的进展,如有了30 多种形态分析算法[103]。但是什么样的算法是最好的,如何利用上下文信息、如何利用,监督学习算法等问题留到以后再研究。此后研究人员利用该评测中的数据集进行了进一步研究。例如,捷克马萨里克大学的 Baisa等人[104]从网上自动爬取了六种中亚语言语料,并进行了无监督的词法分析。在 MorphoChallenge 2005 上的土耳其语数据集上得到了较好的结果。美国麻省理工学院的Narasimhan等人提出了基于无监督的形态链方法,该方法在Morpho Challenge 2010 数据集上得到了最好的结果[105]。
此外,捷克查理大学的Straková等人研究并实现了作为比较典型的屈折语捷克语的词法分析、词形还原以及命名实体识别工具,并讨论了屈折语通用模型构建的可能性[106],为中亚语言通用模型构建提供了参考。 卡耐基梅隆大学的Faruqui 等人提出了基于神经网络的屈折变化生成模型,他们的模型对于芬兰语的元音和谐生成得到了最好的结果[107],并进一步通过基于图的半监督方法对于 11 种语言生成了形态—句法词汇(Morpho-Syntactic Lexicon)[108]。
加州大学伯克利分校的Durrett等人用有监督的方法将 Wiktionary*http://en.wiktionary.org上的屈折表作为训练语料构造了生成词汇的形态变化模型[109]。瑞典哥德堡大学(University of Gothenburg)的Ahlberg 等人[110]提出了最长共同子序列(LCS)方式,用半监督方法构造了词汇的形态变化模型并在此基础上采用判别分类模型得到了较好的结果[111]。加拿大阿尔伯塔大学(University of Alberta)的Nicolai 等人对屈折表生成的规则进行重新排序得到了较好的结果[112]。
3 面临的问题
从以上的国内外中亚自然语言处理研究进展可以看出,国内以维吾尔语、哈萨克语及柯尔克孜语为主在自然语言处理的各领域进行了比较广泛的研究。在国外,近年来美国、俄罗斯、土耳其、哈萨克斯坦等国在中亚诸语种的信息处理技术方面开展相关研究,取得了积极进展。土耳其自然语言处理各领域取得了较好的进展;哈萨克语在词法、句法分析、共性语言模型的构建方面也取得了一定的成果;吉尔吉斯语、鞑靼语小语种在基本的自然语言处理技术上取得了一定进步。但是相对于国际大语种的研究,差距仍然巨大。在科学研究方面,我的认为中亚语言资源的开放、Wiktionary等开放数据平台上的中亚语言稀缺,以及中亚语言研究机构的前沿技术应用的欠缺,可能是导致该差距的主要因素。
在资源开放方面,据我们文献调研,除了土耳其语有公开的词语切分语料、依存树库、平行语料,德国莱比锡大学(Universität Leipzig)的通过爬虫自动构建的200多种语言的网络爬虫无标注单语料库*http://corpora.uni-leipzig.de,土耳其语的校对*http://zemberek.googlecode.com/、词法分析工具、基于规则的哈萨克语—鞑靼语机器翻译系统,以及我国CWMT中的从汉语到维吾尔语、哈萨克语、柯尔克孜语的平行语料以外,其他领域和语言几乎很少有公开的加工语料和工具供给研究人员进行进一步研究。因此中亚语言资源及开源的语言处理工具还是很匮乏的,这在一定程度上限制了中亚语言自然语言处理技术的广泛研究。
非中亚语言国家和地区本土的研究机构和研究者针对形态分析进行研究,尝试提出与语言无关的算法、模型或方法。但这些研究主要用 MorphoChallenge 和 Wiktionary的数据进行研究。虽然 MorphoChallenge的数据比较可靠权威,但是仅覆盖了四、五种语言。对于中亚语言来说,该评测只包含土耳其语。然而由志愿者来维护的Wiktionary上的相关的语言种类丰富,超过3 000种,但只有43种语言的词条超过 1 万(包括土耳其语),其他语言均小于 1 万,且其他大部分语言的词条都是几百个、几十个,增长速度也很缓慢。2016 年 1 月 12 日的统计结果中,各中亚语言的词条数分别为: 土库曼语(609)、乌兹别克语(515)、哈萨克 语(464)、维吾尔语(460)、吉尔吉斯语(353)。2017 年 2 月 1 日的统计结果中: 土库曼语(554)、乌兹别克语(477)、哈萨克语(496)、维吾尔语(501)、吉尔吉斯语(368)*https://en.wiktionary.org/wiki/Wiktionary: Statistics。因此开放数据平台上中亚语言资源的稀缺阻碍了中亚语言自然语言处理的发展。
中亚国家及我国少数民族区域研究机构的研究方法中,主要采用相对过时的技术和方法,前沿理论、技术和方法的应用力度不够。这种现状也可能是中亚语言自然语言处理技术和其他英语等其他语言相差比较大的原因之一。
4 未来研究方向
对于在本文第一部分提到中亚语言自身的语言复杂特点,适用于大语种的研究方法并不能完全适用于这些语言的研究,因此针对中亚诸语言的特点,在基本理论和计算模型上进行创新性研究,探讨适合中亚诸语言计算的模型是今后研究的思路。
针对资源稀缺和前沿技术应用欠缺的问题,在中亚语言资源方面具有优势的研究机构和前沿技术研究方面具有优势的单位相互合作,发挥各自优势,在资源和技术的充分挖掘下,可以将资源和工具开放,吸引更多的研究机构研究中亚语言处理,推动中亚自然语言处理发展。
对于我国中亚语言研究而言,虽然目前我国维吾尔语、哈萨克语的资源建设已经有了较好的基础,但是其他中亚诸多语言的资源建设和处理方面在国内还没有研究成果。因此,可以充分利用中亚诸多语言相似性,通过跨语言映射的方式为目标语言获取可用的标注信息,从而建立中亚语言知识库。并将维吾尔语、哈萨克语等少数民族语言和汉语之间的机器翻译成果应用到中亚语言,并进一步在接近语言之间的机器翻译和非接近语言之间的机器翻译理论和方法上进行创新,推动我国在中亚地区的影响力。
5 结束语
本文总结了到目前为止中亚自然语言处理在国内外的研究现状,分析了当前所面临的问题与困难,并针对问题的解决和未来的研究提出了建设性的建议。
[1] Oflazer K. Two-level description of Turkish morphology [J]. Literary and Linguistic Computing, 1994, 9(2): 137-148.
[2] Oflazer K. Error-tolerant finite-state recognition with applications to morphological analysis and spelling correction [J]. Computational Linguistics, 1996, 22(1): 73-89.
[3] Eryigit G, Adali E. An affix stripping morphological analyzer for Turkish[C]//Proceedings of the IASTED international conference on artificial intelligence and applications, Vols 1and 2, Innsbruck, Austria: 2004, 299-304.
[4] Hakkani-Tür D Z, Oflazer K, Tür G. Statistical morphological disambiguation for agglutinative languages [J]. Computers and the Humanities, 2002, 36(4): 381-410.
[5] Sak H, Gungor T, Saraclar M. Morphological disambiguation of Turkish text with perceptron algorithm [M]. Computational linguistics and intelligent text processing, Gelbukh A, 2007: 107-118.
[6] Sak H, Guengor T, Saraclar M. Turkish language resources: morphological parser, morphological disambiguator and web corpus[C]//Proceedings of the advances in natural language processing,2008. 417-427.
[7] Sak H, Güngör T, Saraçlar M. Resources for Turkish morphological processing [J]. Language Resources and Evaluation, 2011, 45(2): 249-261.
[8] Dincer T, Karaoglan B, Kisla T. a suffix based part-of-speech tagger for Turkish[C]//Proceedings of the fifth international conference on information technology: New generations, USA: IEEE Computer Society, 2008: 680-685.
[9] Kutlu M, Cicekli I. A hybrid morphological disambiguation system for Turkish[C]//Proceedings of the IJCNLP,2013: 1230-1236.
[10] Yildiz E, Tirkaz C, Sahin H B, et al. A morphology-aware network for Morphological Disambiguation[C]//Proceedings of the 13th AAAI conference on artificial Intelligence, USA, 2016: 2863-2869.
[11] Zafer H R, Tilki B, Kurt A, et al. Two-level description of Kazakh morphology [C]//Proceedings of 1st International Conference on Foreign Language Teaching and Applied Linguistics. Sarajevo,2011: 560-564.
[12] Yergesh B, Mukanova A, Sharipbay A, et al. Semantic hyper-graph based representation of nouns in the Kazakh language [J]. Computación y Sistemas, 2014, 18(3): 627-635.
[13] Mukanova A, Yergesh B, Sharipbay A, et al. Formal model of adjective in the Kazakh language [J]. TÜRKiYE BiLiiM VAKFI BiLGiSAYAR BiLiMLERi ve MÜDERGiSi, 2015, 8(8): 57-61.
[14] Tukeyev U A, Zhumanov Z M, Rakhimova D R. Models and algorithms of translation of the Kazakh language sentences into English language with use of link grammar and the statistical approach[C]//Proceedings of the IV Congress of the Turkic World Mathematical Society, Baku,2011.
[15] Zhumanov Z M. Understanding of Kazakh language with using of link grammar[C]//Proceedings of the 2012 Joint 6th International Conference on Soft Computing and Intelligent Systems and 13th International Symposium on Advanced Intelligent Systems(SCIS-ISIS 2012),IEEE, 2012: 1085-1088.
[16] Tukeyev U A, Miosz M, Zhumanov Z M. Finite-state transducers with multivalued mappings for processing of rich inflectional languages [M].New trends in intelligent information and database systems. Springer International Publishing, Barbucha D, Nguyen N T, Batubara J. 2015: 271-280.
[17] Kuandykova A, Kartbayev A, Kaldybekov T. English-Kazakh parallel corpus for statistical machine translation [J]. International Journal on Natural Language Computing(IJNLC), 2014, 3(3): 65-72.
[18] Rakhimova D, Abakan M. Lexical selection in machine translation of Russian-to-Kazakh [J]. TÜRKiYE BiLiiM VAKFI BiLGiSAYAR BiLiMLERi ve MÜDERGiSi, 2015, 8(8): 97-102.
[19] Bekbulatov E, Kartbayev A. A study of certain morphological structures of Kazakh and their impact on the machine translation quality[C]//Proceedings of the 2014 IEEE 8th International Conference on Application of Information and Communication Technologies(AICT), Kazakhstan,2014: 1-5.
[20] Kairakbay B M. Finite state approach to the Kazakh nominal paradigm[C]//Proceedings of the Finite State Methods and Natural Language Processing, Scotland, 2013: 108.
[21] Kairakbay B M, Nurseitov D B, Stolyarov Y Y, et al. Design and implementation of interactive web system for the Kazakh text recognition and correction with using of parallel computing[C]//Proceedings of the International Journal of New Computer Architectures and their Applications(IJNCAA),2013: 100-114.
[22] Kairakbay B M, Nurseitov D B, Stolyarov Y Y, et al. Integrated high-performance and web-oriented system of the Kazakh language text Recognition[C]//Proceedings of the the 2nd International Conference on Informatics Engineering & Information Science(ICIEIS2013),The Society of Digital Information and Wireless Communication, 2013: 25-36.
[23] Kessikbayeva G, Cicekli I. Rule Based Morphological Analyzer of Kazakh Language[C]//Proceedings of the 2014 Joint Meeting of SIGMORPHON and SIGFSM, USA: 2014, 46-54.
[24] Kessikbayeva G, Cicekli I. A rule based morphological analyzer and a morphological disambiguator for Kazakh language [J].Linguistics and Literature Studies, 2016, 4(1): 96-104.
[25] Makhambetov O, Makazhanov A, Yessenbayev Z, et al. Assembling the Kazakh language corpus [C]//Proceedings of 2013 Conference on Empirical Methods in Natural Language Processing. Seattle, Washington, USA; Association for Computational Linguistics.2013: 1022-1031.
[26] Makazhanov A, Makhambetov O, Sabyrgaliyev I, et al. Spelling correction for Kazakh[C]//Proceedings of the computational linguistics and Intelligent text processing, Germeny: Springer Berlin Heidelberg, 2014: 533-541.
[27] Makazhanov A, Yessenbayev Z, Sabyrgaliyev I, et al. On certain aspects of Kazakh part-of-speech tagging[C]//Proceedings of the 2014 IEEE 8th International Conference on Application of Information and Communication Technologies(AICT)Kazakhstan,2014: 1-4.
[28] Makhambetov O, Makazhanov A, Yessenbayev Z, et al. Towards a data-driven morphological analysis of Kazakh language [J].TÜRKiYE BiLiiM VAKFI BiLGiSAYAR BiLiMLERi ve MÜDERGiSi, 2015, 8(8): 69-74.
[29] Makhambetov O, Makazhanov A, Sabyrgaliyev I, et al. Data-driven morphological analysis and disambiguation for Kazakh [M]. Computational linguistics and Intelligent text processing. Springer International Publishing, Gelbukh A. 2015: 151-163.
[30] Yessenbayev Z, Karabalayeva M, Shamayeva F. Towards building an intelligent voice system for Kazakh: Acoustic database and system design[C]//Proceedings of the 8th EUROSIM Congress on Modelling and Simulation(EUROSIM), United Kingdom,2013: 393-397.
[31] Yessenbayev Z, Yapanel U. Perceptual mvdr-based unsupervised built-in speaker normalization for Kazakh speech recognition[C]//Proceedings of the 2014 IEEE 8th International Conference on Application of Information and Communication Technologies(AICT), Kazakhstan, 2014: 1-5.
[32] Yessenbayev Z, Saparkhojayev N, Tibeyev T. Implementation of the intelligent voice system for Kazakh [J]. Journal of Physics: Conference Series, 2014, 495(1): 1-5.
[33] 达吾勒·阿布都哈依尔, 古丽拉·阿东别克. 哈萨克语词法分析器的研究与实现 [J]. 计算机工程与应用, 2008, 44(19): 146-149.
[34] 侯呈风, 古丽拉·阿东别克. 改进的HMM应用于哈萨克语词性标注 [J]. 计算机工程与应用, 2010, 46(36): 147-149.
[35] Altenbek G, Wang X, Haisha G. Identification of basic phrases for Kazakh language using maximum entropy model [C].//Proceedings of the 25th International Conference on Computational Linguistics(COLING 2014)Dublin, Ireland; Association for Computational Linguistics,2014: 1007-1014.
[36] 吐尔根·依布拉音, 袁保社. 新疆少数民族语言文字信息处理研究与应用 [J]. 中文信息学报, 2011, 25(06): 149-156.
[37] 玉素甫·艾白都拉, 张海军, 艾孜尔古丽. 信息处理用现代维吾尔语词干词类标记集研究 [J]. 信息技术与标准化, 2011(06): 45-48,63.
[38] 玉素甫·艾白都拉, 艾孜尔古丽, 祖丽皮亚. 基于网站用词调查的现代维吾尔语词长研究 [J]. 计算机应用与软件, 2012, 29(05): 32-34.
[39] Wumaier A, Tursun P, Kadeer Z, et al. Uyghur noun suffix finite state machine for stemming[C]//Proceedings of the 2nd IEEE International Conference on Computer Science and Information Technology, Beijing,China,2009: 161-164.
[40] Wumaier A, Kadeer Z, Tursun P, et al. Maximum entropy combined FSM stemming method for Uyghur[C]//Proceedings of the 2009 Oriental COCOSDA International Conference on Speech Database and Assessments, Urumqi,China,2009: 51-55.
[41] Wumaier A, Yibulayin T, Zaokere K, et al. Conditional random fields combined FSM stemming method for Uyghur[C]//Proceedings of the 2009 2nd IEEE International Conference on Computer Science and Information Technology, Beijing,China, 2009: 295-299.
[42] 麦热哈巴·艾力, 姜文斌, 王志洋, 等. 维吾尔语词法分析的有向图模型 [J]. 软件学报, 2012, 23(12): 3115-3129.
[43] 麦热哈巴·艾力, 姜文斌, 吐尔根·依布拉音. 维吾尔语词法中音变现象的自动还原模型 [J]. 中文信息学报, 2012, 26(01): 91-96.
[44] 帕提古丽·依马木一, 买合木提·买买提, 卡哈尔江·阿比的热西提, 等. 基于感知器算法的维吾尔语词性标注研究 [J]. 中文信息学报, 2014, 28(05): 358-362.
[45] 赛迪亚古丽·艾尼瓦尔, 向露, 宗成庆, 等. 融合多策略的维吾尔语词干提取方法 [J]. 中文信息学报, 2015,(05): 204-210.
[46] Mahmoud A, Pattar A, Hamdulla A. Uyghur stemming using conditional random fields [J]. International Journal of Signal Processing, Image Processing and Pattern Recognition, 2015, 8(8): 43-50.
[47] Tohti T, Musajan W, Hamdulla A. Unsupervised learning and linguistic rule based algorithm for Uyghur word segmentation [J]. Journal of Multimedia, 2014, 9(5): 627-634.
[48] Yang Y, Mi C, Ma B, et al. Character tagging-based word segmentation for Uyghur [M]. Machine translation. Shi X, Chen Y. Springer,2014: 61-69.
[49] 王海波, 祖漪清, 力提甫·托乎提. 基于功能词缀串的维吾尔语词性标注方法 [J]. 中文信息学报, 2013, 27(05): 179-183.
[50] 张海波, 蔡洽吾, 姜文斌, 等. 基于联合音变还原和形态切分的形态分析方法 [J]. 中文信息学报, 2014, 28(06): 9-17.
[51] Atalay N B, Oflazer K, Say B. The annotation process in the turkish Treebank[C]//Proceedings of the 4th Intern Workshop on Linguistically Interpreteted Corpora(LINC),Citeseer, 2003.
[54] 陈莉,古丽拉·阿东别克. 基于HMM的柯尔克孜语词性标注的研究 [J]. 计算机工程与应用, 2014, 50(15): 120-124.

[57] 哈里旦木·阿布都克里木, 吐尔根·依布拉音, 帕力旦·吐尔逊, 等. 基于短语结构语法的维吾尔语规则库建设 [J]. 现代计算机(专业版), 2010(5): 30-33.
[58] Wushouer J, Abulizi W, Abiderexiti K, et al. Building contemporary Uyghur grammatical information dictionary[C]//Proceedings of the Worldwide Language Service Infrastructure, Kyoto, Japan: Springer International Publishing, 2016: 137-144.
[59] Mamitimin S, Ibrahim T, Eli M. The annotation scheme for Uyghur dependency treebank[C]//Proceedings of the 2013 International Conference on Asian Language Processing(IALP), Urumqi, China, 2013: 185-188.
[60] Aili M, Xialifu A, Maimaitimin S. Building Uyghur dependency Treebank: Design principles, annotation schema and tools[C]//Proceedings of the Worldwide Language Service Infrastructure, Kyoto, Japan: Springer, 2016: 124-136.
[61] Aili M, Mushajiang W, Yibulayin T, et al. Universal dependencies for Uyghur[C]//Proceedings of the WLSI-OIAF4HLT 2016, Japan,2016: 44-50.
[62] Buchholz S, Marsi E. Conll-X shared task on multilingual dependency parsing[C]//Proceedings of the 10th Conference on Computational Natural Language Learning,Association for Computational Linguistics, 2006: 149-164.
[63] Tatar S, Cicekli I. Automatic rule learning exploiting morphological features for named entity recognition in Turkish [J]. Journal of Information Science, 2011, 37(2): 137-151.

[65] Yavuz S, Küçük D, YazcA. Named entity recognition in Turkish with Bayesian learning and hybrid approaches [M]. Information sciences and systems 2013. Switzerland: Springer Gelenbe E, Lent R. International Publishing, 2013: 129-138.
[66] Küçük D. Automatic compilation of language resources for named entity recognition in Turkish by utilizing Wikipedia article titles [J]. Computer Standards & Interfaces, 2015, 41: 1-9.
[67] Demir H, Ozgur A. Improving named entity recognition for morphologically rich languages using word embeddings[C]//Proceedings of the 13th International Conference on Machine Learning and Applications(ICMLA), USA. IEEE, 2014: 117-122.
[68] 李佳正, 刘凯, 麦热哈巴·艾力, 等. 维吾尔语中汉族人名的识别及翻译 [J]. 中文信息学报, 2011,25(04): 82-87.
[69] 艾斯卡尔·肉孜, 宗成庆, 姑丽加玛丽·麦麦提艾力, 等. 基于条件随机场的维吾尔人名识别方法 [J]. 清华大学学报(自然科学版), 2013(06): 873-877.
[70] 加日拉·买买提热衣木, 吐尔根·依布拉音, 艾山·吾买尔. 基于统计和规则混合策略的维吾尔人名识别研究 [J]. 新疆大学学报(自然科学版), 2014, 31(03): 319-324.
[71] 热合木·马合木提, 于斯音·于苏普, 张家俊, 等. 基于模糊匹配与音字转换的维吾尔语人名识别 [J]. 清华大学学报(自然科学版), 2017(02): 188-196.
[72] 麦合甫热提, 米日姑·肉孜, 麦热哈巴·艾力, 等. 基于语法语义知识的维吾尔文机构名识别 [J]. 计算机工程与设计, 2014, 35(08): 2944-2948.
[73] 木合塔尔·艾尔肯, 艾斯卡尔·艾木都拉, 地里木拉提·吐尔逊. 基于规则的维吾尔文地名识别 [J]. 通信技术, 2013(7): 103-105.
[76] Tyers F M, Alperen M S. South-East European Times: A Parallel Corpus of Balkan Languages[C]//Proceedings of the LREC Workshop on Exploitation of Multilingual Resources and Tools for Central and(South-)Eastern European Languages, Valletta,Malta,2010: 49-53.
[77] Mericli B S, Bloodgood M. Annotating cognates and etymological origin in Turkic languages[C]//Proceedings of the 1st Workshop on Language Resources and Technologies for Turkic Languages at LREC 2012, Turkey,2012: 47-50.
[78] Eyigöz E, Gildea D, Oflazer K. Simultaneous word-morpheme alignment for statistical machine translation[C]//Proceedings of the NAACL-HLT 2013, USA,2013: 32-40.
[81] Oflazer K. Turkish and its challenges for language processing [J]. Language Resources and Evaluation, 2014, 48(4): 639-653.
[82] Cöltekin C. A set of open-source tools for Turkish natural language processing[C]//Proceedings of the 9th International Conference on Language Resources and Evaluation, Reykjavik, Iceland, 2014: 1079-1086.
[83] 董兴华, 周俊林, 郭树盛, 等. 基于短语的汉维/维汉统计机器翻译 [J]. 计算机工程, 2011, 37(9): 16-18,21.
[84] 董兴华, 陈丽娟, 周喜, 等. 汉维统计机器翻译中的形态学处理 [J]. 计算机工程, 2011, 37(12): 150-152.
[85] 陈丽娟, 张恒, 董兴华, 等. 基于句法调序的汉维统计机器翻译 [J]. 计算机工程与应用, 2011, 38(3): 169-171.
[86] 艾孜孜·吐尔逊, 杨雅婷, 吐尔洪·吾司曼, 等. 维—汉统计机器翻译中维吾尔语预处理研究 [J]. 计算机工程与设计, 2014, 35(11): 4034-4039.
[87] 米成刚, 王磊, 杨雅婷, 等. 维汉机器翻译未登录词识别研究 [J]. 计算机应用研究, 2013, 30(04): 1112-1115.
[88] Wang Z, Lü Y, Sun M, et al. Stem translation with affix-based rule selection for agglutinative languages[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria. Association for Computational Linguistics, 2013, 364-369.
[89] Abiderexiti K, Yao T, Yibulayin T, et al. Implementation of Chinese-Uyghur bilateral EBMT system[C]//Proceedings of the 2013 International Conference on Asian Language Processing(IALP), China,Urumqi, 2013: 87-90.
[90] Xuehelaiti M, Liu K, Jiang W, et al. Uyghur language model with graphic structure [J]. Journal of Multimedia, 2014, 9(8): 1005-1010.
[91] 米莉万·雪合来提, 麦热哈巴·艾力, 吐尔根·依布拉音, 等. 维吾尔语词尾对汉维统计机器翻译影响的研究 [J]. 计算机工程, 2014, 40(03): 224-227.
[92] Washington J N, Ipasov M, Tyers F M. A finite-state morphological transducer for Kyrgyz[C]//Proceedings of the 8th International Conference on Language Resources and Evaluation(LREC'12), Turkey, 2012: 934-940.
[93] Washington J N, Salimzyanov I, Tyers F M. Finite-state morphological transducers for three Kypchak Languages[C]//Proceedings of the Ninth International Conference on Language Resources and Evaluation, Iceland, 2014: 3378-3385.
[94] Tyers F M, Washington J N, Salimzyanov I, et al. A prototype machine translation system for Tatar and Bashkir based on free/open-source components [C]//Proceedings of 1st Workshop on Language Resources and Technologies for Turkic Languages at LREC 2012. Turkey, 2012: 11-14.
[95] Salimzyanov I, Washington J N, Tyers F M. A Free/Open-Source Kazakh-Tatar Machine Translation System[C]//Proceedings of the XIV Machine Translation Summit, Nice: 2013, 175-182.
[96] Ogawa Y, Fukuda M, Toyama K. Transliteration from Uighur to Uzbek for expansion of Japanese translation dictionary[C]//Proceedings of the recent advances of asian language processing technologies,2008: 182-188.
[97] Wushouer M, Ishida T, Lin D. A heuristic framework for pivot-based bilingual dictionary induction[C]//Proceedings of the 2013 International Conference on Culture and Computing(Culture Computing),IEEE, 2013: 111-116.
[98] Wushouer M, Lin D, Ishida T, et al. A constraint approach to pivot-based bilingual dictionary induction [J]. ACM Transactions on Asian and Low-Resource Language Information Processing, 2015, 15(1): 1-26.
[99] Sheymovich A V, Dybo A V. Towards a morphological annotation of the Khakass corpus[C]//Proceedings of 1st Workshop on Language Resources and Technologies for Turkic Languages at LREC 2012, 2012: 39-46.
[100] Galieva A, Gatiatullin A, Nevzorova O, et al. Semantic annotation of Tatar verbs for linguistic applications [J]. TÜRKiYE BiLiiM VAKFI BiLGiSAYAR BiLiMLERi ve MÜDERGiSi, 2014, 8(8): 45-49.
[101] Suleymanov D S, Gatiatullin A R, Almenova A B. Multifunctional model of morphemes in the Turkic group languages(on the Example of the Kazakh and Tatar Languages)[J]. TÜRKiYE BiLiiM VAKFI BiLGiSAYAR BiLiMLERi ve MÜDERGiSi, 2014, 8(8): 63-67.
[102] 木合亚提·尼亚孜别克, 古力沙吾利·塔里甫, 达吾勒·阿布都哈依尔. 柯尔克孜语语料库语言资源管理平台的设计与开发 [J]. 南昌大学学报(理科版), 2015(03): 247-250.
[103] Kurimo M, Virpioja S, Turunen V, et al. Morpho Challenge Competition 2005—2010: Evaluations and Results[C]//Proceedings of the 11th Meeting of the ACL Special Interest Group on Computational Morphology and Phonology,2010: 87-95.
[104] Baisa V, Suchomel V. Large corpora for Turkic languages and unsupervised morphological analysis[C]//Proceedings of the 8th Conference on International Language Resources and Evaluation(LREC’12), Istanbul, Turkey: European Language Resources Association(ELRA), 2012: 28-32.
[105] Narasimhan K, Barzilay R, Jaakkola T. An unsupervised method for uncovering morphological chains [J]. Transactions of the Association for Computational Linguistics, 2015(3): 157-167.

[107] Faruqui M, Tsvetkov Y, Neubig G, et al. Morphological inflection generation using character sequence to sequence learning [J/OL] 2015, arXiv preprint arXiv: 1512.06110v2.
[108] Faruqui M, Mcdonald R, Soricut R. Morpho-syntactic lexicon generation using graph-based semi-supervised learning [J/OL] 2015, arXiv preprint arXiv: 1512.05030.
[109] Durrett G, Denero J. Supervised learning of complete morphological paradigms[C]//Proceedings of the NAACL-HLT 2013, USA, 2013: 1185-1195.
[110] Ahlberg M, Forsberg M, Hulden M. Semi-supervised learning of morphological paradigms and lexicons[C]//Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, Sweden, 2014: 569-578.
[111] Ahlberg M, Forsberg M. Paradigm classification in supervised learning of morphology[C]//Proceedings of the Main Conference HLT-NAACL 2015 Human Language Technology Conference of the North American Chapter of the Association of Computational Linguistics, USA, 2015: 1024-1029.
[112] Nicolai G, Cherry C, Kondrak G. Inflection generation as discriminative string transduction[C]//Proceedings of the Main Conference HLT-NAACL 2015 Human Language Technology, USA, 2015: 922-931.
