Exploration of In fluential People for Viral Marketing
2018-06-07MuhammadAzamZiaZhongbaoZhangLiutongChenMuhammadHashimSenSu
Muhammad Azam Zia, Zhongbao Zhang, Liutong Chen, Muhammad Hashim, Sen Su,*
1 State key Laboratory of Networking and Switching Technology, Beijing University of Posts and Telecommunications,No.10 Xitucheng Road, Beijing 100876, China
2 Department of Computer Science, University of Agriculture, Faisalabad, Pakistan
3 Department of Management Sciences, National Textile University, Faisalabad, Pakistan
I. INTRODUCTION
Social network is an intricate structure that consists of entities and mutual associations.This complex structure plays a vital role in news broadcasting, advertisements, understanding of social actions, knowledge discovery and propagation of information [1,2].More precisely, social network provides an opportunity to interact with people to share ideas and information [3]. In online social networks (OSNs) field, groups, companies or users tied to interdependencies in terms of comradeship, close relationships and association etc [4]. Leading micro-blogs networks such as Twitter and Sina Weibo are among the most popular blogging platforms [5-7]. Twitter was introduced by Obvious Corporation while Weibo is another micro-blog network. Weibo was introduced in China relatively later than Twitter, yet it is still developing in a rapid mood. Weibo has attracted only a few research groups to study and analyse the data produced by it. These platforms have revolutionized the world due to their high speed of information sharing and public networking functionalities.
To explore influential people (IP) for effective viral marketing purpose, OSNs are being employed which are penetrated in all dimensions of humans’ life. Recently, the demand of viral marketing is the potential people who have the ability to convince other people through their opinion [4]. Through definition,social in fluence denotes to the ability or power of generating an effect in significant ways.This element unlocks a new aspect of research to discover the most IP that can impact to alter other’s thoughts in a powerful way within OSNs [8]. These IP can propagate the news more effectively. The exploration of IP in OSNs is studied by many scholars during the previous decade and their findings offered different insights for viral marketing field. More precisely, within OSNs, scholars generally focused towards identifying the opinion leaders[9], community leaders [10], and trend setters[11]. Similarly, TunkRank algorithm proposed by Tunkelang [12] based on PageRank model to mine the key nodes in Twitter network. But only considered the following relationship between users, while there are missing factors that might be considered like re-tweet, mention and comment etc. Further, the influence value is distributed evenly rather than proportionally. While Cha et al. [15] concluded that IP have substantial influence on variant topics; more in fluential user is one, having an active audience to re-tweet the tweets or to mentions the user and overlooked to consider the significance of re-tweet factor. Albeit of much progress in the underlying field, there still exist many limitations that necessitate to be considered while extracting effective IP.
This study motivated by the aforementioned works; this article aims to propose an effective algorithm to depict IP in a more efficient way. There exist a lot of related works which are only trying to improve the results based on several classic algorithms,but this study comes up with a novel idea of label propagation algorithm that simulate the spread of influence. Various studies have overlooked the interaction between followers and followees, but this study hypothesizes that the communication strength (CS) has a large impact on the process of information spreading, which means that CS and authority help to explore the better IP in the micro-blog networks. Furthermore, as the active and popular users are more likely trusted by others in the social networks, the nodes themselves play an important role in information spread, therefore the node’s attributes are considered as an authority in our proposed algorithm.
In this article, the authors proposed a novel algorithm named IPLPA to discover the IP in micro-blog networks.
The main contributions of this study are described as follows:
First, this is pioneer attempt to propose the innovative concept of CS and authority which are involved in the process of evaluating IP.We calculate CS between users by three kinds of actions including retweets, comments and mentions. While, authority is measured from a novel perspective that comprises the tweets,times of re-tweets and number of followers.
Second, we proposed an innovative algorithm named: Influential People Label Propagation Algorithm (IPLPA). More precisely,the proposed algorithm identifies the better IP while considering both interactive strength and authority.
Third, we performed numerous experiments to extract IP with respect to other comparative users in the micro-blog networks. Then, we compared the gained outcomes with prior algorithms. The comparative analysis shows that IPLPA outperforms the baseline algorithms while discovering the people having more CS and authority. Additionally, we also adopt the propagation model to measure the influence propagation for obtained IP in order to validate the proposed concept.
II. RELATED WORK
Research groups have been giving efforts in the field of mining the key nodes in the social networks. Various models and conclusions have been proposed by many scholars in different perspectives.
In 2003, before the appearance of micro-blog social platforms, Park had proposed the “Influence Maximization” model [13].They gave an approximate solution to the problem, which was about how to find the set of seed users so that the in fluence can be spread most widely. In 2010, Goyal et al [14]studied the above propagation model and then gave a set of parameters based on the user’s record from the picture sharing website Flickr.With these parameters, they analysed the influence between the users who are friends to each other but did not evaluate the influence with respect to all the other users. However,they did not concentrate on estimate the parameters of propagation model from the actual data, which means this research cannot be applied to measure the social in fluence of users in Weibo.
In micro-blog platforms, the research groups have spent lots of time on the influence spreading in Twitter and proposed models from different perspectives. Cha et al [15] compared three ways of measuring social in fluence, separately based on times of retweeted, times of mentioned and number of followers. Also, they analysed the rule about how the influence changes with respect to time. However, they found that the user with large number of followers will not absolutely get retweeted or mentioned by other users. It means that we should not only concentrate on the network structure based on the following relationship. In the same year, Weng et al [16]measured the influence under specific topics based on the following relationship between users and the main topic extracted from blogs.But according to [15] users who are more likely to be followed by others may not have strong ability to spread the information.
There exist few studies that have been initiated from other perspectives. Among of them,Diakopoulos and Shammaa were inspired by the increasing number of words about attitude and emotions from the tweet of President of United States and came up with an idea, which indicated that the combination of Twitter and Video could provide a social video experiences so that an analysis method could be created to help journalists and experts understand the attitude of people in the Internet [17]. Moreover,some experts conducted a content analysis on the unique events to monitor and identify the trend of information spread in Twitter, then the rules behind these events could be uncovered.The occurrence and development of the trends summarized in [18]. Ye and Wu, proposed a comparison based on the in fluence of followers, comments, retweets, and number of followers, tweets, retweets. They proposed that the in fluence based on the comment was more stable and thus ranked the user’s influence[19]. Albeit of many nuanced results, either some proposals employed only small datasets or proper weight age is not given to CS while prior studies also overlooked the authority of the user in dissemination of information.
III. PROBLEM DEFINITION
This study defines the micro-blog network as G =(V, E), where V represents the set of nodes in the network while E indicates the links between users. For instance, a node i∈V, it can be either a follower or a followee i-e person being tracked on a social networks.For an edge e∈E, it reflects the types of relationship between two users while, the given edge also determines the information flow.We extend the basic notion of graph theory G by proposing communication strength (CS)and authority metrics. For interactive strength CS( i→j), it reflects the CS that user i obtains from user j, which means user i is the followee of user j. If user i and user j are follower to each other, then there may exist both CS( i→ j) and CS( j→i), as mentioned in figure 1. First of all, CS evaluates between two users based on the mentions, retweets,and comments factors. While, authority metric is measured by employing number of tweets,total times of getting re-tweeted, and number of followers of an underlying user i. Then the proposed algorithm takes CS and authority as an input to explore the influential people.Moreover, CS can be measured between every two linked nodes. The association between two users is represented by term A. For instance, Ajimeans that user i follows user j and the link value will be A=1 otherwise 0. Similarly Aijdenotes that user j follows user i and here link value will be A=1 otherwise 0. The association between two nodes within network can be described as follows:
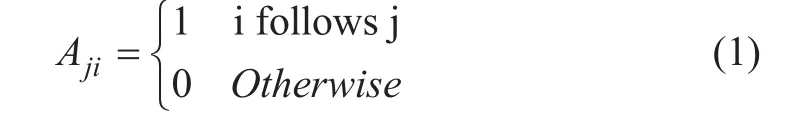
IV. INFLUENTIAL PEOPLE LABELPROPAGATION ALGORITHM (IPLPA)
In this section, we described the necessary factors that need to be incorporated in order to evaluate the influence between users. We enlist the mathematical formulations of interactive strength and authority. Then we explain the PageRank and COPRA algorithms with their corresponding limitations. Consequently,we also explain the IPLPA algorithm and its outline.
4.1 Modelling the communication strength
In this section, CS is analyzed by considering three factors. The CS can reflect the interaction between users so that IP can be identified by prior and proposed algorithms based on CS.
4.1.1 Re-tweeting strength
The re-tweeting strength (RS) in social network platform creates opportunities for information dissemination. When user A posts a tweet, the follower B who is in fluenced by this tweet is likely to re-tweet this user, if user B’s follower C continue re-tweeting it, then user C has re-tweeted both user A and user B. After many iterations of above process, the influence of user A is spread along the re-tweeting network into the whole network.
The re-tweeting strength is computed as follows:

where, the first part of equation is the number of user j re-tweeting user i divided by number of user j re-tweeting others. The second part is calculated as the number of user j re-tweeting user i divided by number of user i re-tweeted by others. These two parts represent the in fluence that user i has on user j, and the larger the re-tweeting strength is, the larger in fluence that user i has on user j.

Fig. 1. Flow of communication.
4.1.2 Commenting Intensity
The comment intensity (CI) in Weibo is an action that a user gives several lines of words under a tweet. While comment action reflects the degree that a user is in fluenced by a tweet,which also indicates this user is affected by the user of given tweet. The equation of commenting strength is as follows:
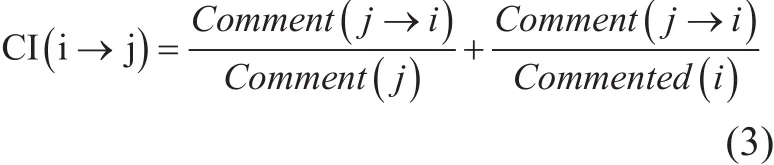
where, the first part of equation is the number of user j commenting user i divided by number of user j commenting others. The second part is calculated as the number of user j commenting user i divided by number of user i commented by others. The larger the commenting strength is, the larger in fluence that user i has on user j.
4.1.3 Mentioning strength
Mentions reflect the degree that a user cares about another user; this is another kind of influence. The mathematical formulation of mentioning strength (MS) is as follows:
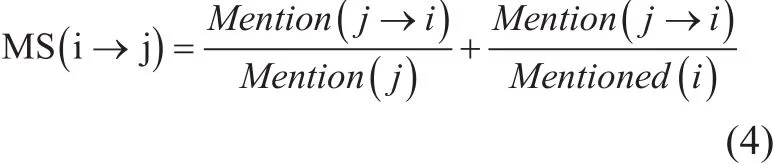
where, the first part of equation is the number of user j mentioning user i divided by number of user j mentioning others. The second part is calculated as the number of user j mentioned user i divided by number of user i mentioned by others. The larger the mentioning strength is, the larger in fluence that user i has on user j.
The essence of proposed CS is the evaluation of in fluence a user has on another user.The more CS between two users, the more accurate in fluence can be calculated. CS measured by three factors namely; re-tweeting strength, commenting intensity, mentioning strength, which are all obey the fact that larger value reflects high influential degree. The above factors are aggregated in the following way:
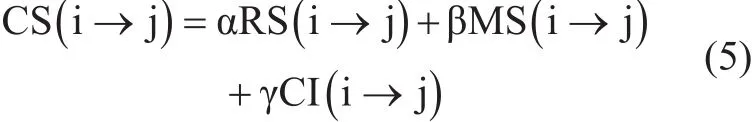
There, are three weight coefficients α,β,γ separately multiplied with three factors which reflect different actions in Weibo. Since these actions have different meanings. So, there should be given corresponding weight age.According to the fact and experience, the coefficients are set as α = 0.5, β = 0.2, γ= 0.3.
4.2 Modelling the authority
During the influence propagation, the degree that a user can accept the in fluence is affected by many factors in the network. So, this study incorporated the factors into one metric called authority. If a user owns high authority, then its followers are more likely willing to trust the information posted by this user and will accept the influence spread by this user. We define the factor that reflects the features of a user as an authority and described as follows:
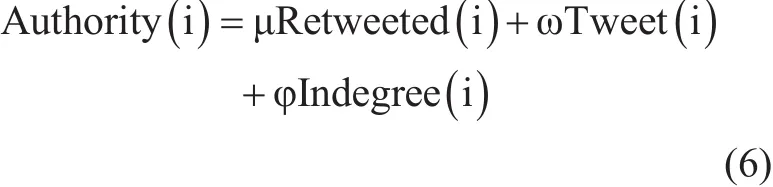
where, there are three weight coefficients μ,ω,φ separately multiplied with three factors, these coefficients should be determined based on the importance of the factors to reflect the authority. The coefficients are set as μ = 0.8, ω = 0.1, φ =0.1
Authority of user i consists of three factors including, number of tweets, times of being re-tweeted, and number of followers of underlying user. The number of tweets reflect the activeness of a user, which means a user with large number of tweets has more chances to let other users to view his tweet and get in fluenced. Times of re-tweeted reflect the quality of user’s tweet, if a user gets re-tweeted many times, then this user is trusted by others and frequently can in fluence other users. The number of followers can also imitates the in fluence of a user and it also believed that having more followers is already trusted by other users.
We use the order relation analysis method to calculate the weights of each factor. In order relation analysis,
If evaluation index Xiis more important than Xj, then Xi> Xj.
There is quantity limit rkbetween two evaluation indexes, while rksatisfies:
Theorem 1:If X1> X2> X3> … > Xm,then rkand rk−1must satisfy rk−1> 1/rk.
Theorem 2:If the quantity limits satisfy theorem 1, then the weights of each evaluation index ωmis calculated as:

Based on the above factors analysis, the weight of each factor calculated according to their importance in the information spreading.
4.3 Drawbacks of existing algorithms
In this section, we illustrate the brief descriptions of prior algorithms. Moreover, we also explain the limitations of baseline algorithms.
4.3.1 PageRank algorithm
PageRank algorithm (PRA) was originally created for ranking the websites’ level, the essence of PRA is that the websites links from websites with good quality are also good. Traditional influence analyzing methods usually use the central idea of PRA or the centralization of nodes to analyze the importance of nodes in the social networks [20,21]. This algorithm simulates the process that Internet surfers randomly click web links to visit the websites. After limited iterations, the scores of every website will converge to a stable value.The final PageRank model can be explained into mathematical notion as follows:

where, PR( pi) denotes the scores of website i, M( pi) denotes the set of websites directing from website i, L( pj) denotes the number of out-links of website j.
4.3.2 Limitations of PageRank algorithm
PRA performs well in ranking websites in the Internet. However, the social network is more complicated, it not only contains the following relationships like that in the Internet, but also interaction relationships between users. Also,PageRank distributes ranking value evenly rather than proportionally.
4.3.3 Community overlap propagation algorithm (COPRA)
Label Propagation algorithm is a community identifying algorithm designed to be used in intricate networks. Gregory firstly proposed the Community Overlap Propagation Algorithm (COPRA) [22] based on the label propagation algorithm, which gathers the nodes with same labels into one community. The overlapping community can be mined since a node can contain several labels.
In COPRA, every node uses label list which contains labels and corresponding memberships. This information is used to identify the community for which user belongs to and how much given user is fond of that community.For instance, if a node’s label list has three labels, then this node belongs to three different communities. To discover the overlapping community, the labels in every label list propagate along the links in the network. Random node v in the network can be in fluenced by the neighboring nodes to update its label list in tthiteration; the membership of label k of node v in tthiteration will be updated as follows:
where, N( v) means the neighbors of user v.
4.3.4 Limitations of COPRA
Since COPRA was originally created for identifying overlapping community, if applied in the information propagation network. There exist several drawbacks which are listed below:
During propagation, the nodes don’t carry the label of itself after each round, which means it does not conform to the fact that a user can continuously in fluence others.
当大巴车驶进有着申根协定的法国境内的时候,我问到他为什么回去有离婚的“风险”?似乎“忘记”风险的他告诉我,原本是他同老伴儿一起来。可临行前不久,他心脏出现房颤,家里所有人都要他等等,怕他受不了十几个小时的飞机……最终,他为实现奶奶,包括父亲在内的“百年祭奠”遗愿,还是瞒着家人踏上了欧洲旅途……他告诉我,如果他父亲活着,整整一百岁!只不过父亲没能有幸成为百岁老人,甚至都没能等到自己的“平反”和“被解放”那一天。纵然后来被恢复了所有的功绩和荣誉,但他却早在五十岁那年,就怀着永远的不解和遗憾,长眠于“牛棚”里!
There is a limitation of the amount of labels that a node can carry, but in the social networks, this limitation sometimes affects the propagation of in fluence.
In fact, the information doesn’t follow fluently and evenly through the networks as expected. It usually depends on the attributes and relationships between two nodes.
Hence, these drawbacks should be filled in order to use this algorithm in our study.
4.4 In fluential people label propagation algorithm (IPLPA)
A user in the micro-blog network can be in fluenced by many users as information propagate to the whole network. Keeping in view this fact, we finally choose the label propagation idea which can simulate the information spread through the network. Inspired by the COPRA, the proposed algorithm (Influential People Label Propagation Algorithm, IPLPA)uses label as the abstract of influence in the social network, the degree of influence is indicated by the membership of label. When the in fluence is spread through the whole network and accumulated to a stable value, the influence of every user is calculated by the sum of membership of the label indicating this user.
As every node has a label list containing all the labels and corresponding membership, the list need be updated in each round of propagation. In tthiteration, labels of user i will be updated as equation (8), where Lt(i) denotes the label list of user i in tthround.
As shown in the equation (9), the fol-lowee’s labels will be added to the user’s label list, which means that this user is influenced by others.
As the in fluence that a user receives is affected by the interactive strength between users as well as the authority of users, in tthiteration, label k’s membership of user i,will be updated as equations (10) and (11):

when k=i, which means the user’s own in fluence is propagated from other users, the membership will not change because a user can not in fluence him/herself.

Algorithm 1. IPLPA Algorithm.Input: social network graph and action file: G (V,E)Output: get each user in fluence inf(i)1. for each edge (i, j)∈E do 2. Evaluate RS i j, CI i j, MS i j) ( ) ( )3. end for 4. for each node i∈V 5. Evaluate Authority (i)6. set L i :1(→ → →t()11. update P k()={li}7. end for 8. while (true)9. for each node i∈V 10. update L i it()12. normalize Pit 13. end for 14. if no changes in all L i t()15. breaks 16. end while 17. for each node i∈v 18. remove li from L( i)19. normalize Pit 20. end for 21. for each node i∈v 22. for each node j∈v 23. inf(i P i)+= j()24. end for 25. end for
The proposed algorithm will stop when all the label lists remain in in a stable size. Then user’s influence can be calculated by aggregating the memberships of each label. Every node carries the label of itself to continuously spread its in fluence but not to in fluence itself.So after the propagation, the label indicating the node itself should be removed from the label list, and then normalize the membership.The final in fluence is the sum of membership of the label indicating this user among all the label lists.
4.4.1 Algorithm outline
The following are the descriptions of the basic steps in proposed IPLPA algorithm:
Line 1-3: calculate the re-tweeting strength,commenting intensity and mentioning strength for every interaction relationship between two users.
Line 4-7: calculate the authority and initialize the label list for every user.
Line 8-16: propagate the labels according to the equation until the end condition.
Line 17-20: remove the label i from the label list of user i, and then normalize the membership.
Line 21-25: calculate the in fluence for every user.
V. EXPERIMENTS AND RESULTS
5.1 Experiment setup
Weibo is one of the largest social network platforms in China. By now, millions of the users have registered a Weibo account, which means that there are numerous contents posted every day. KDD Cup 2012 data set is chosen due to its comprehension [23]. This data set contains all necessary data required to conduct the analysis and experiments. To ensure accuracy, the dataset is pre-processed to a sub-network of users. During pre-processing, we choose 100 seed users who have large amount of followers, then found the followers of these seed users. Next, we found the followers of these users in step 2. After several rounds,we selected users form a small complicated network. In details, this data set includes the basic attributes of users like number of tweets,the following relationship (communication strength) mentions, re-tweets and comments.
5.2 Experiment results and analysis
IPLPA incorporated CS, authority metrics and flow of their operations existed in the aforementioned algorithm outline. We applied IPLPA on the processed dataset in order to measure the in fluence of each user in the network.Numerous experiments repeated several times to produce ranks through iterative process.The top ranked IP discovered those having more CS and authority through proposed IPLPA model. The top 10 IP obtained by IPLPA algorithm are placed in table 1. In order to evaluate the effectiveness of IPLPA model,PageRank and COPRA algorithms are also applied on the same dataset, and their obtained results are showed in table 1 and table 2 for comparison purpose.
5.2.1 Comparative study
The comparative analysis presented that there is only one common user in top 10, which are obtained by IPLPA and COPRA as depicted in table 1. The new users retrieved by IPLPA placed at 1st, 2nd, 3rd, 4th, 5th, 6th, 7th, 8thand 9thpositions are originated to be more in fluential as compared to COPRA algorithm. These users gained better CS and authority comparative to respective users. As depicted, the users with UIDs 1010402, 2188303, 1774717, 1760378,1837210, 1774797, 424477, 1774766,1760642, and 1902321 are emerged as new IP in table 1 by our proposed concept due to their better CS and authority. There are 9 users retrieved by COPRA reflected less influence strength due to having low CS and authority.Therefore, IPLPA is more effective approach than COPRA algorithm in terms of identifying better IP.
Comparative analysis showed that there are six common users out of top 10, which are discovered by IPLPA and PageRank as placed in table 2. The new users discovered by IPLPA placed at 1st, 6th, 7th, and 8thpositions are originated to be more IP as compared to PRA.As depicted, the users with UIDs 1010402,1774797, 424477, and 1774766 are emerged as new in fluential users in table 2 by our proposed concept while these users also validated in the next section. Moreover, we noticed that user 1010402 stood at rank 1st, because it gets re-tweeted more than 17000 times and this value is too large than respective users. Users 1774797, 424477 and 1774766 also have large times of re-tweeted, while less than users 1010402 and 2188303. The uncommon users retrieved by PageRank are not so persuasive in terms of CS and authority. Thus, IPLPA identified more IP than users retrieved by PageRank.
Consequently, it analyzed that that IPLPA achieved much better results than the baseline algorithms, in which less IP are retrieved in top 10 users.
5.2.2 Analysis
In COPRA, as the label propagation idea was used to find the over lapping community,while it did not perform well on identifying the IP in social network. For instance, the size of label list in COPRA is limited to control the number of communities a node can belong to.But IPLPA, which aims to find IP, as a user can be in fluenced by any user, the size of label list is set to unlimited. Likewise, COPRA only considered the single following links between users; it is enough for finding community. In this way, IPLPA is more suitable choice to use in the social networks to find the IP because it considered more factors. Our findings offer new intuitions to determine the IP by employing proposed concept in micro-blog networks.The experiment results demonstrated that proposed IPLPA model uncovers better IP due to inclusion of CS and authority metrics which,improved the results significantly in contrast with prior algorithms.
5.3 Verification
After top users identified, the next step is to verify whether the top users are really the most influential. For this purpose, we employed linear threshold propagation model[24-25] to evaluate the in fluence propagation of the retrieved IP by three algorithms. This model selected a set of nodes as seed nodes to activate, and then every activated node tried to activate the neighbour nodes until no more nodes can be activated. We choose the same number of top in fluential users as seed nodes from the result of each algorithm. Then, we used these nodes as an input to run the Linear Threshold Model. When the algorithm stops,we compared the number of nodes in fluenced by these seed nodes. However, the larger scale influence maximization of these seed nodes reflected the corresponding algorithm is more effective.
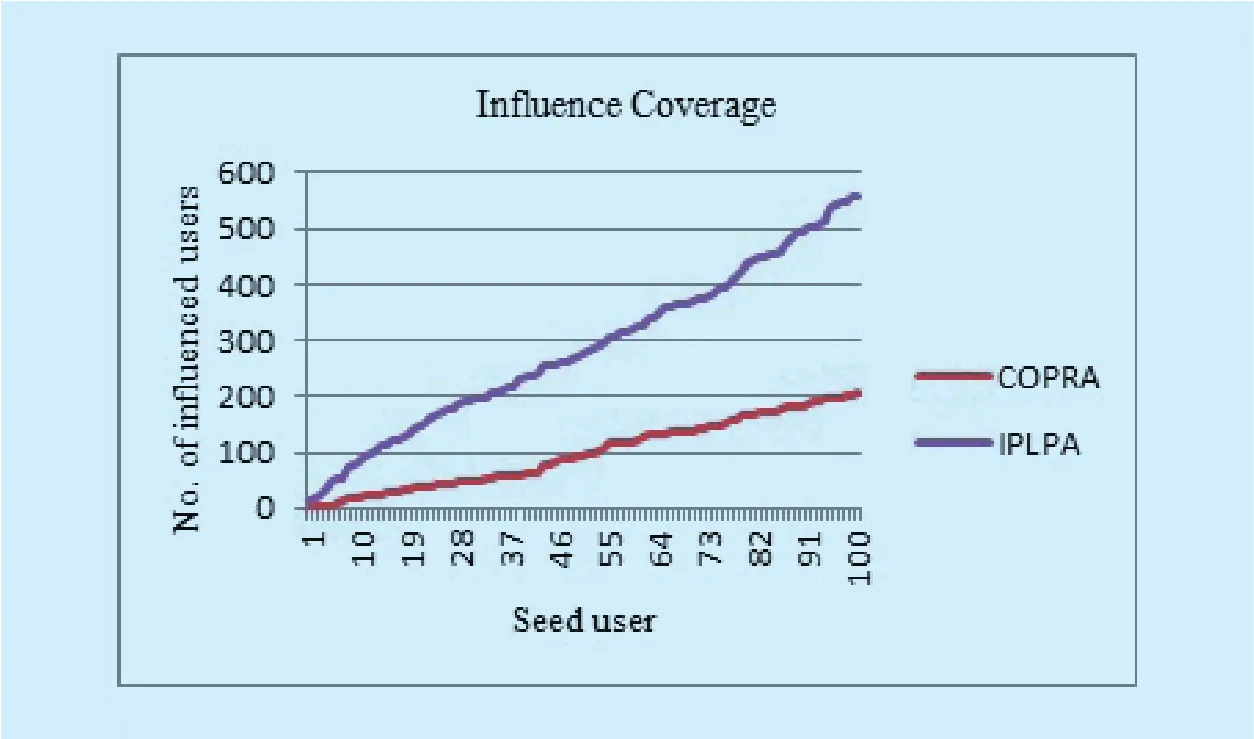
Fig. 2. In fluence coverage of users identified by IPLPA and COPRA.

Fig. 3. In fluence coverage of users identified by IPLPA and PageRank.
Here, we use k to indicate the size of seed users, each time we added the next IP identified by the algorithm into the seed set, so that the set contains top k IP. IPLPA is compared with COPRA as depicted in Fig 2. As both trends are ascending, the number of users that are in fluenced by IPLPA is more than COPRA algorithm.
Influence maximization of IPLPA is also compared with PRA as depicted in Fig 3. Both trends are also ascending, but the number of people which are in fluenced by IPLPA users is always more than users obtained by PRA. In this way, we can say that IPLPA is more effective than baseline algorithms in terms of in fluence maximization. In conclusion, we found that (1) the user’s in fluence is not necessarily determined by the number of followers; (2)the user’s in fluence is more likely affected by the interaction with each other.
VI. CONCLUSION
Nowadays, extraction of IP in OSNs has become a leading issue for experts around the world. In this article, we proposed a novel algorithm named: IPLPA to discover the IP in micro-blog networks. The proposed algorithm incorporated two novel conceptions namely;communication strength and authority metrics. Extensive experiments were conducted out and their outcomes showed that ranking results produced by our approach are more convincing than prior algorithms. Moreover, it was analysed that IPLPA achieved much better results than the baseline algorithms, in which less in fluential people are retrieved in top 10 uses. For validation purpose, the influence maximization was measured for retrieved top users by proposed and prior algorithms. It was noticed that users obtained by IPLPA model propagated more in fluence in contrast of prior algorithms. Hence, we can say that proposed IPLPA is more effective for in fluence maximization than prior algorithms. Consequently, it was concluded that the findings of this study would be useful for the viral marketing and advertisements perspectives. Future studies can be applied the proposed method to other online social networking contexts in order to generalize the findings of this work.

Table I. Top 10 in fluential users identified by IPLPA and COPRA.
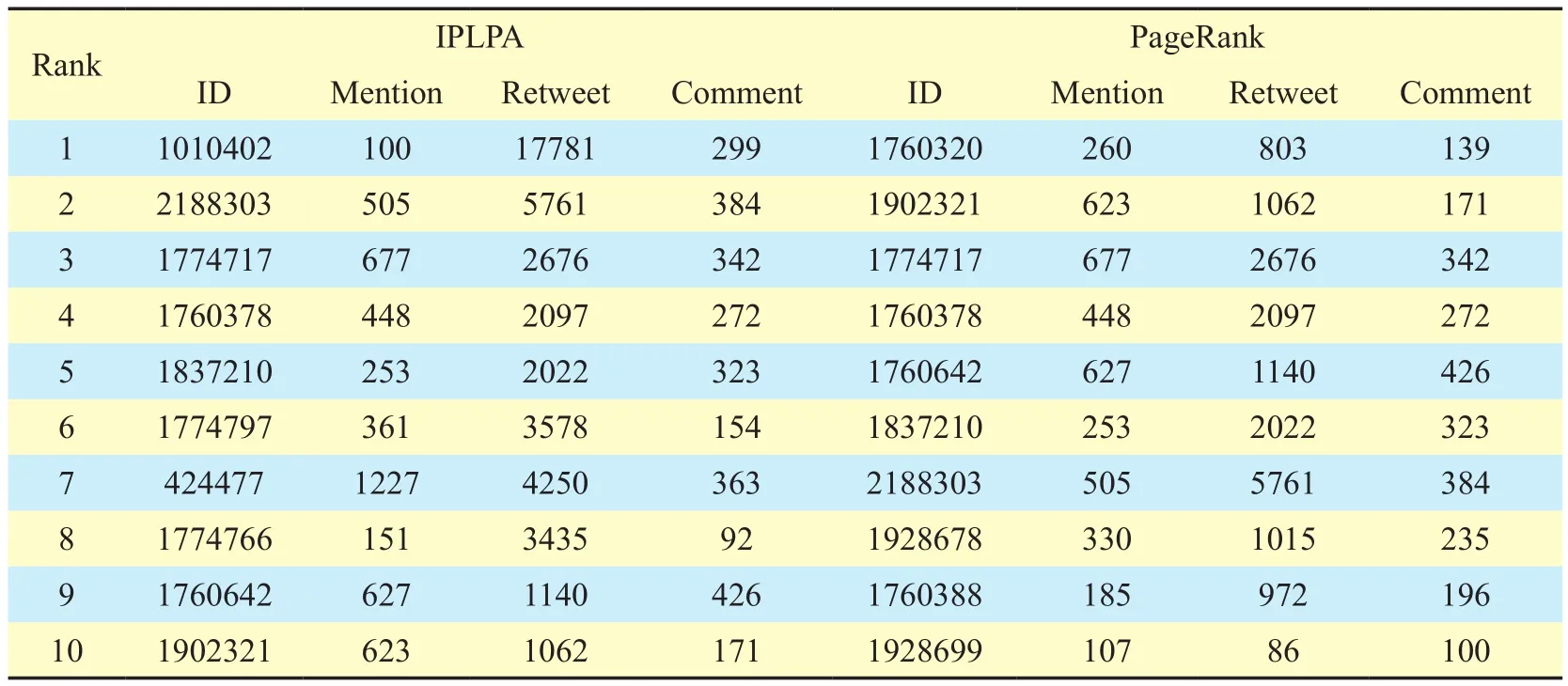
Table II. Top 10 in fluential users identified by IPLPA and PageRank.
ACKNOWLEDGEMENT
This work was supported in part by the following funding agencies of China: National Natural Science Foundation under Grant 61170274, 61602050 and U1534201.
[1] L. Liu and H. Liang, “Influence analysis for celebrities via public cloud and social platform”,China Communications, vol. 13, no. 8, 2016, pp.53-62.
[2] L. Zhang, T. Zhou, Q. Zhixin, L. Guo and L. Xu,“The research on e-mail Users’ behavior of participating in Subjects based on social network analysis”, China Communications, vol. 13, no.4,2016, pp. 70-80.
[3] L. Zhang, T. Zhou, Q. Zhixin, L. Guo, and L. Xu,“The research on e-mail Users’ behavior of participating in Subjects based on social network analysis,” China Communications, vol. 13, no. 4,2016, pp. 70-80.
[4] M. A. Zia, Z. Zhang, L. Chen, H. Ahmad and S.Su, “Identifying Influential People Based on Interaction Strength,” Journal of Information Processing Systems, vol. 13, no. 4, 2017, pp. 987-999.
[5] M. C. Yang and H. C. Rim, “Identifying interesting Twitter contents using topical analysis”,Expert Systems with Applications, vol. 41, no. 9,2014, pp. 4330-4336.
[6] M. A. Zia, Z. Zhang, G. Li, H. Ahmad and S. Su,“Prediction of Rising Venues in Citation Networks,” Journal of advanced computational intelligence and intelligent informatics, vol. 21, no.4, 2017, pp. 650-658.
[7] N. Wang, Q. Sun, Y. Zhou and S. Shen, “A Study on Influential User Identification in Online Social Networks”, Chinese Journal of Electronics, vol. 25, no. 3, 2016, pp. 467-473.
[8] E. Keller and J. Berry, “One American in ten tells the other nine how to vote, where to eat and,what to buy, They are the Influential”, (2003),pp. 21544-21549.
[9] W. Zhang, G. Sun and S. Bin, “An Opinion Leaders Detecting Algorithm in Multi-relationship Online Social Networks”, International journal of hybrid information technology, vol. 9, no. 5,2016, pp. 391-398.
[10] R. Wang, W. Zhang, H. Deng, N. Wang, Q. Miao and X. Zhao, “Discover community leader in social network with PageRank”, International Conference in Swarm Intelligence, 2013, pp. 154-162.
[11] L. L. Yu, S. Asur and B. A. Huberman, “Artificial in flation: the real story of trends and trend-setters in Sina Weibo”, International Conference on Social Computing, 2012, pp. 514-519.
[12] D. Tunkelang, “A Twitter Analog to PageRank”,The Noisy Channel, 2009.
[13] H. Park, “What is Twitter, a social network or a news media?”, 2010.
[14] A. Goyal, F. Bonchi and L. V. S. Lakshmanan,“Learning influence probabilities in social networks”, International Conference on Web Search and Web Data Mining, WSDM, 2010, pp. 241-250.
[15] M. Cha, H. Haddadi, F. Benevenuto and P. K.Gummadi, “Measuring User In fluence in Twitter:The Million Follower Fallacy”, ICWSM, 2010, pp.30-38.
[16] J. Weng, E. P. Lim, J. Jiang and Q. He, “TwitterRank: finding topic-sensitive influential twitterers”, In Proceedings of the third ACM international conference on Web search and data mining, 2010, pp. 261-270.
[17] N. A. Diakopoulos and D. A. Shamma, “Characterizing debate performance via aggregated twitter sentiment”, Sigchi Conference on Human Factors in Computing Systems, ACM, 2010, pp.1195-1198.
[18] A. S. Badashian and E. Stroulia, “Measuring User Influence in Github: The Million Follower Fallacy”, IEEE/ACM, International Workshop on Crowdsourcing in Software Engineering, 2016,pp. 15-21.
[19] S. Ye and S. F. Wu, “Measuring Message Propagation and Social Influence on Twitter.com”,Measuring message propagation and social in fluence on twitter. com”, SocInfo, 2010, pp. 216-231.
[20] M. A. Zia, Z. Zhang, X. Li, H. Ahmad and S. Su,“ComRank: Joint Weight Technique for the Identification of In fluential Communities,” China Communications, vol. 14, no. 4, 2017, pp. 101-110.
[21] M. Xagi, A. Guerbas, K. Kianmehr, P. Karampelas,M. Ridley, R. Alhajj and J. Rokne, “Employing Social Network Construction and Analysis in Web Structure Optimization,” From Sociology to Computing in Social Networks, 2010, pp. 13-34.
[22] S. Gregory, “Finding overlapping communities in networks by label propagation”, New Journal of Physics, vol. 12, no. 10, 2010, pp. 103018.
[23] Kdd Cup, [Online]. Available online at: http://www.kddcup2012.org/c/kddcup2012-trackl,2012.
[24] D. Kempe, J. Kleinberg and E. Tardos, “In fluential nodes in a diffusion model for social networks”,Automata, Languages and Programming,Springer Berlin Heidelberg, 2005, pp. 1127-1138.
[25] H. Chen and Y. Wang, “Threshold-based heuristic algorithm for in fluence maximization”, Journal of Computer Research & Development, vol.49, no. 10, 2012, pp. 2181-2188.
杂志排行

China Communications的其它文章
- Geometric Mean Decomposition Based Hybrid Precoding for Millimeter-Wave Massive MIMO
- Outage Performance of Non-Orthogonal Multiple Access Based Unmanned Aerial Vehicles Satellite Networks
- Outage Probability Minimization for Low-Altitude UAV-Enabled Full-Duplex Mobile Relaying Systems
- Optimal Deployment Density for Maximum Coverage of Drone Small Cells
- Energy Efficient Multi-Antenna UAV-Enabled Mobile Relay
- Energy-Efficient Trajectory Planning for UAV-Aided Secure Communication