一种改进的道路目标检测方法研究
2018-06-07董超俊张秀杰
胡 爽, 董超俊, 张秀杰
(五邑大学信息工程学院, 广东 江门 529020)
引言
随着人工智能领域的快速发展,自动驾驶技术备受关注。目标检测作为计算机视觉领域的重要分支,同时也是自动驾驶的关键技术之一。无可否认,在目标检测领域,深度神经网络的性能优于传统机器学习方法。目标检测的深度学习方法可以分为两种:基于区域提名的方法和基于回归的方法。而基于区域提名的方法包括 R-CNN[1],SPP-net[2],Fast R-CNN[3],Faster R-CNN[4]和R-FCN[5]等。这些方法对于目标的检测可以分为两个阶段:第一阶段生成预选框,第二阶段使用深度神经网络进行分类和位置回归。早期的R-CNN,SPP-net和Fast R-CNN通过选择性搜索方法产生区域提名,这是整个算法的瓶颈。随后,Faster R-CNN放弃了选择性搜索方法,而使用区域提名网络(RPN)来生成区域提名。目前而言,基于R-CNN的方法检测准确率相对较高,但它们无法实现实时处理。
为了提高检测速度,研究者们提出了基于回归的方法,包括YOLO[6]和SSD[7],它们只使用单一网络同时生成边界框并且完成分类。这些方法可以在GPU上实现实时处理。YOLO对输入图像划分网格,每个网格预测两个对象框的置信度和位置。但是当多个对象在一个网格中时,模型也只能预测出一个目标,这是YOLO的短板所在,所以YOLO的检测精度不尽如人意。SSD是冲着YOLO的缺点来的,它分为两部分:前半部分是基于VGG16的网络,去掉了分类相关的层;后半部分是引入的额外的多尺度特征提取层,达到检测不同大小目标的目的。虽然相对于YOLO,SSD在检测精度上有了很大提高,但是对于小目标的检测性能还是不能令人满意。
1 改进的道路目标检测方法
鉴于SSD不逊于Faster R-CNN的准确率,而且检测速度可以达到实时处理,本文重新设计了SSD的网络结构,通过增加卷积核的类型,在VGG-16之后的附加层中引入了Inception模块[8],这增加了模型对小物体的敏感度,可以提取到更多小目标的信息。
1.1 Inception模块
SSD中附加层的尺寸相对较小,其中包含的小物体信息是有限的,而且随着SSD网络的深入,这些信息变得越来越少。一般来说,模型的性能可以通过提高它们的深度和宽度来得以提升,但是,这会导致参数增加,使得计算量几何增长并容易过拟合。文献[8]认为解决由参数增加引起的这两个问题的基本方法是将整个连接层或甚至一半卷积层转换为稀疏链接,而Inception结构不仅利用了密集矩阵的高性能,而且保持了网络的稀疏性,近似一个稀疏结构。因此,本文认为,在不增加网络复杂性的情况下,Inception模块可以捕获更多信息。
下页图1所示为Inception模块的基本结构,它将 1×1、3×3、5×5 的卷积核堆叠在一起,一方面增加了网络的宽度,另一方面增加了网络对尺度的适应性,而且提高了网络内部计算资源的利用率。本文对Inception模块的结构进行改变:将5×5的卷积核替换成两个3×3卷积核,这样可以保留更多的目标细节;同时减少Inception模块的每一层中的特征图数量,保持特征图的总和与原始附加层中的特征图的总和相同;为了反映不同尺度卷积核的重要性,给三种卷积 conv1×1、conv3×3、conv5×5 的输出分别赋予不同的权重1/4、1/2、1/4;为了加快模型的训练速度,在Inception模块的每个卷积层后使用BN(Batch Normalization,批归一化)。改进后的Inception模块如图2所示。

图1 Inception模块结构
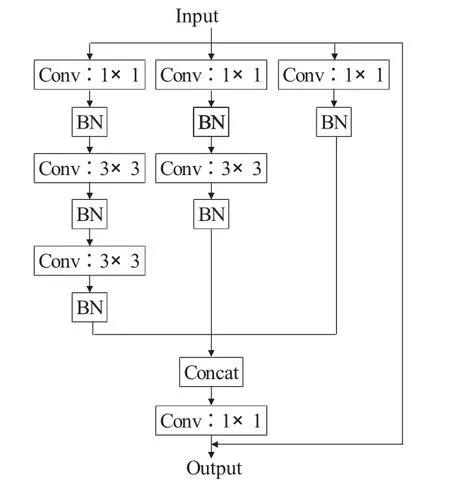
图2 改进的Inception模块
1.2 改进的SSD网络
SSD的网络结构如图3-1所示,前面基于VGG16的 网 络 包 括 conv1_1、conv1_2、conv2_1、conv2_2、conv3_1、conv3_2、conv3_3、conv4_1、conv4_2、conv4_3、conv5_1、conv5_2、conv5_3,FC6、FC7 原为全连接层,现改为卷积层,附加层包括 conv6_1、conv6_2、conv7_1、conv7_2、conv8_1、conv8_2、conv9_1、conv9_2、loss。使用 conv4_3,fc7,conv6_2,conv7_2,conv8_2 和conv9_2作为特征提取层,其中 conv4_3、FC7、conv6_2、conv7_2、conv8_2 用 3×3卷积核进行卷积,并且对其输出再分别采用两个3×3大小的卷积核进行卷积,这两个卷积核是并列的,一个输出分类用的confidence,一个输出回归用的localization。本文用 Inception 模 块 代 替 conv6_1、conv6_2、conv7_1、conv7_2、conv8_1、conv8_2,仍然使用 conv4_3,fc7,conv6_2,conv7_2,conv8_2 和 conv9_2作为特征提取层来检测对象。但是,随着网络的深入,融合变得越来越困难,为了克服这个问题,本文在附加层中引入了残差结构:连接conv6_2的输入和输出作为conv7_1的输入,连接conv7_2的输入和输出作为conv8_1的输入。改进后的SSD网络结构如图3(b)所示。
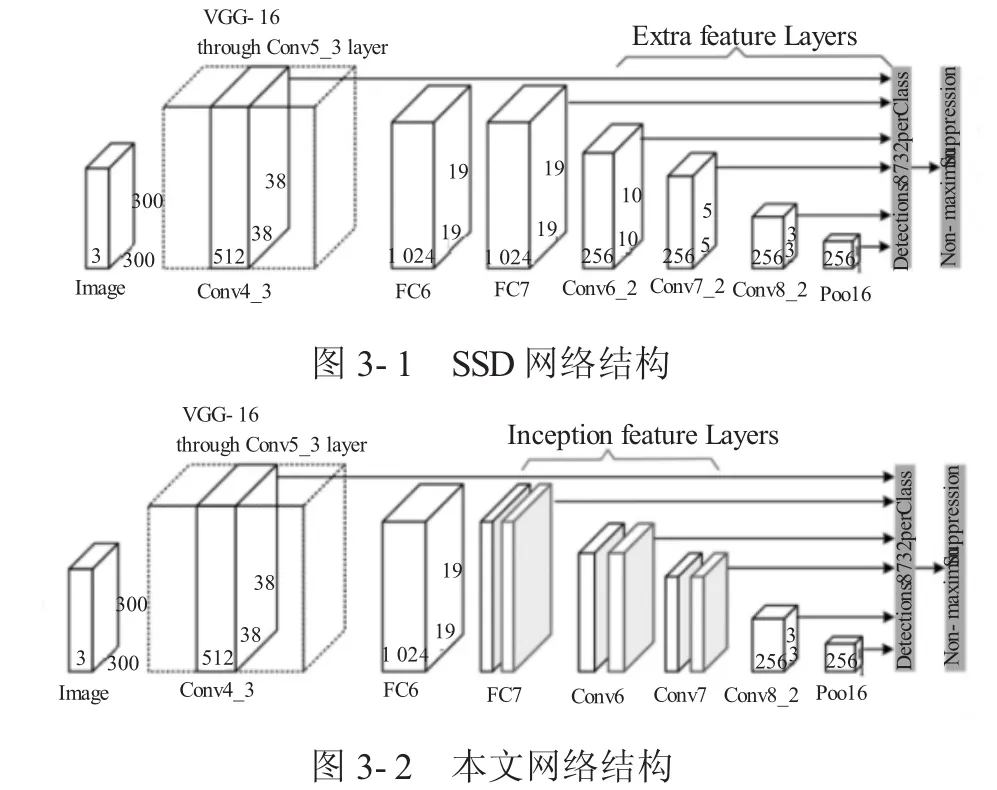
图3 改进后的SSD网络结构与普通SSD网络结构的区别
2 实验结果与分析
本文使用深度学习框架Caffe来实现网络重构并训练。实验环境:Ubuntu 14.04操作系统,处理器为8G Intel(R)Core(TM)i7-7700K CPU@4.20 GHz,显卡为8G GeForce GTX1080。
2.1 PVD数据集
PVD(Pedestrian and Vehicle dataset)是根据 PASCAL VOC数据集的格式制作的行人和车辆的数据集,包括 people、car、bus、bike、motorcycle 五个类别,图片主要来源于车载摄像头、网络图片及其他数据集。数据集共有5 000张图片,约13 000个目标,选择1 000张作为测试集。
2.2 结果分析
训练时,采用SGD(随机梯度下降),初始学习率base_lr为0.001,最大迭代次数max_iter设置为120 000次,stepsize为40 000,动量momentum为0.9,weight_decay为 0.000 5,batch_size为 32。
图4为召回率随交并比(LoU)的变化曲线,可以看出,当IoU为0.5时,本文网络召回率为72.8%,要高于SSD的71.0%,随着IoU的上升,本文网络的召回率仍然高于SSD。
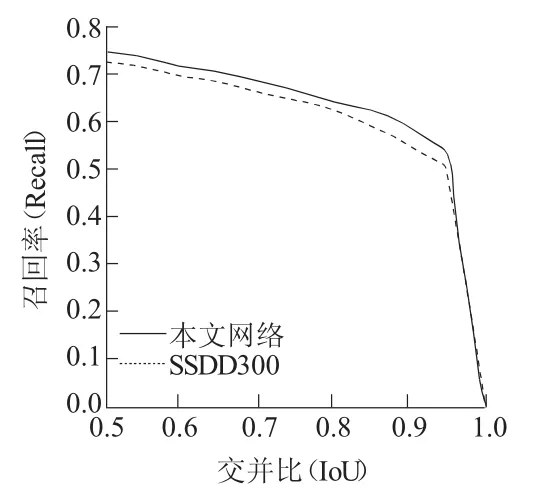
图4 召回率—IoU曲线
表1列出了SSD与本文网络检测的准确率和速度。可以看出,本文网络在五类目标的准确率和平均准确率上均高于SSD,本文网络机构的速度仅比SSD略慢,仍然能够实现实时检测。

表1 准确率和速度对比

图5 本文网络检测与SSD网络检测的区别
图5是置信度阈值为0.6时的实际检测效果图,图5-1为本文网络检测结果,图5-2为SSD检测结果。可以看出,本文网络对于小目标的检测效果确实要比SSD好。
3 结语
本文提出了一种改进的SSD网络,在SSD附加层中引入Inception模块来提升网络对小目标的提取能力。通过在自制数据集上的实验表明,相较于SSD网络,本文提出的方法确实提高了对小目标的检测准确率,而且网络的速度可以达到实时检测的效果。
[1]R Girshick,J Donahue,T Darrell,and J Malik.Rich feature hierarchies for accurate object detection and semantic segmentation[J].2014:580-587.
[2]Kaiming He,Xiangyu Zhang,Shaoqing Ren,and Jian Sun.Spatial pyramid pooling in deep convolutionalnetworks forvisual recognition[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2015:37(9):1 904-1 916.
[3]Ross Girshick.Fast r-cnn[J].Computer Science,2015.
[4]S.Ren,K.He,R Girshick,andJ.,Sun.Faster r-cnn:Towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,201,39(6):1.
[5]Jifeng Dai,Yi Li,Kaiming He,and Jian Sun.R-fcn:Object detectionvia region-based fully convolutional networks[J].2016:379-387.
[6]Wei Liu,Dragomir Anguelov,Dumitru Erhan,Christian Szegedy,Scott Reed,Cheng Yang Fu,and Alexander C.Berg.Ssd:Single shot multibox detector[J].2016:21-37.
[7]Joseph Redmon,Santosh Divvala,Ross Girshick,and Ali Farhadi.You only look once:Unified,real-time object detection[J].Computer Science,2016:779-788,.
[8]C Szegedy,Wei Liu,Yangqing Jia,et.al.Going deeper with convolutions[J].in IEEE Conference on Computer Vision and Pattern Recognition,2015:1-9.
