在反垃圾邮件技术中贝叶斯算法的应用
2018-06-05
(辽宁广播电视学校本溪分校 辽宁本溪 117000)
自电子邮件被越来越多的人们使用以来,垃圾邮件的问题一直困扰着电子邮件的使用者,人们也找到了很多的解决之道,从早期的关键字匹配,到通过连接频率来提高发送垃圾邮件的成本,再到设立专用服务器,提供RBL实时黑名单查询,直到全世界范围内关于垃圾邮件立法的呼吁。无论哪种方式方法,要想从根本上解除垃圾邮件的泛滥,还是需要一套能够有效防范垃圾邮件的安全技术。
一、垃圾邮件的产生和无法避免的技术原因
垃圾邮件(SPAM) 也称作UCE(Unsoticited Commercial Email.未经许可的商业电子邮件)或UBE(Unsolicited Bulk Email,未经许可的大量电子邮件)。首次关于垃圾邮l件的记录是1985年8月的一封通过电子邮件发送的连锁信,一直持续到1993年6月出现了名为“Make Money Fast 的电子邮件。1994年4月SPAM一词首次出现.当时Canter和Siegel律师事务所把一封信发送到6000多个新闻组,宣传获得美国国内绿卡的法律支持。这时开始,很多商人瓤利用垃圾邮件广告。1995年首个专门用于发送垃圾邮件的程序Floodgate发布,诙程序能够自动地把邮件发送给大批人。同年8月开始出现出售邮件地址的事件。从此,垃圾邮件频频出现.也引起了人们的反感。[1]
当前邮件传输的主要协议是SMTP协议,从设计之初,为了满足简单传输的需要,该协议没有任何认证手段,因此缺省的SMTP邮件服务器对于邮件的来源和目的地不做控制而是支持发送。[2]
随着垃圾邮件的泛滥,大部分的邮件服务器都关闭了OpenRelay,在发送方和发送服务器之间进行认证,从而保证只有合法用户才能使用这台服务器发送邮件,这就是增强的ESMTP协议。然而这个方法无法解决在发送服务器和接收服务器之间的合法认证,垃圾邮件仍然无法避免。[3]
二、贝叶斯过滤技术介绍
1.贝叶斯公式
贝叶斯定理由英国数学家贝叶斯 ( Thomas Bayes 1702-1761 ) 发展,用来描述两个条件概率之间的关系,比如 P(A|B) 和 P(B|A)。按照乘法法则,可以立刻导出:P(A∩B) = P(A)*P(B|A)=P(B)*P(A|B)。如上公式也可变形为:P(B|A) = P(A|B)*P(B) / P(A)。[4]
通常,事件A在事件B(发生)的条件下的概率,与事件B在事件A的条件下的概率是不一样的;然而,这两者是有确定的关系,贝叶斯法则就是这种关系的陈述。作为一个规范的原理,贝叶斯法则对于所有概率的解释是有效的;然而,频率主义者和贝叶斯主义者对于在应用中概率如何被赋值有着不同的看法:频率主义者根据随机事件发生的频率,或者总体样本里面的个数来赋值概率;贝叶斯主义者要根据未知的命题来赋值概率。一个结果就是,贝叶斯主义者有更多的机会使用贝叶斯法则。贝叶斯法则是关于随机事件A和B的条件概率和边缘概率的。[5]
如果事件组A1,A2,……AK为一完备事件组,则对任意事件B(其P(B)≠0)有:
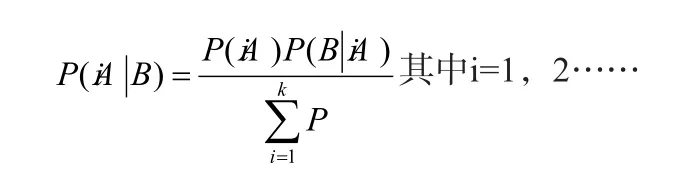
贝叶斯公式实际上是综合利用先验概率和样本信息从而计算后验概率的一种方法。
2.2 贝叶斯算法在反垃圾邮件技术中的应用
首先,我们可以将电子邮件分为正常邮件和垃圾邮件两类,贝叶斯过滤器针对这两类邮件进行自学习。分析每封电子邮件中的每一个单词,确定正常邮件和垃圾邮件中词汇发送频率的差异。
贝叶斯算法分析邮件的工作过程如下:
(1)过滤器收集大量的垃圾邮件和正常邮件,建立垃圾邮件集和正常邮件集。
(2)过滤器提取邮件主题和邮件体中的独立字串。
(3)每一个邮件集对应一个哈希表,hashtable_good对应正常邮件集而hashtable_bad对应垃圾邮件集。表中存储TOKEN串到字频的映射关系。
(4)计算每个哈希表中TOKEN串出现的概率p=(某TOKEN串的字频)/(对应哈希表的长度)
(5)综合考虑hashtable_good和hashtable_bad,推断出当新来的邮件中出现某个TOKEN串时,该新邮件为垃圾邮件的概率。数学表达式为:
A事件……邮件为垃圾邮件;
t1,t2……,tn代表TOKEN串,则P(A|ti)表示在邮件中出现TOKEN串ti时,该邮件为垃圾邮件的概率。
设 P1(ti)=(ti在hashtable_good中的值)
P2(ti)=(ti在hashtable_bad中的值)
则P(A|ti)=P1(ti)/[P1(ti)+P2(ti)];
(6)建立新的哈希表hashtable_probability存储TOKEN串ti到P(A|ti)的映射
(7)至此,垃圾邮件集和正常邮件集的学习过程结束。根据建立的哈希表hashtable_probability可以估计一封新到的邮件为垃圾邮件的可能性。[6]
当新到一封邮件时,按照步骤(2)生产TOKEN串。查询hashtable_probability得到该TOKEN串的键值。
假 设 由 该 邮 件 共 得 到N个TOKEN串,t1,t2……,tn,hashtable_probability中对应的值为P1,P2,……Pn,P(A|t1,t2,t3……tn)表示在邮件中同时出现多个TOKEN串t1,t2……tn时,该邮件为垃圾邮件的概率。由复合概率公式可得:P(A|t1,t2,t3……tn)=(P1*P2*……PN)/[P1*P2*……PN+(1-P1)*(1-P2)*……(1-PN)]当P(A|t1,t2,t3……tn)超过预定阈值时,就可以判断邮件为垃圾邮件。
2.贝叶斯算法的优劣
贝叶斯风险是衡量一个决策法则的好坏的标准。一般来说,多数情况下,对于某一个(或某些)状态θ值,决策法则δ的风险函数值ρ(θ,δ₁)最小;而对于另一个(或另一些)θ值,另一个决策法则δ₂的风险函数最小,因此,评价一个决策法则的好坏,只能用在各种不同状态下其风险函数的平均值来衡量。贝叶斯风脸β(δ)就是当决策法则为δ,在状态θ下风险函数的平均值,决策法则一经确定,其贝叶斯风险即为一常数。它反映出利用这一决策法则决策的平均损失。
因为贝叶斯算法是基于先验概率和样本信息来计算后验概率的方法,所以其对于样本积累的数量具有很大的依赖性,需要一个较长的过程,开始的时候,可能会发生很大的误判和漏判现象,只有当积累的样本数量足够多,其检测精度才能到达一定高度并为用户所接受。
3.结和展望
随着网络成熟,将贝叶斯过滤技术应用到反垃圾邮件技术中,可以说是一种尝试,也是反垃圾邮件技术领域中的一个研究方向。目前,对于贝叶斯技术的应用正在成为反垃圾邮件领域的一个研究热点,越来越多的专用发垃圾邮件产品正在尝试使用贝叶斯过滤技术来提高其产品的检测精度,降低管理成本。
[1]倪加勋,袁卫,应用统计学,北京中国人民大学出版社,1993.
[2]郭泓,电子邮件过滤技术浅析,信息网络安全.2002.
[3]王斌,潘文峰,基于内容的垃圾邮件过滤技术综述,中国科学院计算机技术研究所硕士毕业论文.2004.
[4]托马斯·贝叶斯 .智库[引用日期2013-03-07].
[5]条件概率和贝叶斯定理 .中国开放教育资源联合体[引用日期2013-01-07].
[6]An Essay towards solving a Problem in the Doctrine of Chance. Philosophical Transactions of the Royal Society of London .1763[引用日期2015-03-31].
[7]贝叶斯定理-贝叶斯 .贝叶斯定理.2014-03-21[引用日期2014-03-21].
