基于fastText的中文文本分类
2018-06-04代令令
代令令,蒋 侃
(广西大学计算机与电子信息学院,广西 南宁 530004)
0 引 言
随着互联网的迅速发展,网络已经成为信息传播的主要载体。面对各大网站每天产生的大量新闻数据,如何帮助用户从杂乱的新闻信息中获取有效信息,变得尤为重要。文本分类不仅能对信息进行有效的管理和筛选,而且在网络搜索、信息检索与排名、自动文摘、垃圾邮件过滤和文档分类等方面有着重要的作用[1],同时与自然语言处理相关的人机通信、人工智能等领域,都离不开文本分类技术。文本分类是一个有监督的学习过程,该过程主要包括2个步骤:1)利用数据训练一个最优模型;2)将待分类的数据输入训练好的模型并对输入数据进行判断,输出相应的分类结果[2]。分类结果的准确率反映了分类器的分类精度,在这之前,需要对文本进行表示,将其转化成现有分类算法能够处理的形式[3-4]。目前文本表示方法大多是基于词袋模型(Bag-of-Words,BOW)和向量空间模型(Vector Space Model,VSM)。词袋模型将文本看成词的集合,且词与词之间是相互独立的。它将一篇文档表示成高维度的向量,向量中每个分量的值与该位置所代表的词在文档中出现的次数相等。一篇文档包含的词数越多,则用词袋模型表示的文档向量的维度越高,并且随着新词的增加,文档向量维度也会增加[5]。词袋模型不考虑词的语义和语序,是对文本的一种浅层表示,文本信息损失严重,进而不能进行有效的语义学习,使得文本分类面临着巨大的挑战[6]。为了克服词袋模型不能考虑上下文语义以及维度过高的问题,研究者们开始使用向量空间模型来进行单词的向量表示。Mikolov等人[7]提出了word2vec,它使用深度学习技术,将词转化成词向量,文本内容的处理便转化为向量空间中的向量运算。通过向量空间上的相似度,来表示文本语义上的相似度。唐明等人[5]利用TF-IDF算法计算每篇文档中词的权重,并结合word2vec词向量生成文档向量来进行文档向量表示。后来研究者们又将词向量表示扩展到短语级或句子级表示[8-10]。2014年,Mikolov等人[11]提出了一种可将句子或段落直接转化为固定维度向量的文档表达法“doc2vec”。该方法提出段落向量的概念,是一种无监督学习的算法,它从长度可变的文本片段,如句子、段落和文档中学习固定长度的特征表示。该方法能很好地结合上下文语境、词语和段落中的语义信息,减少忽略语序、词语歧义等问题对分类结果造成的影响。当把文本转换成向量的形式后,就可以利用分类算法进行文本分类的后续工作了。目前文本分类的算法很多,常见的有Naïve Bayes、SVM、KNN、Logistic回归等。
在大数据的时代背景下,已有的文本分类方法训练速度较慢,限制了它们在大规模数据集上的广泛使用,已渐渐不能满足对信息处理的高速要求。因此,迫切需要设计新的方法,在能满足文本分类准确率的同时又能缩短分类时间。标准线性分类器因模型简单,不能很好地表示文本信息,一直被认为不适合进行复杂的自然语言处理。但是Wang等人[12]证明如果选用合适的特征来表示文本,线性分类器不仅能达到较好的文本分类效果,而且能大量缩短训练时间[13]。为了将线性分类器扩展到更多大的数据集上,2016年Facebook AI Research提出了fastText[14],其实验数据显示,通过使用一个标准多核CPU可以在10 min完成对10亿多个单词的训练,并在1 min内将50万个句子分成31.2万个类别。fastText通过使用n-grams,来缩小线性模型和深度模型之间的准确度差距,能够取得与深度学习分类器相近的准确率,并且在训练和评估上要比深度学习分类器快很多[14]。
目前fastText已经有效地应用于英文标签预测和情感分析[14],在情感分析与标签预测这2个方面,fastText获得的性能与最近提出的基于深度学习的方法接近,而且速度更快,但fastText是否能够适用于中文文本分类还有待验证。本文尝试将fastText运用到中文文本分类领域中,并与目前主流的文本分类方法进行对比,从分类准确率和分类时间这2个方面来研究fastText在中文文本分类中的应用效果。fastText源码只能输出总的分类准确率和召回率,本文通过添加统计代码段,细化输出,统计不同种类的文本分类结果。此外,本文还通过对不同参数下fastText模型分类准确率进行分析,希望获得fastText模型参数优化规则,以供以后的研究者借鉴。
1 相关工作
1.1 词的向量化
文本分类的第一步是词的向量化,即把语言中的词转化为机器能够识别的数字形式。常见的向量化方式有以下3种。
1)one-hot representation。
这是词向量化的最初形式,对每一个词用一个很长的向量表示。每一个词向量只有一个分量是1,代表该词在词典中的位置,其余分量全为0,如[0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 …]。这些词的向量组合就是这篇文档的向量表示。这种方法有2个缺点:①不能表达词之间的语义信息;②一篇文档包含很多词,这就导致词典很大。词典的大小就是向量的维度,这样的向量表示不仅稀疏而且高维。
2)Distributed representation(分布式表达)。
Distributed representation是将词映射到低维、稠密的向量空间中,克服了one-hot representation的词向量稀疏和维度过高的缺点,同时可以利用向量计算公式来计算词之间的相似性。
3)word2vec模型。
2013年Mikolov等人[7]提出了word2vec模型来训练词向量,与流行的神经网络模型相比,word2vec模型更加简单,训练出来的词向量质量更高,在准确率、语法和语义的相似性方面有很大的提高。每个词由一个向量表示,通过当前词的前后n个词来预测当前词,同时这个词向量还可以预测上下文中的其他单词。
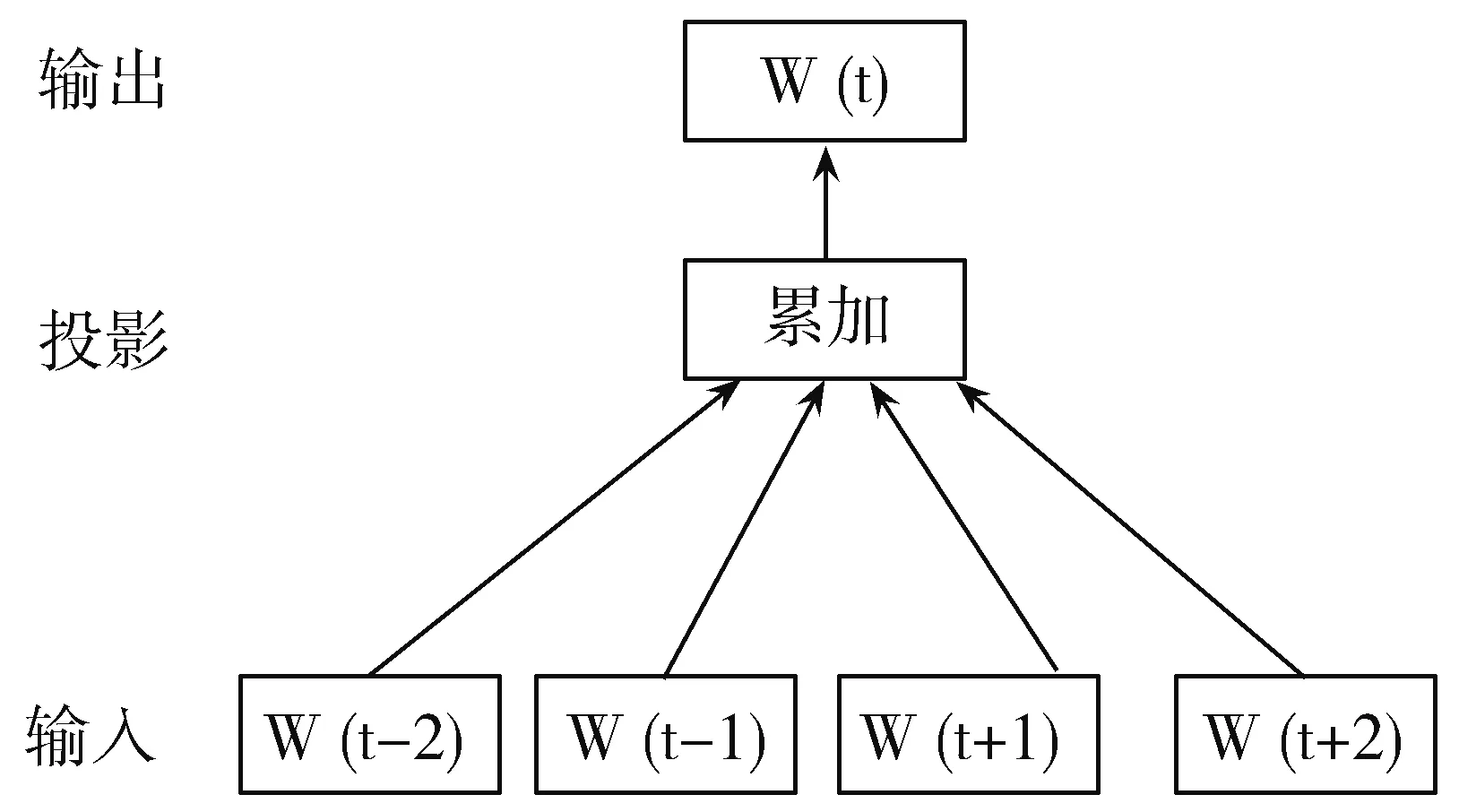
图1 CBOW模型
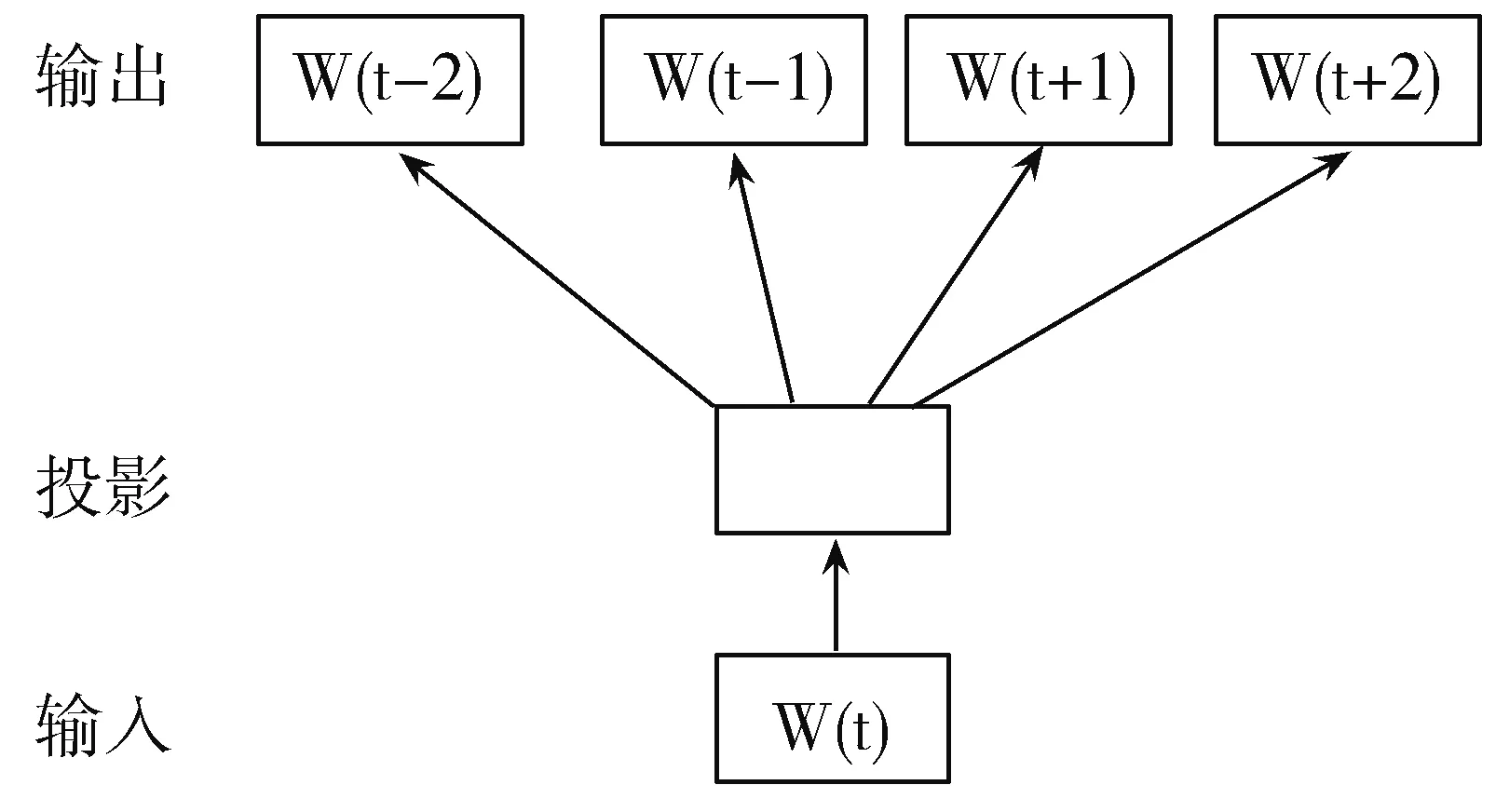
图2 Skip-gram模型
word2vec有2种模型:CBOW(Continuous Bag-of-Words Model)模型和Skip-gram模型。如图1所示,CBOW模型的非线性隐藏层被移除,投影层被共享,所有的词都被投射到同一个位置。输入和投影层之间的权重矩阵被所有的单词位置共享。与BOW模型不同,它使用上下文的连续分布式表示。根据上下文n个词(这里n=2)预测当前词W(t)。如图2所示,Skip-gram模型不是根据上下文来预测当前单词,而是根据同一个句子中的一个单词来最大化另一个单词的分类。更准确地说,它是使用每个当前单词作为一个带有连续投影层的对数线性分类器的输入,并在当前单词前后预测单词的范围。
1.2 文档向量化
许多机器学习算法要求其输入为固定长度的特征向量。当涉及文本时,最常见的固定长度特征表示是使用BOW模型。但是这种文档向量表示法有2个主要的弱点:它们忽略词序和语义。
2014年Mikolov在doc2vec模型[11]中提出了段落向量的概念,它使用无监督算法从可变长度的文本片段,如句子、段落和文档中学习固定长度的特征表示。它将段落向量与一个段落中的几个单词向量连接在一起,并在给定上下文中预测下一个单词。词向量和段落向量都是由随机梯度下降法和反向传播训练的。段落向量在段落中是唯一的,词向量是共享的。它克服了BOW模型的弱点。doc2vec包含2种模型:DM(Distributed Memory Model)和DBOW(Distributed Bag of Words)。
如图3所示,DM模型每个段落都映射到一个唯一的向量,由矩阵D中的一个列表示,每个字也映射到一个唯一的向量,由矩阵W中的一个列表示。段落向量和词向量被平均或者串联在一起来预测上下文中的下一个单词。利用随机梯度下降法对段落向量和词向量进行训练,并通过反向传播获得梯度向量。经过训练后,段落向量可以作为段落的特征来使用,然后用传统的机器学习技术如逻辑回归、支持向量机或K-means进行后续的分类任务。DM模型使用段落向量与单词向量的连接以预测文本窗口中的下一个单词,如图4所示,DBOW模型与DM模型不同,DBOW模型不考虑输入中的上下文单词,在只给定段落向量的情况下,预测一组随机单词。在随机梯度下降的每一次迭代中,采样一个文本,然后从文本中抽取一个随机单词,并在给定段落向量的情况下进行预测。
2 fastText文本分类方法
fastText[14]的模型架构类似于word2vec的CBOW,这2种模型都是基于分层softmax,都是3层架构:输入层、隐藏层和输出层。fastText的模型则是将整个文本作为特征去预测文本的类别。将输入层中的词和词组构成特征向量,再将特征向量通过线性变换映射到隐藏层,隐藏层求解最大似然函数,然后根据每个类别的权重和模型参数构建Huffman树,将Huffman树作为输出。
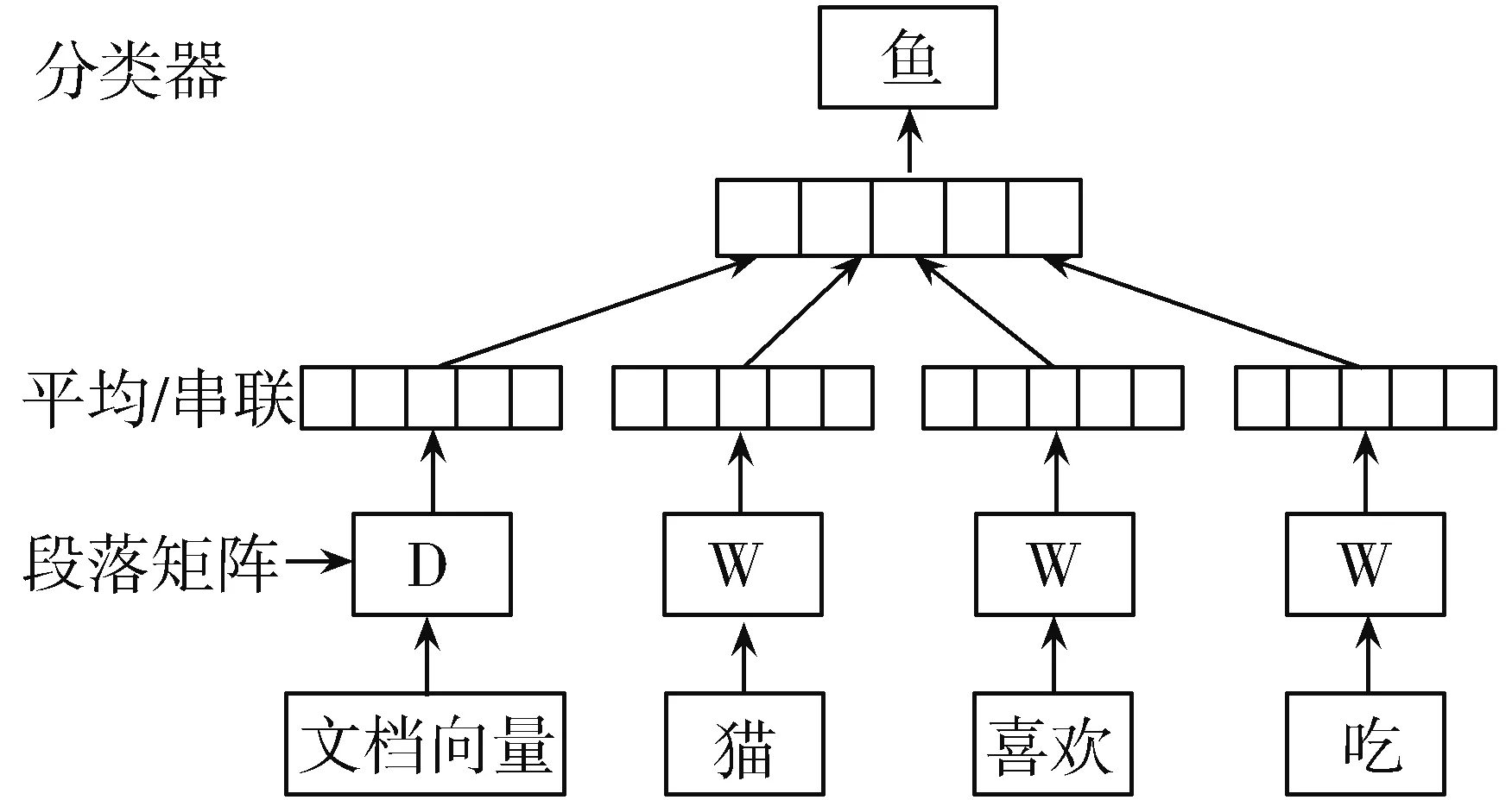
图3 DM模型
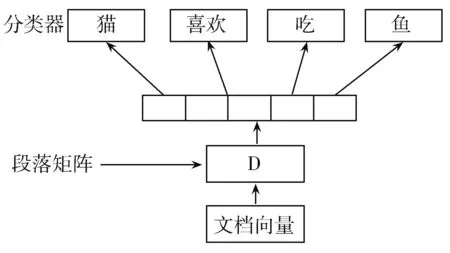
图4 DBOW模型
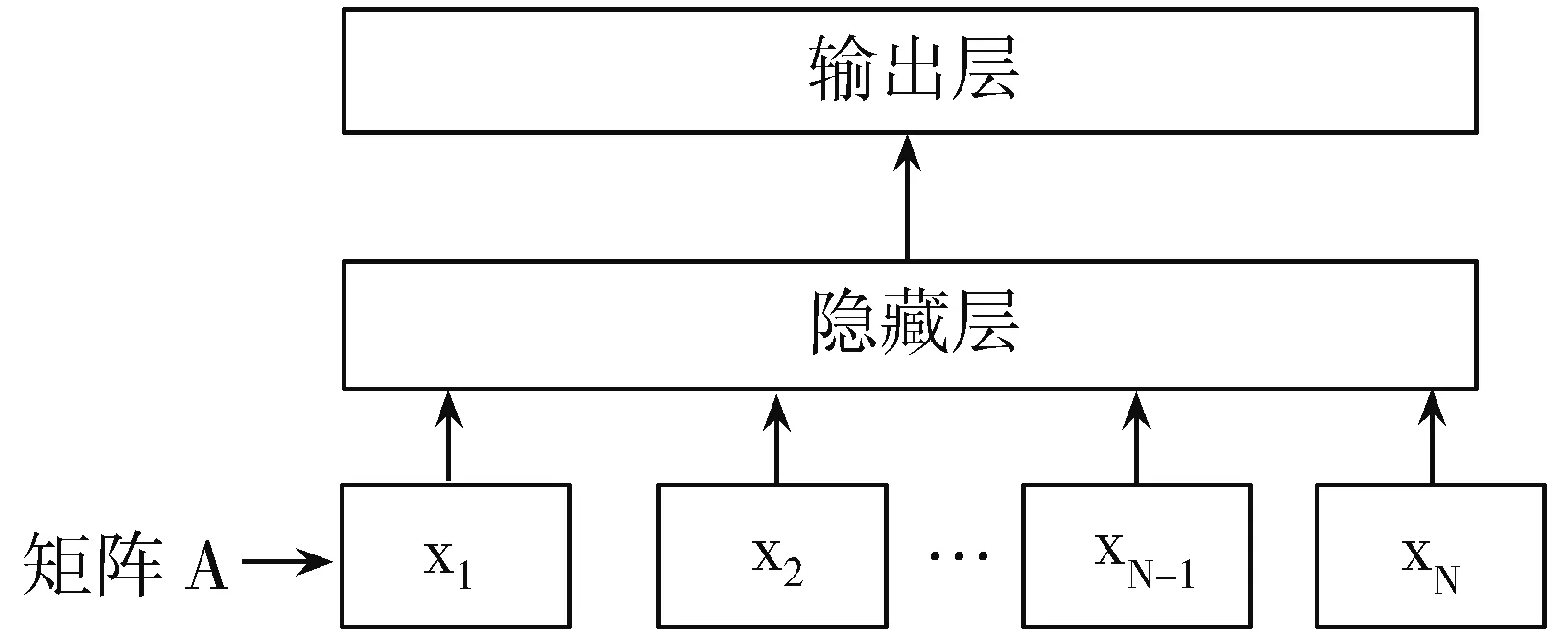
图5 fastText模型架构
图5展示了一个有单个隐藏层的简单模型。第一个权重矩阵A可以被视作某个句子的词查找表。将词表示平均成一个文本表示。文本表示是一个隐藏变量,然后将其送入一个线性分类器。这个构架与word2vec中的CBOW模型类似,区别在于CBOW模型中的中间词(middle word)被替换成了标签(label)。该模型将一系列单词作为输入并产生一个预定义类的概率分布。本文使用softmax函数f来计算预定义类的概率分布,对于一组包含N个文档的文档集,fastText模型目标是使公式(1)最小化。
(1)
其中,xn是第n个文档特征的标准化包[15],yn,A和B是权重矩阵。该模型采用随机梯度下降法和线性衰减的学习速率,在多个CPU上进行异步训练。
2.1 分层softmax
当目标的数量太大时,线性分类器的计算会变得十分昂贵,其计算复杂度是O(kh),其中k是目标的数量,h是隐藏层的维度。为了改善运行时间,fastText使用了一个基于Huffman树[7]的分层softmax。在这个Huffman树中,每一叶子结点代表一个label。根据每个类别出现的次数作为权重来构建Huffman树,出现次数越多的类别的样本,路径就越短,如果该结点的深度是l+1,其父结点是n1,…,nl,那么它的概率是:
(2)
这意味着一个结点的概率总是比它的父结点小。在训练过程中,计算复杂度会下降到O(hlog2(k))。
2.2 n-gram特征
词袋(BOW)模型中的词顺序是不变的,但是直接考虑该顺序的计算成本通常十分高昂。作为替代,fastText使用n-grams袋(bag of n-gram)作为额外特征来获取关于局部词顺序(local word order)的部分信息。
3 实验与分析
3.1 实验数据与实验环境
3.1.1 数据收集
实验数据来自清华大学THUCNews数据集[16],共83万条新闻文本,包括财经、房产、股票、家居、教育、科技、社会、时尚、时政、体育、游戏、娱乐、彩票、星座等14个类。将实验数据划分为2部分,一部分用来作训练数据,另一部分用来做测试数据。Test1和Test2来自测试数据,DS1~DS5来自训练数据。每个数据集的选取情况如表1所示。
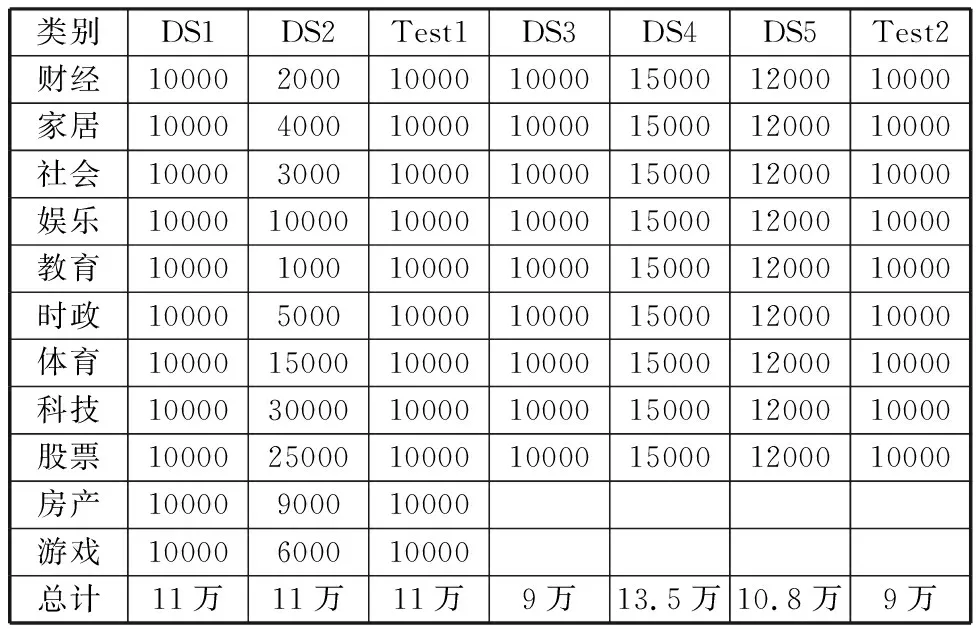
表1 数据集文本数量选取 单位:条
3.1.2 数据预处理
文本自动分词是自然语言处理的基础性工作,本文使用中文分词工具——张华平博士开发的NLPIR汉语分词系统,并且使用Java调用里面的工具包进行中文文本的分词,每个词用空格分割。将分词后的数据处理为,每条新闻文本为一行,每一行的结尾使用“__label__+标签”。
3.1.3 实验环境
实验机器配置为Win7系统,内存8 GB。fastText源码在Mac OS和Linux上发布,本文使用Cygwin在Windows平台上运行类Linux模拟环境。fastText使用C++11标准编写,因此需要一个对C++11支持良好的编译器,本文使用gcc-4.9.3。
3.2 评价方法
本文采用的评估指标包括准确率、召回率和F1值,同时增加实验时间。
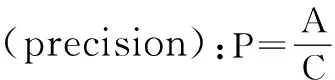
(3)
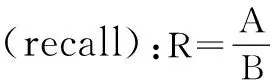
(4)
(5)
其中,A:预测正确的各个类的数目;B:测试数据集中各个类的数目;C:预测结果中各个类的数目。
3.3 实验结果分析
3.3.1 基于fastText的中文文本分类结果
为了验证fastText对中文文本分类的效果,本文使用DS1做训练集,包括67814627个汉字,Test1做测试集,包括62076154个汉字。n-gram使用默认值1,维度使用默认值100,实验结果如表2所示,分类准确率的宏平均值以及所用的时间如表3所示。
表2 数据集DS1的中文文本分类结果
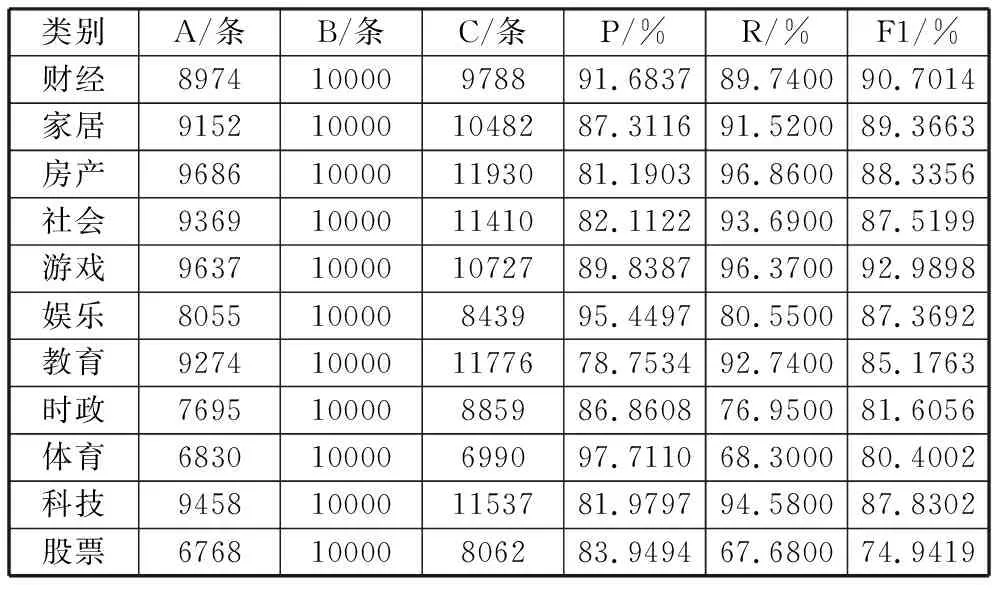
类别A/条B/条C/条P/%R/%F1/%财经897410000978891.683789.740090.7014家居9152100001048287.311691.520089.3663房产9686100001193081.190396.860088.3356社会9369100001141082.112293.690087.5199游戏9637100001072789.838796.370092.9898娱乐805510000843995.449780.550087.3692教育9274100001177678.753492.740085.1763时政769510000885986.860876.950081.6056体育683010000699097.711068.300080.4002科技9458100001153781.979794.580087.8302股票676810000806283.949467.680074.9419
表3 准确率的宏平均值与所用时间

P/%Train/sTest/s86.98553810
由表2和表3可知fastText能在38 s内训练11万条新闻文本,包括67814627个汉字。10 s时间内对11万条包括62076154个汉字的文本进行分类,并输出测试集中11个类的预测结果,以及每个类的分类准确率P、召回率R和F1值。对实验数据只进行分词处理,参数使用系统默认值,没有进行任何调优的情况下,准确率P、召回率R和F1值的宏平均值均达到86%以上,这也说明了fastText快速文本分类方法能有效处理中文文本分类问题。
3.3.2 基于doc2vec的中文文本分类结果
由于在进行中文文本表示时,doc2vec优于其他文本特征表达方式[17],而svm能很好地解决文本分类问题[18],因此本实验使用DS1作为训练数据集,Test1作为测试数据集,使用doc2vec将其转化成文档向量,使用svm作为分类器。实验得到分类准确率为82.9564%,实验所用时间如表4所示。
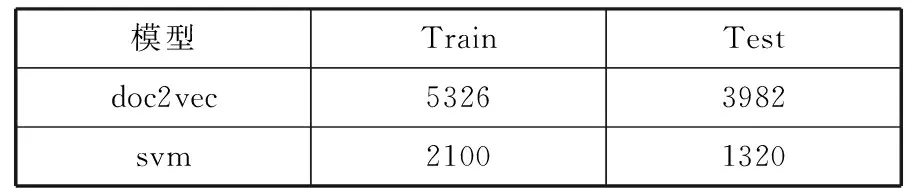
表4 doc2vec+svm所用时间 单位:s
通过分类准确率P和实验所用时间来对比基于fastText的中文文本分类方法和doc2vec+svm这2种方法在中文文本领域的分类效果,对比结果如表5所示。
表5 2种方法的文本分类结果对比
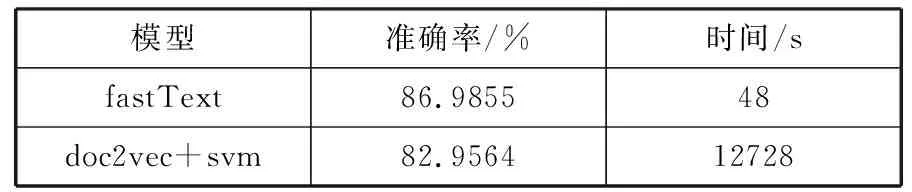
模型准确率/%时间/sfastText86.985548doc2vec+svm82.956412728
由表5可知,fastTest快速文本分类方法和doc2vec+svm的分类确准率,都达到80%以上,但fastText时间上明显减少很多。在大数据背景下,使用fastText来进行文本分类,与目前中文分类领域的主流方法doc2vec+svm相比,能大大缩短文本分类的时间。
3.4 参数优化规则
3.4.1 最小向量维度
一般情况下,分类器越简单,学习的参数的数量就越少,训练分类器的难度就越小,越不适应的风险就越小。假设语料库中有N个段落,词汇表中有M个词,在学习段落向量时,使得每个段落都映射到p维,并且每个词都映射到q维,那么fastText模型的参数总和为N×p+M×q。因此,消除隐层和减少向量的维数,既能提高识别速度,又能提高训练算法的收敛速度。Zolotov等人[19]用正式的代数变换证明,fastText可以被转换成一个更简单的等价分类器。本文通过2组实验来验证fastText在中文文本分类中满足最高分类准确率的最小向量维度。第一组实验训练集采用大小为9万条的数据集DS3,测试集采用Test2,验证了维度分别从1到20,分类准确率的值,结果如图6所示。第二组实验训练集采用大小为11万条的数据集DS1,测试集采用Test1,结果如图7所示,2组实验n-gram值均为默认值1。

图6 数据集DS3不同维度下文本分类效果
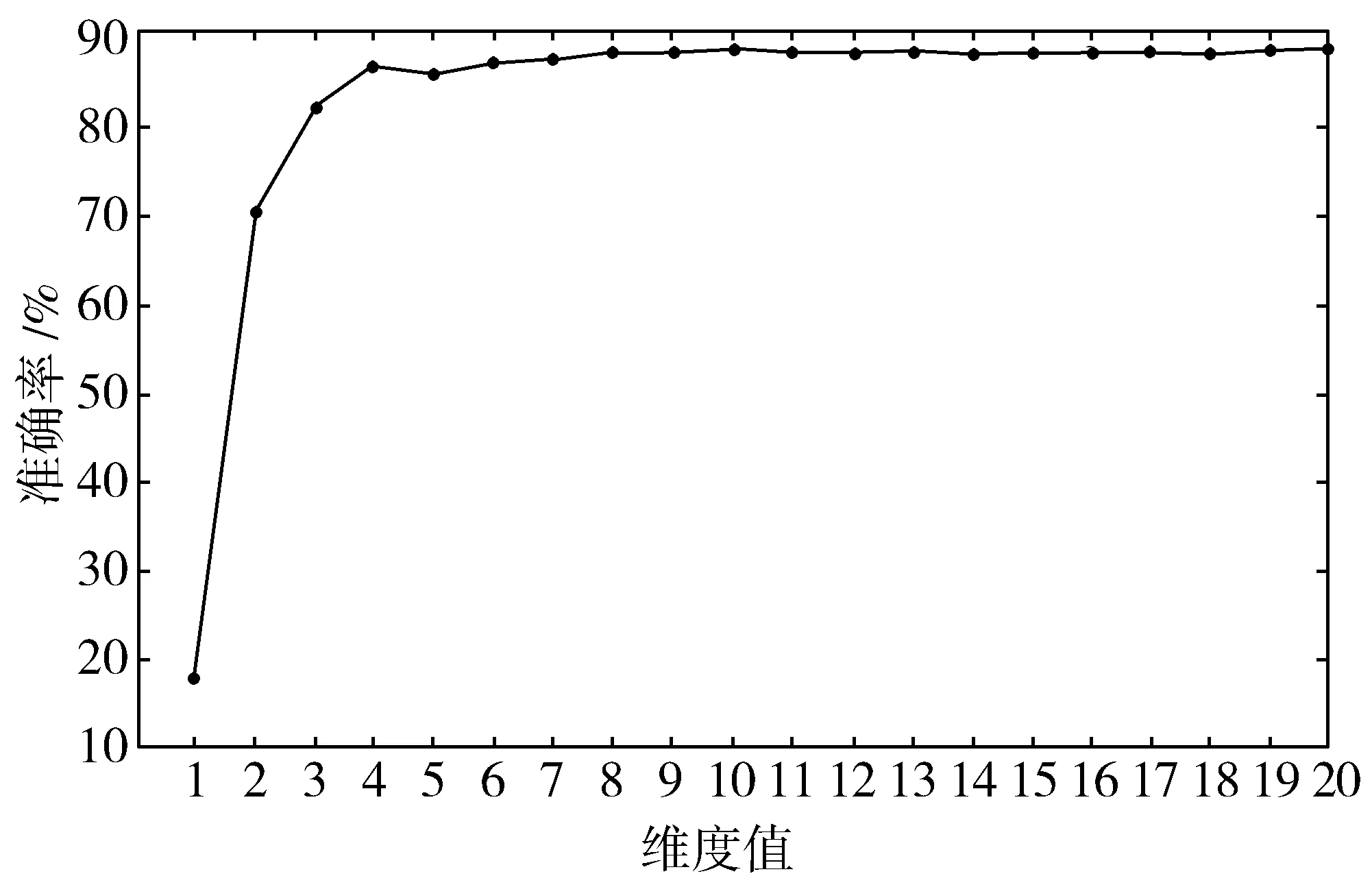
图7 数据集DS1不同维度下文本分类效果
由图6发现,维度值小于数据集文本种类9时,准确率一直在随着维度的增大而增大。当维度达到9时,准确率也达到最大值86.9767%,之后再增大维度,准确率趋于平稳。同理可从图7得出,分类准确率在维度高于数据集DS1文本种类数11时,趋于平稳。由图6和图7可得出,在保证准确率不丢失的情况下,维度的最小值为数据集中包含的文本的种类数。维度值低于数据集的种类数时,分类的准确率将会丢失。增加维度值超出了文档类的数量,不能提高线性分类器的精度。这为以后在中文文本分类中构建模型简单、参数最优的fastText分类模型提供了参考依据。
3.4.2 训练集的大小与准确率的关系
为了提高fastText在中文文本领域的文本分类准确率,获得更好的分类模型,本文接下来将验证测试集的大小对fastText模型训练的影响。实验使用大小为9万条的数据集DS3,10.8万条的数据集DS5和大小为13.5万条的数据集DS4来做训练集训练fastText模型,使用Test2来验证训练集的大小对分类准确率的影响。Test2大小为9万条,数据集的选取情况见表1,实验结果如表6所示。本实验维度值为默认值100,n-gram使用默认值1。
表6 准确率P 单位:%

数据集DS3DS5DS4P86.415689.433391.6044
由表6可知,在测试集大小为9万条的情况下,训练集的大小由9万条增大到10.8万条时,分类准确率由86.4156%增大到89.4333%。当训练数据集增大到13.5万条时,分类准确率增大到91.6044%。由于数据集大小的限制,在测试集大小为9万条的情况下,目前所能使用的训练集最大为13.5万条,相比于9万条的训练集,分类准确率由86.4156%上升到91.6044%,提高了6%。因此,将来在数据集大小能够满足的情况下,希望能找到在测试集大小一定的情况下,使准确率达到最高的训练集的大小。
3.4.3 最佳n-gram值
为了获得更高的分类准确性,fastText使用n-grams作为附加功能来获取单词顺序的部分信息,每个字都表示成一个字符n-gram袋。“我爱她”这句话中的词袋模型特征是“我”、“爱”、“她”,这些特征和句子“她爱我”的特征是一样的。如果加入2-gram,第一句话的特征还有“我-爱”和“爱-她”,这2句话“我爱她”和“她爱我”就能区别开来了。为了验证n-gram大小对中文文本分类的影响,本次实验训练集使用DS3,测试集Test2在不同n-gram下测试fastText在中文文本分类的准确率,维度值使用模型默认值100,结果如图8所示。
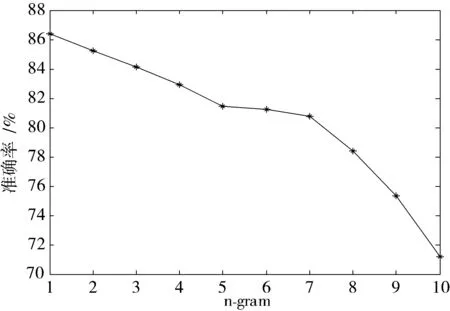
图8 n-gram值与准确率的关系
由图8可知,n-gram值为1可以达到最佳性能,随着n-gram值的增大,准确率一直在下降。这是因为,fastText将长词再通过n-gram切分为几个短词。由于中文的词大多比较短,这对英文语料的用处会比中文语料更大,在中文领域并没什么优势。同时在实验中发现随着n-gram值的增大,所用时间越来越长,因此,n-gram值为1时fastText在中文文本分类中的效果最好。
4 结束语
针对目前中文文本分类方法在处理大规模数据时用时较长的问题,本文引入fastText,探讨其在中文文本分类领域的适用性,进一步探究在保证分类精度不丢失的情况下,构建等价简单分类器的最小维度值,以及提升分类准确率的参数优化规则。
研究发现,相对于doc2vec+svm,fastText能达到与其相近的准确率,且文本分类准确率、文本分类速度大幅度提升,表明fastText对中文文本分类具有较好的适用性。实验结果显示n-gram值为1时,使用n-gram袋作为额外特征来获取中文词序信息效果最好。在测试数据集大小一定的情况下,增大训练数据集的大小超过测试集,分类准确率会在一定范围内上升。另外,实验表明,fastText在中文文本分类领域存在保证分类准确率最大的最小向量维度,该维度值等于数据集中包含的文本种类数。当增加向量的长度超出文档类的数量时,不能提高fastText分类器的精度。这些结论有助于在保证最大的分类准确度的同时,构造更优的线性文本分类器,降低了训练分类器的难度,同时又能提高训练算法的收敛速度。
参考文献:
[1] 夏从零,钱涛,姬东鸿,等. 基于事件卷积特征的新闻文本分类[J]. 计算机应用研究, 2017(4):991-994.
[2] 石文娟,龙舜,云飞. 基于背景学习的迭代式文本分类框架[J]. 计算机工程与应用, 2015,51(9):129-134.
[3] Debole F, Sebastiani F. Supervised term weighting for automated text categorization[M]// Text Mining and Its Applications. Springer Berlin Heidelberg, 2004:81-97.
[4] Sebastiani F. Machine learning in automated text categorization[J]. ACM Computing Surveys (CSUR), 2002,34(1):1-47.
[5] 唐明,朱磊,邹显春. 基于Word2Vec的一种文档向量表示[J]. 计算机科学,2016, 43(6):214-217.
[6] 闫琰. 基于深度学习的文本表示与分类方法研究[D]. 北京:北京科技大学, 2016.
[7] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. Computer Science, 2013: arXiv:1301.3781.
[8] Mitchell J, Lapata M. Composition in distributional models of semantics[J]. Cognitive Science, 2010,34(8):1388-1429.
[9] Zanzotto F M, Korkontzelos I, Fallucchi F, et al. Estimating linear models for compositional distributional semantics[C]// Proceedings of International Conference on Computational Linguistics. 2010:1263-1271.
[10] Yessenalina A, Cardie C. Compositional matrix-space models for sentiment analysis[C]// Conference on Empirical Methods in Natural Language Processing. 2011:172-182.
[11] Le Q, Mikolov T. Distributed representations of sentences and documents[C]// Proceedings of the 31st International Conference on Machine Learning. 2014:1188-1196.
[12] Wang S, Manning C D. Baselines and bigrams: Simple, good sentiment and topic classification[C]// Meeting of the Association for Computational Linguistics. 2012:90-94.
[13] Agarwal A, Chapelle O, Dudik M, et al. A reliable effective terascale linear learning system[J]. Journal of Machine Learning Research, 2011,15(1):1111-1133.
[14] Joulin A, Grave E, Bojanowski P, et al. Bag of tricks for efficient text classification[J]. Computer Science, 2016: arXiv:1607.01759.
[15] Bojanowski P, Grave E, Joulin A, et al. Enriching word vectors with subword information[J]. Computer Science, 2016:arXiv:1607.04606.
[16] 孙茂松,李景阳,郭志芃,等. THUCTC:一个高效的中文文本分类工具包[DB/OL]. http://thuctc.thunlp.org, 2016-01-25.
[17] 杨宇婷,王名扬,田宪允,等. 基于文档分布式表达的新浪微博情感分类研究[J]. 情报杂志, 2016,35(2):151-156.
[18] 吕超镇,姬东鸿,吴飞飞. 基于LDA特征扩展的短文本分类[J]. 计算机工程与应用, 2015,51(4):123-127.
[19] Zolotov V, Kung D. Analysis and optimization of fastText linear text classifier[J]. Computer Science, 2017:arXiv:1702.05531.
