基于Docker的MPI和OpenMP混合编程
2018-06-04赵博颖
赵博颖,肖 鹏,张 力
(中国航天科工二院706所,北京 100854)
0 引 言
随着信息技术的蓬勃发展,单个处理器的运算速度以及传统的串行算法已经难以满足人们对于大量数据处理的需求。在这种背景下,并行计算机及其并行计算技术逐渐成为人们关注的热点。而且,利用高速通信网络将几台计算机连接成一个整体构成集群已经成为构建高可用并行计算机的一种趋势。但是搭建集群并行处理系统需要若干台计算机且集群配置过程复杂耗时,文献[1-2]给出了传统物理机搭建集群的方法,硬件要求较高而且配置复杂。本文针对这个问题,采用轻量级虚拟化技术Docker来搭建集群并行处理系统。Docker是一种轻量级的虚拟化技术,凭借对系统资源的低占有率,它可以兼顾系统应用的性能以及系统的开销,而且Docker容器的启动和关闭能够在几秒内实现,速度非常快,可以很好地满足搭建并行编程环境的要求[3]。同时,本文中主要介绍了并行计算的2种模型:消息传递模型(Message Passing Interface,MPI)和共享内存模型(OpenMP)。这2种模型各有特点,而且在一定程度上可以互补。MPI常用于分布式存储系统中,它将通信和计算优化完全分离,通过MPI库实现节点间的通信,可扩展性好;OpenMP常常用于共享存储系统上,通信速度较快,执行效率较高。将两者结合在一起,采用两级并行的方式,在一定程度上可以提高并行系统的效率。近年来已经有许多学者在矩阵乘法的并行程序设计方面做了大量工作。文献[4-5]介绍了并行系统上矩阵乘法的MPI实现,但该算法由于自身通信模式的限制不能完全发挥并行环境中各个节点本身独立的性能。本文基于矩阵乘法的算法设计并实现一种基于MPI和OpenMP的混合编程模型,并在基于Docker搭建的并行编程环境上进行算法验证以及性能对比。
1 关于Docker
Docker是一个开源的应用容器引擎,在Linux Container(LXC)项目的基础上发展而来,它的目的是进一步优化对容器操作的使用体验[6]。它可以将应用和它的依赖软件包等打包封装为一个轻量级并且可移植的容器。而且,一个容器可以等同于一台虚拟机,它可以只包含一个应用,也可以存在独立的操作系统[7]。而且,Docker包含多种容器管理工具可供使用,不需要深入底层就能够很容易地使用并管理容器。
传统的虚拟机方式决定了如果想运行多个不同的应用就需要创建多个虚拟机,而Docker技术仅仅需要创建几个相隔离的容器,然后把应用放入容器中即可[8]。这个过程基本不消耗额外的系统资源,可以在保证应用性能的同时尽量减小系统开销。这也使得Docker技术在搭建开发环境等很多应用场景下都具有巨大的优势。图1给出了Docker和传统虚拟化技术的区别。
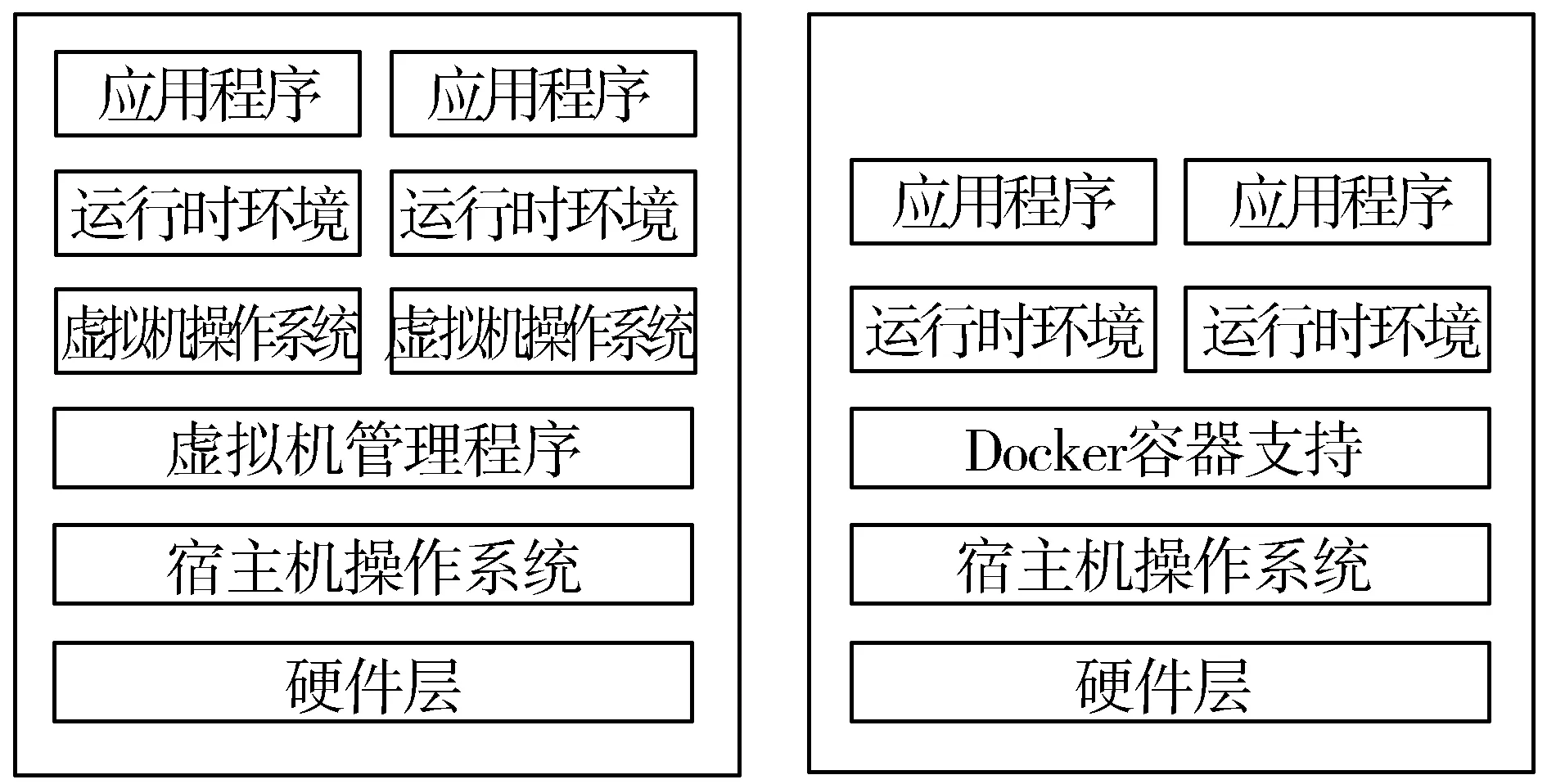
图1 传统的虚拟化方式和Docker的不同
Docker容器技术中主要有镜像、容器、数据卷以及网络这4大核心模块[9],如图2所示。使用Docker可以通过镜像来快速构建一套标准的并行开发环境,开发完成后,Docker可以快速创建和删除容器,实现快速迭代,很大程度上节约了开发、部署和测试的时间[10]。可见,Docker技术在小型集群的搭建以及并行任务的测试等方面会大有可为。
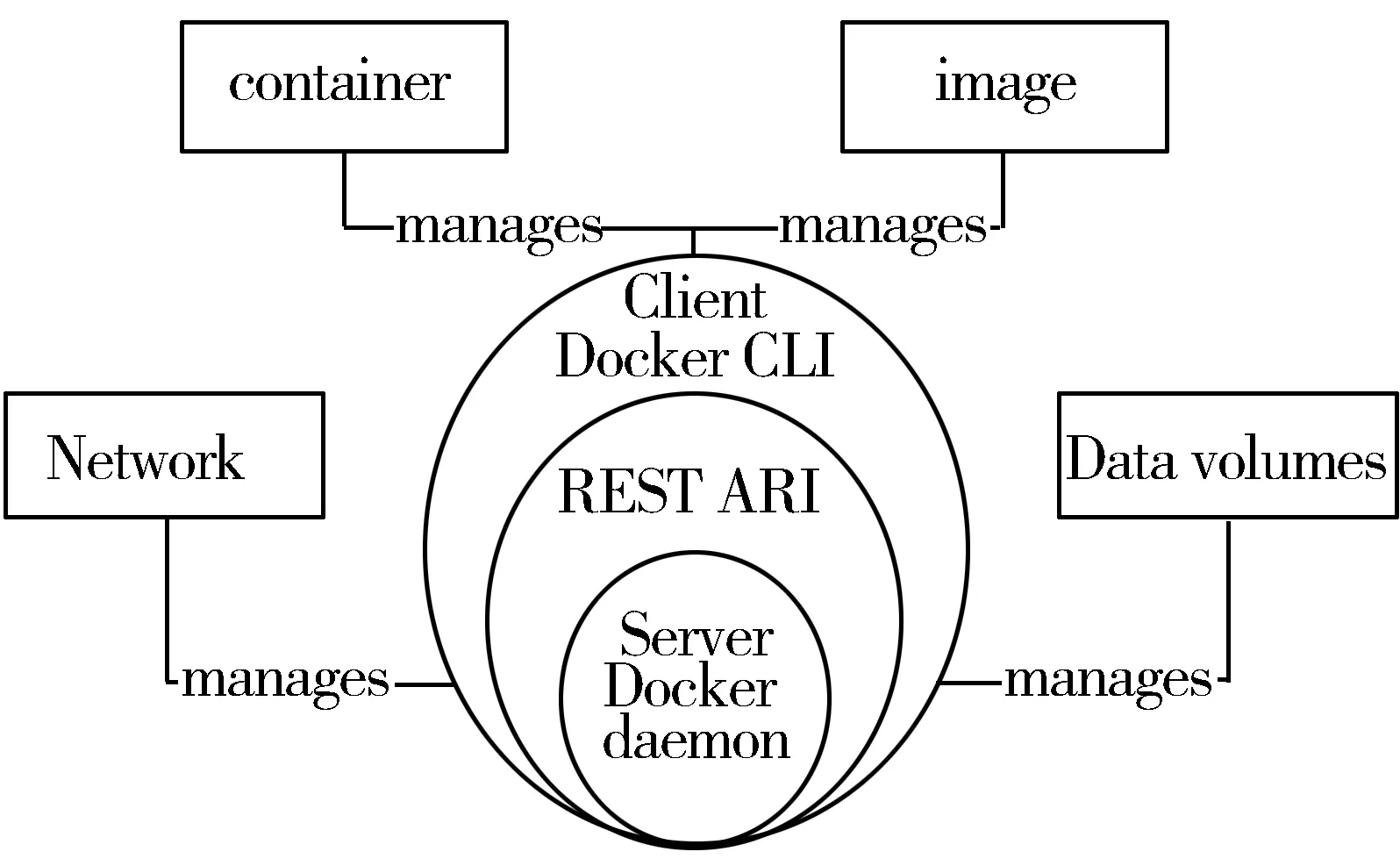
图2 Docker的体系结构
2 矩阵乘法算法的设计实现
2.1 基于Docker的集群并行环境构建
集群并行开发环境的构建在64位Ubuntu平台上完成。主要包括以下几个步骤:安装Docker;创建3个容器作为3个虚拟节点,制作并行环境MPI的镜像文件;在每个节点上安装安全协议SSH并设置各个节点免密码登录。
2.1.1 Docker环境的构建
目前,Docker在主流的操作系统和云平台上都可以使用,其中包括Windows、MacOS、Linux操作系统以及AWS云平台。同时,Docker仅支持64位操作系统。除此之外,对于Linux系统而言,要确保Linux内核版本在3.10以上,这是因为Docker所需的一些功能在3.10版本之前是缺失的,可能会造成数据的丢失。本文选择64位Ubuntu系统,内核版本为4.4.0,系统版本为14.04LTS来安装Docker。
在安装Docker之前,首先安装需要的软件包linux-image-extra-virtual以及linux-image-extra-$(uname -r),这2个软件包保证我们可以使用AUFS storage driver、storage driver实现多层数据的堆叠并为用户提供一个合并后的统一视图。这种分层结构可以使容器和镜像的创建、分发以及共享变得更加高效。然后添加Docker的官方GPG密钥来确认所下载软件的合法性,添加成功后,更新apt软件包索引,执行以下命令就可以安装最新版本的Docker:
$ sudo apt-get install docker-ce
2.1.2 MPI并行环境的构建
目前,国际上已经出现很多MPI的实现方式,比如MPICH、OpenMPI、LAM等。这里选择OpenMPI来实现MPI并行。OpenMPI是基于LAM/MPI、LA-MPI以及FT-MPI的一种采用构件思想的MPI实现,它提供了一些MPI实现方式无法达到的独特的组合方法,它也是MPI-2标准的一个开源实现。
Docker Hub是Docker默认的镜像仓库,提供了数十万个镜像可供开放下载。在这里通过docker pull hmonkey/openmpi14.04:v3命令直接下载Docker Hub中已经存在的MPI镜像hmonkey/openmpi14.04:v3。利用Docker在Ubuntu上启动3个虚拟节点,以主节点为例,其他节点与主节点命令一致。
$ sudo docker run -itd --name master--privileged=true hmonkey/openmpi14.04:v3/bin/bash
通过以上命令可以得到3个基于Docker的虚拟节点:master,cluster1,cluster2。
在并行计算中,任务被分割成并行的几个部分分配到各个计算节点中,计算节点之间的无密码访问可以使计算进程在并行计算机之间自由跳跃,从而提高并行计算的效率。因此需要在3个虚拟节点上均安装安全协议SSH,并设置各个节点免密码登录。
2.2 矩阵乘法算法的并行实现
矩阵乘法运算是一种很重要的数值运算,广泛应用于数值分析以及线性代数中,它是一种最基本的运算,很多科学问题的基础都是矩阵[11]。在这里,采用矩阵乘法来测试并行计算的性能,介绍基于MPI和OpenMP的混合并行编程模型,同时基于该模型设计矩阵乘法的并行实现。
2.2.1 MPI和OpenMP的混合并行编程模型
MPI是一种被广泛用于分布式存储并行计算机的编程环境,它作为一种并行程序设计方法已经被广泛应用于高性能并行计算环境中[12]。但在某些情况下,单一的MPI消息传递编程模型不能很好地满足多处理器集群并行计算的需求。OpenMP是一种基于共享存储体系结构的编程标准,作用在共享内存的计算节点上[13]。对于同时具备节点内共享内存和节点间分布式内存的多处理器集群,需要MPI+OpenMP的混合编程模型,在计算节点内使用OpenMP多线程化,在计算节点之间采用MPI消息传递,通过两级并行的方式,有效提高并行计算的效率[14]。
MPI和OpenMP混合模型主要包括2种方式:一种是主进程通信方式,另外一种是线程通信方式[15]。主进程通信方式是指MPI控制进程间通信,调用发生在OpenMP并行区域之外,OpenMP主要完成并行程序中的主要计算。在这种模型中,首先初始化MPI进程,各个节点上的MPI进程进行节点间的通信或独立做一些计算,当遇到大量计算时,就需要用到OpenMP多线程求解[16],求解结束后,MPI进程继续进行节点内的计算以及节点间的同步、通信等,直到进程结束,如图3所示。线程通信方式是指MPI调用发生在OpenMP并行区域之内。在这种模型中,进程间的通信由线程来完成,而且在一些线程进行通信的同时,其他线程可以同步进行并行程序的计算,是一种更为灵活的混合编程方式[17]。

图3 主进程通信方式
2.2.2 基于MPI和OpenMP的混合并行矩阵乘法算法实现
基于MPI和OpenMP混合并行矩阵乘法算法的实现主要包括2个部分,一个是消息传递模型MPI的实现,一个是共享内存模型OpenMP的实现。
以往的基于MPI的并行矩阵乘法大多将矩阵A按行或列分解,矩阵B发送到各个进程不作处理,大大降低了并行计算的效率。本文提出一种基于域分解思想的矩阵并行算法。首先将矩阵A按照进程个数依行分解,矩阵B依列分解;重新分发分解后的矩阵B,保证矩阵A中的每个任务得到矩阵B中相应的部分;每个任务完成各自部分的矩阵乘法;最后将每个任务规约求和的结果返回矩阵C。
基于OpenMP的并行算法主要包括2类:一类是OpenMP细粒度并行,一类是OpenMP粗粒度并行。在OpenMP细粒度并行中,需要在包含大部分计算量的循环部分加入编译制导语句,程序的其他部分不作处理;在OpenMP粗粒度并行中,编译制导语句在程序的最外层,在程序开始时生成多个线程,通过线程的调配来完成并行计算。但粗粒度并行的程序较为复杂,而且通信和调度的开销较大,故本文选择OpenMP细粒度并行。
本文设计实现的基于MPI和OpenMP混合并行矩阵乘法算法的主要思想是采用MPI内嵌OpenMP的方法,在模型外层,采用MPI进程控制通信,完成大粒度的并行;在模型内层,使用OpenMP工作共享结构并行,选择计算时间占程序运行总时间比例大的循环进行并行化,将MPI分配给各个节点的任务细化分给每个节点的多个CPU或多核处理器中的每个核心,对于一些循环次数较少的循环还是串行执行,完成细粒度的并行。在该混合模型中,MPI进程的通信与OpenMP计算部分不发生重叠。算法的伪代码如下:
BEGIN:
MPI_Init(&argc,&argv); //初始化MPI进程通信
MPI_Comm_size(MPI_COMM_WORLD, &size); //获取设置的进程个数
MPI_Comm_rank(MPI_COMM_WORLD, &rank); //自动获取进程编号
if rank==0 then
random(); //主进程随机生成矩阵A和B
scatter();//主进程向其他进程发送矩阵A和B的分块
else
for k from 0 to size-1 do
MPI_Recv(); //其他进程接收来自主进程发送的矩阵分块
omp_set_num_threads(t); //设置线程数
#pragma omp parallel for schedule(static) private(i,j,m) //多线程并行计算各个分块矩阵
matrix_C+=matrix_A*matrix_B
end{for}
end{if}
if size>1 then
MPI_Gatherv(); //将每个进程的计算结果汇总到矩阵C
end{if}
MPI_Finalize();//结束MPI并行计算
END
3 性能测试与分析
3.1 并行环境的运行与算法测试
矩阵乘法算法的测试在基于Docker搭建的并行环境下进行。主要过程如下:
1)开启已存在的容器master,cluster1,cluster2。以master为例:
# docker start master
2)进入正在运行的3个容器,内容如下:
# docker exec -itd master /bin/bash
3)进入包含矩阵乘法程序的文件夹下,对程序进行编译得到可执行文件main:
#mpic++ -o main main.cpp -fopenmp
4)将可执行文件main分别复制到其余2个计算节点的相同位置上。同时,在主节点master上创建hostfile,在hostfile文件中配置其余2个计算节点的IP地址。
5)测试矩阵乘法得到实验结果,内容如下:
# mpirun -np 2 -hostfile hostfile ./main
3.2 混合并行计算与MPI和OpenMP并行计算的性能对比
算法的验证实现在64位具有4片处理器的Ubuntu操作系统上完成,在Ubuntu系统上基于Docker创建3个节点,一个作为主节点,其他2个作为计算节点。在单独MPI程序中设置启用2个进程,在单独OpenMP程序中设置启用2个线程,在MPI+OpenMP的混合程序中,设置启用2个进程、2个线程。矩阵的大小分别设为100×100、800×800、1600×1600,共测试3组数据,考虑到误差原因,每组数据测试3次取平均值。这里通过加速比来定义并行的优化效果,加速比表示并行前程序的运行时间与并行后程序的运行时间的比值。表1为矩阵乘法串行计算和并行计算的测试结果。

表1 矩阵乘法不同算法的性能对比 单位:s
从表1可看出,设置2个进程或线程分别执行程序时,MPI和OpenMP均有明显的并行效果,加速比接近于2。整体上OpenMP的加速比要略高于MPI,这是因为MPI需要进行节点间的相互通信,会增加一些时间损耗。另一方面,混合编程模型具有更优的并行性能以及更高的加速比,这是因为MPI+OpenMP混合程序中,节点之间,主进程只需要通过MPI将数据传递给其他节点的进程,不需要进行节点内部的数据分配计算等工作;而在节点内部,采用OpenMP进行数据的再分配,执行包含大部分计算量的循环部分,而且线程间的通信非常容易,执行效率较高。通过这种两级并行的方式,可以充分发挥MPI和OpenMP的并行优势,从而达到更好的并行效果及更高的加速比。
3.3 基于Docker的并行系统与传统物理机集群并行效果对比
本文使用的传统物理机并行系统选择基于银河麒麟的国产化并行系统。该并行系统采用64位高性能银河麒麟安全操作系统,具有稳定、可靠、易于使用、管理简单等特点。包含1个管理节点和2个计算节点,每个计算节点含有2个8核微处理器,计算节点间通过高速千兆以太网连接。并行系统中,编译系统的MPI遵循MPI-2.0标准,同时支持最新的OpenMP API3.0标准。表2给出了基于Docker的并行系统与传统并行系统的并行效果对比。均选择MPI+OpenMP混合编程模型。
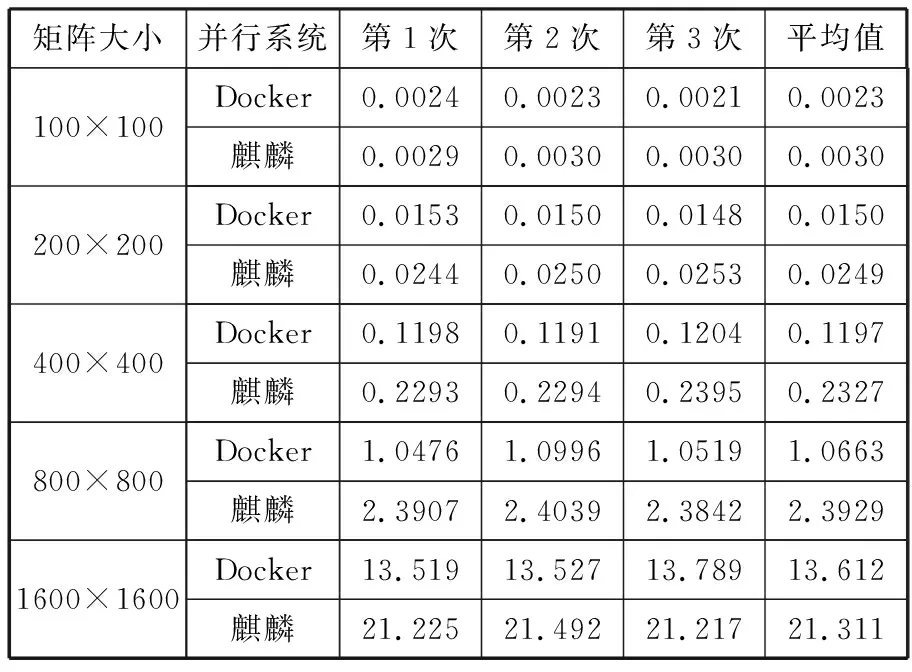
表2 2种并行系统的性能对比 单位:s
从表2可以看出,当矩阵规模较小时,两者的并行效果相差不大,随着矩阵规模的增大,基于Docker的并行系统的并行效果会明显优于基于银河麒麟的并行系统。可见,在一些简单环境搭建与部署并行系统以及并行测试中,Docker技术凭借其独有的优势会有很大作为。
4 结束语
本文首先介绍了轻量级虚拟化技术Docker的基本概念与优势,就现今采用传统物理机搭建集群并行处理系统存在配置复杂以及硬件要求苛刻等问题,提出采用Docker搭建集群并行编程环境,并通过矩阵乘法并行算法来测试。比较了基于Docker的并行系统与传统物理机集群的并行效率,结果显示基于Docker的并行系统具有更好的并行效果。简要阐述了并行编程模型的分类与适用场景,并详细介绍了MPI和OpenMP编程模型,通过对矩阵乘法算法的讨论验证了MPI和OpenMP混合编程的效率。MPI和OpenMP混合编程通过两级并行的方法,可以充分发挥消息传递模型和共享内存模型的优势,有效提高了并行计算的效率。
参考文献:
[1] 希润高娃. 基于PC集群的MPI并行环境的搭建[J]. 网络安全技术与应用, 2012(4):48-50.
[2] 王长安. 基于Linux的PC集群搭建及其性能分析[J]. 电子技术与软件工程, 2014(2):190-191.
[3] 苗立尧,陈莉君. 一种基于Docker容器的集群分段伸缩方法[J]. 计算机应用与软件, 2017,34(1):34-38.
[4] 姚玉坤,丁冬. 并行计算系统中的矩阵乘算法及其MPI实现[J]. 数字通信, 2011,38(1):52-56.
[5] 黄九梅,吕翔,赵英. MPI下矩阵相乘的实现与分析[J]. 中国科技信息, 2007(13):263-264.
[6] 马晓光,刘钊远. 一种适用于Docker Swarm集群的调度策略和算法[J]. 计算机应用与软件, 2017,34(5):283-287.
[7] 卢胜林,倪明,张翰博. 基于Docker Swarm集群的调度策略优化[J]. 信息技术, 2016(7):147-151.
[8] 卫彪,刘成龙,郭旭. 深入浅出Docker轻量级虚拟化[J]. 电子技术与软件工程, 2016(10):252.
[9] 刘思尧,李强,李斌. 基于Docker技术的容器隔离性研究[J]. 软件, 2015,36(4):110-113.
[10] Merkel D. Docker: Lightweight Linux containers for consistent development and deployment[DB/OL]. http://www.th7.cn/system/lin/201405/57068.shtml, 2014-05-20.
[11] 韩建勋. 并行计算在矩阵运算中的应用[J]. 信息与电脑, 2017(5):93-96.
[12] 张艳华,刘祥港. 一种基于MPI与OpenMP的矩阵乘法并行算法[J]. 计算机与现代化, 2011(7):84-87.
[13] 陈树敏,罗俊博,陈青. 并行计算技术的几种实现方式研究[J]. 计算机技术与发展, 2015(9):174-177.
[14] 孙秋实,王移芝. MPI+OpenMP混合并行编程的分析[J]. 现代计算机, 2014(12):7-11.
[15] 唐兵,Bobelin L,贺海武. 基于MPI和OpenMP混合编程的非负矩阵分解并行算法[J]. 计算机科学, 2017,44(3):51-54.
[16] 于朋. 多线程并行快速求解Pi的方法[J]. 电子技术与软件工程, 2016(15):208-209.
[17] Xu Ying, Zhang Tie. A hybrid open MP/MPI parallel computing model design on the SM cluster[C]// 2015 6th IEEE International Conference on Power Electronics Systems and Applications. 2015.
