针对快速排序改进的一些思考及其实现
2018-06-01李一达黄维通
李一达,黄维通
(1.清华大学 物理系,北京 100084;2.清华大学 计算机系,北京 100084)
0 引 言
计算机程序设计基础课程从算法设计的角度出发,包含冒泡排序、选择排序、插入排序、希尔排序、快速排序、归并排序等最基本、最常用的排序算法,提供解决排序问题的多元化思路;对快速排序适当拓展,介绍多种选取基准元素的方法,同时说明快速排序的问题——基准元素的选取直接决定排序的效率。
之所以基于快速排序进行改进,是因为相对其他基于比较的排序算法,快速排序效率较高并被广泛应用,STL(standard template library)的sort函数就建立在快速排序的基础上。快速排序最主要的问题在于不管用什么方法选取快速排序的基准元素,总会有使其时间复杂度退化到O(n2)的情况出现。为了减少这种不利情况对排序效率的影响,STL的解决方案是当快速排序的递归深度超过某个阈值时,改用堆排序,从而保证时间复杂度仍为O(nlb(n))(本文中lb均代表以2为底的对数)。
针对快速排序的上述问题,有许多跳出快速排序基于比较这一限制的改进方法。文献[1]提出的高效快速排序,以待排序元素的平均值作为划分的基准元素以实现较为均匀的划分。文献[2]的超快速排序实质上是二进制整数的基数排序,不再受划分不均的影响。
1 几种排序算法效率分析
文献[1]提出的高效快速排序用待排序元素的平均值代替随机选取的基准元素,在大部分情况下保证了均匀的划分,但是此算法在比较、交换操作之外增加了大量加法运算(每次划分前计算待排序元素的平均值),nlb(n)次的加法运算必定会使整体的效率有所下降,预期结果就是在快速排序选择基准元素较合适的情况下高效快速排序更慢。此外,依然有导致此算法划分极不均匀的特例。例如,待排序的序列为{1,10,100,1 000,10 000,100 000},每次用平均值作为基准元素,会使划分极其不平均,从而高效快速排序退化到冒泡排序。高效快速排序可以较好地解决快速排序划分不均匀问题,但是在提高排序效率方面还有较大提升空间。
文献[2]提出的超快速排序是采用快速排序划分方法的二进制基数排序,划分的均匀与否不再是影响排序效率的因素,而基数排序的本质也保证了较高的排序效率,但是排序前,浮点数要转化为整数,并且负数要单独处理,这使得超快速排序适用范围较窄。
快速二分排序虽然不源于对以上两种算法的思考,但是能够较好地解决以上两种算法存在的问题,使快速排序效率提升明显。
2 快速二分排序
快速二分排序算法描述:在排序开始前找出待排序元素的最小值和最大值,每次以两者的平均值(取整;对浮点数保留到最末位)作为基准元素进行划分,并以此平均值作为划分出的两个子序列新的最小值或最大值,当某段子序列待排序元素个数为1或最大值和最小值之差为1(即整数的精度;对浮点数来说,最大值和最小值之差为浮点数的精度时结束排序,下文涉及的最大值最小值之差的“1”均可等价地用浮点数的精度替换)时结束对该段子序列的排序。C语言代码如下。


此算法需要预处理,即在排序开始前将待排序元素的最小值放在序列第1个元素位置,待排序元素的最大值放在序列最后1个元素位置。
划分操作保证左边元素小于等于flag,右边元素大于flag,因而每段子序列(最左边子序列除外,因为它的元素大于等于最小值)的元素都小于等于它的最大值且大于最小值,这保证了最大值和最小值之差为1时可以结束排序(该区间只有一个可取值)。对于最左边子序列,只要调用排序函数时,最小值位置填入a[0]-1即可消除其特殊性(如果不能保证不越界,可换用预先剔除所有等于a[0]元素的方法,只需一趟类似快速排序的划分操作,将等于a[0]的元素放到左边,不等于a[0]的元素放到右边即可,不会影响排序效率)。
2.1 对预处理环节的思考
预处理要同时找出待排序元素的最小值和最大值。两趟简单选择排序可以使用2n次比较解决这个问题,而借鉴归并排序的做法,可以得到更高效的方案。把寻找待排序元素的最小值和最大值问题分解成两个子问题(分别对一半数量的待排序元素寻找最小值和最大值),分别解决后再合并。
有如下表达式(T(n)代表寻找n个元素最小值和最大值需要的比较次数):T(n)=2T(n/2)+2,解得T(n)=3n/2-2,这意味着只需要3n/2次比较就能得到最小值和最大值。
实现也较为简单:每次取两个元素,比较后分别与当前的最小值和最大值进行比较。这样每两个元素只需要3次比较,总的比较次数就是3n/2。这种实现相比两趟简单选择排序,代码量会增加很多,并且在将最小值和最大值交换到首、末位置时有较多的特殊情况。为了使代码简洁明了,快速二分排序用两趟简单选择排序得到最小值和最大值。
2.2 对快速二分排序的时间复杂度分析
快速二分排序实际上是借用快速排序的划分方法把最大值和最小值之间的每个整数都隔离出来,核心仍是二进制基数排序,其最大递归深度是lb(max-min),因而时间复杂度不会超过O(nlb(max-min))。分3种情况讨论(n为待排序元素个数)。
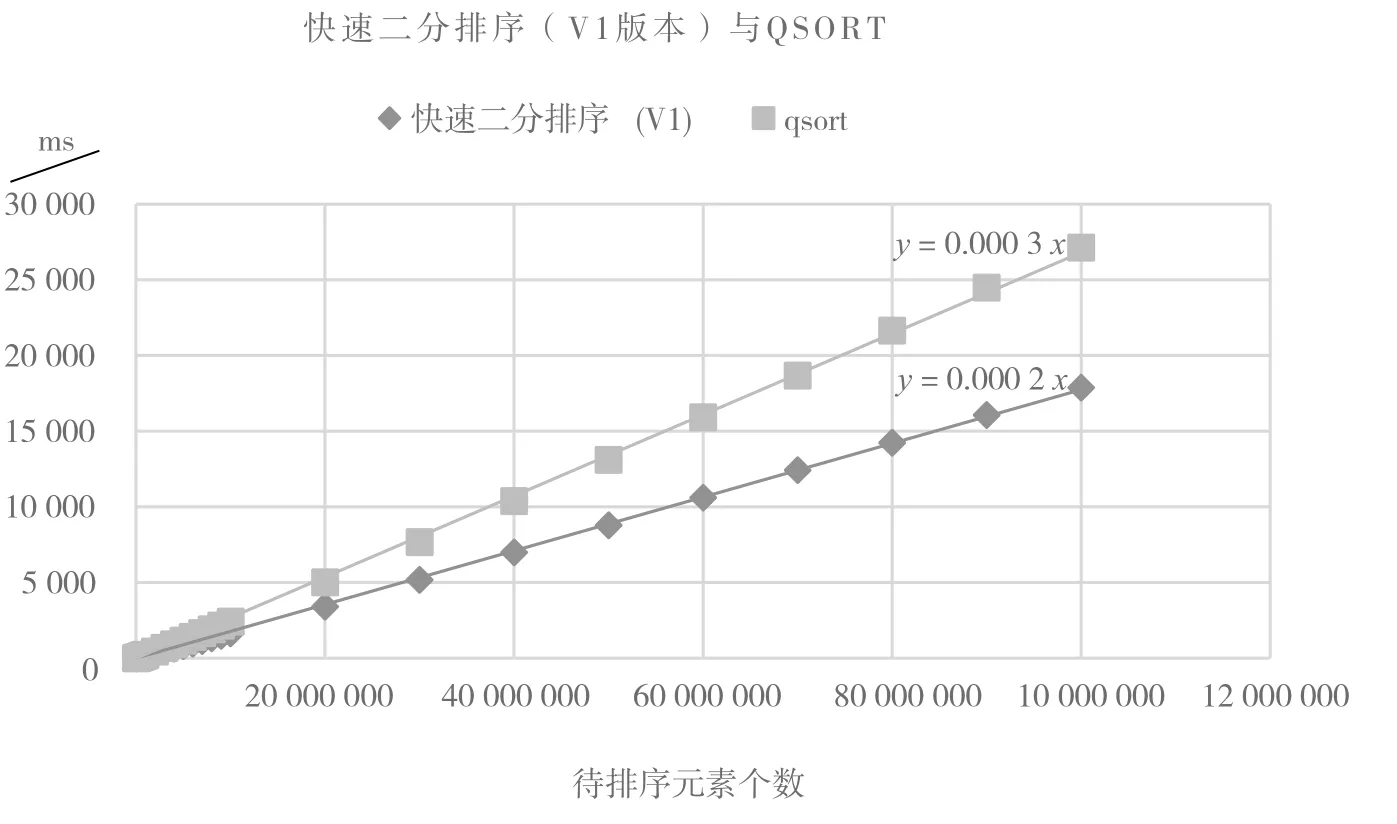
1)(max-min) (max-min) 除去最大值和最小值之差这一个特征量,影响排序效率的主要数据特征就是较多重复元素的存在。对于重复元素的处理方案(判断最大值和最小值之差与1的关系)本身就是快速二分排序算法的一部分,(max-min)=1即代表重复元素被排好序。原始快速排序对于重复元素没有预案,较多的重复元素会导致划分不均匀。 针对快速排序处理较多重复元素时的较差表现,有3路划分的改进方法,可避免因重复元素较多而划分不均匀的情况出现,消除重复元素对快速排序的不利影响。 为了说明快速二分排序的高效性,对快速二分排序与C++库函数qsort(使用3路划分方法的快速排序)进行对比。 图1所示为快速二分排序(V1版本)与qsort在待排序元素个数相同、最大值和最小值之差不同情况下的用时比较(快速二分排序计算寻找最小值、最大值和排序的总用时)。 图1 不同取值范围(最大值和最小值之差的范围是9~499 999)下快速二分排序(V1版本)与qsort对比(500 000待排序元素) 可以看出,(max-min) 2) (max-min)≈n。 (max-min)≈n时,如果待排序元素取值的分布较为均匀,主要影响因素就不再是重复元素,而是快速排序无法完全避免的情况——基准元素选取偏差过大,导致划分严重不均匀。对于选取序列首个元素作为基准元素的快速排序,顺序序列就能导致快速排序时间复杂度退化到O(n2)。qsort用3点取中的方法确定基准元素,在很大程度上能够降低这种不利情况发生的概率,可以确定这样的例子必定存在,但是快速二分排序不会受到划分不均匀的影响,(max-min)≈n的前提就已经将其最大递归深度限制在lb(max-min)(约等于 lb(n)),因而对于满足 (max-min)≈n的任何待排序序列都会保持O(nlb(max-min)) (约等于O(nlb(n)))的时间复杂度。 3) (max-min)>n。 此时不利于快速二分排序的主要因素是待排序元素取值范围过大导致递归深度过大(待排序元素取值范围过大不会给快速排序带来不利影响)。假设(max-min)=nn,那么快速二分排序的时间复杂度O(n2lb(n))甚至超过冒泡排序的O(n2),但实际中这样的情况并不多见。由于n较小时插入排序等低级算法与快速排序等高级算法在用时上差距较小,以下讨论n≥10 000的情况。 目前32位编译环境下int类型的取值范围约为-2×109~2×109,即使long long int类型取值范围的最大值和最小值之差也在1019量级,而1019=(104)4.75,即快速二分排序最坏情况(比较次数达到最大,即nlb((max-min)/n))的时间开销仅是正常情况下的4~5倍(数据量大时这个比值更小),并且最坏情况可被预判(最大值和最小值之差相比待排序元素个数过大时可考虑换用其他排序算法),在这一点上好于某些情况下退化到冒泡排序而无法预判的快速排序。 此时快速二分排序的总比较次数在nlb(n)~nlb(max-min)范围内。 以一个极端的例子说明快速二分排序可能的最坏情况。假设待排序的序列为{min,min+1,...,min+n-2,max} 且 (max-min)>>n,可以估计总的比较次数约为nlb((max-min)/n)+nlb(n),nlb((max-min)/n)表示为了将最大值和最小值之差缩小到n需要lb((max-min)/n)层递归,每层递归需要n次比较(遍历一次除最大值外的待排序元素),nlb(n)表示将前n-1个元素分开需要的比较次数。 最好情况的一种可能是待排序元素的取值在最大值和最小值确定的区间内均匀分布,即待排序的序列为{min,min+(max-min)/(n-1),min+2×(max-min)/(n-1)......min+(n-2)×(max-min)/(n-1),max},此时比较次数是nlb(n)(每次划分都会使待排序元素数量规模减半,因而递归深度是lb(n)),而如果有一个元素偏离均匀分布的位置(如和一个相邻元素大小只差1),为了确定这个元素的位置,排序时需要的递归深度就比均匀分布的情况更大,从而使比较次数增多,随着偏离均匀分布位置的元素个数增多,快速二分排序时间复杂度逐渐接近最坏情况。 如果假设输入的数据较为均匀,那么快速二分排序的时间开销将更接近于nlb(n)次比较,只在少数情况下退化到nlb(max-min)。虽然一个数据就可以使时间复杂度增大,但是鉴于实际应用中收集数据时已经剔除明显偏离正常范围的“坏点”,而且退化的时间复杂度也是O(nlb(n)),因此排序效率不会受到太大影响。 图2所示为数据取值范围0~109的情况下,快速二分排序(V1版本)与C++库函数qsort在不同数据量时的用时比较。 可以看到,快速二分排序(V1版本)相比于qsort有50%左右的速度提升(图中拟合直线的斜率代表排序一个元素的平均用时,定义此用时的倒数为排序的速度)。 图2 不同数据量下快速二分排序(V1版本)与qsort对比 作为采用3路划分改进方法的快速排序,C++库函数qsort的表现已经很出色,而STL中的sort函数进行了更细致的优化,经验表明相同条件下sort用时是qsort的一半,大致的测试结果显示快速二分排序(V1版本)慢于sort。 《STL源码剖析》[3]中提到了sort对快速排序进行的几点主要优化措施:①如果分段后的小区间长度小于某个阈值(书中指明为16),改用插入排序;②如果递归深度超过某个阈值(书中指明为2lb(n)),改用堆排序;③书中并不推荐的一点:每次划分后,sort只对右半段进行递归排序,对左半段采用循环的方式继续排序——虽然书中认为这样降低了可读性,并且效率不是很高[3],但实际应用中,递归的效率低于循环,这样的改进可以减少函数调用的次数,应当能适当提升效率。 基于3.2中3)的分析,快速二分排序目前不需要②的优化策略,但是①和③所述优化方法仍然值得借鉴,为了让快速二分排序和sort有一定的可比性,我们也对快速二分排序进行①和③的优化,代码如下(划分操作不变): 优化后的快速二分排序性能提升明显,达到了能够同sort进行比较的水平。 图3是待排序元素取值范围0~109、不同待排序元素个数的情况下,快速二分排序(V2版本)和sort的比较结果。 图3 不同数据量下快速二分排序(V2版本)与sort对比 虽然V2版本对快速二分排序的优化必定不如STL开发者对sort的优化精细,并且测试条件是不利于快速二分排序的情况((max-min)>n),但是快速二分排序仍然在较多情况下保持优势,小幅超越sort。 (max-min) 虽然快速二分排序的时间复杂度只与待排序元素的最大值和最小值之差有关,但是由于我们只利用待排序元素最初的最小值和最大值信息,多次划分之后将出现较大的误差积累(即我们记录的最小值(最大值)远小于(大于)该区间元素实际的最小值(最大值)),实际的比较次数仍然在一定程度上依赖于待排序元素的数据特点,取值分布不均匀的数据对快速二分排序有着不利影响。然而,又存在如下矛盾:仅在排序前找到待排序元素的最小值和最大值,能够完全保证递归深度最大是lb(max-min),并保持快速排序的高效性,但是受数据分布情况影响较大;如果类似高效快速排序[1],每次划分前都重新寻找当前待排序元素的最小值和最大值,虽然做到每次划分都完全适应当前序列的特点,但是会增加时间开销。 目前看来,快速二分排序只是一个初级的处理方案,虽然优化后的快速二分排序具有等同于甚至超过STL中sort算法的效率,但是仍有较大的改进空间。如何让二分法更“智能”,减少对重复元素的遍历次数,将是改进的方向。 本文对快速排序做出一些并不基于比较的调整,旨在提高快速排序的效率,从根本上解决快速排序时间复杂度退化的问题。实际测试的结果也令人满意。在目前数据存储范围有限(指的是通常的32位、64位编译环境下)的情况下,快速二分排序具有接近甚至超过STL中sort函数的性能,并且仍有进一步改进的空间,但就其目前的良好表现来看,快速二分排序已经具备了成为标准模板库排序函数的素质。 [1] 汤亚玲, 秦锋. 高效快速排序算法研究[J]. 计算机工程, 2011(6): 77-78. [2] 周建钦. 超快速排序算法[J]. 计算机工程与应用, 2006(29): 41-42. [3] 侯捷. STL源码剖析[M]. 武汉: 华中科技大学出版社, 2011: 389-400.
2.3 对快速二分排序与qsort在不同数据量下的对比
2.4 对快速二分排序的优化


3 可能的改进方向
4 结 语
