关联图谱和舆情分析在异常传导路径分析中的应用
2018-05-30上交所技术有限责任公司
上交所技术有限责任公司 王 泊
0.引言
传统的指数贡献度算法,主要使用涨跌幅乘以权重的计算方法,这种方法只能计算个股(行业)本身对指数贡献的直接影响。现实情况下,个股(行业)之间不是孤立的,是有相互影响的。如果不考虑个股(行业)对其它个股(行业)的影响而衍生出对指数影响的话,市场分析工作就有很大的局限性。
本研究突破传统的指数贡献度算法的局限,首次量化个股对其关联个股的影响,以及行业对其关联行业的影响,并且更加精确地衡量个股、行业对指数的影响程度,结合对舆情关联行情数据的分类处理,绘制个股(行业)的异常传导路径,为日常对异动股票、异动行业的监管提供了理论支持。
1.研究背景
在证券二级市场上,市场风险具有较强的扩散性的特性,例如,概念股炒作往往从龙头个股开始,接力炒作龙二、龙三等股票。研究个股(行业)异常波动之间的相关性和风险的传播方向就显得尤为重要。
如果能根据个股(行业)出现异常波动之间的相关性,在风险扩散的初级阶段提前以预警方式提示风险,则能从源头上抑制炒作,有效的控制风险。比如,如果能从历史的交易信息中,提前挖掘出可能炒作的与龙头关联的龙二、龙三等股票,并以预警形式提请关注,则可以为实现事前监管累积丰富的基础。
另一方面,舆情信息也对市场波动有重要影响。本文考虑将股市异常分析与舆情分析相结合,构建出异常股票(行业)的关联和风险传播网络图谱,用以更好地侦查和控制风险。在实际应用中,个股信息和新闻信息是海量、高维度的,并存在数据噪声需要处理,因此本研究结合深度学习、贝叶斯网络和自然语言处理技术,对数据进行有效的筛选,构建出兼具准确性、可解释性和不断自我学习优化的传导模型。
2.绘制异常传导路径的理论和算法
如“深度贝叶斯网络技术及股票关联机器学习识别”一文中介绍,可以通过抓取异常节点和计算节点连接强度的方法,搭建股票的关联图谱。如果我们引入时间轴,将个股或行业在某一个时间点的异常波动抓取出来、作为图谱的节点,沿用节点连接强度的计算方法,并结合舆情分析给节点标注利好或利空的分数,进而调整节点的连接强度(即异常传导的相关系数),得到的股票(行业)的异常传导路径,用以解释或预测股市的波动。模型整体思路的架构图如图1所示:

图1 抓取异常传导路径的模型架构图
第三、四两章将分别介绍用行情数据搭建异常节点网络和用舆情数据计算利好利空分数这两部分内容。第五章介绍综合前两步计算的结果、寻找异常传导路径的过程。第六章介绍数据实验和结论部分。
3.用行情数据搭建异常节点网络和节点相关性的计算
异常节点网络的搭建分为节点识别、节点连接、网络参数优化和网络微调四个部分,详细的流程如图2所示:
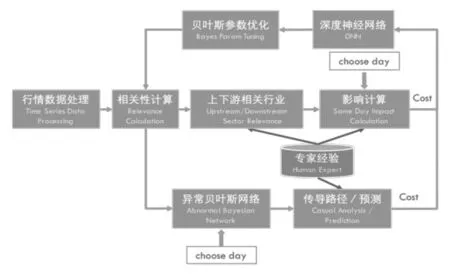
图2 异常贝叶斯网络搭建机器学习算法框架图
3.1 节点识别
“在股票关联图谱中,节点的定义是某个股或行业。节点的筛选,可以通过专家规则来确定,或者是通过确定异常节点阈值的方式进行选择。如果是通过专家规则来定义的话,就由市场分析专家来确定将哪些个股(行业)作为节点。如果通过异常节点的方式来定义的话,考虑到个股(行业)的形态不同,需要对个股采用用不同的阈值。不同个股(行业)的波动率(Volatility)不同,因此每个个股的异常定义也不同。对于波动率较低的个股,其异常阈值也相对较低。”以上这段文字是叙述在构建股票关联图谱中抓取节点的方法,这里的波动率是一段时间的平均波动率,异常阈值的设定也是针对一段时间的平均值。而在本研究中,异常节点是指某个时间点上波动异常的某支股票或某个行业,我们要构建的是存在时间轴的传导网络。
3.2 节点连接
运用点互信息(Pointwise Mutual Information (PMI))计算出节点连接强度,公式如下:
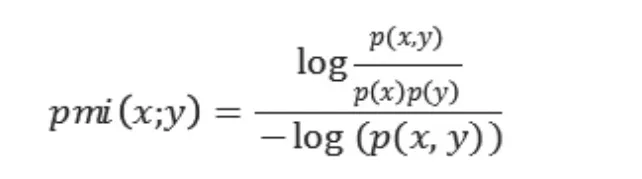
其中各符号含义如下:
p(x)是事件x单独出现的概率;
p(y)是事件y单独出现的概率;
p(x, y)是两个事件x, y共现的概率;

log(p(x, y))是归一化项,采用归一化处理的PMI值更加稳定。
3.3 网络参数优化和网络微调
基于构建好的节点和连接强度,结合人类专家标记出个股(行业)间的关联关系,可对贝叶斯网络的参数进行调整。具体地,系统在收到人类专家的反馈后,会根据惩罚函数对现有参数进行调整,重新计算连接强度,专家提供的惩罚函数具体可由如下两种形式来实现:
方式一,个股(行业)间关系的排序。人类专家标记出个股(行业)间的关联关系,可以作为有监督学习的标签。在系统计算出每对行业之间的相关性后,惩罚函数如下:

其中,Rij是行业i,j之间的相关性,UDij代表上下游行业关系。UDij是1代表有上下游关系,此时Rij越大惩罚值越小,UDij是0代表没有上下游关系,此时Rij越大惩罚值越大。
方式二,人类专家给定的关联关系权重值。对于系统分析出的关联关系中的每条边,人类专家可以给予1-5的评分,用以评判关联关系的准确性。惩罚函数的数学表达如下:
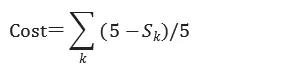
其中,关联关系由k条边组成,Sk代表人类专家对每条边的打分。
得分越高,惩罚函数值越小,反之亦然。最终的惩罚函数等于所有边的调整过的惩罚值相加。
4.用舆情数据计算利好或利空分数
除了股票价格的直接波动,舆情也是影响异常事件传导的重要因素。本研究的一个创新之处,即把舆情分析得到的利多或利空判断与异常股票的关联性相结合,作为异常传导路径的计算要素。
本研究用自然语言处理技术(Natural Language Processing),对舆情信息进行数据筛选、文本清理,建立了舆情信息与个股和行业的关联以及利多、利空的识别模型。
为解决高维数据与数据噪声问题,研究对舆情文本进行数据预处理,并引入关键词引擎ElasticSearch辅助生成行情利多利空特征,加强舆情分类判断的准确性。其中预处理和关键词引擎与云脑Deepro NLP形成多次迭代,通过机器学习不断优化模型。
舆情分析整个流程具备高度自动化与高度适应性的能力,可以应对不同种类的文本数据输入,如:各种类别财经新闻。对于新引入的行情关键词可以快速更新模型库,以便调整分类与评判结果。整体流程设计模块化,具备标准API调用接口,并充分考虑了可扩展性,预留模块包括专家经验引入,以及根据专家对分类结果的反馈等。如图3所示。
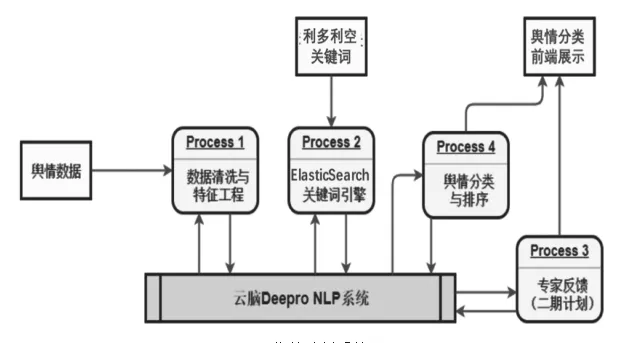
图3 舆情分析系统图
4.1 用BM25模型获取利好(利空)分数
研究在现有的舆情数据集的基础上,测试了一系列排序与打分算法,包括:BM25、TF-IDF、DFR、DFI、IB、LM Dirichlet、LM Jelinek Mercer等,凭借BM25算法在文本查询排序与文本误查率等评判标准中的优异表现,将BM25算法选定为本课题的舆情分析的最终算法。
BM是在概率搜索的框架下被提出的Best Matching(最佳匹配)算法的缩写,BM25又常被称为“Okapi BM25”。BM算法返回与搜索关键词相关性最符合的结果,并给出结果排序,被广泛应用于复杂搜索引擎中。BM25核心计算公式如下:

其中各符号含义如下:
D:文档;
Q:搜索词(多个);
f(qi, D):qi这个词在文档D中出现的次数;
|D|:D的单词数;
avgdl:整个文档库中文档的平均长度;
k1, b:自由参数,一般取值范围是k1 ∈ [1.2,2.0], b = 0.75。IDF(qi)(inverse document frequency):通常由下述公式计算

其中,N是文档库中的文章总数,n(qi)是包含qi这个词的文章总数。
4.2 用NLP预测利好(利空)分数
通过以上过程我们得到一系列训练数据,包括新闻的文本和针对每一篇文本用BM25标记的利好和利空分数。接下来,本研究用循环神经网络(RNN)中的长短期记忆网络(LSTMs)模型对文字的处理,将所有和节点相关的新闻进行利好或利空的分类,并输出每个节点的利好、利空分数,作为下一步综合系数计算连接强度的输入。简单介绍下模型:
循环神经网络(RNN)是在传统神经网络的基础上,加入一个循环的操作,这种循环结构使得某个时刻的状态能够传到下一个时刻,即每一网络会把它的输出传递到下一个网络中。把循环神经网络在时间步上进行展开,就得到如图4这样的模型:
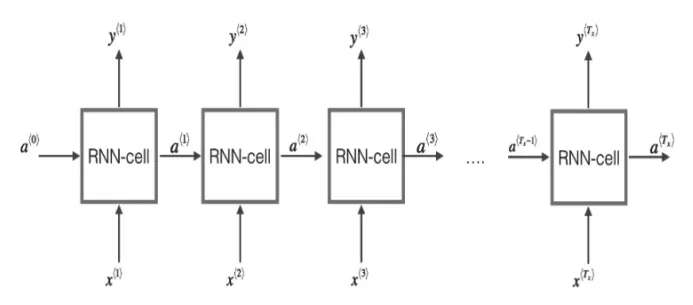
图4 RNN原理说明图
循环神经网络的出现和广泛应用,主要是因为它们能够把以前的信息联系到现在,从而解决现在的问题。比如在视频中利用前面的画面,能够帮助我们理解当前画面的内容。有时候,我们在处理当前任务的时候,只需要看一下比较近的一些信息,即我们所要预测的内容和相关信息间的间隔很小,这种情况下RNN就能够很容易利用过去的信息进行预测。但是非常幸运地,长短期记忆网络(LSTMs)的出现可以帮助我们避免这种长期依赖(long-term dependency)的问题。它们的本质就是能够记住很长时期内的信息,其原理如图5所示:

图5 LSTMs原理说明图
长短期记忆网络最关键的地方在于每个单元(cell)的状态和结构图上面的那条横穿的水平线。单元状态的传输就像一条传送带,向量从整个单元中穿过,只是做了少量的线性操作。这种结构能够很轻松地实现信息从整个单元中穿过而不做改变,从而实现长期记忆的保留。
5.综合系数模型和寻找异常传导路径
5.1 综合系数模型
前文叙述了抓取异常节点、用点互信息的方法计算节点连接强度和计算利好或利空分数的过程,这部分内容将把用点互信息计算的连接强度和利好利空分数结合,综合考虑了股市的异常波动和舆情传播两种情况对节点连接的影响。综合系数模型计算新的连接强度的公式如下:

其中,pmi是2.2节中计算出的连接强度,ε是用LSTM预测的利好利空分数,a是一个比较大的常数,其取值可以通过参数微调的过程进行优化。
5.2 寻找异常传导路径
得到异常节点和新的节点连接强度后,用最长路径算法在这个有向无环图中寻找异常传播路径。即:
拓扑排序图(G)中的所有节点;
对于线性排序的每个节点v ∈ V,dist(v)=max(u, v)∈E{dist(u)+w(u, v)},w(u, v)是节点v和节点u的连接强度;
返回maxv ∈ V{dist(v)}。
6.数据实验结果输出和结论
本例中,系统分析2017年4月19日上证指数的异常波动。所输出的异常传导路径从2017年4月17日国防军工板块异常,到4月18日的银行板块与多个权重个股异常,到4月19日的钢铁板块异常,以及上证指数异常。其中,板块,个股之间异常事件的相关性也一并标出。经过行业专家与当时舆情验证验证,证明此分析与专家经验分析类似。
各节点说明如下:
(1)国防军工(申万)跌幅异常:-3.24%
(2)银行(申万)跌幅异常:-1.37%
(3)包钢股份跌幅异常:-3.10%
(4)交通银行跌幅异常:-1.80%
(5)浦发银行跌幅异常:-1.67%
(6)兴业银行跌幅异常:-1.77%
(7)钢铁(申万)跌幅异常:-2.73%
(8)上证综指5日跌幅超3%:-3.15%
本系统将用深度贝叶斯网络构建关联图谱的方法迁移到构建异常节点网络的模型中,结合舆情信息的分析。从股票价格和舆情这两个维度出发、刻画风险如何从舆情传导到相应的股票或行业,进而传导到关联的股票和行业,最终形成对指数波动的影响。以异常传导路径的方法,可以更加直观和准确地刻画出市场波动的原因。从创新角度,本系统首次将贝叶斯网络技术与NLP自然语言处理技术有机结合,利用NLP技术从非结构化的舆情中提取有效相关信息,作为结构化的证券行情数据的标签。整个系统需要经过多轮迭代,以同时优化贝叶斯网络参数与NLP系统的参数。本系统的高精确度来源于深度贝叶斯网络快速收敛的特性,以及NLP系统中采用的LSTM对语言序列高精度建模的能力。经过专家验证,本系统在证券行业的实际应用中,能高度协助,并在某些场景下超越专家经验的分析。
[1]K.W.Church and et al.(March 1990).“Word association norms,mutual information, and lexicography”.Compute. Linguist.16(1):22-29.
[2]T.M.Cover and et al.(1991).Elements of Information Theory(Wiley ed.).ISBN 978-0-471-24195-9.
[3]C.D.Manning and et al.,An Introduction to Information Retrieval,Cambridge University Press,2009,p.233.
[4]S.E.Robertson and et al.(November 1994).Okapi at TREC-3.Proceedings of the Third Text REtrieval Conference(TREC 1994).Gaithersburg, USA.
[5]S.E.Robertson and et al.(November 1998).Okapi at TREC-7.Proceedings of the Seventh Text REtrieval Conference.Gaithersburg,USA.
[6]A.Y.Ng,sequence model course slides on coursera, https://www.coursera.org/learn/nlp-sequence-models/.
[7]C.Olah,Understanding LSTM Networks, http://colah.github.io/posts/2015-08-Understanding-LSTMs/.
