基于弱特征重识别的多目标长效摘要
2018-05-28石亚玲刘正熙熊运余
石亚玲,刘正熙,熊运余,李 征
(四川大学 计算机学院,四川 成都 610000)
0 引 言
在当今的信息社会,监控摄像头已经遍布大街小巷。但是如何在发生异常情况之后在海量的监控视频中查找事件产生的原因,即在原始的视频流中找到感兴趣的视频内容形成紧凑的摘要,这些摘要简短便于组织、能够快速浏览检索对象。对此,国内外对视频摘要技术进行了研究,提出了一些较为成熟的摘要系统,如哥伦比亚大学设计的VideoQ[1]系统、FX PaloAlto实验室提出的VideoManga[2]系统、国防科技大学开发的Videowser[3]系统。视频摘要[4-5]研究领域主要分为视频概略以及视频梗概(视频概述、精彩片段)。阿姆斯特丹大学设计的Goalgle[6]足球视频搜索引擎,通过Web端搜索视频找到足球场上红牌、黄牌、进球和换人等事件,也可以针对特定的足球运动员进行搜索操作,以获得单个运动员的运动事件。在视频概略中基于对象的视频摘要技术[7],即通过目标跟踪获取目标的连续信息,将不同时刻出现的目标显示在同一画面中,如果目标检测不准确、跟踪的连续性较低,则会导致摘要断裂、重复等。
而在跟踪过程中,背景的复杂以及人本身的遮挡、变形使得目标的长效跟踪变得很困难。文献[8]融合目标的颜色、纹理、运动信息进行相似度比对;文献[9]定义目标的遮挡类型,根据不同的类型采取不同的方法以提高鲁棒性;文献[10]联合目标的颜色、纹理特征并使用卡尔曼滤波预测-跟踪的方案减少遮挡的影响;而文献[11-12]加入目标的显性特征同时增加目标的搜索区域,从而解决目标的遮挡问题。
文中针对在视频摘要中目标信息不连续的问题,提出在基于JPDA的跟踪下加入颜色和纹理特征进行重识别,当目标被稳定跟踪时提取目标的颜色和纹理特征,并且随着时间变化进行更新,当发生遮挡时不进行更新。通过增加目标运动方向的搜索范围使得目标再次出现时能被识别从而获得目标的长效摘要,使得视频概略中目标的连续性更高。
1 多目标关联算法
进行多目标跟踪最重要的算法就是数据关联算法[13],在真实的情况中存在许多影响关联准确性的外部因素。而联合概率数据关联(joint probabilistic data association,JPDA)是目前公认的在杂波环境下对多目标进行跟踪的最理想的方法之一。其主要思想是当某测量在多个目标的候选区域内,即测量可能源于多个目标。JPDA的目的就是计算每一个测量与其可能源于的所有目标的关联概率,且认为所有的有效测量都可能源于某个特定目标,只是它们源于不同目标的概率不同,源于某目标概率最高的测量即成功匹配。联合概率数据关联算法具有良好的性能,但是该算法中,联合事件数是所有候选测量的指数函数,并随着量测密度的增大而迅速增大,致使出现组合爆炸现象。文中使用的JPDA算法[14]改进了计算复杂度,在联合事件数进行爆炸式增长时,选择最优的100种假设进行联合概率的计算,大大减少了复杂场景下的计算率。
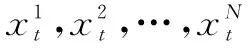
(1)

联合数据关联空间Θ的定义为满足以下几种条件的所有可能的测量与目标的组合:
(1)每个检测(除了丢失的情况即i=0)至多分配一个目标;
(2)一个目标只能分配一个检测。
这个空间集合通过一系列的二进制向量表示为:

(2)
其中,|Θ|=:nh为联合分配的总数;θ∈Θ⊆BN×(M+1)为数据关联问题的一种可能的解决方案的二进制向量。
(3)
其中
(4)
2 多目标跟踪算法
由以上获得目标联合概率的方式可知,在计算目标的联合概率时利用了卡尔曼滤波的预测位置以及当前的目标位置。而卡尔曼滤波仅针对线性运动,在真实的运动场景中目标可能会与原来的运动方向有所偏差,并不是线性运动。因此仅根据联合概率进行目标关联会使得跟踪效果缺乏鲁棒性,由此介绍基于位置预测结合弱特征的匹配关联模型。
希望在改进目标的跟踪鲁棒性的同时能兼顾实时性能,故选取的特征都是具有代表性并且计算复杂度较低的。在图像中,颜色特征能够描述目标的全局特征,对目标形变,旋转不敏感,但是当背景颜色相似、光照强度大以及存在遮挡时影响较大。纹理特征描述图像区域的本质属性,对光照变化、噪声有较强的适应性,具有旋转不变性。通过两个特征的互补可以适应复杂情景,实现更为鲁棒的跟踪。其中对颜色特征,选取颜色直方图,将RGB空间转换为HSV空间,减少光照的影响。
2.1 LBP特征提取
纹理是图像灰度和色彩在空间上的变化和重复,它体现了物体表面的具有缓慢变化或者周期性变化的表面结构组织排列属性,通过像素及其周围空间邻域的灰度分布来表现,即局部纹理信息。LBP(local binary pattern,局部二值模式)是一种描述图像局部纹理特征的算子。文中使用的纹理特征为具有旋转不变性的LBP算子:在以R为半径的圆形区域内选取P个采样点,若周围像素值大于中心像素值,则该像素点的位置标记为1,否则为0。这样将得到一个LBP算子,而当图像发生旋转时,只要LBP算子的值不为全0或全1,LBP算子的值会发生改变。不断地旋转圆形邻域将得到一系列的LBP值,然后取其最小值作为该邻域的LBP值。
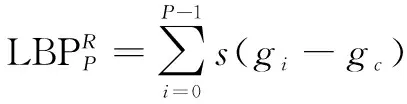
(5)
其中,gc表示中心的像素值;gi表示周围的像素值。
(6)
其中,ROR表示通过向右移位取不同的LBP。
计算目标的纹理特征直方图时,用矩形区域表示跟踪目标。使用半径为R的有P个采样点的LBP算子,目标模型的像素点总数为n,将目标的纹理特征空间均匀分成2P个直方图区间,目标模型的直方图表示为ht,则目标模型的直方图由下式计算:
(7)
其中,m()为求旋转不变LBP值的函数;hist()表示将矩阵转换为直方图。
由于LBP特征以直方图形式表征,因此可以使用卡方统计来度量两个LBP特征之间的差异,即
(8)
其中,S和M分别为LBP直方图特征向量。
在跟踪过程中,若光照发生改变或目标发生旋转,可以保持目标的特征函数不变,增加目标函数匹配度,提高跟踪的准确性。
2.2 基于颜色和纹理的JPDA算法
由于卡尔曼滤波无法预测非线性运动,若目标被遮挡进行非线性运动,利用联合概率进行关联很可能会关联不是由此目标产生的测量,错误的关联将导致当前帧两个目标都发生错误匹配,并且在后续的过程中无法纠正。而加入了弱特征的JPDA算法根据丢失帧数加大搜索范围,即在目标的运动方向的半个圆内搜索量测进行特征匹配,极大地避免了目标遮挡所带来的跟踪错误。
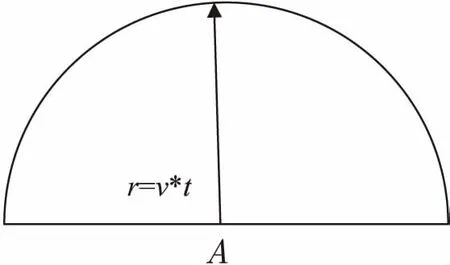
图1 在候选区域周围增大搜索范围示意
图中A为丢失匹配前的最后位置,箭头所指方向为目标出现第一帧位置与A位置的连线方向。由于真实情况中被遮挡目标折返的情况比较少,搜索方向为与目标运动方向垂直的半个圆的方向,距离为丢失时的运动速度乘以丢失的帧数。
为了避免JPDA因测量距离目标较近使得联合概率变大导致跟踪错误,对在阈值范围内的检测和目标的特征匹配,增加目标跟踪的准确性,同时由于颜色直方图和纹理特征计算简单,仍能使得算法实时性保持良好。加入弱特征的JPDA算法流程如下所示:
(1)将第一帧的检测作为初始跟踪目标。
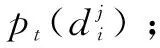
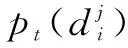
(4)若目标被连续跟踪不小于3帧,则计算目标的颜色和纹理特征,保存为特征模板。目标被稳定跟踪并且匹配的检测并未与其他检测有重叠部分,则认为该目标为单独目标,并且特征模板与当前帧目标特征对比在阈值范围内,则更新特征模板的值。
(5)将在丢失的目标的搜索范围内并未匹配其他目标的量测与该目标的特征值进行比对,若颜色直方图相关系数大于α且纹理直方图差异小于β,则认为该检测为此目标产生,更新目标的状态;若两个特征比对只满足一个条件,则该检测被认为是此目标的子目标,在后面的跟踪过程中再进行特征比对,防止测量被物体遮挡只露出一部分的情况。当前帧所有目标状态更新完成即进入步骤2,进行下帧跟踪。
3 实验结果及分析
使用Matlab2015b进行仿真,实验图片序列来自于TUD-campus与TUD-stadtmitte,是以较低的视角拍摄的大学以及街道的图片。检测结果均来自DPM(deformable parts model)[15],然后使用该算法进行跟踪。为了测试算法的优劣,对上述图片进行测试,并对仿真的结果进行比较和分析。为了方便观察,只给出了部分会发生遮挡的目标的跟踪结果。
3.1 较长距离遮挡实验
图2中,实验的测试序列为一组学校道路的图像,TUD-campus总共由71张640×480的图片组成。在这组图像中拍摄的角度为人的侧面,由于摄像机的角度问题会使得目标运动时发生遮挡。当目标在第5帧时,原算法及文中算法均能跟踪目标,此时目标未发生遮挡,两种算法均识别为目标2;第20帧时发生遮挡,但由于遮挡时间较短且为线性运动,根据卡尔曼滤波的预测,两种算法也均能识别目标2;当目标随后被完全遮挡40帧(即检测不出此目标)之后再次出现时,原算法将原目标2识别为新目标19,原目标与预测位置的距离超过丢失阈值后则认为丢失,形成了两条目标摘要。而文中算法增加了搜索区域,只要目标的丢失帧数小于消失阈值45都会进行重识别,将与丢失目标运动方向一致且在搜索范围内测量的特征进行对比,从而实现目标的重识别。
3.2 相同颜色遮挡实验
图3中,实验的测试序列TUD-stadtmitte由179张640×480的JPG图片组成,为一组在商店门口拍摄的图片序列,目标在运动过程中会出现被穿有相似颜色衣服的人遮挡的情况。由对比图片可知,在第4帧时两种算法均识别目标1;而当目标被穿有相似颜色衣服的人遮挡之后再次出现时即第49帧,由于原算法将未与其他检测匹配的目标认为是新目标,故识别为新目标14,而文中算法将新出现的目标与丢失的目标进行特征匹配识别为目标1;在第68帧目标再次被遮挡之后,原算法根据距离最近的检测匹配识别为目标13,而文中算法将量测与在距离阈值内所有的丢失目标进行特征对比并且选择匹配度最高的目标匹配,故识别为目标1。

图3 相同颜色遮挡实验
3.3 实验对比分析
对两种算法下获得的总摘要数和正确摘要数进行了分析和对比,如表1所示。
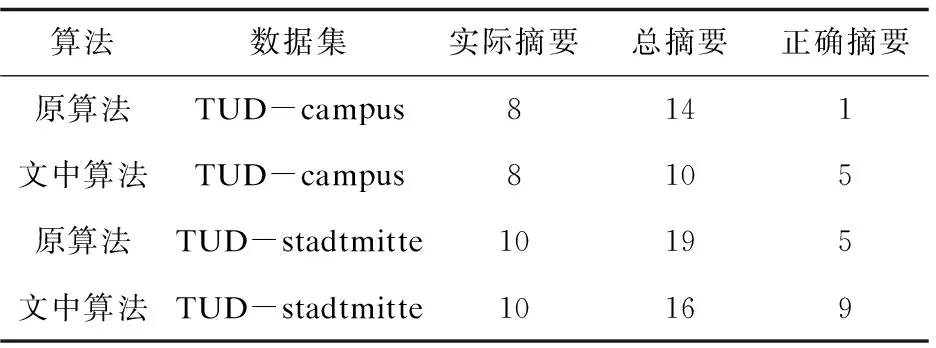
表1 算法的结果对比
表1中的实际摘要数是数据集中实际存在的轨迹数,而总摘要数是最后的跟踪结果中记录的目标位置大于两帧的轨迹数,只记录一帧位置轨迹被认为是误检且不认为是真实目标轨迹。正确摘要数指当目标离开画面时的ID与进入画面的ID是相同的,即认为目标被正确跟踪。
通过比较得出,文中算法较原算法减少了总摘要数,增加了正确摘要数。在TUD-campus图片序列中,有三个目标出现时一直重叠在一起,检测时只能识别为一个目标,则获得一个目标的摘要,无法判断为三个目标。在TUD-stadtmitte中,存在一个目标提取特征时为目标侧面而遮挡之后再出现时为目标正面,由于目标的自旋转导致特征匹配度下降,匹配失败,从而导致无法获得连续的目标摘要。
4 结束语
在现实生活场景中,常常存在目标与背景颜色相似的情况或者目标被遮挡的情景。利用传统的跟踪算法无法对目标进行准确的跟踪,而文中利用目标的颜色特征和纹理特征对目标进行描述,避免了背景与目标颜色相似时的跟踪错误。并且当目标丢失时根据运动目标的速度增大搜索区域以解决目标遮挡问题。通过实验证明,该算法有更好的鲁棒性。未来将考虑利用目标更多有效的、互补性强的特征,使得在复杂场景的跟踪更加准确。
参考文献:
[1] CHANG S F,CHEN W,MENG H J,et al.VideoQ:an automatedcontent based video search system using visual cues[C]//Proceedings of the 5th ACM international conference on multimedia.Seattle,Washington,USA:ACM,1997:313-324.
[2] UCHIHASHI S,FOOTE J,GIRGENSOHN A,et al.Video manga:generating semantically meaningful video summaries[C]//Proceedings of the seventh ACM international conference on multimedia.Orlando,Florida,USA:ACM,1999:383-392.
[3] 吴玲琦,李国辉.视频结构化浏览和查询系统:Videowser[J].小型微型计算机系统,2001,22(1):112-115.
[4] KIM E Y,PARK S H.Automatic video segmentation using genetic algorithms[J].Pattern Recognition Letters,2006,27(11):1252-1265.
[5] 王 娟,蒋兴浩,孙锬锋.视频摘要技术综述[J].中国图象图形学报,2014,19(12):1685-1695.
[6] SNOEK C G M,WORRING M.Time interval maximum entropy based event indexing in soccer[C]//Proceedings of IEEE international conference on multimedia and expo.[s.l.]:IEEE,2003:481-484.
[7] 刘松涛,殷福亮.基于图割的图像分割方法及其新进展[J].自动化学报,2012,38(6):911-922.
[8] TAKALA V,PIETIKAINEN M.Multi-object tracking using color,texture and motion[C]//IEEE conference on computer vision and pattern recognition.Minneapolis,Minnesota,USA:IEEE,2007:1-7.
[9] 张彦超,许宏丽.遮挡目标的分片跟踪处理[J].中国图象图形学报,2014,19(1):92-100.
[10] 谢建超.基于多特征联合的多目标跟踪的研究[D].哈尔滨:哈尔滨工业大学,2015.
[11] 姚原青,李 峰,周书仁.基于颜色-纹理特征的目标跟踪[J].计算机工程与科学,2014,36(8):1581-1587.
[12] 田 浩,巨永锋,王 培.改进的抗遮挡MeanShift目标跟踪算法[J].计算机工程与应用,2016,52(6):197-203.
[13] 魏 祥,李 颖,骆荣剑.数据关联算法综述[J].无线互联科技,2016(11):101-102.
[14] REZATOFIGHI S H, MILAN A, ZHANG Z, et al.Joint probabilistic data association revisited[C]//IEEE international conference on computer vision.[s.l.]:IEEE,2016:3047-3055.
[15] FELZENSZWALB P F,GIRSHICK R B,MCALLESTER D,et al.Object detection with discriminatively trained part-based models[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2010,32(9):1627-1645.
