基于逆梅尔对数频谱系数的回放语音检测算法
2018-05-25林朗王让定严迪群李璨
林朗,王让定,严迪群,李璨
(宁波大学,浙江 宁波 315211)
1 引言
说话人识别技术[1]以其自身独特的优势,诸如语音获取方便、使用者接受度高、说话人系统算法复杂度低等优点,在司法、金融、生活等领域得到了广泛应用。同时,说话人识别技术的安全性也成为亟待解决的问题。如何防止仿冒语音的攻击已成为研究的重点。
根据攻击手段的不同,仿冒语音主要分为两类:一是模仿特定说话人的声音进行攻击,称为说话人仿冒攻击;二是通过专业的设备和技术仿冒说话人的声音[2,3](如合成语音、拼接语音、回放语音等)。对于第一种攻击方式,现有的说话人识别技术已经能够有效地检测。而对于第二种攻击方式,目前还没有比较成熟有效的手段能够完全检测出来。在实际场景中,由于合成、拼接语音需要比较专业的技术支持,而回放语音相对来说操作简单,便于仿冒,已经成为不法分子最善用的攻击手段[4]。回放语音的产生过程如图1所示。
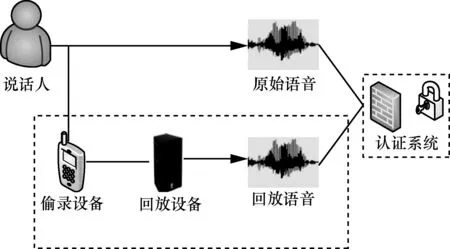
图1 回放语音产生过程
由图1可知,回放语音是真实地来源于说话人本人的声音,相较于其他仿冒语音来说,对说话人识别系统威胁更大。与原始语音相比,回放语音多经历了偷录设备的录制和回放设备的播放等过程,因此会不可避免地引入设备噪声和设备编码、解码的失真以及环境噪声等,使得回放语音和原始语音产生了细微的差异。目前,针对回放语音检测问题,主要分为以下两类:一种是基于语音随机性的检测算法,如 Shang等人[5,6]利用语音产生的随机性,提出了一种检测待测语音和合法语音在峰值图上的相似度的算法,此方法只能够应用于文本相关的声纹认证系统;另一种是基于语音信道的检测算法,如张利鹏等人[7]通过探究回放语音产生的机理,对语音的静音段信道进行建模,提出了一种基于语音静音段信道差异的回放语音检测算法,该算法由于静音段幅度很小,容易受到噪声的污染,因此很难建立精确的信道模型。王志峰等人[8]分析了回放语音产生过程中由不同设备引入的信道噪声,提出了一种基于信道模式噪声的录音回放检测算法。该方法解决了文本相关问题,但实验过程中只涉及一种录音设备和回放设备,存在实验设备单一的问题。
通过分析原始语音和回放语音的语谱图发现,在高频区域原始语音和回放语音有显著的差异。而传统的 MFCC(Mel-frequency cepstral coefficient,Mel倒谱系数)特征提取使用的 Mel滤波器由于低频分辨率高、高频分辨率低的特点,使得原始语音和回放语音在高频区的差异性削弱,从而不利于人们对回放语音的检测。其次在分析 MFCC特征参数时,经过实验发现,使用MFCC提取过程中去离散余弦变换(discrete cosine transform,DCT)前的梅尔对数频谱系数(log Mel-frequency spectral coefficient,MFSC)在回放语音的检测上有更好的检测效果。
基于上述分析,本文提出了一种基于逆Mel滤波器的梅尔对数频谱(log inverse Mel-frequency spectral coefficient,I-MFSC)的算法,逆Mel滤波器的设计是由Mel滤波器逆置得到的,表现为高频区域频谱分辨率高、低频区域分辨率低的特点,这样使得高频区回放语音和原始语音的差异性会更加显著地显示出来。实验结果表明,在回放语音的检测上I-MFSC有较好的检测效果。将本文提出的回放语音检测方法加载到目前主流的 GMM-UBM 说话人识别系统中后,系统安全性能有了显著的提高。
2 高频区回放语音和原始语音差异分析
尽管现有的偷录和回放设备都有着良好性能,能够做到较小的失真录制和高保真的回放。但原始语音和回放语音仍会存在一定的差别。本文从语谱图[9]着手,考究了原始语音和回放语音在频谱上的差异性,如图2和图3所示,实验语音是由Aigo R6620采集的一段4 s的语音,语音内容为“芝麻开门,我是土豪,千里共婵娟”。其中图(a)代表原始语音的语谱图。图(b)、图(c)、图(d)分别对应偷录设备为iPhone6、Mi4以及Sony PX440的语谱图。图2使用的回放设备为Huawei AM08,而图3对应的回放设备为Philips DTM3115。
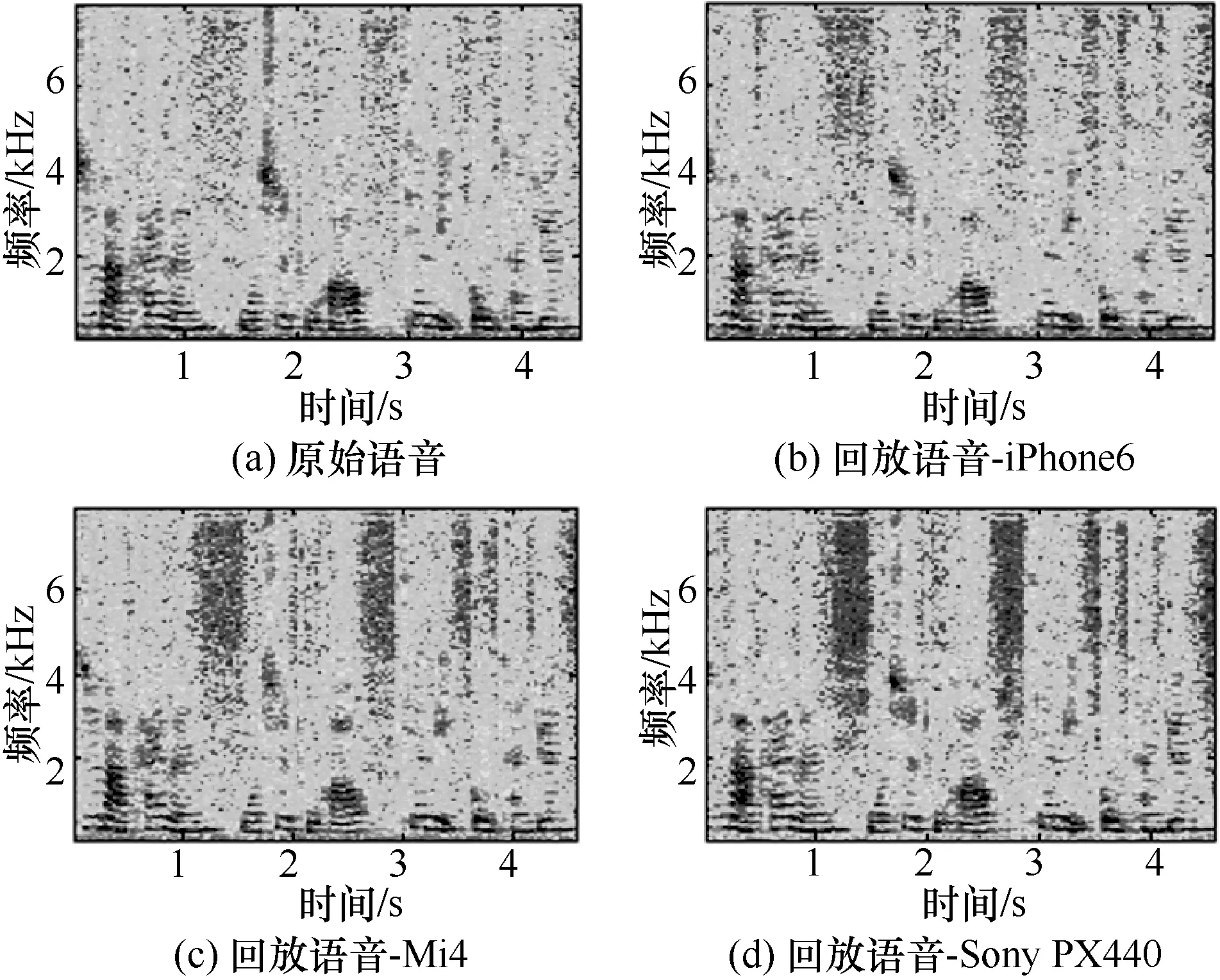
图2 原始录制和回放语音的语谱图(回放设备:Huawei AM08)
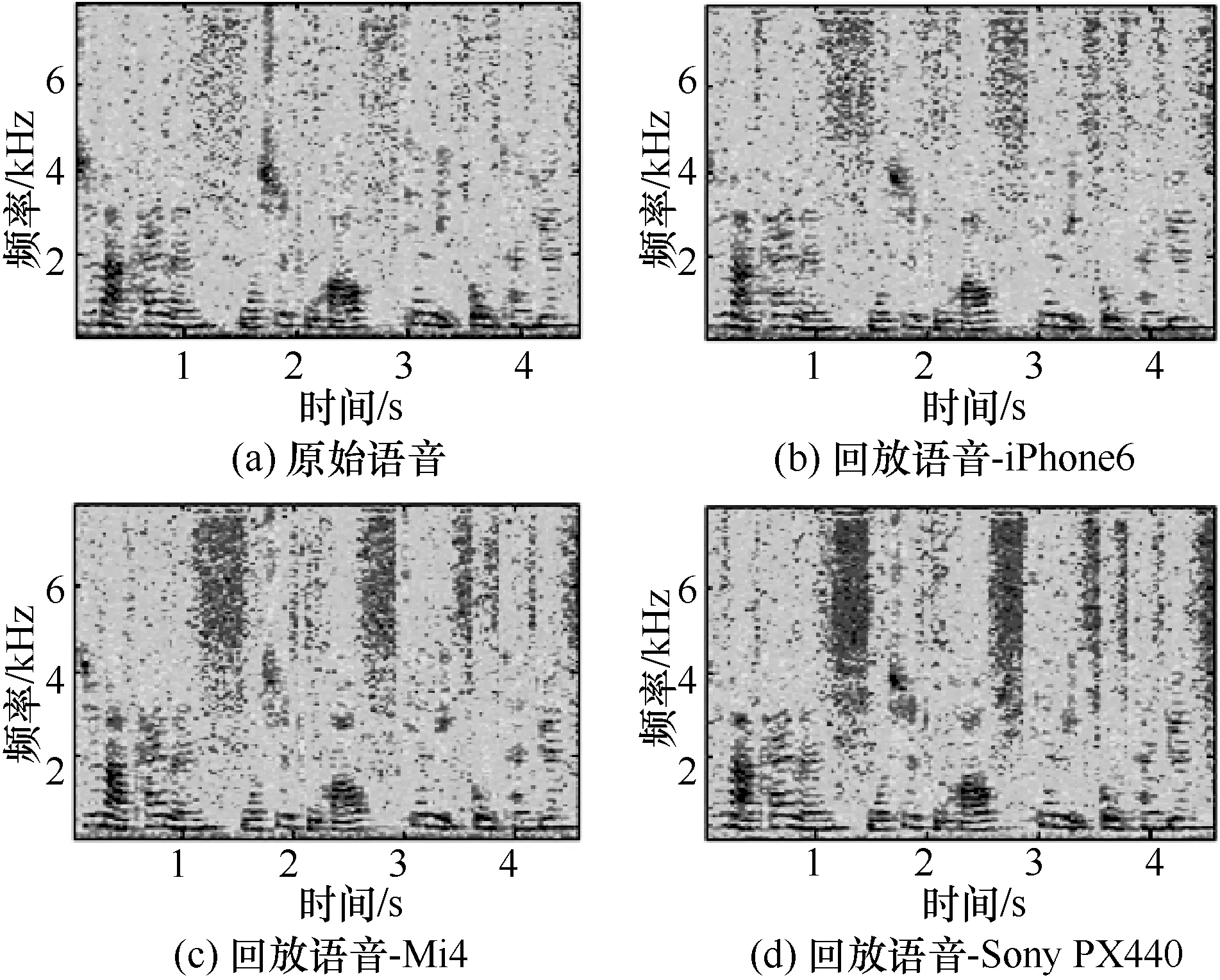
图3 原始录制和回放语音的语谱图(回放设备:Philips DTM3115)
从图2和图3中可以看出,与图(a)的原始语音语谱图相比,3种偷录设备高频区域(6~8 kHz)的频率值均小于原始语音,其中图(c)、图(d)显示出了更大的差异性。这表明 Mi4以及 Sony PX440两种设备失真度更高。此外在4 kHz左右,原始语音和iPhone6以及Sony PX440语谱图频谱过渡相对平滑,而Mi4分界线较为明显,产生了跳变现象,探究后发现这和Mi4设备自身固有的设备性能有关。
3 基于I-MFSC回放语音检测算法
3.1 MFCC特征提取过程
在说话人识别中,MFCC因能够较好地模拟人耳听觉系统的感知能力被广泛应用。图 4为MFCC特征的提取过程。
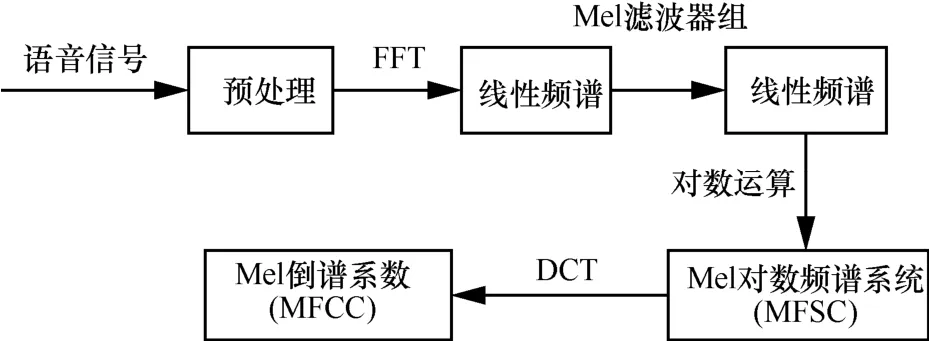
图4 MFCC特征的提取过程
首先对语音信号x(n)进行预处理,包括预加重、分帧和加窗,得到分帧后的语音信号
xi(n),其中下标i表示分帧后的第i帧。然后对每帧语音信号xi(n)进行FFT得到各帧的线性频谱Xi(k),即:
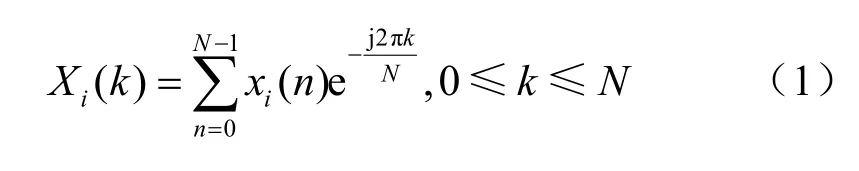
其中,N表示傅里叶变换的点数;将得到的线性频谱Xi(k)经由Mel滤波器进行滤波生成Mel频谱,然后再对 Mel频谱计算对数能量得到对数频谱Si(m),即:

其中,M表示滤波器个数,m=1,2,…,M,这里M通常取 27~40。最后经离散余弦变换(DCT)得到L阶的MFCC:
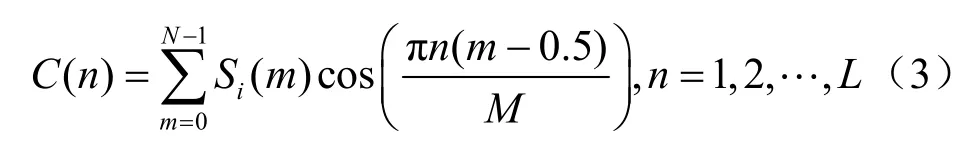
其中,C(n)为L阶的MFCC,L通常取12~16。
3.2 基于逆Mel滤波器组的MFSC
传统的Mel滤波器组,在低频段带宽较窄,频谱分辨率相对较高。而高频段带宽较宽,频谱分辨率相对较低。因此在高频区域较宽的滤波器平滑了高频信息,削弱了不同频率带之间的差异,使得高频区域的部分信息丢失。而由第2.1节的分析可知,回放语音和原始语音在高频区域存在明显的差异,因此为了利用两种语音在高频区域的差异性,本文采用一种逆Mel滤波器组[10-12]的设计来提取本文特征参数。逆Mel滤波器组的设计如图5所示。

图5 逆Mel滤波器组的设计
逆Mel滤波器组是基于逆Mel刻度变换得到的,逆Mel刻度变换的物理频率和Mel频率的对应关系为:

其中,fI-Mel表示逆 Mel频率,fmax表示语音信号最大频率,f表示语音信号的物理频率。逆 Mel和Mel变换关系如图6所示。
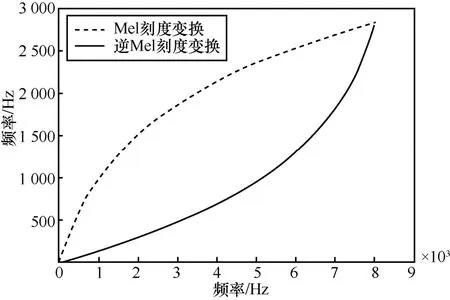
图6 逆Mel和Mel变换关系
此外,在 MFCC特征提取时,会将得到的Mel频谱取对数后再进行 DCT,得到最后的MFCC特征参数。这里的DCT有两种作用[13]:一是利用DCT后较强的能量集中特性,能够对数据进行压缩;二是由于 MFCC提取过程中使用的Mel滤波器之间是有重叠的,因此能量值之间具有很强的相关性,使用DCT可以达到去相关的目的。而 Mohamed等人[14]的研究表明,相较于MFCC特征,MFSC具有更高的相关性和维度,更适合于机器学习的建模方式。因此将DCT前的MFSC作为参数特征,在滤波器的设计上,采用逆Mel滤波器组,新得到的参数定义为I-MFSC。
3.3 特征构造与选择
I-MFSC的特征提取过程和MFCC相似,在第3.1节MFCC提取的基础上,将Mel滤波器组换成逆 Mel滤波器组,然后将去 DCT前的对数Mel频谱Si(m)作为本文算法的最后特征参数,最终得到本文的特征参数I-MFSC。
为了更好地说明 I-MFSC特征的性能,分别对 Mel倒谱系数(MFCC)、Mel对数频谱系数(MFSC)、逆Mel倒谱系数(I-MFCC)和逆Mel对数频谱系数(I-MFSC)在均值上做了对比分析,图7分别为这4种特征系数在均值上的差异。
由图7可以看出,虽然MFCC和I-MFCC在某些特征维度上也体现了差异性,可以作为检测回放语音的特征,但相较于MFSC与I-MFSC两种,后者在原始语音和回放语音的检测上体现出了更好的性能。而尽管MFSC特征与I-MFSC特征都具有很好的检测性能,但是第4节后续的实验表明,本文提出的 I-MFSC特征参数略优于MFSC特征参数。
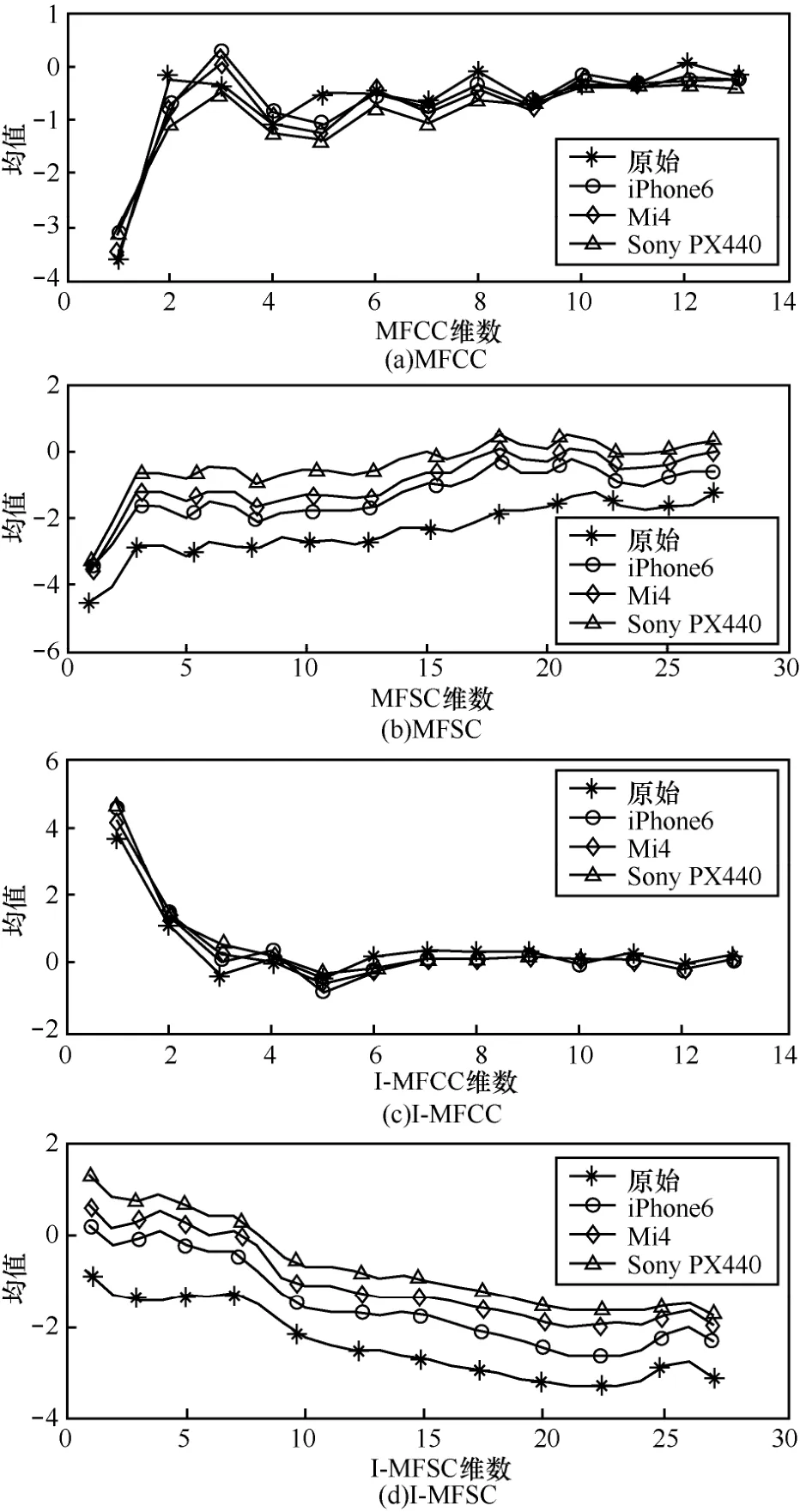
图7 4种特征均值分布
3.4 回放语音检测算法
实验分类器的选择是LibSVM[15],它是一种有监督的机器学习方法。在分类训练和测试时需要为每一条数据设置标签,这里将原始语音设置为正样本,标签设置为“Y”,回放语音设置为负样本,标签设置为“N”,LibSVM分类器其他参数均使用默认参数。
将提取的矩阵特征(MFCC、MFSC、I-MFCC、I-MFSC)按帧求取均值,得到每一条语音的均值特征,并将每一条语音特征设置标签。在训练阶段,使用训练集训练模型参数。在测试时,根据训练阶段得到的模型参数对测试数据进行判别归类,然后根据分类结果和测试数据的已知标签比较,得出回放语音检测的准确率,具体流程如图8所示。
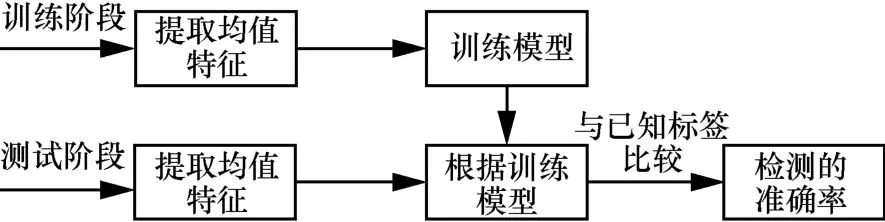
图8 回放语音检测流程
4 实验仿真及分析
4.1 实验设置
为了说明本文算法的有效性和适用性,分别构建了原始语音库和回放语音库。数据库的具体设置如下:语料库来源于863语料库[16];人员分布为10男6女;考虑到现实场景中说话人验证系统中的语音采集模块通常采用16 kHz的采样率,所以在实验中使用了与其采样率相同的设备Aigo R6620;而偷录和回放设备则选择了多款常见的高保真设备,设备的具体详情见表1。
实验库的构建环境为安静办公室,具体录音流程为:说话人按照语料库语料录音,并使用采集设备进行语音采集,通常将采集设备采集到的语音称为原始语音。与此同时,使用3种偷录设备同时录制说话人语音,并在同样的环境下,将偷录设备录制的语音经音响回放,并使用采集设备录制该回放的语音,将此种条件下采集的语音称为回放语音。数据集共有实验样本15 000个,其中原始语音样本2 400个,两种回放设备对应3种偷录设备共计有12 600个回放语音样本,所有样本详情见表2。

表1 设备的具体详情
4.2 实验结果与分析
4.2.1 不同特征的实验结果与分析
本节主要检测MFCC、I-MFCC、MFSC以及I-MFSC这4种特征对回放语音检测性能影响。实验所用样本详情见表2。表3为不同特征的检测结果,TPR为真阳性率(true positive rate),FPR为假阳性率(false positive rate),ACC为正确检测率。
由表3可知,两种Mel对数频谱系数MFSC和I-MFSC的性能显著优于MFCC和I-MFCC。尽管MFSC对回放语音的检测率也有很优越的性能,但最好的检测结果仍然是I-MFSC,因此本文后续实验所使用的特征选择I-MFSC作为最后的特征参数。
4.2.2 不同设备之间的交叉实验对检测率的影响
现实场景中由于偷录设备的多种多样,回放语音检测算法能否对多种偷录设备和回放设备都有较好的检测结果是衡量算法有效性的关键所在。本节实验目的是检测本文提出的算法在不同设备之间交叉是否依然有较好结果。实验采用的样本见表 2,实验采用的特征是本文提出的I-MFSC特征,具体检测结果见表4。
由实验结果可知,在不涉及交叉设备时,每种设备的检测率均达到了 100%。当 iPhone6和Sony PX440作为训练样本时,虽然检测效果有所下降,但检测效果依旧可观;当Mi4作为训练集样本时,检测效果不甚理想。由第2.1节的语谱图分析结论可知,这是因为受到Mi4设备本身特性的影响,对高频区有些许的抑制作用;但综合来看,本文提出的 I-MFSC特征在设备交叉的实验检测中具有良好的检测性能。

表2 原始语音和回放语音样本详情
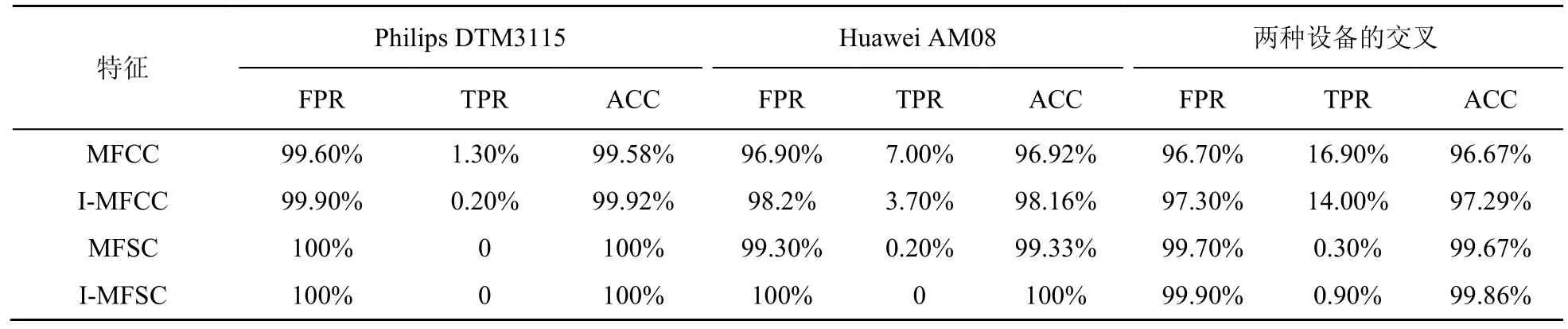
表3 不同特征的检测结果
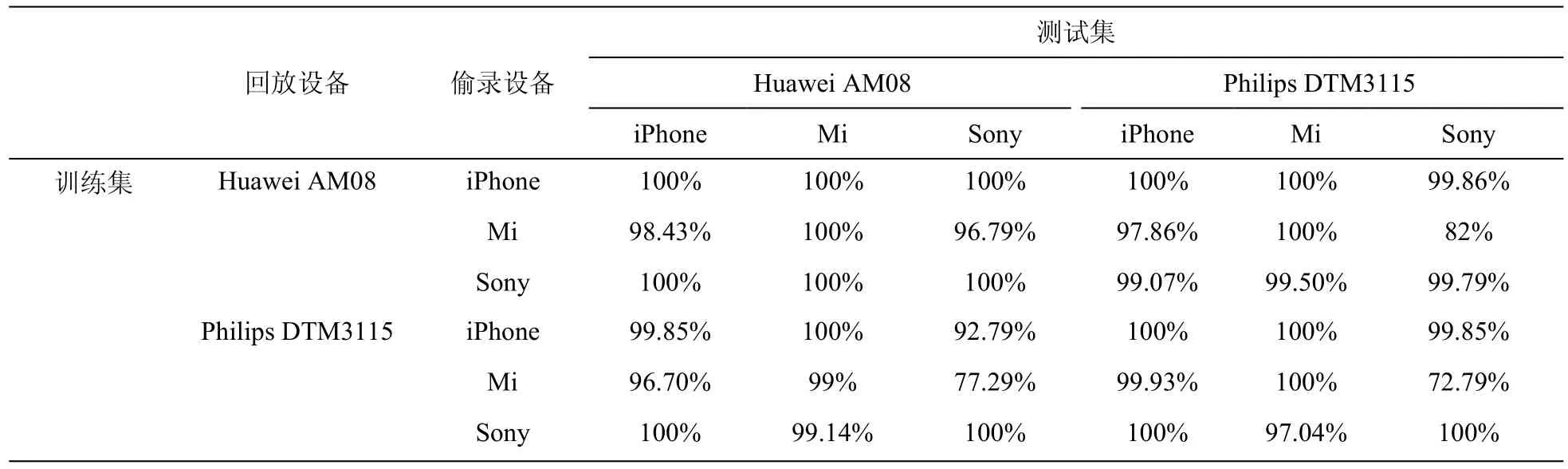
表4 不同设备之间的交叉实验检测结果

表5 噪声环境下实验检测结果
4.2.3 噪声环境下几种特征的检测效果
现实场景中偷录环境的多样性和复杂性也是影响回放语音检测性能的重要因素。考虑到声纹识别系统的实际应用场景,过高的噪声环境在声纹认证领域意义不大,且噪声环境特别大时,声纹系统会直接拒绝待测语音进入系统,因此本实验将回放语音和原始语音加上15~30 dB的高斯白噪声以检测本算法的顽健性。检测结果见表5。
由表5可以看出,噪声的引入对回放语音检测有一定的影响,当信噪比从30 dB降到15 dB时,回放语音的检测率总体呈下降趋势。但相对而言,本文提出的算法I-MFSC相较于其他3种特征,在噪音环境下表现出更好的性能。
4.2.4 对比试验
为检验本算法的有效性和适用性,将本文的算法以单独的模块形式加载到 GMM-UBM 说话人识别系统[17]中,加载回放语音检测模块的说话人识别系统如图9所示。
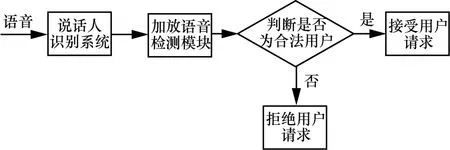
图9 加载回放语音检测模块的说话人识别系统
语音进入说话人识别系统后,说话人识别系统对语音进行第一次判别,当说话人识别系统判决为非法用户时,系统会直接拒绝该语音,不再进入回放语音检测模块。只有当说话人识别系统判决该语音来自于合法用户后,才会进行回放语音检测模块;如果回放语音检测模块判决为原始语音,则系统接受该用户请求,否则拒绝该用户请求。
此外,将本文算法同参考文献[4]和参考文献[5]提出的算法进行比较。参考文献[4]的算法采用短时能量法提取静音,并用谱减法进行去噪。采用12维MFCC和一阶差分ΔMFCC作为特征参数。而参考文献[5]的算法则采用高通滤波器进行去噪,提取6个统计特征及6阶Legendre多项式系数(共12维)作为信道模式噪声的特征参数。检测检测结果见表6,其中ACC表示检测的正确率,EER表示将检测模块加载到 GMM-UBM系统的等错误概率。

表6 对比实验检测结果
由表6可知,本文提出的算法相较于参考文献[4]和参考文献[5]在性能上有很大的提升。最后将几种方法以单独的模块加载到说话人识别系统,加载回放语音检测模块前后的等错误概率如图 10所示。由图10可以看出,加载到GMM-UBM系统后,本文提出的算法更能有效地提高说话人识别系统对回放语音的抵抗能力。
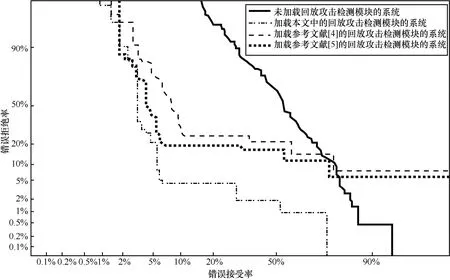
图10 加载回放语音检测模块前后的等错误概率
5 结束语
本文利用原始语音在回放语音在高频区的差异,通过逆Mel滤波器和提取去DCT前的MFSC特征,提出了一种基于高频区 I-MFSC特征的回放语音检测算法。该算法能够有效地弥补现有算法中设备单一的问题。通过实验表明,本文算法能够有效地检测回放语音和原始语音,将本文算法加载到GMM-UBM说话人识别系统时,对说话人识别的性能有了很大的提高。现实场景中,偷录设备和回放设备种类繁多,高保真的设备层出不穷,因此今后的工作将进一步探索回放语音产生的机理以及回放语音和原始语音产生差异性的具体因素。
参考文献:
[1]ZHU D, MA B, LI H.Speaker verification with feature-space MAPLR parameters[J].IEEE Transactions on Audio Speech &Language Processing, 2011, 19(3): 505-515.
[2]易克初, 胡征.一种应用矢量量化的语音合成新方法[J].电信科学, 1987(11): 1-6.YI K C, HU Z.A new speech synthesis method using vector quantization[J].Telecommunications Science, 1987(11): 1-6.
[3]郭弘.录音证据的真实性检验与研究[J].电信科学, 2010,26(Z2): 56-60.GUO H.Authenticity verification and research of recording evidence[J].Telecommunications Science, 2010, 26(Z2): 56-60.
[4]李璨, 王让定, 严迪群, 等.基于相位谱的翻录语音攻击检测算法[J].电信科学, 2017, 33(8): 145-154.LI C, WANG R D, YAN D Q, et al.Detection algorithm of riprap voice attack based on phase spectrum[J].Telecommunications Science, 2017, 33(8): 145-154.
[5]SHANG W, STEVENSON M.A playback attack detector for speaker verification systems[C]//IEEE International Symposium on Communications Control and Signal Processing (ISCCSP),March 12-14, 2008, St Julians, Malta.Piscataway: IEEE Press,2008: 1144-1149.
[6]SHANG W, STEVENSON M.Score normalization in playback attack detection[C]//IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), March 14-19, 2010, Dallas, USA.Piscataway: IEEE Press, 2010: 1678-1681.
[7]张利鹏, 曹犟, 徐明星.防止假冒者闯入说话人识别系统[J].清华大学学报(自然科学版), 2008, 48(S1): 699-703.ZHANG L P, CAO J, XU M X.Prevention of impostors entering speaker recognition systems[J].Journal of Tsinghua University (Science and Technology), 2008, 48(S1): 699-703.
[8]王志峰, 贺前华, 张雪源, 等.基于模式噪声的录音回放攻击检测[J].华南理工大学学报, 2011, 39(10): 7-12.WANG Z F, HE Q H, ZHANG X Y, et al.Channel pattern noise based playback detection algorithm speaker recognition[J].Journal of South China University of Technology (Natural Science Edition), 2011, 39(10): 7-12.
[9]李富强, 万红, 黄俊杰.基于MATLAB的语谱图显示与分析[J].微计算机信息, 2005(20): 172-174.LI F Q, WAN H, HUANG J J.The display and analysis of sonogram based on MATLAB[J].Control & Automation,2005(20): 172-174.
[10]BURILLO P, BUSTINCE H.Entropy on intuitionistic fuzzy sets and on interval-valued fuzzy sets[J].Fuzzy Sets & Systems,1996, 78(3): 305-316.
[11]项要杰, 杨俊安, 李晋徽, 等.一种适用于说话人识别的改进Mel滤波器[J].计算机工程, 2013(11): 214-217.XIANG Y J, YANG J A, LI J H, et al.An improved Mel-frequency filter for speaker recognition[J].Computer Engineering, 2013(11): 214-217.
[12]陶佰睿, 郭琴, 苗凤娟, 等.基于改进 Mel滤波器组的声纹特征提取SoC设计[J].微电子学, 2015(6): 785-788.TAO B R, GUO Q, MIAO F J, et al.SoC design of voiceprint features extraction based on improved Mel filter banks[J].Microelectronics, 2015(6): 785-788.
[13]胡永刚, 吴翊, 王洪志, 等.高维数据降维的 DCT变换[J].计算机工程与应用, 2006(32): 21-23.HU Y G, WU Y, WANG H Z, et al.Discrete cosine transform in data dimensionality reduction[J].Computer Engineering and Applications, 2006(32): 21-23.
[14]MOHAMED A.Deep neural network acoustic models for ASR[J].Doctoral, 2014.
[15]CHANG C C, LIN C J.LIBSVM: a library for support vector machines[J].ACM Transactions on Intelligent Systems &Technology, 2012, 2(3): 1-27.
[16]王天庆, 李爱军.连续汉语语音识别语料库的设计[C]//第六届全国现代语音学学术会议论文集, 2003年10月1日, 天津,中国.[出版地不详: 出版者不详], 2003: 1-4.WANG T Q, LI A J.The design of the continuous Chinese speech recognition corpus[C]//The Sixth National Conference on Modern Phonetics Learning, Oct 1, 2003, Tianjin, China.[S.l.:s.n.], 2003: 1-4.
[17]CHAKROBORTY S, ROY A, SAHA G.Improved closed set ttext-independent speaker identification by combining MFCC with evidence from flipped filter banks[J].International Journal of Signal Processing, 2007, 4(2): 114-122.
