基于改进Tri-Training算法的大数据保险业客户分类研究
2018-05-25林志鸿
林志鸿
(湄洲湾职业技术学院 信息工程系,福建 莆田351254)
经过改革和重组后,我国保险市场呈现了以多个大规模保险企业为主,数量不断增长的众多小保险企业为辅的格局.同时,国外的大型保险公司也进入我国保险市场,我国保险企业面临着激烈的竞争.我国保险公司需要寻求新的盈利模式,才能够在激烈的竞争中立于不败之地.目前,信息技术正处于迅猛发展的阶段,几乎各个领域都涉及到正在快速增长的大数据.大数据的增长速度保持在60%左右.在大数据背景下,保险业发展的根本就在于建立良好的客户管理体系.保险行业需要依据大数据资源确立健全的客户评价体系,进行相应的客户评价和分类.通过对客户的细分,保险公司能够有效地采取相应的客户战略,针对不同的客户群体特征,选择不同的保险产品,实现客户资源的优化.为了提高保险业客户分类的有效性,应该选择一种行之有效的分类方法.半监督学习技术是新型的机器学习方法,能够同时使用标记和未标记样本,通过未标记样本为辅助手段,获得最佳的保险业客户分类效果,非常适用于保险业客户大数据的处理[1].
1 保险业客户细分的指标
对于保险业客户大数据的特点,首先应对保险业客户的信息有一个基本的了解,针对保险业客户的行为特点,建立适宜的客户细分指标体系,能够确定客户的行为特征,分析出客户能够带来的利润,确定具有较高企业价值的客户[2].依据RFM理论,保险业客户可以通过R(相邻两次购买保险产品的时间间隔),F(在一个时期间购买保险产品的次数)和M(在一个时期购买保险产品的金额)进行客户细分.针对目前保险业客户大数据的特征,增加了相应的客户细分指标,主要包括:客户的基本信息、客户的交易行为、客户在保险企业浏览、检索等操作特点以及客户购买保险后续保的状况等.
2 改进Tri-Training分类算法的基本理论
Tri-Training算法对采样进行标记,可以形成3个带有标记的样本集合,能够确保3个样本集能够具有普遍意义,能够涵盖全部类别,避免带标记样本均衡的缺陷.改进后Tri-Training算法具有更好泛化性能,能够获得更高的分类正确率.首先,将不同样本集取出,接着,对不同样本进行随机采样.算法利用随机采样法确定样本集类别数,定义为H,再确定不同类别样本的数量,利用随机采样函数从每个类中任意选取标记样本,这样就获得了3类标记样本集.算法流程如下:
输入:带标记样本集(定义为L),没有标记样本集(定义为U),测试集(定义为T)和分类器(定义为H).
输出样本:利用分类模型对测试集进行分类所获得的分类精度[3].
步骤1:利用样本集对分类器进行训练.
步骤2:利用分类采样技术将样本集L划分为3个子集合,从而获得3个带标记的样本集,定义为Li(i=1,2,3).
步骤3:利用3个带有标记的样本集训练3个分类器Hi(i=1,2,3).
步骤4:进行分类器分类错误率的初始化(ei=0.6).分类器的分类性能利用如下的公式进行判别[4]:

步骤5:进行未标记样本的预测分类,进行分类器的迭代训练.
步骤6:循环执行步骤3~步骤5,当分类器的分类错误率不变时,分类器预测迭代结束.
步骤7:训练好分类器后,利用分类器对测试集进行分类,确定分类器的分类正确率.
步骤8:算法结束.
3 基于改进Tri-Training算法的大数据保险业客户分类流程
基于改进Tri-Training算法的大数据保险业客户分类主要包括:大数据输入、数据预处理、分类器迭代训练和分类结果4个部分[5-7].
(1)大数据输入:将收集的数据输入至大数据保险业客户分类系统.
(2)数据预处理:提取保险业潜在客户的特征,选择恰当的基本特征对保险业潜在客户所蕴藏的属性进行量化处理,获得分类器需要的数据格式.利用仿真程序进行保险业潜在客户大数据的预处理,在构建保险业客户分类模型时,选择保险业客户细分指标为基本特征,能够验证改进Tri-Training算法的鲁棒性.
(3)迭代训练:分类器的迭代训练师通过数据预处理所获得的客户细分集,对分类器进行相应的训练,同时能够对分类器进行测试.利用改进的Tri-Training算法对3个分类器同时进行训练.分类采样技术是通过提取标记样本集中不同类的保险业客户,再针对提取的不同类别的客户样本进行随机采样,能够获得3个带标记的样本集合.重复这些步骤得到的样本集训练不同的分类器,通过训练后的3个分类器共同对没有标记的样本集中各个样本进行标记.相对于一个分类器对未被标记样本的分类,其他两个分类器如果得到相同的结论,此时这些未被标记的样本将归入至这个分类器的带有标记样本集中,并且利用该分类器对新的样本集进行迭代训练,当分类器的分类结果不变化时,迭代训练结束.
(4)分类结果:将最终保险业大客户的分类结果输出.
基于改进Tri-Training算法的大数据保险业客户分类流程见图1.
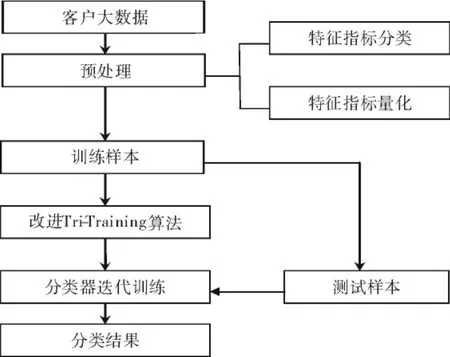
图1 基于改进Tri-Training算法的大数据保险业客户分类流程
4 实例研究
随机从10个保险公司分别选取1 000个客户,共10 000个客户,其中7 000个客户为训练样本(训练集中标记样本的比例40%),3 000个客户为测试样本.利用改进的Tri-Training算法对其进行分类,将客户划分为6类,分别为黄金客户(购买保险的需求较多的高端客户,对于该类客户一定要建立良好的客户关系),重要发展客户(保险销售的主要目标群体,通过有效的收集刺激该群体的购买欲望)、重要挽留客户(容易流失的投保能力强的客户,应该努力保留这类客户)、重点维持客户(购买能力有限的投保群体,该类客户对于保险公司利润贡献是一定的)、普通客户(无法从中获得利润的群体,只要保持一般的维持关系即可)和无价值客户(该类客户对于保险公司利润基本无作用,可以放弃的群体).
分别利用传统的支持向量机、传统的Tri-Training算法和改进的Tri-Training算法对样本进行训练,最终对测试样本进行测试,测试结果见表1.基于改进的Tri-Training算法相对于支持向量机和传统的Tri-Training算法具有更高的分类准确率,能够有效地对大数据保险业进行分类,能够根据分类结果,针对不同类别客户的特点,选择不同的应对策略,确保公司的利润.
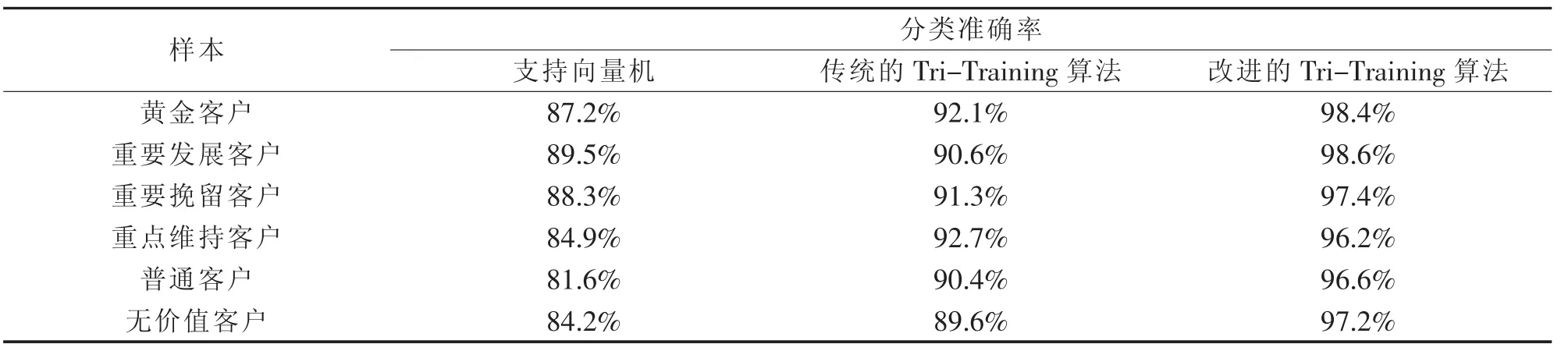
表1 保险公司客户测试样本分类结果(标记样本的比例40%)
为了分析标记样本比例对分类准确率的影响,将标记样本的比例从40%提高至60%,进行相应的保险业客户分类,测试结果见表2.当测试样本中标记样本的比例从40%增加至60%时,对于不同的客户类型获得的分类准确率都有提高,结果表明,随着测试样本集中标记样本比例的增加,保险业客户分类结果的准确率将随之增加.

表2 保险公司客户测试样本分类结果(标记样本的比例60%)
5 结论
保险业正处蓬勃发展的阶段,提升客户关系管理是增加保险企业利润的关键.在大数据背景下,有效地对客户进行分类,使保险公司能够有效地识别不同的客户群体.针对不同的客户特征增加新的保险业务,能够极大地提高客户满意度,提升保险业的服务质量.利用改进的Tri-Training算法提升了大数据保险业客户分类的准确率,仿真分析表明改进的Tri-Training算法能够提高大数据保险业客户分类的精度,将其应用于保险业客户分类中具有较好的可行性,能够提高保险业客户细分的性能,这样就能够极大地提升保险业的市场战略水平,提升保险公司的核心竞争力.
[1]李品睿,许守任,许晖.基于RFM模型的核心客户识别与关系管理研究——以保险业为例[J].现代管理科学,2015(6):24-26.
[2]葛春燕.数据挖掘技术在保险公司客户评估中的应用研究[J].软件,2013,34(1):116-118.
[3]张栩晨.利用 tri—training 算法解决推荐系统冷启动问题[J].计算机科学,2016,43(12):108-114.
[4]徐海龙,龙光正,别晓峰,等.结合tri-training半监督学习和凸壳向量的 SVM主动学习算法[J].模式识别与人工智能,2016,29(1):39-46.
[5]彭雅琴,宫宁生.一种自适应的 tri-training 半监督算法[J].计算机系统应用,2016,25(8):130-134.
[6]胡学钢,马利伟,李培培.一种基于 tri-training 的数据流集成分类算法[J].数据采集与处理,2017,32(5):853-860.
[7]王雷,杨思春.基于改进 tri-training 算法的中文问句分类[J].安徽工业大学学报(自然科学版),2016,33(2):172-176.
